PreAct: Computer-Using Agents that Get Faster on Repeated Tasks
Pith reviewed 2026-06-27 01:03 UTC · model grok-4.3
The pith
PreAct compiles successful agent runs into state-machine programs that replay tasks faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
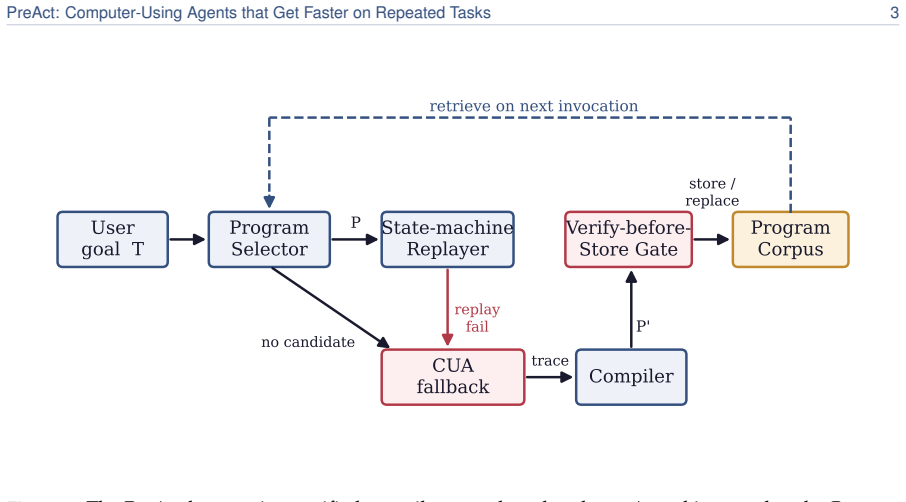
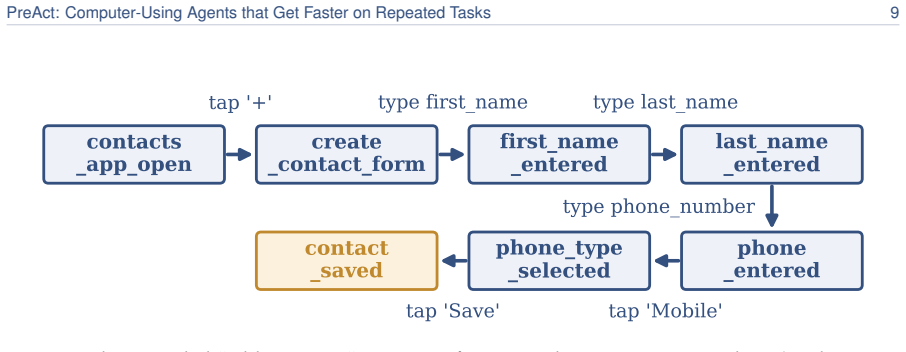
PreAct compiles the run into a small state-machine program—states that check the screen, transitions that act—and on later runs replays it directly instead of invoking the agent. Replay checks that the screen matches expectations before acting and returns control to the agent if something is off. A program enters the store only if an independent evaluator run from a clean state confirms it solved the task.
What carries the argument
The compiled state-machine program that encodes screen checks and actions from a successful run, enabling direct replay with verification.
If this is right
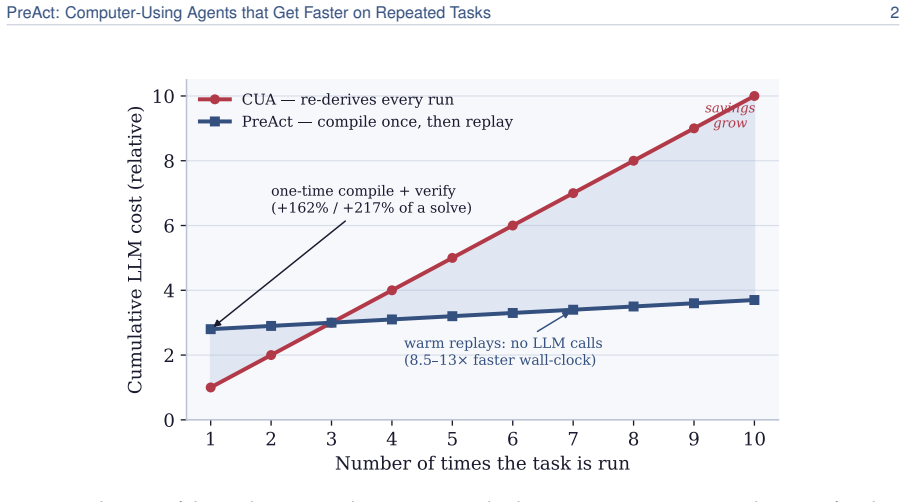
- Agents achieve 8.5-13x faster execution on repeated tasks with no per-step language model calls.
- An independent evaluator from clean state filters out programs that fail to complete the task despite matching final screen.
- This filtering keeps performance improving rather than degrading across repeated uses on benchmarks.
- A fallback to fresh agent exploration when no matching program exists achieves parity with record-and-replay baselines.
- Selection of which program to reuse is insensitive to prompt wording, runtime guardrails, or whether using language model or embedding retriever.
Where Pith is reading between the lines
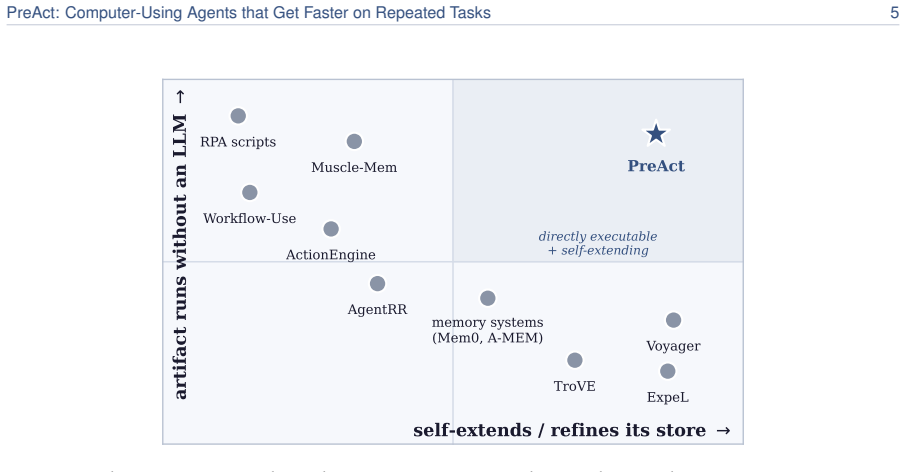
- The stored programs could form a growing library of optimized routines for common software tasks across users.
- This compilation approach might apply to other sequential decision tasks where verification of state is possible.
- Long-term use could reduce overall compute costs for agent-based automation significantly.
Load-bearing premise
An independent evaluator started from a clean state can reliably detect if the compiled program actually solved the task instead of just reaching the final screen state while leaving the goal incomplete.
What would settle it
Observe whether the independent evaluator accepts a program that reaches the final screen but fails to complete the underlying task goal, such as filling a form but not submitting it.
Figures

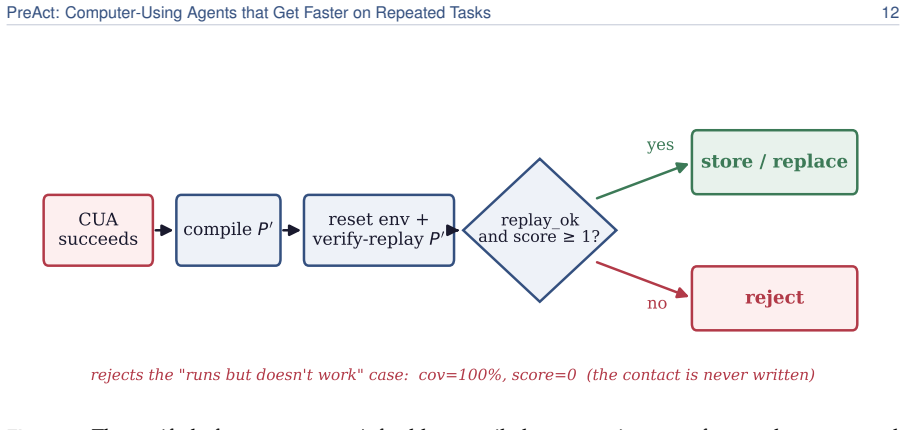
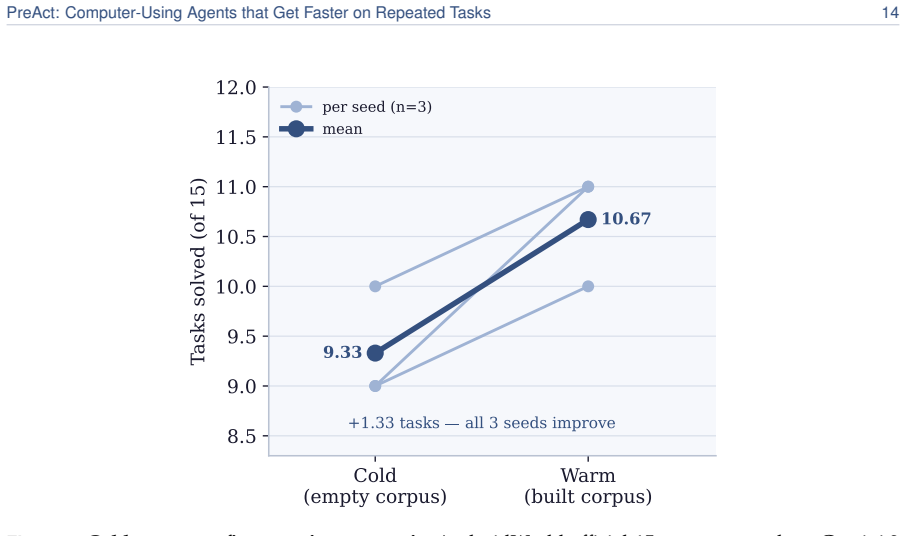
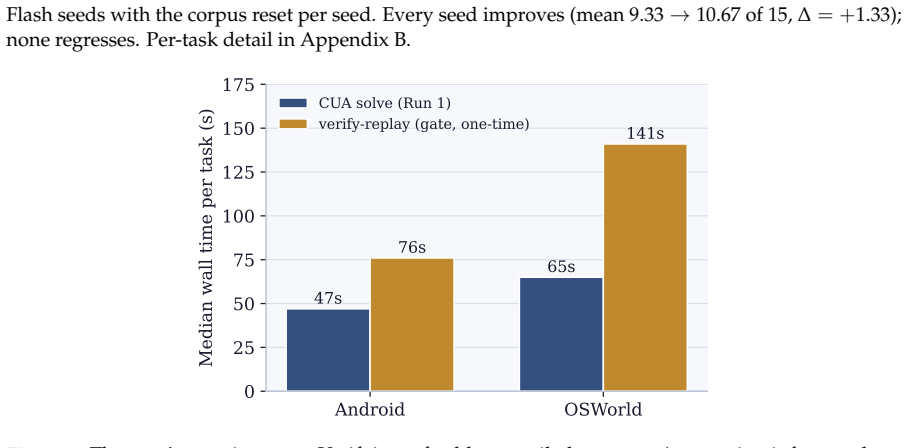
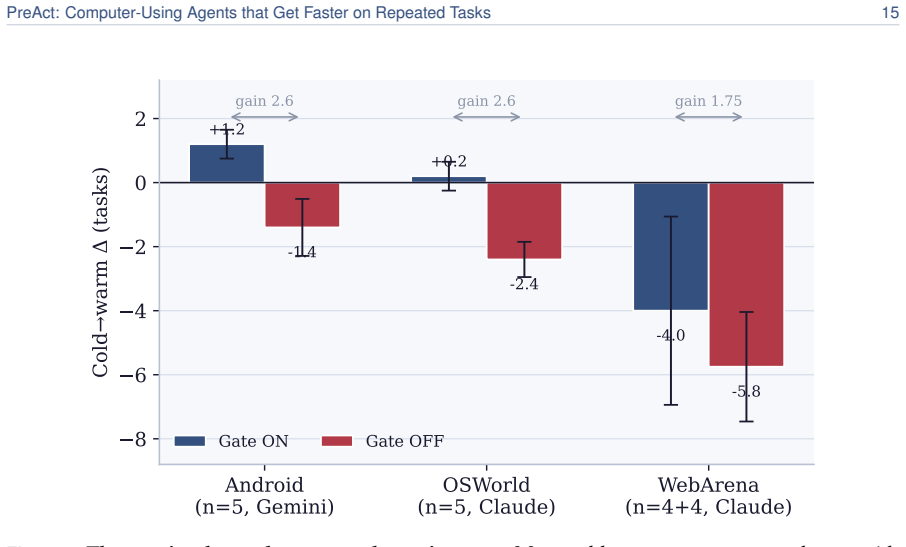
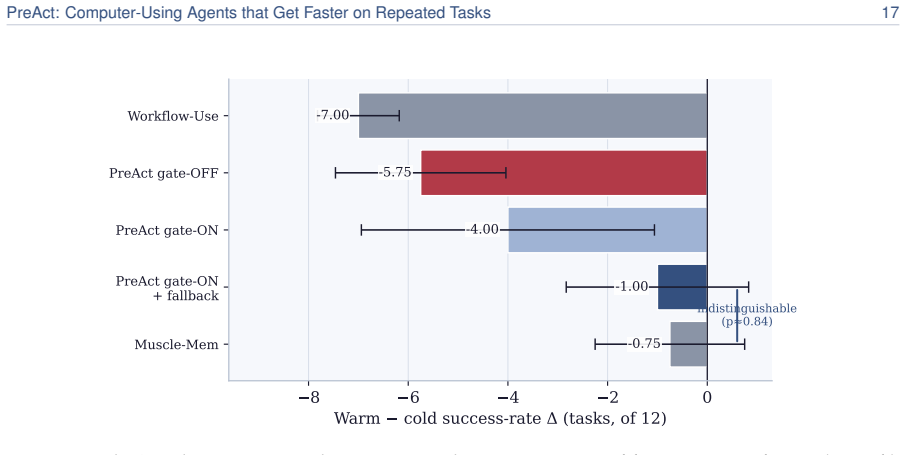
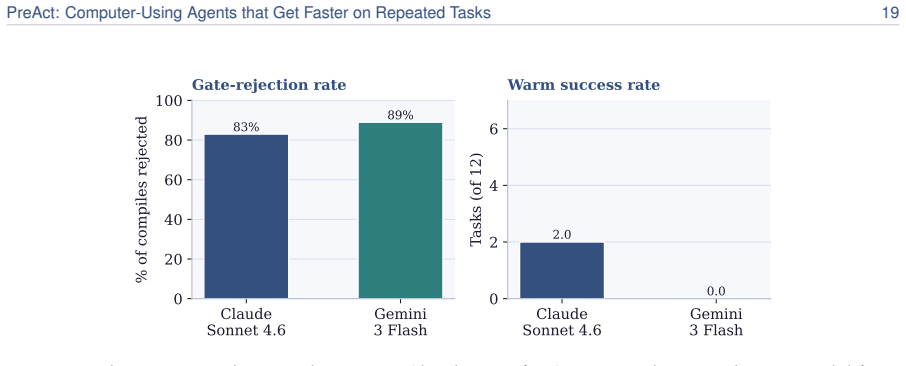
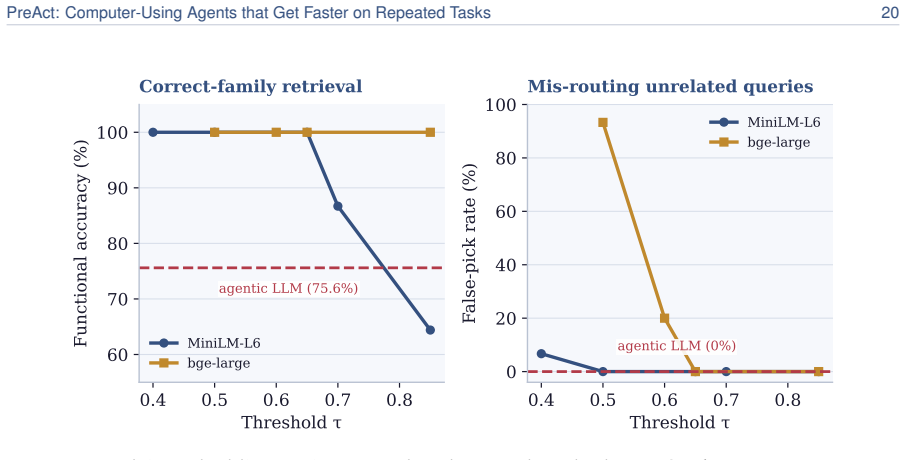
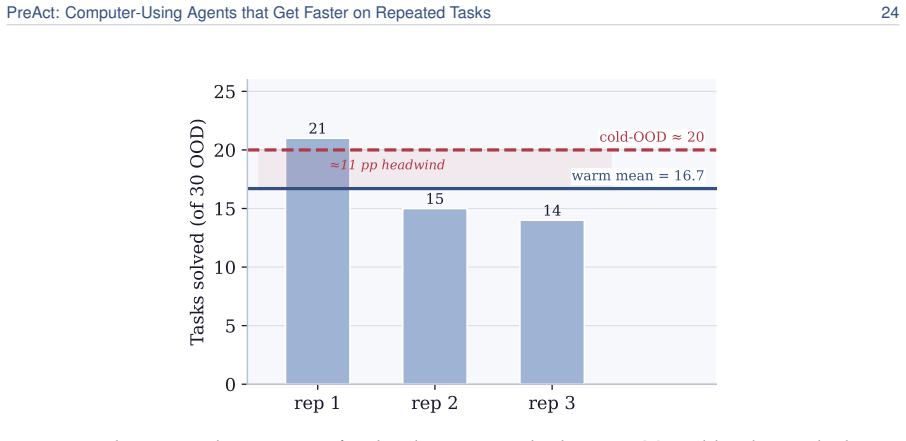
read the original abstract
Computer-using agents drive real software through the screen -- clicking and typing -- but they solve every task from scratch: asked to repeat a task, an agent re-reads the screen, re-reasons every tap, and pays the full cost again. We present PreAct, which lets such an agent get faster on tasks it has done before. The first time it succeeds, PreAct compiles the run into a small state-machine program-states that check the screen, transitions that act-and on later runs replays it directly instead of invoking the agent 8.5-13x faster, with no per-step language-model calls. Replay is not blind: at each step PreAct checks that the screen matches what the program expects before acting, and hands control back to the agent the moment something is off. PreAct applies the same discipline when deciding what to keep: a freshly compiled program enters the store only if, re-run from a clean state, an independent evaluator confirms it solved the task-catching programs that replay to their last step yet leave the task undone. Across a mobile, a desktop, and a web benchmark, this store-time check separates repeated runs that improve from ones that degrade as faulty programs accumulate, worth 1.75-2.6 tasks per benchmark, the same direction on all three; a fallback that explores afresh when no program fits brings PreAct level with a strong record-and-replay baseline. We also report what did not matter: prompt wording, runtime guardrails, and whether a language model or a plain embedding retriever selects which program to reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PreAct, a method for computer-using agents that compiles a successful first-run trace into a compact state-machine program (states check screen, transitions act). On repeats the program replays directly with no per-step LM calls, achieving 8.5-13x speedups, while handing control back to the agent on mismatch. A store-time check requires an independent evaluator, started from a clean state, to confirm the task was solved before the program is stored; this is claimed to prevent accumulation of faulty programs (those reaching the final screen but leaving the goal incomplete) and to produce 1.75-2.6 task gains over baselines across mobile, desktop, and web benchmarks. A fallback to fresh exploration keeps PreAct competitive with record-and-replay. Negative results on prompt wording, guardrails, and retriever type are also reported.
Significance. If the independent evaluator supplies a ground-truth success signal stricter than final-screen matching, the compile-and-verify loop would be a practical way to amortize agent cost on repeated GUI tasks while preserving correctness. The empirical separation of improving versus degrading runs and the finding that several design choices do not matter are useful if reproducible. The approach does not rely on fitted parameters or new axioms, but its value hinges on the evaluator's reliability.
major comments (3)
- [store-time check] § on store-time check (abstract and method): the claim that the independent evaluator 'confirms it solved the task' and thereby 'separates repeated runs that improve from ones that degrade' is load-bearing, yet the manuscript supplies no description of how the evaluator obtains a ground-truth notion of success (task specification, human judgment, or another agent) that is stricter than final-screen matching. Without this, the safeguard against faulty programs is not guaranteed by construction.
- [Results] Results (speedup and task-count tables): the central numbers (8.5-13x, 1.75-2.6 tasks) are reported without error bars, number of tasks per benchmark, number of runs, or any statistical test, so it is impossible to judge whether the reported gains are distinguishable from noise or from the fallback baseline.
- [Benchmarks] Benchmark description: the three benchmarks are named but the manuscript does not state task count, task diversity, or an independent success metric, which is required to evaluate whether the 1.75-2.6 task improvement generalizes or is an artifact of how success is measured.
minor comments (2)
- [Abstract] Abstract: the phrase 'the same direction on all three' is stated without variance or per-benchmark numbers, reducing interpretability.
- [Method] The state-machine representation is described informally; a short pseudocode or transition-table example would clarify the 'small state-machine program' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [store-time check] § on store-time check (abstract and method): the claim that the independent evaluator 'confirms it solved the task' and thereby 'separates repeated runs that improve from ones that degrade' is load-bearing, yet the manuscript supplies no description of how the evaluator obtains a ground-truth notion of success (task specification, human judgment, or another agent) that is stricter than final-screen matching. Without this, the safeguard against faulty programs is not guaranteed by construction.
Authors: We agree that the manuscript lacks a detailed description of the evaluator's ground-truth success signal. The current text notes only that the evaluator is independent, starts from a clean state, and confirms task solution to catch programs that reach the final screen without completing the goal. In revision we will add an explicit subsection describing the evaluator's success criterion (task-specific verification of key outcomes, distinct from final-screen matching) used in the reported experiments. This will substantiate how the check separates improving from degrading runs. revision: yes
-
Referee: [Results] Results (speedup and task-count tables): the central numbers (8.5-13x, 1.75-2.6 tasks) are reported without error bars, number of tasks per benchmark, number of runs, or any statistical test, so it is impossible to judge whether the reported gains are distinguishable from noise or from the fallback baseline.
Authors: We acknowledge that the results section omits these statistical details. In the revised manuscript we will report the number of tasks per benchmark, the number of runs, error bars on all speedup and task-gain figures, and any applicable statistical tests. The directionally consistent gains across three benchmarks already provide supporting evidence, but fuller reporting will allow readers to assess distinguishability from the fallback baseline. revision: yes
-
Referee: [Benchmarks] Benchmark description: the three benchmarks are named but the manuscript does not state task count, task diversity, or an independent success metric, which is required to evaluate whether the 1.75-2.6 task improvement generalizes or is an artifact of how success is measured.
Authors: We will expand the benchmark section to state the exact task counts, describe task diversity (action types and environment coverage), and specify the independent success metrics used for each benchmark. This addition will clarify the basis for the reported task improvements and support evaluation of generalizability. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper reports performance (speedups, task improvements) from direct runs on mobile/desktop/web benchmarks. No equations, fitted parameters, or derivations appear. The store-time evaluator is described as an independent confirmation step using a clean-state re-run; success is not defined in terms of the PreAct mechanism itself. No self-citations are invoked as load-bearing premises. The central claims therefore do not reduce to inputs by construction and remain falsifiable against the stated external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An independent evaluator can be run from a clean state to confirm task completion
- domain assumption Screen-state checks during replay are sufficient to detect deviations that require handing control back to the agent
invented entities (1)
-
state-machine program compiled from agent trace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
Anthropic. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use, October 2024
2024
-
[2]
DigiRL: Training in-the-wild device-control agents with autonomous reinforcement learning
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Ku- mar. DigiRL: Training in-the-wild device-control agents with autonomous reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[3]
Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
arXiv 2024
-
[4]
Workflow-Use: Create and run workflows (RPA 2.0).https://github.com/ browser-use/workflow-use, 2025
Browser-Use. Workflow-Use: Create and run workflows (RPA 2.0).https://github.com/ browser-use/workflow-use, 2025
2025
-
[5]
Large language models as tool makers.arXiv preprint arXiv:2305.17126, 2023
Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, and Denny Zhou. Large language models as tool makers.arXiv preprint arXiv:2305.17126, 2023
arXiv 2023
-
[6]
Hyungjoo Chae, Namyoung Kim, Kai Tzu-iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. Web agents with world models: Learning and leveraging environment dynamics in web navigation.arXiv preprint arXiv:2410.13232, 2024
arXiv 2024
-
[7]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research (TMLR), 2023. arXiv:2211.12588. PreAct: Computer-Using Agents that Get Faster on Repeated T asks 27
Pith/arXiv arXiv 2023
-
[8]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[9]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. ECAI 2025
Pith/arXiv arXiv 2025
-
[10]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[11]
Get experience from practice: LLM agents with record & replay.arXiv preprint arXiv:2505.17716, 2025
Erhu Feng, Wenbo Zhou, Zibin Liu, Le Chen, Yunpeng Dong, Cheng Zhang, Yisheng Zhao, Dong Du, Zhichao Hua, Yubin Xia, and Haibo Chen. Get experience from practice: LLM agents with record & replay.arXiv preprint arXiv:2505.17716, 2025
arXiv 2025
-
[12]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023. arXiv:2211.10435
Pith/arXiv arXiv 2023
-
[13]
A real-world webagent with planning, long context under- standing, and program synthesis
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context under- standing, and program synthesis. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[14]
World models.arXiv preprint arXiv:1803.10122, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
Pith/arXiv arXiv 2018
-
[15]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[16]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[17]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhen- zhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (ACL), 2024
2024
-
[18]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Dong, Ming Ding, and Jie Tang. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[19]
SWE-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations (ICLR), 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations (ICLR), 2024. PreAct: Computer-Using Agents that Get Faster on Repeated T asks 28
2024
-
[20]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[21]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Na- man Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020. arXiv:2005.11401
Pith/arXiv arXiv 2020
-
[22]
User as code: Executable memory for personalized agents.arXiv preprint arXiv:2606.16707, 2026
Bojie Li. User as code: Executable memory for personalized agents.arXiv preprint arXiv:2606.16707, 2026
arXiv 2026
-
[23]
Chain of code: Reasoning with a language model-augmented code emulator
Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, and Brian Ichter. Chain of code: Reasoning with a language model-augmented code emulator. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. arXiv:2312.04474
arXiv 2024
-
[24]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Flo- rence, and Andy Zeng. Code as policies: Language model programs for embodied control. InIEEE International Conference on Robotics and Automation (ICRA), 2023. arXiv:2209.07753
Pith/arXiv arXiv 2023
-
[25]
Xiangyuan Liang, Bohan Cao, Shengyu Gu, Yifei Li, et al. SAGE: Self-evolving agents with reflective and memory-augmented abilities.arXiv preprint arXiv:2409.00872, 2024
arXiv 2024
-
[26]
Yaxi Lu, Shenzhi Yang, Cheng Qian, Guirong Chen, Qinyu Luo, Yesai Wu, Huadong Wang, Xin Cong, Zhong Zhang, Yankai Lin, Weiwen Liu, Yasheng Wang, Zhiyuan Liu, Fangming Liu, and Maosong Sun. Proactive agent: Shifting llm agents from reactive responses to active assistance.arXiv preprint arXiv:2410.12361, 2024
arXiv 2024
-
[27]
Language models of code are few-shot commonsense learners
Aman Madaan, Shuyan Zhou, Uri Alon, Yiming Yang, and Graham Neubig. Language models of code are few-shot commonsense learners. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. arXiv:2210.07128
arXiv 2022
-
[28]
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Skill-pro: Learning reusable skills from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869, 2026. ICML 2026
Pith/arXiv arXiv 2026
-
[29]
GAIA: A benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general ai assistants. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[30]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. We- bGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
Pith/arXiv arXiv 2021
-
[31]
Screenagent: A vision language model-driven computer control agent
Runliang Niu, Jindong Li, Shiqi Wang, Yali Fu, Xiyu Hu, Xueyuan Leng, He Kong, Yi Chang, and Qi Wang. Screenagent: A vision language model-driven computer control agent. InProceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI), 2024. PreAct: Computer-Using Agents that Get Faster on Repeated T asks 29
2024
-
[32]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[33]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[34]
Muscle-Mem: A cache for AI agents to learn and replay complex behaviors
Pig.dev. Muscle-Mem: A cache for AI agents to learn and replay complex behaviors. https://github.com/pig-dot-dev/muscle-mem, 2025
2025
-
[35]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. UI-TARS: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
Pith/arXiv arXiv 2025
-
[36]
Android- World: A dynamic benchmarking environment for autonomous agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Android- World: A dynamic benchmarking environment for autonomous agents. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[37]
Android in the wild: A large-scale dataset for android device control
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Android in the wild: A large-scale dataset for android device control. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[38]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Ham- bro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[39]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2303.11366
Pith/arXiv arXiv 2023
-
[40]
Auto-gpt: An autonomous gpt-4 experiment
Significant Gravitas. Auto-gpt: An autonomous gpt-4 experiment. https://github.com/ Significant-Gravitas/AutoGPT, 2023
2023
-
[41]
Cognitive architectures for language agents.Transactions on Machine Learning Research (TMLR), 2024
Theodore R Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[42]
The bitter lesson
Richard Sutton. The bitter lesson. http://www.incompleteideas.net/IncIdeas/ BitterLesson.html, 2019. Blog post, March 13, 2019
2019
-
[43]
Richard S. Sutton. Learning to predict by the methods of temporal differences.Machine Learning, 3(1):9–44, 1988
1988
-
[44]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018. PreAct: Computer-Using Agents that Get Faster on Repeated T asks 30
2018
-
[45]
Geert Trooskens, Aaron Karlsberg, Anmol Sharma, Lamara De Brouwer, Max Van Puyvelde, Matthew Young, John Thickstun, and Gil Alterovitz. Compiled AI: Deterministic code generation for LLM-based workflow automation.arXiv preprint arXiv:2604.05150, 2026
Pith/arXiv arXiv 2026
-
[46]
Robotic process automation
Wil M P van der Aalst, Martin Bichler, and Armin Heinzl. Robotic process automation. Business & Information Systems Engineering, 60(4):269–272, 2018
2018
-
[47]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large lan- guage models.Transactions on Machine Learning Research (TMLR), 2024. arXiv:2305.16291
Pith/arXiv arXiv 2024
-
[48]
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception.arXiv preprint arXiv:2401.16158, 2024
Pith/arXiv arXiv 2024
-
[49]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. arXiv:2402.01030
arXiv 2024
-
[50]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[51]
Zhiruo Wang, Daniel Fried, and Graham Neubig. Trove: Inducing verifiable and efficient toolboxes for solving programmatic tasks.arXiv preprint arXiv:2401.12869, 2024
arXiv 2024
-
[52]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[53]
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456, 2024
arXiv 2024
-
[54]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
2024
-
[55]
A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025. NeurIPS 2025
Pith/arXiv arXiv 2025
-
[56]
SWE-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[57]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. PreAct: Computer-Using Agents that Get Faster on Repeated T asks 31
2022
-
[58]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[59]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[60]
UFO: A ui-focused agent for windows os interaction.arXiv preprint arXiv:2402.07939, 2024
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. UFO: A ui-focused agent for windows os interaction.arXiv preprint arXiv:2402.07939, 2024
arXiv 2024
-
[61]
Appagent: Multimodal agents as smartphone users.arXiv preprint arXiv:2312.13771, 2023
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users.arXiv preprint arXiv:2312.13771, 2023
Pith/arXiv arXiv 2023
-
[62]
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents.arXiv preprint arXiv:2404.13501, 2024
Pith/arXiv arXiv 2024
-
[63]
ExpeL: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[64]
Gpt-4v(ision) is a generalist web agent, if grounded
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v(ision) is a generalist web agent, if grounded. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[65]
Hongbin Zhong, Fazle Faisal, Luis França, Tanakorn Leesatapornwongsa, Adriana Szek- eres, Kexin Rong, and Suman Nath. ActionEngine: From reactive to programmatic GUI agents via state machine memory.arXiv preprint arXiv:2602.20502, 2026
arXiv 2026
-
[66]
type the filename (parameter filename)
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. We- bArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024. Appendix A. Computer-Action Schema Each transition’s actio...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.