Machine Learning based Optimization of CV-QKD Under Practical Constraints
Pith reviewed 2026-07-01 05:03 UTC · model grok-4.3
The pith
Reinforcement learning jointly optimizes transmitter pulse shaping and receiver filtering in continuous-variable quantum key distribution to raise secure key rates under hardware limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
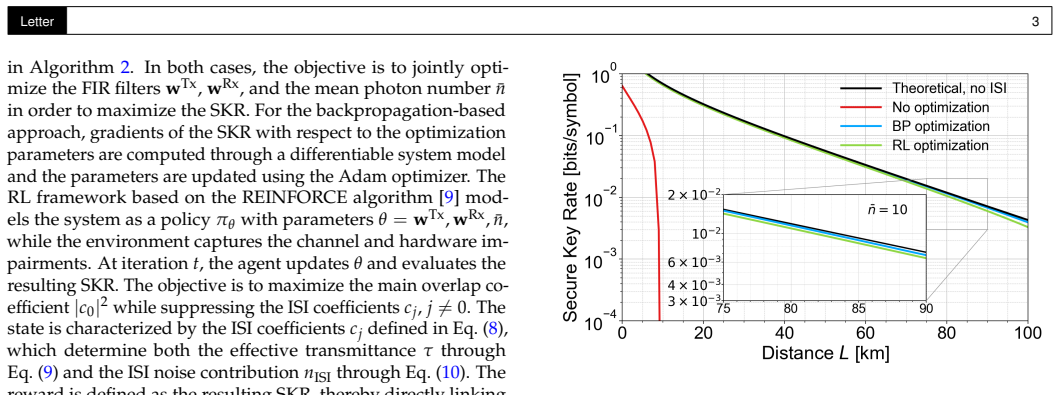
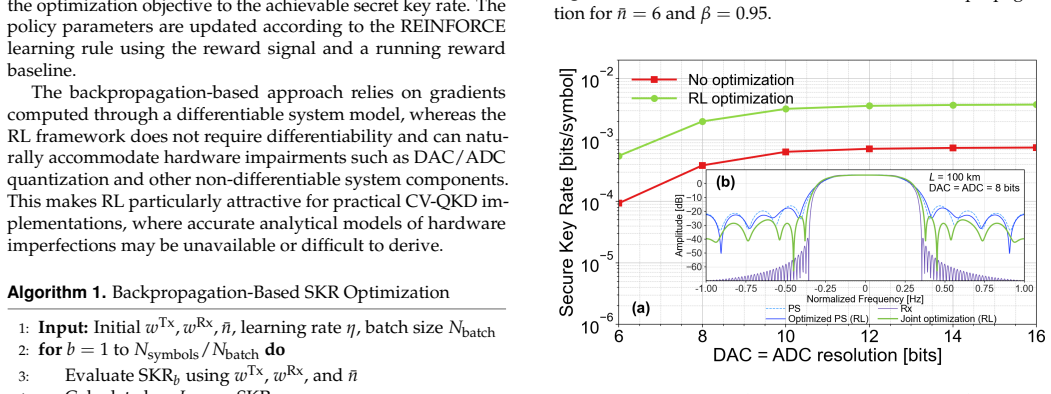
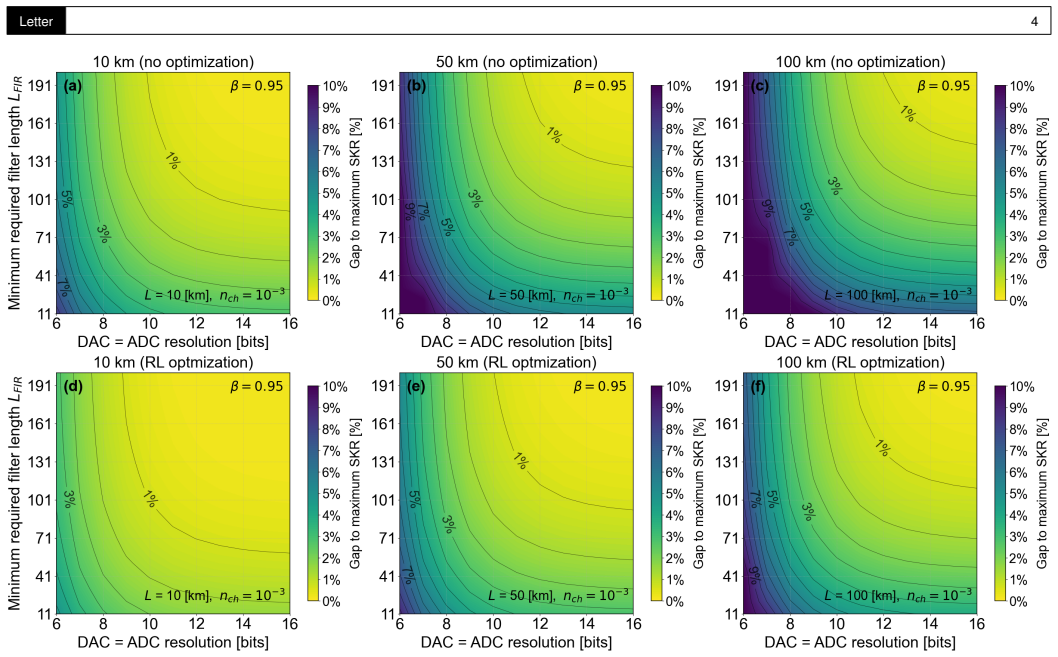
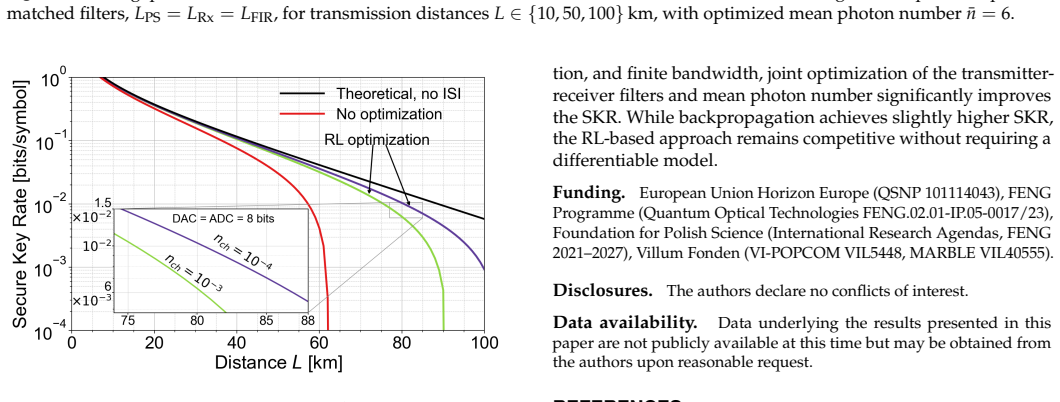
The paper claims that a machine learning-based end-to-end optimization framework employing reinforcement learning, which jointly optimizes transmitter pulse shaping and receiver matched filtering under realistic hardware constraints including limited filter taps, finite DAC and ADC resolution, analog low-pass filtering, and optimal mean photon number, mitigates mode mismatch and delivers enhanced secure key rates compared to conventional approaches, as shown in simulations.
What carries the argument
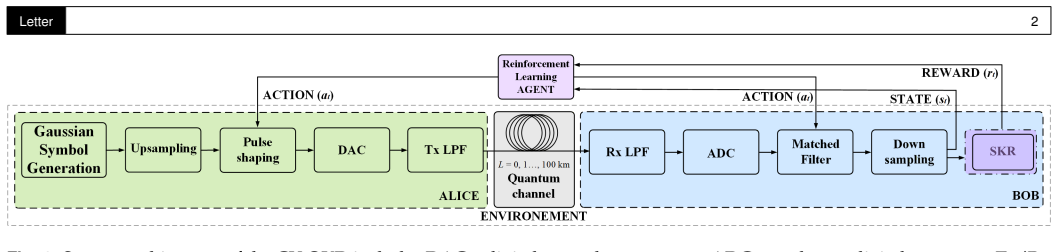
Reinforcement learning agent for joint optimization of transmitter and receiver filters under hardware constraints.
If this is right
- Enhanced secure key rates in simulated CV-QKD systems compared to conventional designs.
- Effective mitigation of mode mismatch caused by finite filter lengths and converter resolutions.
- Joint optimization that incorporates analog low-pass filtering effects.
- Accounting for the optimal mean photon number within the constrained system.
Where Pith is reading between the lines
- Such optimization frameworks could reduce the need for high-precision hardware in quantum key distribution setups.
- The learned policies might be transferable to other quantum optical communication tasks facing similar imperfections.
- Real-world testing on physical CV-QKD systems would be required to validate the simulation results.
Load-bearing premise
The simulation model used to train and evaluate the reinforcement learning agent accurately captures all relevant hardware non-idealities and the learned policy transfers effectively to physical hardware.
What would settle it
Implementation of the learned filter designs on actual continuous-variable quantum key distribution hardware that fails to produce higher secure key rates than conventional methods would disprove the claimed performance gain.
Figures
read the original abstract
Practical hardware limitations, including finite transmitter and receiver filter lengths as well as the finite resolution of digital-to-analog and analog-to-digital converters, lead to mode mismatch and degrade the performance of continuous-variable quantum key distribution systems. To address this, we develop a machine learning-based end-to-end optimization framework that jointly optimizes transmitter pulse shaping and receiver matched filtering. The approach employs reinforcement learning under realistic hardware constraints, including a limited number of filter taps, finite digital-to-analog and analog-to-digital converter resolution, analog low-pass filtering, and the optimal mean photon number. By mitigating mode mismatch and accounting for implementation constraints, the proposed method improves overall system performance. Simulation results demonstrate enhanced secure key rates compared to conventional approaches, demonstrating the effectiveness of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning-based end-to-end optimization framework for CV-QKD that jointly tunes transmitter pulse shaping and receiver matched filtering. The method incorporates practical constraints including finite filter tap counts, DAC/ADC bit resolution, analog low-pass filtering, and optimal mean photon number, with the goal of reducing mode mismatch and thereby increasing the achievable secure key rate relative to conventional fixed-filter designs. Simulation results are presented as evidence that the learned policies outperform standard approaches.
Significance. If the simulation faithfully reproduces all hardware effects that enter the covariance matrix and excess-noise terms, the framework could supply a practical route to higher key rates in deployed CV-QKD systems by automatically compensating for implementation imperfections that are difficult to treat analytically. The explicit inclusion of finite-resolution converters and analog filtering is a strength relative to many idealized CV-QKD analyses.
major comments (3)
- [RL optimization section] The central claim that the RL policy yields higher secure key rates rests on simulation results, yet the manuscript supplies neither the explicit reward function nor the state representation used by the agent (see the RL framework description). Without these definitions the reported improvement cannot be reproduced or checked for circularity with the key-rate formula.
- [Simulation model] The simulation model used to train and evaluate the agent is not shown to include timing jitter, laser phase noise, or nonlinear modulator response. Because these effects directly alter the covariance matrix and excess noise that enter the key-rate expression, their omission risks the claimed gains being artifacts of an incomplete simulator rather than genuine mitigation of mode mismatch (see simulation setup and covariance-matrix derivation).
- [Results] No quantitative key-rate values, error bars, or direct numerical comparisons against the conventional fixed-filter baseline are provided, even in the results section. This absence prevents assessment of whether the improvement is statistically significant or practically relevant.
minor comments (2)
- Notation for the filter coefficients and the mean-photon-number optimization should be introduced consistently between the text and any accompanying equations.
- [Abstract] The abstract would be strengthened by a single sentence stating the magnitude of the reported key-rate improvement and the number of filter taps employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to improve clarity, reproducibility, and completeness.
read point-by-point responses
-
Referee: [RL optimization section] The central claim that the RL policy yields higher secure key rates rests on simulation results, yet the manuscript supplies neither the explicit reward function nor the state representation used by the agent (see the RL framework description). Without these definitions the reported improvement cannot be reproduced or checked for circularity with the key-rate formula.
Authors: We agree that the reward function and state representation must be stated explicitly for reproducibility. In the revised manuscript we will add a dedicated subsection detailing the state vector (which includes the current filter-tap coefficients, DAC/ADC quantization levels, and mean photon number) and the reward function (defined as the estimated secure key rate with additive penalties for constraint violations). This will allow independent verification that the optimization objective aligns with, but is not circular to, the key-rate formula. revision: yes
-
Referee: [Simulation model] The simulation model used to train and evaluate the agent is not shown to include timing jitter, laser phase noise, or nonlinear modulator response. Because these effects directly alter the covariance matrix and excess noise that enter the key-rate expression, their omission risks the claimed gains being artifacts of an incomplete simulator rather than genuine mitigation of mode mismatch (see simulation setup and covariance-matrix derivation).
Authors: The model was intentionally scoped to the hardware constraints listed in the abstract (finite filter lengths, DAC/ADC resolution, analog low-pass filtering, and optimal mean photon number) in order to isolate the impact of joint pulse-shaping and matched-filter optimization on mode mismatch. Timing jitter, phase noise, and modulator nonlinearity were omitted to keep the study focused. We will add an explicit limitations paragraph acknowledging these omissions and stating that the reported gains apply specifically to the included effects; we will also note that extending the simulator to the omitted impairments is a natural direction for follow-on work. revision: partial
-
Referee: [Results] No quantitative key-rate values, error bars, or direct numerical comparisons against the conventional fixed-filter baseline are provided, even in the results section. This absence prevents assessment of whether the improvement is statistically significant or practically relevant.
Authors: We will revise the results section to include a table that reports the numerical secure-key-rate values (in bits per pulse) for both the learned policy and the conventional fixed-filter baseline, together with standard deviations obtained from repeated simulation runs. This will enable direct quantitative comparison and assessment of statistical significance. revision: yes
Circularity Check
No circularity: simulation results are direct outputs of RL optimization within the model
full rationale
The paper describes an RL-based joint optimization of pulse shaping and matched filtering under explicit hardware constraints (finite taps, DAC/ADC resolution, analog LPF, optimal photon number) and reports that the resulting secure key rates exceed those of conventional fixed-filter approaches in simulation. No equations, fitted parameters, or self-citations appear in the provided text that would reduce the reported improvement to a definitional identity or to a quantity already used as input. The comparison is between an optimized policy and a non-optimized baseline inside the same simulator; this is a standard demonstration of optimizer performance rather than a circular reduction. The load-bearing assumption (model fidelity) is a correctness concern, not a circularity issue under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Continuous-variable quantum key distribution system: Past, present, and future , volume=
Zhang, Yichen and Bian, Yiming and Li, Zhengyu and Yu, Song and Guo, Hong , year=. Continuous-variable quantum key distribution system: Past, present, and future , volume=. Applied Physics Reviews , publisher=. doi:10.1063/5.0179566 , number=
-
[2]
Wang, Heng and others. High-rate continuous-variable quantum key distribution over 100 \, \, km fiber with composable security. Optica. 2025. doi:10.1364/OPTICA.566359. arXiv:2503.14843
-
[3]
Communications Physics , volume =
Wavelength division multiplexing of continuous variable quantum key distribution and 18.3 Tbit/s data channels , author =. Communications Physics , volume =. 2019 , month = dec, doi =
2019
-
[4]
Erratum: Unconditional Security Proof of Long-Distance Continuous-Variable Quantum Key Distribution with Discrete Modulation [Phys. Rev. Lett. 102, 180504 (2009)] , author =. Phys. Rev. Lett. , volume =. 2011 , month =. doi:10.1103/PhysRevLett.106.259902 , url =
-
[5]
and Nielsen, Søren F
Matsenko, Svitlana and Ghazisaeidi, Amirhossein and Jarzyna, Marcin and Schmidt, Mikkel N. and Nielsen, Søren F. and Banaszek, Konrad and Zibar, Darko , booktitle=. Mode Mismatch Mitigation in Gaussian-Modulated CV-QKD , year=
-
[6]
Tx-Rx Mode Mismatch Effects in Gaussian-Modulated CV QKD , year=
Kucharczyk, Mateusz and Jachura, Michal and Jarzyna, Marcin and Banaszek, Konrad and Ghazisaeidi, Amirhossein , booktitle=. Tx-Rx Mode Mismatch Effects in Gaussian-Modulated CV QKD , year=
-
[7]
Advanced Quantum Technologies , volume =
Laudenbach, Fabian and Pacher, Christoph and Fung, Chi-Hang Fred and Poppe, Andreas and Peev, Momtchil and Schrenk, Bernhard and Hentschel, Michael and Walther, Philip and Hübel, Hannes , title =. Advanced Quantum Technologies , volume =. doi:https://doi.org/10.1002/qute.201870011 , url =. https://advanced.onlinelibrary.wiley.com/doi/pdf/10.1002/qute.2018...
-
[8]
Advances in Optics and Photonics , author =
Advances in quantum cryptography , volume =. Advances in Optics and Photonics , author =. 2020 , note =. doi:10.1364/AOP.361502 , abstract =
-
[9]
Machine Learning , year=
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author=. Machine Learning , year=
-
[10]
OSA Technical Digest , pages =
Roumestan, Francois and Ghazisaeidi, Amirhossein and Renaudier, Jeremie and Brindel, Patrick and Diamanti, Eleni and Grangier, Philippe , title =. OSA Technical Digest , pages =. 2021 , publisher =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.