Beyond Value Benchmarks: Measuring Value-Structure Alignment in Large Language Models via Symmetric Q-Sorts
Pith reviewed 2026-06-26 12:11 UTC · model grok-4.3
The pith
Q-sorts on moral statements show LLMs organize values into structures that item benchmarks miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
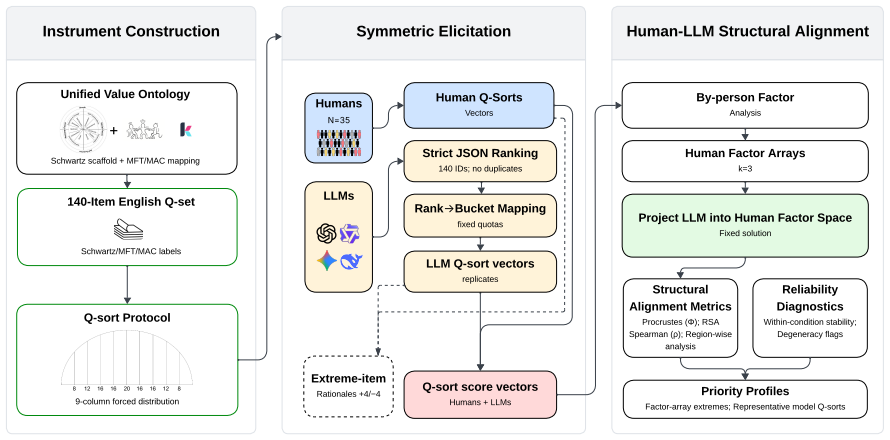
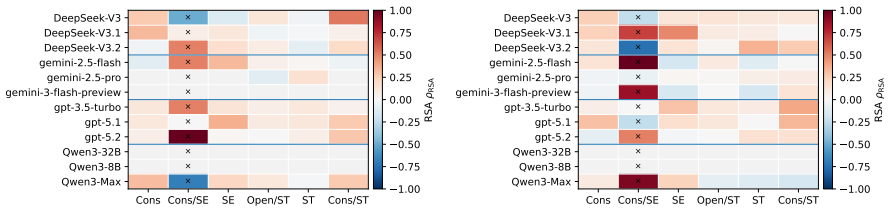
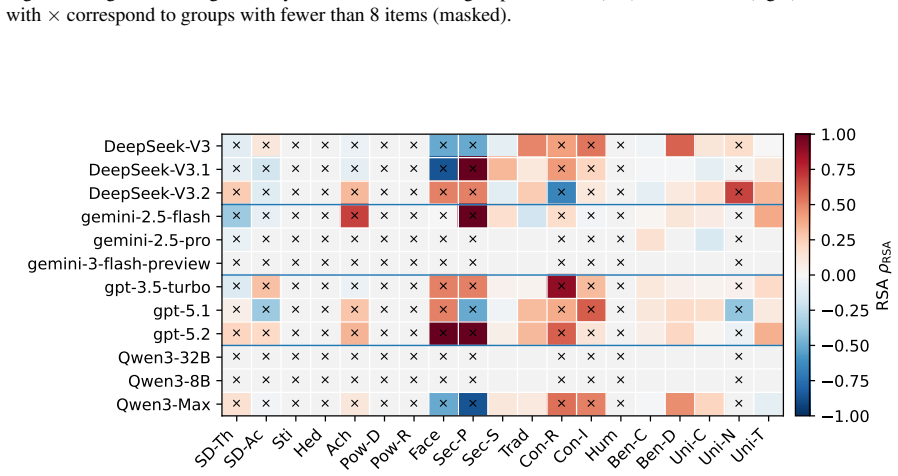
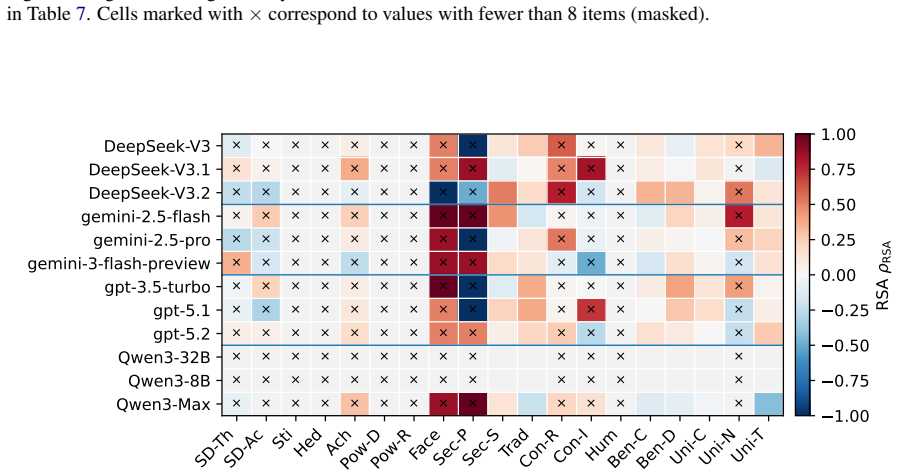
Eliciting strict rankings from LLMs, mapping them deterministically to Q-sort buckets, and comparing the resulting structures to a human three-factor reference via Procrustes and RSA metrics reveals significant heterogeneity across model families plus sensitivity to stochasticity and prompt wording.
What carries the argument
The symmetric Q-sort protocol that forces both humans and LLMs into the same nine-column distribution on 140 items, then quantifies structural match with Procrustes similarity.
If this is right
- Models with high itemwise moral scores can still show regional value distortions relative to human structure.
- Different model families display distinct patterns of alignment and misalignment with the human reference geometry.
- Temperature settings and prompt phrasing alter measured alignment for some but not all models.
- Rank-based and bucket-based analyses of the same sorts remain highly consistent with each other.
Where Pith is reading between the lines
- The method could be applied to track whether fine-tuning moves a model's value structure closer to or farther from the human reference over time.
- If the three-factor geometry proves sensitive to cultural differences in human sorters, multiple reference geometries may be needed for broader use.
- Localized misalignment patterns identified by the protocol could point to specific item clusters for targeted data interventions.
Load-bearing premise
That strict rankings elicited from an LLM and then mapped to Q-sort buckets accurately reflect the model's internal value prioritization structure.
What would settle it
A new human sample producing a substantially different three-factor geometry on the same 140 items, or LLMs whose bucketed sorts fail to produce stable Procrustes scores across repeated runs at fixed temperature.
Figures


read the original abstract
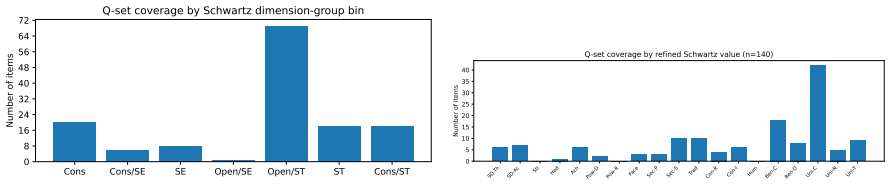
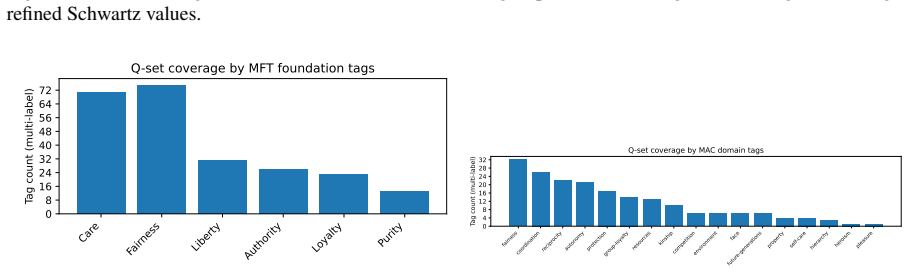
Large Language Models (LLMs) are increasingly deployed in contexts requiring complex moral reasoning and value trade-offs. However, existing evaluations typically rely on item-level behavioral metrics, which fail to capture how models structurally prioritize competing values as a cohesive system. To address this, we propose a symmetric human-LLM evaluation framework, grounded in Q methodology, to measure value-structure alignment. Under our protocol, humans and models sort an identical 140-item moral statement set into a shared nine-column forced distribution; for LLMs, we elicit strict rankings and deterministically map them to Q-sort buckets. Using a human reference sample ($N=35$), we establish a stable three-factor reference geometry specific to this instrument and sample. We evaluate 12 LLMs across four model families via 240 replicated Q-sorts at two temperature settings, quantifying structural alignment via Procrustes similarity ($\phi$) and RSA-based Spearman correlation ($\rho$). Our results reveal significant cross-family heterogeneity, model-specific sensitivity to generation stochasticity and localized misalignment, which demonstrate that favorable global scores can obscure underlying regional distortions. While rank- and bucket-based analyses remain highly consistent, prompt phrasing introduces notable variance. Ultimately, assessing value-structure alignment provides a crucial structural complement to traditional itemwise moral benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a symmetric Q-methodology framework to measure value-structure alignment in LLMs as a complement to itemwise moral benchmarks. Humans (N=35) and 12 LLMs (4 families, 240 replicated Q-sorts at two temperatures) sort an identical 140-item moral statement set into a shared nine-column forced distribution; LLM outputs are elicited as strict rankings and deterministically mapped to buckets. A stable three-factor reference geometry is derived from the human sample. Alignment is quantified via Procrustes similarity (φ) and RSA-based Spearman correlation (ρ), revealing cross-family heterogeneity, prompt/temperature sensitivity, and cases where global scores mask localized misalignments.
Significance. If the central assumptions hold, the work supplies a structural metric that can reveal prioritization geometries not captured by item-level scores, supported by an independent human reference sample and temperature-controlled replications. This could usefully inform alignment research by highlighting when favorable aggregate metrics obscure regional distortions in value systems.
major comments (2)
- [§3] §3 (protocol): The deterministic mapping of one strict ranking per Q-sort to the exact human forced-distribution buckets is presented without modeling uncertainty, ties, or prompt variance, yet the text reports 'notable variance' from phrasing and temperature. This step is load-bearing for the claim that φ and ρ recover internal value prioritization structure rather than output regularities.
- [Methods / Results] Human reference geometry (abstract and methods): The claim of a 'stable three-factor reference geometry' from N=35 lacks reported validation details such as factor loadings, variance explained, or stability checks. All subsequent LLM comparisons and heterogeneity conclusions rest on this baseline.
minor comments (1)
- [Abstract] Abstract: The statement that 'rank- and bucket-based analyses remain highly consistent' is not accompanied by the specific consistency metric or the section reporting those analyses.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each major point below and outline the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [§3] §3 (protocol): The deterministic mapping of one strict ranking per Q-sort to the exact human forced-distribution buckets is presented without modeling uncertainty, ties, or prompt variance, yet the text reports 'notable variance' from phrasing and temperature. This step is load-bearing for the claim that φ and ρ recover internal value prioritization structure rather than output regularities.
Authors: We agree this mapping step requires clearer justification. The deterministic mapping was chosen to enforce direct comparability with the human forced-distribution Q-sorts. However, we acknowledge that it does not explicitly incorporate uncertainty or ties in LLM rankings. In the revision we will expand §3 to include (a) explicit rationale for the mapping, (b) additional sensitivity analyses across prompt phrasings, and (c) a limitations paragraph noting that the metric captures structure conditional on this mapping procedure. These additions will clarify that φ and ρ reflect prioritization geometry under the protocol rather than raw output regularities. revision: partial
-
Referee: [Methods / Results] Human reference geometry (abstract and methods): The claim of a 'stable three-factor reference geometry' from N=35 lacks reported validation details such as factor loadings, variance explained, or stability checks. All subsequent LLM comparisons and heterogeneity conclusions rest on this baseline.
Authors: This is a fair critique. While the full manuscript contains the factor solution, we did not sufficiently foreground the validation statistics. In the revised version we will add a dedicated subsection in Methods reporting (i) factor loadings for the top items per factor, (ii) variance explained by each of the three factors, and (iii) stability metrics including split-half reliability and bootstrap resampling of the human sample. These details will be referenced in the abstract and results to support the claim of stability. revision: yes
Circularity Check
No significant circularity; derivation uses independent human reference and standard metrics on model outputs
full rationale
The paper defines its protocol by eliciting strict rankings from LLMs and deterministically mapping to the fixed nine-column distribution, then compares resulting Q-sorts to an independently collected human reference sample (N=35) via Procrustes similarity and RSA Spearman correlation. No equations or steps reduce a claimed result to a fitted parameter from the same data, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming is presented as a derivation. The human reference geometry is external to the LLM evaluations, satisfying the criteria for a self-contained, non-circular analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The forced nine-column Q-sort distribution and deterministic mapping from LLM rankings accurately reflect value prioritization.
Reference graph
Works this paper leans on
-
[1]
and others , title =
D'Amour, Alexander and Heller, Katherine and Moldovan, Dan and Adlam, Ben and Alipanahi, Babak and Beutel, Alex and Chen, Christina and Deaton, Jonathan and Eisenstein, Jacob and Hoffman, Matthew D. and others , title =. Journal of Machine Learning Research , year =
-
[2]
and Leskovec, Jure and Kundaje, Anshul and Pierson, Emma and Levine, Sergey and Finn, Chelsea and Liang, Percy , title =
Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard Lanas and Gao, Irena and Lee, Tony and David, Etienne and Stavness, Ian and Guo, Wei and Earnshaw, Berton and Haque, Imran and Beery, Sara M. and Leskovec, Jure and Kundaje, Ans...
2021
-
[3]
Concrete problems in
Amodei, Dario and Olah, Chris and Steinhardt, Jacob and Christiano, Paul and Schulman, John and Man. Concrete problems in. 2016 , eprint =
2016
-
[4]
2022 , eprint =
Shah, Rohin and Varma, Vikrant and Kumar, Ramana and Phuong, Mary and Krakovna, Victoria and Uesato, Jonathan and Kenton, Zac , title =. 2022 , eprint =
2022
-
[6]
, title =
Graham, Jesse and Haidt, Jonathan and Nosek, Brian A. , title =. Journal of Personality and Social Psychology , year =
-
[7]
and Haidt, Jonathan and Iyer, Ravi and Koleva, Spassena and Ditto, Peter H
Graham, Jesse and Nosek, Brian A. and Haidt, Jonathan and Iyer, Ravi and Koleva, Spassena and Ditto, Peter H. , title =. Journal of Personality and Social Psychology , year =
-
[9]
, title =
Schwartz, Shalom H. , title =. Advances in Experimental Social Psychology , editor =. 1992 , doi =
1992
-
[10]
, title =
Schwartz, Shalom H. , title =. Online Readings in Psychology and Culture , year =
-
[11]
and Cieciuch, Jan and Vecchione, Michele and Davidov, Eldad and Fischer, Ronald and Beierlein, Constanze and Ramos, Alice and Verkasalo, Markku and L
Schwartz, Shalom H. and Cieciuch, Jan and Vecchione, Michele and Davidov, Eldad and Fischer, Ronald and Beierlein, Constanze and Ramos, Alice and Verkasalo, Markku and L. Refining the theory of basic individual values , journal =. 2012 , volume =
2012
-
[12]
, title =
Kriegeskorte, Nikolaus and Mur, Marieke and Bandettini, Peter A. , title =. Frontiers in Systems Neuroscience , year =
-
[13]
A generalized solution of the orthogonal Procrustes problem , journal =
Sch. A generalized solution of the orthogonal Procrustes problem , journal =. 1966 , volume =
1966
-
[14]
Gower, J. C. , title =. Psychometrika , year =
-
[15]
Human Brain Mapping , year =
Yang, Yang and Li, Luan and de Deyne, Simon and Li, Bing and Wang, Jing and Cai, Qing , title =. Human Brain Mapping , year =
-
[17]
, title =
de Leeuw, Joshua R. , title =. Behavior Research Methods , year =
-
[18]
, title =
Horn, John L. , title =. Psychometrika , year =
-
[19]
, title =
Cattell, Raymond B. , title =. Multivariate Behavioral Research , year =
-
[20]
, title =
Kaiser, Henry F. , title =. Psychometrika , year =
-
[21]
, title =
Efron, Bradley and Tibshirani, Robert J. , title =. 1993 , doi =
1993
-
[22]
Stephenson, William , title =
-
[23]
2012 , doi =
Watts, Simon and Stenner, Paul , title =. 2012 , doi =
2012
-
[24]
SIGKDD Explorations Newsletter , year =
Ji, Jianchao and Chen, Yutong and Jin, Mingyu and Xu, Wujiang and Hua, Wenyue and Zhang, Yongfeng , title =. SIGKDD Explorations Newsletter , year =
-
[27]
and Mireshghallah, Niloofar and Rytting, Christopher Michael and Ye, Andre and Jiang, Liwei and Lu, Ximing and Dziri, Nouha and Althoff, Tim and Choi, Yejin , title =
Sorensen, Taylor and Moore, Jared and Fisher, Jillian and Gordon, Mitchell L. and Mireshghallah, Niloofar and Rytting, Christopher Michael and Ye, Andre and Jiang, Liwei and Lu, Ximing and Dziri, Nouha and Althoff, Tim and Choi, Yejin , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[30]
and Cole-Lewis, Heather and Neal, Darlene and Rashid, Qazi Mamunur and Schaekermann, Mike and Wang, Amy and Dash, Dev and Chen, Jonathan H
Singhal, Karan and Tu, Tao and Gottweis, Juraj and Sayres, Rory and Wulczyn, Ellery and Amin, Mohamed and Hou, Le and Clark, Kevin and Pfohl, Stephen R. and Cole-Lewis, Heather and Neal, Darlene and Rashid, Qazi Mamunur and Schaekermann, Mike and Wang, Amy and Dash, Dev and Chen, Jonathan H. and Shah, Nigam H. and Lachgar, Sami and Mansfield, Philip Andre...
-
[31]
Benefits and risks of
Baltezarevi. Benefits and risks of. Megatrend Revija , year =
-
[33]
, title =
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , title =. 2023 , eprint =
2023
-
[34]
2020 , eprint =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Critch, Andrew and Li, Jerry and Song, Dawn and Steinhardt, Jacob , title =. 2020 , eprint =
2020
-
[43]
Marwa Abdulhai, Gregory Serapio-Garc \'i a, Clement Crepy, Daria Valter, John Canny, and Natasha Jaques. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.982 Moral foundations of large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17737--17752, Miami, Florida, USA. Association for Compu...
-
[44]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . 2016. https://arxiv.org/abs/1606.06565 Concrete problems in AI safety . Preprint, arXiv:1606.06565
Pith/arXiv arXiv 2016
-
[45]
Radoslav Baltezarevi \'c and Ivana Baltezarevi \'c . 2024. https://doi.org/10.5937/MegRev2402071B Benefits and risks of ChatGPT in future education . Megatrend Revija, 21:71--84
-
[46]
Pablo Biedma, Xiaoyuan Yi, Linus Huang, Maosong Sun, and Xing Xie. 2024. https://doi.org/10.48550/arXiv.2404.12744 Beyond human norms: Unveiling unique values of large language models through interdisciplinary approaches . Preprint, arXiv:2404.12744
-
[47]
Raymond B. Cattell. 1966. https://doi.org/10.1207/s15327906mbr0102_10 The scree test for the number of factors . Multivariate Behavioral Research, 1(2):245--276
-
[48]
Oliver Scott Curry, Matthew Jones Chesters , and Caspar J. Van Lissa . 2019. https://doi.org/10.1016/j.jrp.2018.10.008 Mapping morality with a compass: Testing the theory of ‘morality-as-cooperation’ with a new questionnaire . Journal of Research in Personality, 78:106--124
-
[49]
Hoffman, and 1 others
Alexander D'Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, and 1 others. 2022. https://www.jmlr.org/papers/v23/20-1335.html Underspecification presents challenges for credibility in modern machine learning . Journal of Machine Learning Research, 23(226):1--61
2022
-
[50]
Joshua R. de Leeuw. 2015. https://doi.org/10.3758/s13428-014-0458-y jsPsych : A JavaScript library for creating behavioral experiments in a web browser . Behavior Research Methods, 47(1):1--12
-
[51]
Bradley Efron and Robert J. Tibshirani. 1993. https://doi.org/10.1201/9780429246593 An Introduction to the Bootstrap . Chapman & Hall, New York
-
[52]
and Shwartz, Vered and Sap, Maarten and Choi, Yejin
Maxwell Forbes, Jena D. Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.48 Social chemistry 101: Learning to reason about social and moral norms . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 653--670, Online. Association for Computational Linguistics
-
[53]
J. C. Gower. 1975. https://doi.org/10.1007/BF02291478 Generalized procrustes analysis . Psychometrika, 40(1):33--51
-
[54]
Jesse Graham, Jonathan Haidt, and Brian A. Nosek. 2009. https://doi.org/10.1037/a0015141 Liberals and conservatives rely on different sets of moral foundations . Journal of Personality and Social Psychology, 96(5):1029--1046
-
[55]
Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H
Jesse Graham, Brian A. Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H. Ditto. 2011. https://doi.org/10.1037/a0021847 Mapping the moral domain . Journal of Personality and Social Psychology, 101(2):366--385
-
[56]
Zishan Guo, Renren Jin, Chuang Liu, Yufei Huang, Dan Shi, Supryadi, Linhao Yu, Yan Liu, Jiaxuan Li, Bojian Xiong, and Deyi Xiong. 2023. https://arxiv.org/abs/2310.19736 Evaluating Large Language Models : A comprehensive survey . Preprint, arXiv:2310.19736
arXiv 2023
-
[57]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2020. https://arxiv.org/abs/2008.02275 Aligning AI with shared human values . Preprint, arXiv:2008.02275
Pith/arXiv arXiv 2020
-
[58]
John L. Horn. 1965. https://doi.org/10.1007/BF02289447 A rationale and test for the number of factors in factor analysis . Psychometrika, 30(2):179--185
-
[59]
Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, and Yongfeng Zhang. 2025. https://doi.org/10.1145/3748239.3748246 MoralBench : Moral evaluation of LLMs . SIGKDD Explorations Newsletter, 27(1):62--71
-
[60]
Henry F. Kaiser. 1958. https://doi.org/10.1007/BF02289233 The varimax criterion for analytic rotation in factor analysis . Psychometrika, 23(3):187--200
-
[61]
Beery, Jure Leskovec, Anshul Kundaje, and 4 others
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton Earnshaw, Imran Haque, Sara M. Beery, Jure Leskovec, Anshul Kundaje, and 4 others. 2021. https://proceedings.mlr.press/v139/koh21a.html W...
2021
-
[62]
Nikolaus Kriegeskorte, Marieke Mur, and Peter A. Bandettini. 2008. https://doi.org/10.3389/neuro.06.004.2008 Representational similarity analysis---connecting the branches of systems neuroscience . Frontiers in Systems Neuroscience, 2:4
-
[63]
Jiaang Li, Antonia Karamolegkou, Yova Kementchedjhieva, Mostafa Abdou, Sune Lehmann, and Anders S gaard. 2023. https://doi.org/10.48550/arXiv.2306.01930 Structural similarities between language models and neural response measurements . Preprint, arXiv:2306.01930
-
[64]
Nicole Meister, Carlos Guestrin, and Tatsunori Hashimoto. 2025. https://doi.org/10.18653/v1/2025.naacl-long.2 Benchmarking distributional alignment of Large Language Models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
-
[65]
Allen Nie, Yuhui Zhang, Atharva Amdekar, Chris Piech, Tatsunori Hashimoto, and Tobias Gerstenberg. 2023. https://doi.org/10.48550/arXiv.2310.19677 MoCa : Measuring human-language model alignment on causal and moral judgment tasks . Preprint, arXiv:2310.19677
-
[66]
Yuanyi Ren, Haoran Ye, Hanjun Fang, Xin Zhang, and Guojie Song. 2024. https://doi.org/10.18653/v1/2024.acl-long.111 V alue B ench: Towards comprehensively evaluating value orientations and understanding of Large Language Models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2015-...
-
[67]
A generalized solution of the orthogonal procrustes problem
Peter H. Sch \"o nemann. 1966. https://doi.org/10.1007/BF02289451 A generalized solution of the orthogonal procrustes problem . Psychometrika, 31(1):1--10
-
[68]
Shalom H. Schwartz. 1992. https://doi.org/10.1016/S0065-2601(08)60281-6 Universals in the content and structure of values: Theoretical advances and empirical tests in 20 countries . In Mark P. Zanna, editor, Advances in Experimental Social Psychology, volume 25, pages 1--65. Academic Press
-
[69]
Shalom H. Schwartz. 2012. https://doi.org/10.9707/2307-0919.1116 An overview of the Schwartz theory of basic values . Online Readings in Psychology and Culture, 2(1)
-
[70]
Shalom H. Schwartz, Jan Cieciuch, Michele Vecchione, Eldad Davidov, Ronald Fischer, Constanze Beierlein, Alice Ramos, Markku Verkasalo, Jan-Erik L \"o nnqvist, K \"u r s ad Demirutku, Ozlem Dirilen-Gumus, and Mark Konty. 2012. https://doi.org/10.1037/a0029393 Refining the theory of basic individual values . Journal of Personality and Social Psychology, 10...
-
[71]
Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato, and Zac Kenton. 2022. https://arxiv.org/abs/2210.01790 Goal misgeneralization: Why correct specifications aren't enough for correct goals . Preprint, arXiv:2210.01790
arXiv 2022
-
[72]
Hua Shen, Nicholas Clark, and Tanu Mitra. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.154 Mind the value-action gap: Do LLM s act in alignment with their values? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3097--3118, Suzhou, China. Association for Computational Linguistics
-
[73]
Tianhao Shen, Renren Jin, Yufei Huang, Chuang Liu, Weilong Dong, Zishan Guo, Xinwei Wu, Yan Liu, and Deyi Xiong. 2023. https://doi.org/10.48550/arXiv.2309.15025 Large Language Model alignment: A survey . Preprint, arXiv:2309.15025
-
[74]
Ridwan Islam Sifat. 2025. https://doi.org/10.1111/polp.70019 Commentary--- AI and public policy: Navigating the possibilities and limitations . Politics & Policy, 53(1):e70019
-
[75]
Toward Expert-Level Medical Question Answering with Large Language Models,
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, Darlene Neal, Qazi Mamunur Rashid, Mike Schaekermann, Amy Wang, Dev Dash, Jonathan H. Chen, Nigam H. Shah, Sami Lachgar, Philip Andrew Mansfield, and 16 others. 2025. https://doi.org/10.1038/s41591-024-03423-7 Toward...
-
[76]
Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, and Yejin Choi
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell L. Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, and Yejin Choi. 2024. https://proceedings.mlr.press/v235/sorensen24a.html Position: A roadmap to pluralistic alignment . In Proceedings of the 41st International Conference on Ma...
2024
-
[77]
William Stephenson. 1953. The Study of Behavior: Q -Technique and Its Methodology . University of Chicago Press, Chicago
1953
-
[78]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. https://arxiv.org/abs/2305.04388 Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting . Preprint, arXiv:2305.04388
Pith/arXiv arXiv 2023
-
[79]
Xiting Wang, Liming Jiang, Jose Hernandez-Orallo, David Stillwell, Luning Sun, Fang Luo, and Xing Xie. 2023. https://doi.org/10.48550/arXiv.2310.16379 Evaluating general-purpose AI with psychometrics . Preprint, arXiv:2310.16379
-
[80]
Simon Watts and Paul Stenner. 2012. https://doi.org/10.4135/9781446251911 Doing Q Methodological Research: Theory, Method and Interpretation . SAGE Publications, London
-
[81]
Shaoyang Xu, Weilong Dong, Zishan Guo, Xinwei Wu, and Deyi Xiong. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.96 Exploring multilingual concepts of human values in Large Language Models : Is value alignment consistent, transferable and controllable across languages? In Findings of the Association for Computational Linguistics: EMNLP 2024, pages ...
-
[82]
Shaoyang Xu, Yongqi Leng, Linhao Yu, and Deyi Xiong. 2025. https://doi.org/10.18653/v1/2025.naacl-long.350 Self-pluralising culture alignment for Large Language Models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6...
-
[83]
Yang Yang, Luan Li, Simon de Deyne, Bing Li, Jing Wang, and Qing Cai. 2024. https://doi.org/10.1002/hbm.26546 Unraveling lexical semantics in the brain: Comparing internal, external, and hybrid language models . Human Brain Mapping, 45(1):e26546
-
[84]
Linhao Yu, Yongqi Leng, Yufei Huang, Shang Wu, Haixin Liu, Xinmeng Ji, Jiahui Zhao, Jinwang Song, Tingting Cui, Xiaoqing Cheng, Tao Liu, and Deyi Xiong. 2024. https://doi.org/10.18653/v1/2024.findings-acl.703 CM oral E val: A moral evaluation benchmark for Chinese Large Language Models . In Findings of the Association for Computational Linguistics: ACL 20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.