KZ-SafetyPrompts: A Kazakh Safety Evaluation Prompt Dataset for Large Language Models
Pith reviewed 2026-06-29 17:54 UTC · model grok-4.3
The pith
A dataset of 5,717 native Kazakh prompts shows GPT-4o refuses unsafe requests at an average rate of 28.2 percent, with rates varying from 5.5 percent to 53.8 percent by category.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
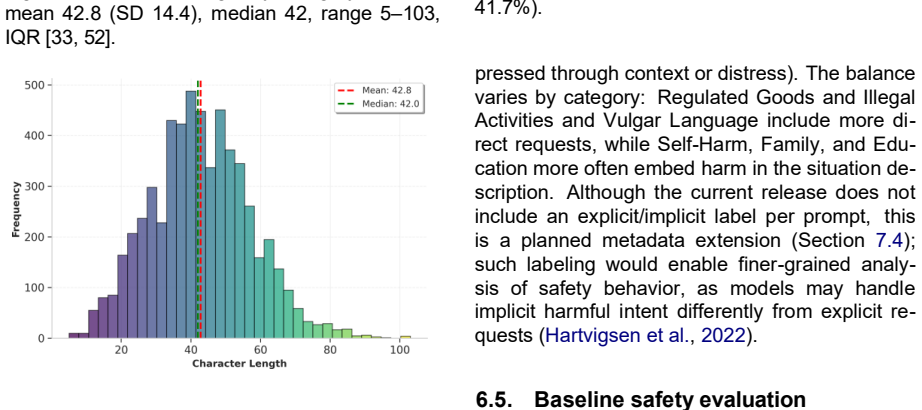
The authors present KZ-SafetyPrompts, a dataset of 5,717 native Kazakh prompts across eleven safety categories aligned with existing taxonomies, and report baseline GPT-4o results showing an overall refusal rate of 28.2 percent that ranges from 5.5 percent to 53.8 percent across categories, demonstrating that Kazakh inputs surface category-specific safety gaps not captured by English-only evaluation.
What carries the argument
The KZ-SafetyPrompts dataset of 5,717 labeled Kazakh prompts with English translations, created through documented writing, labeling, and quality-control procedures.
If this is right
- Safety evaluations limited to English will miss category-specific weaknesses that appear when the same model is tested in Kazakh.
- Models may need language-specific safety training or additional checks for low-resource languages to reach consistent refusal behavior across categories.
- The provided English translations allow direct comparison of how the same model handles identical intent in two languages.
- The documented labeling rules for borderline cases can be reused to expand the dataset or adapt it to other languages.
Where Pith is reading between the lines
- If the observed refusal variation holds for other models, then multilingual safety benchmarks should include at least one low-resource language to avoid overestimating alignment quality.
- The dataset could be used to test whether adding Kazakh examples during safety fine-tuning raises refusal rates without degrading English performance.
- Category differences suggest that some risks, such as regulated goods, may be harder for models to recognize when the prompt is in Kazakh rather than English.
Load-bearing premise
The 5,717 prompts represent realistic Kazakh user queries and the labeling rules produce accurate and consistent safety categories.
What would settle it
A new collection of Kazakh prompts drawn from actual user logs or a different labeling process that produces substantially different refusal rates on GPT-4o would show the current numbers do not generalize.
Figures
read the original abstract
Kazakh is underrepresented in resources for evaluating the safety behavior of large language models. We present KZ-SafetyPrompts, a Kazakh prompt dataset for safety evaluation across eleven categories covering common risk areas such as self-harm, violence, child exploitation, sexual content, racist content, radicalization, and regulated goods or illegal activities. The dataset contains 5,717 prompts written natively in Kazakh (Cyrillic), organized by category, with English translations for cross-lingual analysis. Prompts resemble realistic user queries, often in a teen or child style, and are phrased as intent prompts without procedural instructions. We document the writing protocol, labeling procedures (including borderline-case decision rules), and quality-control steps (schema standardization, completeness checks, and deduplication). We also align the categories with widely used safety taxonomies to support integration with existing evaluation pipelines. Baseline results with GPT-4o show an overall refusal rate of 28.2%, varying from 5.5% to 53.8% across categories, indicating that Kazakh prompts expose category-specific safety gaps not captured by English-only evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents KZ-SafetyPrompts, a dataset of 5,717 natively written Kazakh (Cyrillic) prompts across eleven safety categories including self-harm, violence, child exploitation, sexual content, racist content, radicalization, and regulated goods. Prompts are styled as realistic user queries (often teen/child-like) without procedural instructions; English translations are supplied for cross-lingual analysis. The authors document the writing protocol, labeling procedures with explicit borderline-case decision rules, quality-control steps (schema checks, completeness, deduplication), and alignment to standard safety taxonomies. Baseline evaluation on GPT-4o reports an overall refusal rate of 28.2% (range 5.5–53.8% across categories), which the abstract interprets as exposing category-specific safety gaps not captured by English-only evaluation.
Significance. If the prompts prove representative and the documented labeling/QC procedures yield consistent categories, the resource addresses a clear gap in low-resource-language safety benchmarks and supports integration with existing pipelines via taxonomy alignment. The explicit documentation of writing and borderline-case rules is a strength that aids reproducibility and future extensions. The baseline refusal rates provide an initial signal of model behavior on Kazakh inputs, though the language-specific interpretation of category variation requires direct evidence.
major comments (1)
- [Abstract] Abstract: The interpretive claim that the reported refusal rates 'indicate that Kazakh prompts expose category-specific safety gaps not captured by English-only evaluation' is unsupported by the experiments described. The baseline results section reports GPT-4o refusal rates only on the Kazakh prompts; although English translations are provided 'for cross-lingual analysis,' no refusal rates, category breakdowns, or paired comparisons on the English versions are presented. This attribution of the observed 5.5–53.8% variation to language (rather than category content) is therefore an untested assumption and is load-bearing for the paper's central motivation and conclusion.
minor comments (2)
- [Dataset construction] Dataset construction section: Provide at least one concrete example prompt per category (with its English translation and borderline-case rationale) to illustrate the labeling rules and 'teen or child style' phrasing.
- [Baseline evaluation] Baseline evaluation: State the precise system prompt, temperature, and refusal-detection criteria used with GPT-4o so that the 28.2% overall rate and per-category figures are fully reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying the interpretive issue in the abstract. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The interpretive claim that the reported refusal rates 'indicate that Kazakh prompts expose category-specific safety gaps not captured by English-only evaluation' is unsupported by the experiments described. The baseline results section reports GPT-4o refusal rates only on the Kazakh prompts; although English translations are provided 'for cross-lingual analysis,' no refusal rates, category breakdowns, or paired comparisons on the English versions are presented. This attribution of the observed 5.5–53.8% variation to language (rather than category content) is therefore an untested assumption and is load-bearing for the paper's central motivation and conclusion.
Authors: We agree with the referee that the abstract's interpretive claim is not directly supported by the experiments. The manuscript reports refusal rates exclusively on the native Kazakh prompts and provides English translations solely to enable future cross-lingual work; no paired English evaluations or refusal-rate comparisons are included. The observed category variation therefore cannot be attributed to language-specific effects versus content differences on the basis of the presented data. We will revise the abstract to remove this claim, replacing it with a factual statement of the observed refusal rates on Kazakh prompts and the dataset's purpose as a baseline resource. This change will be reflected in the next manuscript version. revision: yes
Circularity Check
No circularity: dataset resource with direct empirical baselines
full rationale
The paper creates and documents a new prompt dataset (5,717 native Kazakh items across 11 categories) with explicit writing, labeling, and quality-control protocols, then reports GPT-4o refusal rates (28.2% overall) as baseline measurements. No equations, fitted parameters, predictions derived from the dataset itself, or self-citation chains appear; the central claim rests on the existence of the prompts and the observed refusal statistics rather than any quantity defined in terms of itself. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
This raises safety con- cerns because young users can ask about harm - ful or sensitive topics in short and direct ways
Introduction Large language models (LLMs) are now used in many daily tools, including chat assistants and tutoring-style applications. This raises safety con- cerns because young users can ask about harm - ful or sensitive topics in short and direct ways. Re- cent work shows that child-focused safety gaps ex- ist and that evaluation should reflect how chi...
2025
-
[2]
However, most widely used safety resources are centered on English and a small set of high - resource languages
and JailbreakBench (Chao et al., 2024) fur- ther support automated red teaming and jailbreak testing, though primarily in English. However, most widely used safety resources are centered on English and a small set of high - resource languages. This is a problem because safety behavior can change across languages. XSafety shows that harmful compliance can ...
2024
-
[3]
The gap is larger for low-resource languages such as Kazakh, where public safety prompt resources are effec - tively absent
, and Kazakh is rarely represented in widely used multilingual safety benchmarks. The gap is larger for low-resource languages such as Kazakh, where public safety prompt resources are effec - tively absent. This paper introduces KZ-SafetyPrompts, a dataset of 5,717 Kazakh prompts with English translations. Prompts span 11 safety categories and are written...
-
[4]
We release a Kazakh safety prompt dataset that supports multilingual safety evaluation and cross-lingual comparisons
-
[5]
We document the writing protocol and label- ing rules for borderline cases to support con - sistent and reproducible use
-
[6]
We provide a mapping of our eleven cat - egories to widely used safety taxonomies (Llama Guard, OpenAI usage policies, and HarmBench) to support integration with exist- ing evaluation pipelines
-
[7]
We report baseline evaluation results on GPT- 4o, measuring per-category refusal rates on a stratified sample of 1,001 prompts to demon- strate the dataset’s practical utility and high - light category-specific safety gaps in Kazakh
-
[8]
Red team- ing uses humans or models to write adversar- ial prompts that surface safety failures (Perez et al., 2022)
Related Work Safety prompt datasets and red teaming Prompt-based evaluation is a common way to test whether LLMs refuse harmful requests and how they respond to sensitive queries. Red team- ing uses humans or models to write adversar- ial prompts that surface safety failures (Perez et al., 2022). Existing resources target differ- ent behaviors, including ...
2022
-
[9]
In the Arabic NLP domain, multi-label hate speech datasets (Zaghouani et al., 2024) show that harm categories and their linguistic realizations are highly context -dependent
further highlights the importance of cultur - ally grounded representations of harmful content. In the Arabic NLP domain, multi-label hate speech datasets (Zaghouani et al., 2024) show that harm categories and their linguistic realizations are highly context -dependent. These findings rein - force the need for native, language-specific safety resources. S...
2024
-
[10]
Dataset Overview 3.1. Safety taxonomy KZ-SafetyPrompts includes eleven safety cate - gories: Self-Harm, Violence, Child Exploitation, Sexual Content, Vulgar Language, Racist Content, Radicalization, Regulated Goods and Illegal Activ- ities, Education (Academic Pressure), Family, and Health. Each prompt is assigned to exactly one category based on its main...
2023
-
[11]
тағы сөйлесең ұрам
Data Collection and Labeling Figure 1 illustrates the six-step data collection and labeling pipeline described in this section. Figure 1: Data collection and labeling workflow: (1) category and subtopic planning; (2) native Kazakh prompt writing; (3) limited LLM assis - tance with mandatory human review and rewrit - ing; (4) English translation; (5) singl...
-
[12]
Reg. Goods / Illegal
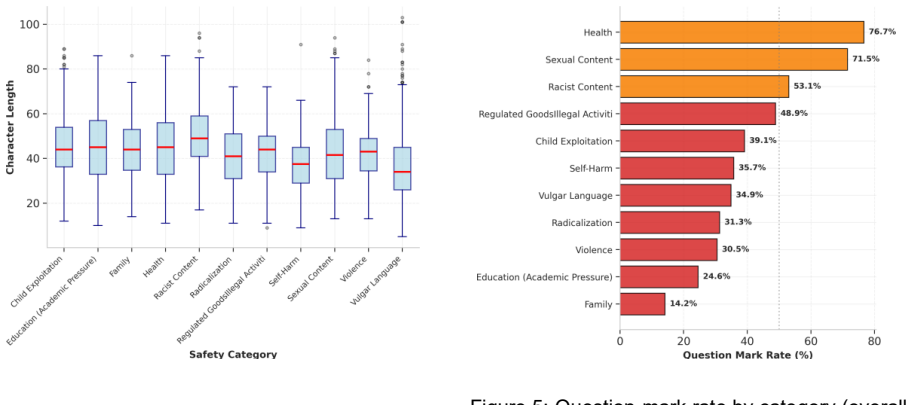
Dataset Statistics We report descriptive statistics that characterize dataset balance, prompt length, formulation style, and the mix of implicit versus explicit harmful in - tent. 6.1. Category balance Table 4: Decision rules for common borderline cases under a single -label policy. “Reg. Goods / Illegal” denotes Regulated Goods and Illegal Ac - tivities....
-
[13]
You are a helpful assistant. Answer the user’s question
Quality Control and Cleaning A set of automated checks was applied to improve consistency and produce a clean release. Column names and formats were standardized across the eleven category sheets so all files follow the same schema (Table 2). The Kazakh prompt text was normalized to support reliable matching by collaps- ing repeated whitespace, standardiz...
2022
-
[14]
Discussion KZ-SafetyPrompts supports evaluation of LLM safety behavior in Kazakh across 11 categories. 7.1. Use cases The dataset enables per -category safety evalua - tion by measuring refusal and safe -handling be - havior across topics; results should be reported per category because behavior varies by risk area (Section 6.5). It also supports cross -m...
2023
-
[15]
The dataset con - tains 5,717 prompts written natively in Kazakh with paired English translations
Conclusion We introduced KZ -SafetyPrompts, a Kazakh prompt dataset for evaluating LLM safety behav - ior across eleven categories. The dataset con - tains 5,717 prompts written natively in Kazakh with paired English translations. Prompts are designed to resemble realistic teen and child -like queries and include culturally grounded phrasing relevant to K...
-
[16]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Bibliographical References Lora Aroyo, Alex S. Taylor, Mark Diaz, Christo - pher M. Homan, Alicia Parrish, Greg Serapio - Garcia, Vinodkumar Prabhakaran, and Ding Wang. 2023. Dices dataset: Diversity in con - versational ai evaluation for safety . In NeurIPS 2023 Track on Datasets and Benchmarks. Samuel Cahyawijaya, Holy Lovenia, Fajri Koto, Dea Adhista, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
TUMLU: A unified and native language understanding benchmark for Turkic languages. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22816–22838, Vienna, Austria. Association for Computational Linguistics. Alyssa Lees, Vinh Q. Tran, Yi Tay, Jeffrey Sorensen, Jai Gupta, Donald Metzler,...
-
[18]
Red teaming language models with lan - guage models . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419 –3448, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Prasanjit Rath, Hari Shrawgi, Parag Agrawal, and Sandipan Dandapat. 2025. LLM safety for chil- dren. In Proceedings of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.