From Intent to AI Pipelines: A Controlled Agentic Framework for Non-AI Expert Scientists
Pith reviewed 2026-05-21 09:22 UTC · model grok-4.3
The pith
A four-stage framework lets non-AI scientists build competitive pipelines from their own intent using large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
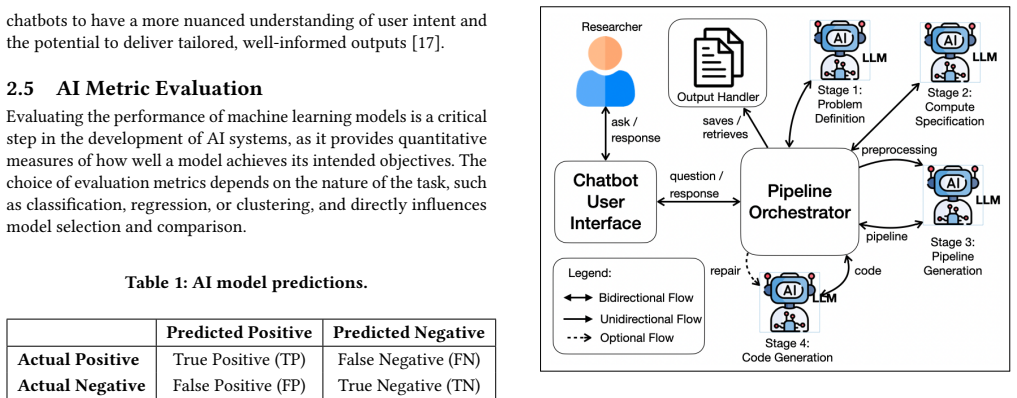
DDAP structures the development process into four stages of guided interaction that adapt to domain context, user expertise, and resource constraints while maintaining user control over key decisions. When evaluated across multiple datasets spanning business, biology, and health science domains by comparing its AI models against expert-developed models, the framework achieves competitive results in several tasks, although performance varies across problem types, particularly for text-based clustering tasks.
What carries the argument
The four-stage controlled agentic process of DDAP, which uses large language models to interpret user intent and generate pipeline structures and code while preserving human oversight at each stage.
If this is right
- Domain scientists in medicine, agriculture, and social sciences can create and run their own predictive models and data analyses without hiring AI specialists.
- The staged structure improves reproducibility by logging each decision and adaptation step.
- Performance remains competitive for many supervised and regression tasks but shows clear gaps on unsupervised text clustering.
- Resource constraints can be incorporated early so the generated code respects available compute limits.
Where Pith is reading between the lines
- If language-model reliability improves on intent interpretation, the framework could reduce the remaining performance gaps without changing its core structure.
- The same staged, controllable approach might transfer to other technical workflows such as experimental protocol design or simulation setup.
- Adding explicit validation checks after each stage could make the system more robust for production use by non-experts.
Load-bearing premise
Large language models can reliably interpret user-provided domain context and intent to produce correct pipeline structures and code without introducing systematic errors that would require extensive human debugging.
What would settle it
A direct head-to-head comparison on new text-clustering datasets where non-expert users run DDAP to completion and the resulting model accuracy is measured against expert baselines on identical data splits.
Figures











read the original abstract
Artificial Intelligence (AI) pipelines have become integral to modern research, supporting fields such as Medical Sciences, Agriculture, and Social Sciences, and enabling large-scale data analysis, predictive modeling, and the automation of complex tasks. However, designing and implementing AI solutions remains challenging for many researchers due to the expertise required in the design and development of end-to-end AI systems. To address this gap, we present Domain-Driven Adaptable AI Pipelines (DDAP), a controlled, human-in-the-loop, agentic framework that leverages large language models to guide users in a systematic construction of AI pipelines and their corresponding implementation code. DDAP structures the development process into four stages: problem definition, compute environment specification, pipeline generation, and code generation. Through this staged interaction, the framework adapts to domain context, user expertise, and resource constraints, while maintaining user control over key decisions. We evaluate DDAP across multiple datasets spanning business, biology, and health science domains by comparing its AI models against expert-developed models. The experimental results show that DDAP achieves competitive results in several tasks compared to expert baselines, although performance varies across problem types, particularly for text-based clustering tasks. By combining guided interaction, adaptability, and reproducibility, DDAP demonstrates that a controlled agentic framework can generate competitive AI pipelines for non-expert users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Domain-Driven Adaptable AI Pipelines (DDAP), a controlled human-in-the-loop agentic framework that uses large language models to help non-AI expert scientists build AI pipelines and implementation code. The process is divided into four stages: problem definition, compute environment specification, pipeline generation, and code generation. The framework is evaluated on datasets from business, biology, and health science domains, where it is reported to achieve competitive results compared to expert baselines, with noted variations in performance across different problem types, especially text-based clustering tasks.
Significance. If the results hold under rigorous quantitative evaluation, DDAP could be significant in lowering barriers for domain scientists to adopt AI techniques, fostering greater reproducibility and adaptability in research across various fields. The human-in-the-loop aspect ensures user control, which is a positive design choice for practical usability.
major comments (2)
- [Evaluation] The manuscript claims that 'the experimental results show that DDAP achieves competitive results in several tasks compared to expert baselines' but does not include any quantitative metrics, error bars, dataset details, or statistical tests. This is a load-bearing issue for the central claim as it prevents verification of competitiveness.
- [Human-in-the-Loop Aspects] Given that DDAP is explicitly a human-in-the-loop framework allowing user control at each stage, the paper should detail the extent of human interventions, such as corrections to LLM-generated pipelines or code, required to reach the reported performance levels. Without this, the attribution of results to the agentic component remains unclear.
minor comments (1)
- [Abstract] The abstract mentions performance variation by task type but does not explain the reasons for underperformance in text-based clustering tasks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript describing the DDAP framework. The comments identify important areas for strengthening the evaluation and clarifying the human-in-the-loop contributions. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Evaluation] The manuscript claims that 'the experimental results show that DDAP achieves competitive results in several tasks compared to expert baselines' but does not include any quantitative metrics, error bars, dataset details, or statistical tests. This is a load-bearing issue for the central claim as it prevents verification of competitiveness.
Authors: We acknowledge that the current version of the manuscript presents the competitiveness claim at a high level without sufficient supporting quantitative evidence. The full experimental section compares DDAP outputs to expert baselines across business, biology, and health domains but omits explicit metrics, variability measures, dataset specifications, and statistical analysis. We will add a revised evaluation section that includes performance tables with metrics such as accuracy, precision, recall, or clustering scores as appropriate; error bars or standard deviations from repeated runs where applicable; complete dataset descriptions including sizes, sources, and preprocessing steps; and statistical tests (e.g., paired t-tests or non-parametric equivalents) to substantiate the 'competitive' characterization. This revision will enable independent verification of the results. revision: yes
-
Referee: [Human-in-the-Loop Aspects] Given that DDAP is explicitly a human-in-the-loop framework allowing user control at each stage, the paper should detail the extent of human interventions, such as corrections to LLM-generated pipelines or code, required to reach the reported performance levels. Without this, the attribution of results to the agentic component remains unclear.
Authors: We agree that quantifying human interventions is necessary to properly attribute performance to the agentic framework versus user guidance. The manuscript describes the four-stage process and user control but does not report the frequency or nature of interventions observed during evaluation. In the revision, we will include a new subsection on human-in-the-loop usage that reports, based on our experimental logs, the average number of user corrections or refinements per stage, representative examples of interventions (such as adjusting problem definitions or validating generated code), and an analysis of how these interventions influenced final pipeline performance. This will provide clearer insight into the balance between automation and human oversight. revision: yes
Circularity Check
No significant circularity: evaluation uses external expert baselines
full rationale
The paper presents DDAP as a four-stage human-in-the-loop framework and supports its claims through direct empirical comparison of generated pipelines against independently developed expert baselines on external datasets from business, biology, and health-science domains. No mathematical derivations, equations, fitted parameters, or predictions are defined; the performance claims rest on external benchmarks rather than any self-referential construction or self-citation chain. The evaluation is therefore self-contained against independent references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can accurately interpret domain-specific user intent and generate appropriate AI pipeline structures and code.
Reference graph
Works this paper leans on
-
[1]
Oguz Akbilgic. 2013. ISTANBUL STOCK EXCHANGE. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C54P4J
-
[2]
Oguz Akbilgic, Hamparsum Bozdogan, and M Erdal Balaban. 2014. A novel hybrid RBF neural networks model as a forecaster.Statistics and Computing24, 3 (2014), 365–375
work page 2014
-
[3]
Leonidas Akritidis. 2020. Product Classification and Clustering. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5M91Z
-
[4]
Leonidas Akritidis, Athanasios Fevgas, and Panayiotis Bozanis. 2018. Effective products categorization with importance scores and morphological analysis of the titles. In2018 IEEE 30th international conference on tools with artificial intelligence (ICTAI). IEEE, 213–220
work page 2018
-
[5]
Leonidas Akritidis, Athanasios Fevgas, Panayiotis Bozanis, and Christos Makris
-
[6]
A self-verifying clustering approach to unsupervised matching of product titles.Artificial Intelligence Review53, 7 (2020), 4777–4820
work page 2020
-
[7]
Răzvan Daniel Albu and Florin Lucian Morgoş. 2025. AI-Assisted Low-Code Plat- forms in Modern Research. In2025 18th International Conference on Engineering of Modern Electric Systems (EMES). IEEE, 1–4
work page 2025
-
[8]
Anonymous, Anonymous, and Anonymous. 2026. AI Pipeline Generation for Sci- entists Without AI Expertise Using a Controlled Agentic Framework (Replication Package). doi:10.5281/zenodo.19241799
-
[9]
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. 2024. A Survey on RAG with LLMs.Procedia computer science246 (2024), 3781–3790
work page 2024
- [10]
-
[11]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for hyper-parameter optimization.Advances in neural information processing systems24 (2011)
work page 2011
-
[12]
Alexander C Bock and Ulrich Frank. 2021. Low-code platform.Business & Information Systems Engineering63, 6 (2021), 733–740
work page 2021
-
[13]
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Pe- ter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. 2012. A survey of Monte Carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in Games4, 1 (2012), 1–43. doi:10.1109/TCIAIG.2012.2186810
-
[15]
Daqing Chen. 2015. Online Retail. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5BW33
-
[16]
Daqing Chen, Sai Laing Sain, and Kun Guo. 2012. Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining.Journal of Database Marketing & Customer Strategy Management 19, 3 (2012), 197–208
work page 2012
-
[17]
Cursor. 2025.Built to make you extraordinarily productive, Cursor is the best way to code with AI.Retrieved September 29, 2025 from https://cursor.com/
work page 2025
-
[18]
Stefano D’Urso, Barbara Martini, and Filippo Sciarrone. 2024. A Novel LLM Architecture for Intelligent System Configuration. In2024 28th International Conference Information Visualisation (IV). IEEE, 326–331
work page 2024
-
[19]
Unai Garciarena, Roberto Santana, and Alexander Mendiburu. 2018. Analysis of the complexity of the automatic pipeline generation problem. In2018 IEEE Congress on Evolutionary Computation (CEC). IEEE, 1–8
work page 2018
-
[20]
M Ghanem, AK Ghaith, VG El-Hajj, A Bhandarkar, A de Giorgio, A Elmi-Terander, et al. [n. d.]. Limitations in evaluating machine learning models for imbalanced binary outcome classification in spine surgery: A systematic review. Brain Sci. 2023; 13 (12): 1723
work page 2023
-
[21]
GitHub. 2025.AI that builds with you. Retrieved September 29, 2025 from https://github.com/features/copilot
work page 2025
-
[22]
Manuel Goyanes, Carlos Lopezosa, and Valeriano Piñeiro-Naval. 2025. The use of artificial intelligence (AI) in research: a review of author guidelines in leading journals across eight social science disciplines.Scientometrics(2025), 1–17
work page 2025
-
[23]
Yang Gu, Hengyu You, Jian Cao, Muran Yu, Haoran Fan, and Shiyou Qian. 2025. Large language models for constructing and optimizing machine learning work- flows: A survey.ACM Transactions on Software Engineering and Methodology (2025)
work page 2025
-
[24]
Yuval Heffetz, Roman Vainshtein, Gilad Katz, and Lior Rokach. 2020. Deepline: Automl tool for pipelines generation using deep reinforcement learning and hierarchical actions filtering. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2103–2113
work page 2020
-
[25]
2026.UCI Machine Learning Repository
University of California Irvine. 2026.UCI Machine Learning Repository. Retrieved March 16, 2026 from https://archive.ics.uci.edu/
work page 2026
-
[26]
Muhammad Tanvirul Islam. 2024. Jute Pest. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5289P
-
[27]
Muhammad Tanvirul Islam and Md Sadekur Rahman. 2024. An efficient deep learning approach for jute pest classification using transfer learning. In2024 6th International Conference on Electrical Engineering and Information & Communica- tion Technology (ICEEICT). IEEE, 1473–1478
work page 2024
-
[28]
Sathvik Joel, Jie Wu, and Fatemeh Fard. 2024. A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[29]
Osama Khan, Mohd Parvez, Pratibha Kumari, Samia Parvez, and Shadab Ahmad
-
[30]
The future of pharmacy: how AI is revolutionizing the industry.Intelligent Pharmacy1, 1 (2023), 32–40
work page 2023
-
[31]
Richard Koch. 2011.The 80/20 Principle: The Secret of Achieving More with Less: Updated 20th anniversary edition of the productivity and business classic. Hachette UK
work page 2011
-
[32]
Yulia Kumar, Wenxiao Li, Kuan Huang, Michael Thompson, and Brendan Hannon
-
[33]
Natural Language Coding (NLC) for Autonomous Stock Trading: A New Dimension in No-Code/Low-Code (NCLC) AI. In2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security Companion (QRS-C). IEEE, 873–874
-
[34]
DonHee Lee and Seong No Yoon. 2021. Application of artificial intelligence- based technologies in the healthcare industry: Opportunities and challenges. International journal of environmental research and public health18, 1 (2021), 271
work page 2021
-
[35]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
work page 2020
-
[36]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys55, 9 (2023), 1–35
work page 2023
-
[37]
Kritin Maddireddy, Santhosh Kotekal Methukula, Chandrasekar Sridhar, and Karthik Vaidhyanathan. 2025. LoCoML: A Framework for Real-World ML Infer- ence Pipelines. In2025 IEEE/ACM 4th International Conference on AI Engineering– Software Engineering for AI (CAIN). IEEE, 83–88
work page 2025
-
[38]
Eder Martinez and Diego Cisterna. 2023. Using low-code and artificial intelligence to support continuous improvement in the construction industry. InProceedings of the 31st Annual Conference of the International Group for Lean Construction (IGLC31). 197–207
work page 2023
-
[39]
2025.Introducing Code Llama, a state-of-the-art large language model for coding
Meta. 2025.Introducing Code Llama, a state-of-the-art large language model for coding. Retrieved September 16, 2025 from https://ai.meta.com/blog/code-llama- large-language-model-coding/
work page 2025
-
[40]
Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heintz, and Dan Roth. 2023. Recent advances in natural language processing via large pre-trained language models: A survey.Comput. Surveys56, 2 (2023), 1–40
work page 2023
-
[41]
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey.arXiv preprint arXiv:2402.06196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Vinith Kumar Nair, R Harikrishnan, S Anjali, Kavya Gopan, et al. 2024. Barriers to AI Adoption in Sales: Challenges and Implications for Sales Professionals Using the Total Interpretive Structural Modelling (TISM) Approach. In2024 IEEE 4th International Conference on ICT in Business Industry & Government (ICTBIG). IEEE, 1–5
work page 2024
-
[43]
Bentley James Oakes, Michalis Famelis, and Houari Sahraoui. 2024. Building domain-specific machine learning workflows: A conceptual framework for the state of the practice.ACM Transactions on Software Engineering and Methodology 33, 4 (2024), 1–50
work page 2024
-
[44]
Cecilia B Öman and Christian Junestedt. 2008. Chemical characterization of landfill leachates–400 parameters and compounds.Waste management28, 10 (2008), 1876–1891
work page 2008
-
[45]
Gunjan Paliwal, Anujkumarsinh Donvir, Praveen Gujar, and Sriram Panyam
-
[46]
In 2024 IEEE Eighth Ecuador Technical Chapters Meeting (ETCM)
Low-code/no-code meets GenAI: A new era in product development. In 2024 IEEE Eighth Ecuador Technical Chapters Meeting (ETCM). IEEE, 1–9
work page 2024
-
[47]
Deven Panchal, Isilay Baran, Dan Musgrove, and David Lu. 2023. MLOps: Creat- ing powerful AI pipelines by stitching together heterogeneous Machine Learning models. In2023 IEEE International Conference on Technology Management, Opera- tions and Decisions (ICTMOD). IEEE, 1–6
work page 2023
- [48]
-
[49]
K Satyanarayan Reddy, Rajesh Gotur, and Vandana Bhat. 2025. Generative AI Adoption in Enterprise: A Comprehensive Case Study Analysis of Implementa- tion Strategies and Outcomes Across Diverse Sectors. In2025 6th International Conference on Recent Advances in Information Technology (RAIT). IEEE, 1–6
work page 2025
-
[50]
Zhao Ru-tao, Wang Jing, Chen Gao-jian, Li Qian-wen, and Yuan Yun-jing. 2020. A Machine learning pipeline generation approach for data analysis. In2020 IEEE 6th International Conference on Computer and Communications (ICCC). IEEE, 1488–1493
work page 2020
-
[51]
Ripon K Saha, Akira Ura, Sonal Mahajan, Chenguang Zhu, Linyi Li, Yang Hu, Hiroaki Yoshida, Sarfraz Khurshid, and Mukul R Prasad. 2022. SapientML: syn- thesizing machine learning pipelines by learning from human-writen solutions. 11 InProceedings of the 44th international conference on software engineering. 1932– 1944
work page 2022
-
[52]
Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models.Nature623, 7987 (2023), 493–498
work page 2023
-
[53]
Zeyuan Shang, Emanuel Zgraggen, Benedetto Buratti, Ferdinand Kossmann, Philipp Eichmann, Yeounoh Chung, Carsten Binnig, Eli Upfal, and Tim Kraska
-
[54]
InProceedings of the 2019 international conference on management of data
Democratizing data science through interactive curation of ml pipelines. InProceedings of the 2019 international conference on management of data. 1171– 1188
work page 2019
-
[55]
Jayasankar Shyam, Cyril K Sony, Aswin Jeev Johny, Basil Siby, and Jacob Thomas
-
[56]
In 2025 Emerging Technologies for Intelligent Systems (ETIS)
Bridging the Gap for Non-Programmers with No-Code ML Solutions. In 2025 Emerging Technologies for Intelligent Systems (ETIS). IEEE, 1–5
work page 2025
-
[57]
Sam Single, Saeid Iranmanesh, and Raad Raad. 2023. RealWaste. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5SS4G
-
[58]
Sam Single, Saeid Iranmanesh, and Raad Raad. 2023. Realwaste: a novel real-life data set for landfill waste classification using deep learning.Information14, 12 (2023), 633
work page 2023
-
[59]
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. 2012. Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems25 (2012)
work page 2012
-
[60]
Vladimir Sonkin and Cătălin Tudose. 2025. Beyond Snippet Assistance: A Workflow-Centric Framework for End-to-End AI-Driven Code Generation.Com- puters14, 3 (2025), 94
work page 2025
-
[61]
Maojun Sun, Ruijian Han, Binyan Jiang, Houduo Qi, Defeng Sun, Yancheng Yuan, and Jian Huang. 2025. Lambda: A large model based data agent.J. Amer. Statist. Assoc.(2025), 1–13
work page 2025
-
[62]
Athanasios Tsanas and Max Little. 2009. Parkinsons Telemonitoring. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5ZS3N
-
[63]
Athanasios Tsanas, Max Little, Patrick McSharry, and Lorraine Ramig. 2009. Accurate telemonitoring of Parkinson’s disease progression by non-invasive speech tests.Nature Precedings(2009), 1–1
work page 2009
-
[64]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
-
[65]
Yujing Yang, Boqi Chen, Kua Chen, Gunter Mussbacher, and Dániel Varró. 2024. Multi-step iterative automated domain modeling with large language models. InProceedings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems. 587–595
work page 2024
-
[66]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
work page 2022
-
[67]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2024. Retrieval- augmented generation for ai-generated content: A survey.arXiv preprint arXiv:2402.19473(2024). 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.