Teacher-Free Self-Training Amplifies but Does Not Compound: A Pass@K Crossover on a Free-Verifier Domain
Pith reviewed 2026-06-27 22:25 UTC · model grok-4.3
The pith
Self-training on verified outputs concentrates probability mass without expanding reachable capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
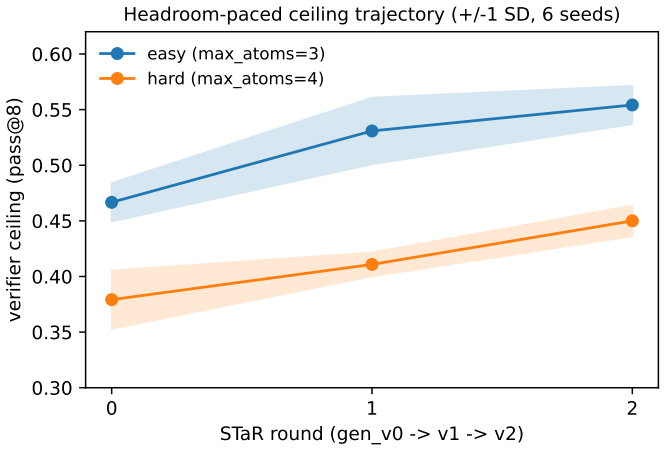
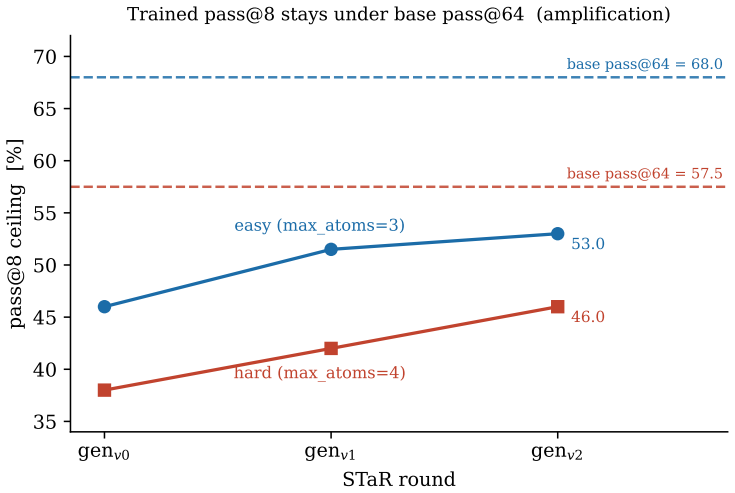
The domain lacks a clean zero-capability frontier. Per-round STaR self-training raises the ceiling but never accelerates, with the gain tracking remaining headroom and decelerating across K=4 trajectories. A measured pass@K crossover settles the diagnosis: the trained model wins at the operating budget (pass@8) but the base overtakes it at a large budget (pass@64) on every trajectory, so self-training concentrates probability mass rather than expanding reach. This is amplification, not compounding.
What carries the argument
The pass@K crossover diagnostic, which compares performance at low versus high sampling budgets to separate concentration of existing probability mass from expansion of reachable solutions.
If this is right
- Critic-guided selection beats verifier-filtered best-of-k by +9.1 pp, with gains localized to tasks where candidates disagree on held-out inputs.
- Self-training gains track remaining headroom and decelerate across independent training trajectories.
- The lack of a zero-capability frontier invalidates the usual 0% to climb test for emergence.
- Self-training produces amplification at operating budgets without compounding new reach.
Where Pith is reading between the lines
- The same crossover test could be applied in other domains that admit free exact verifiers to check for true compounding.
- If concentration dominates, repeated self-training rounds without external signals may plateau even when headroom remains.
- The result suggests self-improvement loops may need mechanisms that actively enlarge the reachable set rather than reweighting existing mass.
Load-bearing premise
The pass@K crossover is a valid diagnostic that distinguishes concentration of probability mass from expansion of reachable capability rather than reflecting domain-specific sampling effects.
What would settle it
Observing the trained model maintaining or widening its lead over the base model at pass@64 and higher budgets across trajectories would falsify the concentration claim.
Figures
read the original abstract
When a language model trains on its own verified outputs, does it acquire capability beyond its base, or merely get better at expressing capability the base already had? We make the question decidable with a teacher-free "constellation" -- a generator, a learned critic, and a free exact verifier -- on a FlashFill-style "trapdoor" DSL, where verified (problem, solution) pairs are cheap to synthesize, hard to invert, and free to check exactly. Everything runs on one 4-bit Qwen3-4B on a single 24 GB GPU, with no model in the loop larger than the base. We report three findings. (i) Critic-guided selection beats verifier-filtered best-of-$k$ by $+9.1$ pp ($6/6$ seeds), with the entire gain localized to tasks where candidates disagree on held-out inputs. (ii) Per-round STaR self-training raises the ceiling but never accelerates -- the gain tracks remaining headroom and decelerates across $K=4$ independent training trajectories. (iii) The domain has no clean zero-capability frontier, so the usual "$0\% \to$ climb $=$ emergence" test is invalid here. A measured pass@$K$ crossover settles the diagnosis: the trained model wins at the operating budget (pass@$8$) but the base overtakes it at a large budget (pass@$64$) on every trajectory, so self-training concentrates probability mass rather than expanding reach. This is amplification, not compounding. ($K=4$ is indicative, not yet a robust across-trajectory CI.)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that teacher-free self-training on verified outputs in a constellation (generator + learned critic + free exact verifier) on a trapdoor DSL amplifies by concentrating probability mass rather than compounding by expanding reachable capability. This is diagnosed via three findings: critic-guided selection outperforms verifier-filtered best-of-k by +9.1 pp across 6/6 seeds; per-round STaR raises ceiling but decelerates without acceleration; and a pass@K crossover where the trained model wins at pass@8 but the base overtakes at pass@64 on all trajectories, with the domain lacking a clean zero frontier.
Significance. If the pass@K crossover is shown to isolate concentration from domain sampling artifacts, the work supplies a concrete empirical test for distinguishing amplification from compounding in self-training, with direct relevance to interpreting scaling and self-improvement results. The fully contained single-GPU setup (4-bit Qwen3-4B, no larger model) is a practical strength for reproducibility.
major comments (2)
- [Abstract] Abstract: The central diagnosis that the observed pass@K crossover demonstrates concentration of mass rather than expansion of reach rests on the untested assumption that the crossover cannot arise from trapdoor DSL problem distribution, verifier properties, or critic-guided selection altering support independently of capability expansion; no ablation or control experiment is described to rule out these alternatives.
- [Abstract] Abstract: The +9.1 pp gain for critic-guided selection is reported as consistent across 6/6 seeds and K=4 trajectories, yet the text provides neither error bars, exact dataset sizes, nor any statistical test; without these the reliability of the localized gain on disagreeing tasks cannot be evaluated and the claim remains under-supported.
minor comments (1)
- [Abstract] The parenthetical note that 'K=4 is indicative, not yet a robust across-trajectory CI' should be expanded with a methods subsection detailing how trajectories were generated and why four is treated as sufficient for the crossover pattern.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation for major revision. We address each major comment below, agreeing where the manuscript is under-supported and outlining targeted revisions. The pass@K crossover remains our central empirical contribution, but we accept the need to better justify its interpretation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central diagnosis that the observed pass@K crossover demonstrates concentration of mass rather than expansion of reach rests on the untested assumption that the crossover cannot arise from trapdoor DSL problem distribution, verifier properties, or critic-guided selection altering support independently of capability expansion; no ablation or control experiment is described to rule out these alternatives.
Authors: The referee is correct that the manuscript presents no explicit ablation or control to isolate the pass@K crossover from possible artifacts of the trapdoor DSL distribution, verifier mechanics, or critic selection. The design rationale (free exact verifier + trapdoor problems where verified pairs are cheap to generate but hard to invert) was intended to reduce such confounds, and the crossover appears uniformly across all four trajectories, but this does not constitute a direct test. We will add a dedicated limitations subsection discussing these alternatives and include at least one control (e.g., a non-trapdoor variant or randomized verifier) if compute permits; otherwise we will qualify the claim more explicitly as suggestive rather than conclusive. revision: partial
-
Referee: [Abstract] Abstract: The +9.1 pp gain for critic-guided selection is reported as consistent across 6/6 seeds and K=4 trajectories, yet the text provides neither error bars, exact dataset sizes, nor any statistical test; without these the reliability of the localized gain on disagreeing tasks cannot be evaluated and the claim remains under-supported.
Authors: We agree the current presentation is under-supported. The +9.1 pp figure is the mean improvement; the gain was observed in every seed, but we omitted standard deviations, exact task counts per split, and any formal test. In revision we will report per-seed values with standard error, state the precise number of tasks and held-out inputs, and add a brief note on consistency (or a paired t-test if appropriate). This change affects both the abstract and the corresponding results paragraph. revision: yes
Circularity Check
No significant circularity; all claims rest on direct empirical measurements
full rationale
The paper reports three findings based on direct empirical measurements of pass@K performance on held-out tasks using a free exact verifier in a trapdoor DSL. No equations, fitted parameters, or self-citations are used to derive the central claim; the pass@K crossover is presented as an observed pattern across trajectories rather than a quantity defined in terms of itself or prior author work. The derivation chain is self-contained against external benchmarks with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Verified (problem, solution) pairs are cheap to synthesize, hard to invert, and free to check exactly.
- domain assumption The learned critic provides selection gains localized to tasks where candidates disagree on held-out inputs.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Zico Kolter, and Aditi Raghunathan
Xingyu Dang, Christina Baek, Kaiyue Wen, J. Zico Kolter, and Aditi Raghunathan. Weight ensembling improves reasoning in language models, 2025. arXiv:2504.10478
-
[3]
Differential smoothing mitigates sharpening and improves LLM reasoning, 2025
Jingchu Gai, Guanning Zeng, Huaqing Zhang, and Aditi Raghunathan. Differential smoothing mitigates sharpening and improves LLM reasoning, 2025. arXiv:2511.19942
-
[4]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Ab- hishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, and Nando de Freitas. Reinforced self-training (ReST) for lan- guage modeling, 2023. arXiv:2308.08998
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Multivariate amortized resource analysis
Sumit Gulwani. Automating string processing in spreadsheets using input-output examples. In Proceedings of the 38th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL), pages 317–330, 2011. doi: 10.1145/1926385.1926423
-
[6]
Rewarding the unlikely: Lifting GRPO beyond distribution sharpening
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting GRPO beyond distribution sharpening. InProceedings of EMNLP, 2025. arXiv:2506.02355
-
[7]
arXiv preprint arXiv:2509.02534 , year=
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations, 2025. arXiv:2509.02534
-
[8]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, et al. ProRL: Prolonged reinforcement learning expands reasoning boundaries in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2505.24864; NVIDIA. 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Qwen Team. Qwen3 technical report, 2025. arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models, 2023. Rejection-sampling fine-tuning (RFT); arXiv:2308.01825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2504.13837
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.