OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
Pith reviewed 2026-06-27 01:04 UTC · model grok-4.3
The pith
OPD-Evolver trains agents to read, use, write and maintain memory through slow-fast on-policy distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
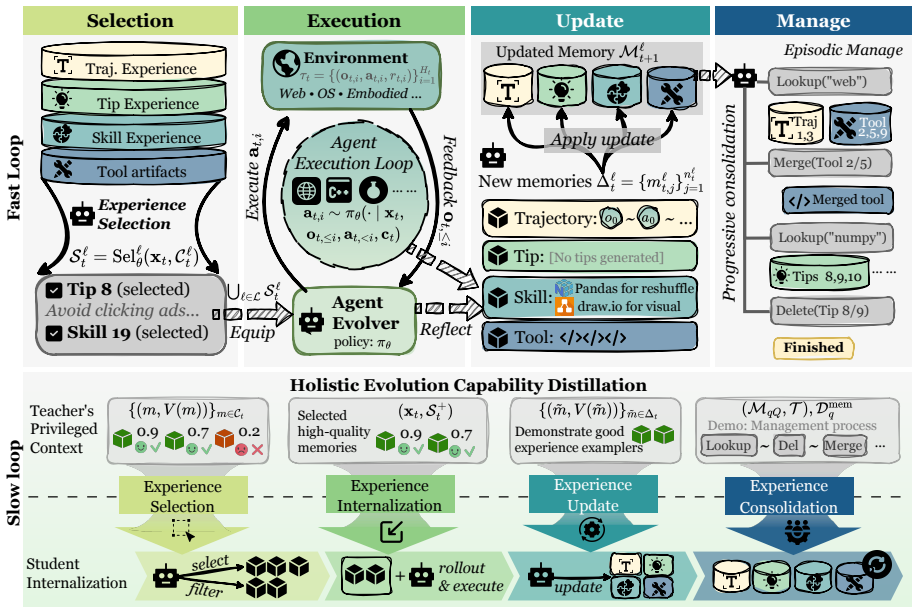
OPD-Evolver cultivates holistic agent evolvers through on-policy self-distillation in a slow-fast co-evolution framework: the fast loop interacts with a four-level memory hierarchy to read, use, write, and maintain experience for rapid test-time evolution, while the slow loop uses outcome-calibrated memory attribution and privileged hindsight to internalize these abilities in the deployable policy.
What carries the argument
The slow-fast co-evolution framework with on-policy self-distillation applied to a four-level memory hierarchy that supports read, use, write, and maintain operations.
If this is right
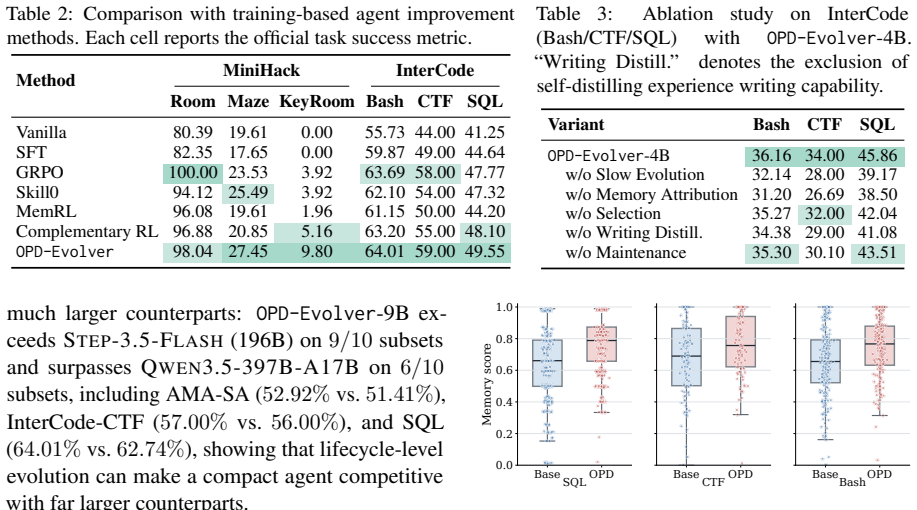
- OPD-Evolver surpasses memory systems such as ReasoningBank by up to 11.5 percent on multi-domain benchmarks.
- OPD-Evolver outperforms training-based methods such as Skill0 by approximately 5.8 percent.
- OPD-Evolver-9B challenges much larger models such as Qwen3.5-397B-A17B and Step-3.5-Flash.
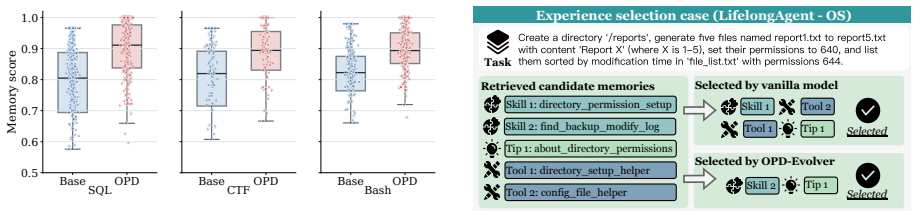
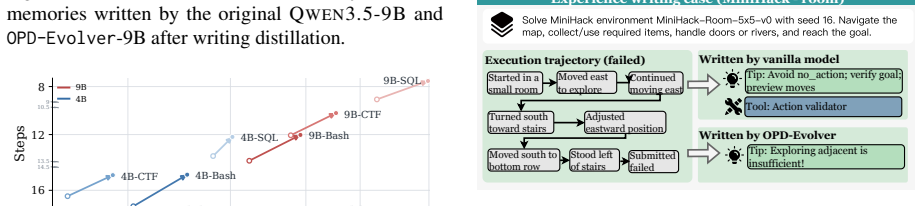
- OPD-Evolver internalizes high-value experience and memory management.
Where Pith is reading between the lines
- The distillation process could be applied to other agent behaviors such as planning or tool selection beyond memory.
- Smaller models trained this way may reduce the need for ever-larger base models in deployed agent systems.
- The framework might support continual learning across changing environments without retraining from scratch.
- Outcome calibration in the slow loop could serve as a general mechanism for attributing credit in multi-step agent trajectories.
Load-bearing premise
That outcome-calibrated memory attribution and privileged hindsight in the slow loop can reliably transfer the four abilities from fast-loop interactions into the deployable policy without domain-specific tuning or benchmark artifacts.
What would settle it
An experiment showing that OPD-Evolver produces no gains over baselines on a new domain or when the memory hierarchy is removed from the fast loop.
Figures
read the original abstract
Memory has become a standard substrate for self-evolving agents, yet retaining experience is not the same as learning how to evolve through it. Existing memory agents can store trajectories, retrieve reflections, or accumulate skills, but often lack the holistic competence to select useful experience, act on it, write reusable knowledge, and maintain a growing repository. We introduce OPD-Evolver, a slow-fast co-evolution framework that cultivates such an agent evolver through on-policy self-distillation. In the fast loop, OPD-Evolver interacts with a four-level memory hierarchy to read, use, write, and maintain experience for rapid test-time evolution. In the slow loop, outcome-calibrated memory attribution and privileged hindsight distill these four abilities into the deployable policy. Across multi-domain benchmarks, OPD-Evolver surpasses memory systems such as ReasoningBank by up to 11.5%, and training-based methods such as Skill0 by ~5.8%. Further analysis shows that OPD-Evolver internalizes high-value experience and memory management, enabling OPD-Evolver-9B to challenge giant counterparts such as Qwen3.5-397B-A17B and Step-3.5-Flash, pointing beyond memory-augmented agents toward genuinely qualified agent evolvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OPD-Evolver, a slow-fast co-evolution framework that cultivates holistic agent evolvers via on-policy self-distillation. In the fast loop, the agent interacts with a four-level memory hierarchy to read, use, write, and maintain experience. In the slow loop, outcome-calibrated memory attribution and privileged hindsight distill these four abilities into the deployable policy. Across multi-domain benchmarks, OPD-Evolver claims to surpass memory systems such as ReasoningBank by up to 11.5% and training-based methods such as Skill0 by ~5.8%, with further analysis showing internalization of high-value experience that allows a 9B model to challenge much larger models.
Significance. If the central claim holds—that on-policy distillation successfully transfers the four memory abilities into the final policy without depending on privileged hindsight signals unavailable at deployment—this would advance the field by moving beyond memory-augmented agents toward genuinely self-evolving ones. The reported gains and size comparisons would be notable if shown to be robust and mechanism-driven rather than benchmark-specific.
major comments (2)
- [Abstract] Abstract: performance numbers (11.5% over ReasoningBank, ~5.8% over Skill0) and the claim of internalization are stated without methods, data details, verification steps, or ablations; this prevents determining whether gains arise from the claimed distillation mechanism or other factors such as benchmark artifacts or the privileged slow-loop signals.
- [Method] Slow-loop description: outcome-calibrated attribution and privileged hindsight are described as distilling the four abilities (read/use/write/maintain), but no equations, fitting details, or transfer analysis are provided to assess whether these abilities are internalized by the deployable fast-loop policy or remain tied to slow-loop access; this is load-bearing for the holistic evolver claim.
minor comments (1)
- [Abstract] Abstract: 'OPD-Evolver-9B' is referenced without specifying the base model, training configuration, or how it relates to the four-level hierarchy.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below, providing clarifications from the manuscript and committing to targeted revisions that will make the distillation mechanism and its empirical support more explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (11.5% over ReasoningBank, ~5.8% over Skill0) and the claim of internalization are stated without methods, data details, verification steps, or ablations; this prevents determining whether gains arise from the claimed distillation mechanism or other factors such as benchmark artifacts or the privileged slow-loop signals.
Authors: We agree the abstract is concise and omits setup details. The reported gains come from the multi-domain experiments and ablations described in Sections 4 and 5, which compare against ReasoningBank and Skill0 while controlling for model size and training data. The internalization claim is supported by the fast-loop-only evaluations in Section 5.3. We will revise the abstract to add one sentence referencing the benchmark domains and the ablation results that attribute gains to the on-policy distillation rather than slow-loop signals at test time. revision: yes
-
Referee: [Method] Slow-loop description: outcome-calibrated attribution and privileged hindsight are described as distilling the four abilities (read/use/write/maintain), but no equations, fitting details, or transfer analysis are provided to assess whether these abilities are internalized by the deployable fast-loop policy or remain tied to slow-loop access; this is load-bearing for the holistic evolver claim.
Authors: Section 3.3 describes outcome-calibrated attribution (weighting memories by outcome delta) and privileged hindsight (generating targets unavailable at deployment). The manuscript already contains transfer experiments in Section 5.3 showing the fast-loop policy retains gains without slow-loop access. To make the mechanism load-bearing claim fully verifiable, we will add explicit equations for the attribution function and distillation loss, plus expanded quantitative transfer metrics for each of the four abilities, in the revision. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and method description outline a slow-fast co-evolution framework using on-policy self-distillation with outcome-calibrated attribution, but contain no equations, fitted parameters presented as predictions, or self-citation chains that reduce the central claims to inputs by construction. The four abilities (read/use/write/maintain) and transfer via privileged hindsight are described as empirical outcomes across benchmarks rather than derived tautologically from the inputs. No load-bearing self-definitional steps or ansatz smuggling are identifiable from the text. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.20286 , year=
Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution , author=. arXiv preprint arXiv:2505.20286 , year=
-
[2]
2026 , eprint=
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
Skill-R1: Agent Skill Evolution via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[6]
2026 , eprint=
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
OpenClaw-RL: Train Any Agent Simply by Talking , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
SOD: Step-wise On-policy Distillation for Small Language Model Agents , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
On-Policy Context Distillation for Language Models , author=. 2026 , eprint=
2026
-
[10]
2026 , eprint=
Lightning OPD: Efficient Post-Training for Large Reasoning Models with Offline On-Policy Distillation , author=. 2026 , eprint=
2026
-
[11]
2026 , eprint=
A Survey of On-Policy Distillation for Large Language Models , author=. 2026 , eprint=
2026
-
[12]
2026 , eprint=
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. 2026 , eprint=
2026
-
[13]
2024 , eprint=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. 2024 , eprint=
2024
-
[14]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[15]
2025 , eprint=
PyVision: Agentic Vision with Dynamic Tooling , author=. 2025 , eprint=
2025
-
[16]
2026 , eprint=
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis , author=. 2026 , eprint=
2026
-
[17]
2026 , eprint=
On Data Engineering for Scaling LLM Terminal Capabilities , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning , author=. 2026 , eprint=
2026
-
[19]
2026 , eprint=
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution , author=. 2026 , eprint=
2026
-
[20]
2025 , eprint=
TaskCraft: Automated Generation of Agentic Tasks , author=. 2025 , eprint=
2025
-
[21]
, author =
`DeepResearchAgent`: A Hierarchical Multi-Agent Framework for General-purpose Task Solving. , author =
-
[22]
arXiv preprint arXiv:2308.10848 , volume=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents , author=. arXiv preprint arXiv:2308.10848 , volume=
-
[23]
arXiv preprint arXiv:2310.02170 , year=
Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization , author=. arXiv preprint arXiv:2310.02170 , year=
-
[24]
2023 , eprint=
RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text , author=. 2023 , eprint=
2023
-
[25]
Embodied
Xudong Guo and Kaixuan Huang and Jiale Liu and Wenhui Fan and Natalia V. Embodied. Language Gamification - NeurIPS 2024 Workshop , year=
2024
-
[26]
, author =
`smolagents`: a smol library to build great agentic systems. , author =
-
[27]
RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems , author =. 2025 , eprint =. doi:10.48550/arXiv.2407.11005 , archiveprefix =
-
[28]
2024 , eprint=
From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models , author=. 2024 , eprint=
2024
-
[29]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[30]
2024 , eprint=
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models , author=. 2024 , eprint=
2024
-
[31]
arXiv preprint arXiv:1909.06146 , year=
Pubmedqa: A dataset for biomedical research question answering , author=. arXiv preprint arXiv:1909.06146 , year=
Pith/arXiv arXiv 1909
-
[32]
Langchain: Build context-aware reasoning applications , author =
-
[33]
Advances in Neural Information Processing Systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[35]
arXiv preprint arXiv:2310.10634 , year=
Openagents: An open platform for language agents in the wild , author=. arXiv preprint arXiv:2310.10634 , year=
-
[36]
arXiv preprint arXiv:2308.08155 , year=
Autogen: Enabling next-gen llm applications via multi-agent conversation , author=. arXiv preprint arXiv:2308.08155 , year=
-
[37]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[38]
arXiv preprint arXiv:2409.03733 , year=
Planning in natural language improves llm search for code generation , author=. arXiv preprint arXiv:2409.03733 , year=
-
[39]
BioRxiv , pages=
Cell2Sentence: teaching large language models the language of biology , author=. BioRxiv , pages=
-
[40]
bioRxiv , pages=
Evaluating the utilities of foundation models in single-cell data analysis , author=. bioRxiv , pages=. 2023 , publisher=
2023
-
[41]
Cell , volume=
Mapping transcriptomic vector fields of single cells , author=. Cell , volume=. 2022 , publisher=
2022
-
[42]
bioRxiv , pages=
A Systematic Comparison of Single-Cell Perturbation Response Prediction Models , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[43]
Bioinformatics , volume=
scPRAM accurately predicts single-cell gene expression perturbation response based on attention mechanism , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[44]
Nature methods , volume=
Causal identification of single-cell experimental perturbation effects with CINEMA-OT , author=. Nature methods , volume=. 2023 , publisher=
2023
-
[45]
Nature methods , volume=
Learning single-cell perturbation responses using neural optimal transport , author=. Nature methods , volume=. 2023 , publisher=
2023
-
[46]
Nature biotechnology , volume=
Cell type prioritization in single-cell data , author=. Nature biotechnology , volume=. 2021 , publisher=
2021
-
[47]
2024 , eprint=
Symbolic Learning Enables Self-Evolving Agents , author=. 2024 , eprint=
2024
-
[48]
2023 , eprint=
Agents: An Open-source Framework for Autonomous Language Agents , author=. 2023 , eprint=
2023
-
[49]
2021 , eprint=
MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research , author=. 2021 , eprint=
2021
-
[50]
2023 , eprint=
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback , author=. 2023 , eprint=
2023
-
[51]
2026 , eprint=
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications , author=. 2026 , eprint=
2026
-
[52]
cell , volume=
Perturb-Seq: dissecting molecular circuits with scalable single-cell RNA profiling of pooled genetic screens , author=. cell , volume=. 2016 , publisher=
2016
-
[53]
Nature , volume=
Dissecting cell identity via network inference and in silico gene perturbation , author=. Nature , volume=. 2023 , publisher=
2023
-
[54]
Bioinformatics , volume=
AttentionPert: accurately modeling multiplexed genetic perturbations with multi-scale effects , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[55]
Nature Biotechnology , volume=
Predicting transcriptional outcomes of novel multigene perturbations with GEARS , author=. Nature Biotechnology , volume=. 2024 , publisher=
2024
-
[56]
Molecular systems biology , volume=
Predicting cellular responses to complex perturbations in high-throughput screens , author=. Molecular systems biology , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Predicting cellular responses to novel drug perturbations at a single-cell resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Nature methods , volume=
scGen predicts single-cell perturbation responses , author=. Nature methods , volume=. 2019 , publisher=
2019
-
[59]
Nature methods , volume=
Large-scale foundation model on single-cell transcriptomics , author=. Nature methods , volume=. 2024 , publisher=
2024
-
[60]
bioRxiv , pages=
Perteval-scfm: Benchmarking single-cell foundation models for perturbation effect prediction , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[61]
bioRxiv , pages=
Benchmarking AI Models for In Silico Gene Perturbation of Cells , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[62]
Nature Reviews Methods Primers , volume=
High-content CRISPR screening , author=. Nature Reviews Methods Primers , volume=. 2022 , publisher=
2022
-
[63]
Advances in Neural Information Processing Systems , volume=
A benchmark for prediction of transcriptomic responses to chemical perturbations across cell types , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
2023 , howpublished =
Daniel Burkhardt and Andrew Benz and Richard Lieberman and Scott Gigante and Ashley Chow and Ryan Holbrook and Robrecht Cannoodt and Malte Luecken , title =. 2023 , howpublished =
2023
-
[65]
arXiv preprint arXiv:2204.11817 , year=
Translation between molecules and natural language , author=. arXiv preprint arXiv:2204.11817 , year=
-
[66]
2024 , publisher=
Peidli, Stefan and Green, Tessa D and Shen, Ciyue and Gross, Torsten and Min, Joseph and Garda, Samuele and Yuan, Bo and Schumacher, Linus J and Taylor-King, Jake P and Marks, Debora S and others , journal=. 2024 , publisher=
2024
-
[67]
Benchmarking Transcriptomics Foundation Models for Perturbation Analysis: one PCA still rules them all , author =. 2024 , month =. arXiv , primaryclass =:arXiv:2410.13956 , doi =
arXiv 2024
-
[68]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery , author =. 2024 , month =. arXiv , primaryclass =:arXiv:2408.06292 , doi =
Pith/arXiv arXiv 2024
-
[69]
The Virtual Lab: AI Agents Design New SARS-CoV-2 Nanobodies with Experimental Validation , author =. 2024 , month =. doi:10.1101/2024.11.11.623004 , url =
-
[70]
scGPT: toward building a foundation model for single-cell multi-omics using generative AI , author =. Nature Methods , volume =. 2024 , month =. doi:10.1038/s41592-024-02201-0 , issn =
-
[71]
Theodoris, Ling Xiao, Adit Chopra, Mark D
Transfer learning enables predictions in network biology , author =. Nature , volume =. 2023 , month =. doi:10.1038/s41586-023-06139-9 , url =
-
[72]
arXiv preprint arXiv:2005.11280 , year =
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author =. arXiv preprint arXiv:2005.11280 , year =
arXiv 2005
-
[73]
arXiv:1908.10084 [cs] , note =
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author =. arXiv:1908.10084 [cs] , note =. 2019 , month =
Pith/arXiv arXiv 1908
-
[74]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author =. 2023 , month =. arXiv , primaryclass =:arXiv:2306.05685 , doi =
Pith/arXiv arXiv 2023
-
[75]
Xingyao Wang and Boxuan Li and Yufan Song and Frank F. Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H. Tran and Fuqiang Li and Ren Ma and Mingzhang Zheng and Bill Qian and Yanjun Shao and Niklas Muennighoff and Yizhe Zhang and Binyuan Hui and Junyang Lin and Robert Brennan and Hao Peng and H...
-
[76]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges , author =. 2024 , month =. arXiv , primaryclass =:arXiv:2402.01680 , doi =
Pith/arXiv arXiv 2024
-
[77]
Cell , volume=
Perturb-Seq: Dissecting molecular circuits with single-cell RNA-seq of pooled genetic screens , author=. Cell , volume=. 2016 , publisher=
2016
-
[78]
Genome biology , volume=
Cell-type-specific perturbation response prediction using single-cell rna-seq , author=. Genome biology , volume=. 2021 , publisher=
2021
-
[79]
Genome biology , volume=
scGen: single-cell gene expression prediction through deep learning , author=. Genome biology , volume=. 2019 , publisher=
2019
-
[80]
Briefings in bioinformatics , volume=
Predicting single-cell perturbation responses using deep learning with application to covid-19 , author=. Briefings in bioinformatics , volume=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.