Prediction-Powered Inference Across Many Tasks for AI Evaluation & Social Science Research
Pith reviewed 2026-06-29 05:58 UTC · model grok-4.3
The pith
Multi-task prediction-powered inference uses cross-task recalibration to improve power from scarce labels across related tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a multi-task prediction-powered inference framework that uses labeled data from related tasks to improve power while preserving task-specific inference. Our methods exploit the shared structure in the proxy-ground-truth relationship through cross-task recalibration, while retaining within-task rectification and power tuning to construct accurate point estimates and confidence intervals. We prove that efficiency gains beyond power-tuned PPI are only possible when the proxy-ground-truth relationship contains nonlinear structure; affine cross-task recalibrations are asymptotically equivalent to using the original proxy.
What carries the argument
Cross-task recalibration of proxies using labels from related tasks to exploit shared nonlinear structure while preserving task-specific validity.
If this is right
- Scarce labels per task can still yield precise task-specific estimates by using data from related tasks.
- No asymptotic efficiency gain from cross-task methods if the relationship is linear.
- The framework applies to auditing language models on multiple election-related topics using human annotations.
- Experiments on synthetic data confirm the theoretical distinction between linear and nonlinear cases.
- Point estimates and intervals remain valid for each individual task.
Where Pith is reading between the lines
- Researchers could test the method on tasks with varying degrees of relatedness to map when the nonlinear structure appears.
- This approach might reduce the total labeling budget needed for comprehensive AI safety evaluations across many behaviors.
- In social science, it could allow finer-grained analysis of survey responses across demographics without additional data collection.
Load-bearing premise
The proxy and ground-truth labels share nonlinear structure across tasks that cross-task recalibration can use while keeping each task's inference valid.
What would settle it
Finding no reduction in confidence interval width from the multi-task method compared to single-task power-tuned PPI in a setting where the proxy-ground-truth map is known to be linear across tasks.
Figures
read the original abstract
Many applications require statistically valid inference across many related tasks, while using only a handful of high-quality labels per hypothesis. In AI evaluation, these tasks may correspond to model behaviors across prompts, subgroups, or hypotheses; in social science surveys, they may correspond to related questions, populations, or measurement conditions. Prediction-powered inference (PPI) uses abundant but inexpensive proxy measurements to improve inference from limited, ground-truth labels, but commonly used methods treat tasks independently and therefore fail to exploit shared structure across related tasks. This limitation is especially important in settings where only a small number of labels are available per task. To address this issue, we introduce a multi-task prediction-powered inference framework that uses labeled data from related tasks to improve power while preserving task-specific inference. Our methods exploit the shared structure in the proxy-ground-truth relationship through cross-task recalibration, while retaining within-task rectification and power tuning to construct accurate point estimates and confidence intervals. We prove that efficiency gains beyond power-tuned PPI are only possible when the proxy-ground-truth relationship contains nonlinear structure; affine cross-task recalibrations are asymptotically equivalent to using the original proxy. We complement our theoretical findings with experiments on synthetic and semi-synthetic datasets, as well as a case study auditing language models on election-related information during the 2024 U.S. presidential election. Using a large human-annotation study, we show that cross-task recalibration can substantially reduce confidence interval widths when labels are scarce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a multi-task extension of prediction-powered inference (PPI) that leverages labeled data from related tasks via cross-task recalibration to improve power for task-specific inference while preserving validity through within-task rectification and power tuning. It proves that efficiency gains beyond power-tuned PPI require nonlinear structure in the proxy-ground-truth relationship and that affine cross-task recalibrations are asymptotically equivalent to the original proxy. Theoretical results are supported by synthetic and semi-synthetic experiments plus a case study auditing language models on 2024 election-related information using human annotations.
Significance. If the central claims hold, the work is significant for AI evaluation and social-science applications that require valid inference across many related tasks with scarce labels. The proof that gains are possible only under nonlinear structure, together with the negative result on affine recalibrations, supplies a clear boundary condition that is useful for practitioners. The retention of within-task rectification directly supports task-specific validity. The real-world case study adds practical value. The combination of theory with reproducible-style experiments on semi-synthetic data is a strength.
minor comments (3)
- Abstract: the phrase 'power-tuned PPI' is used without a one-sentence reminder of its definition or a citation to the base method, which reduces accessibility for readers outside the immediate PPI literature.
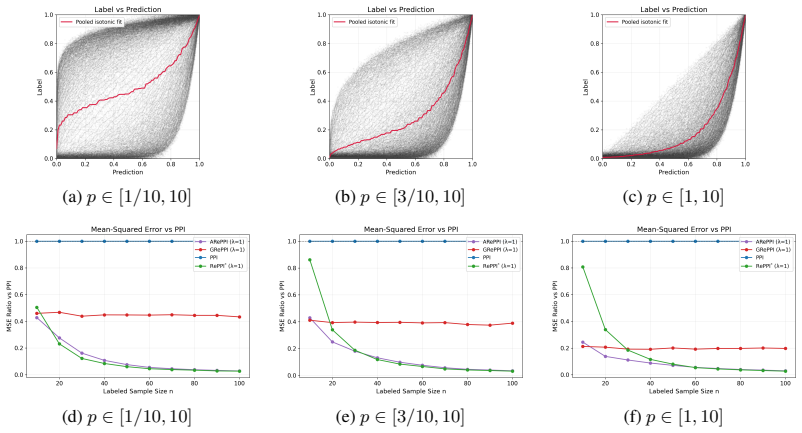
- §5 (experiments): the description of how the semi-synthetic data were constructed to satisfy the nonlinear-structure condition could be expanded with one additional sentence or a small table listing the functional forms used.
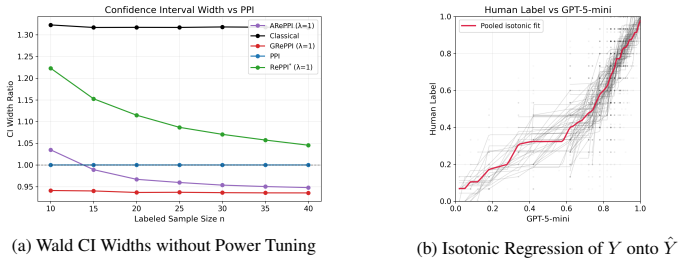
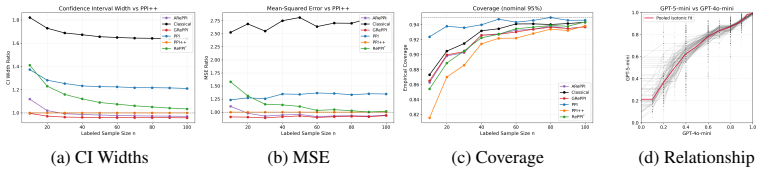
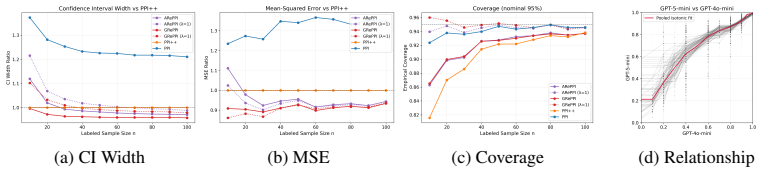
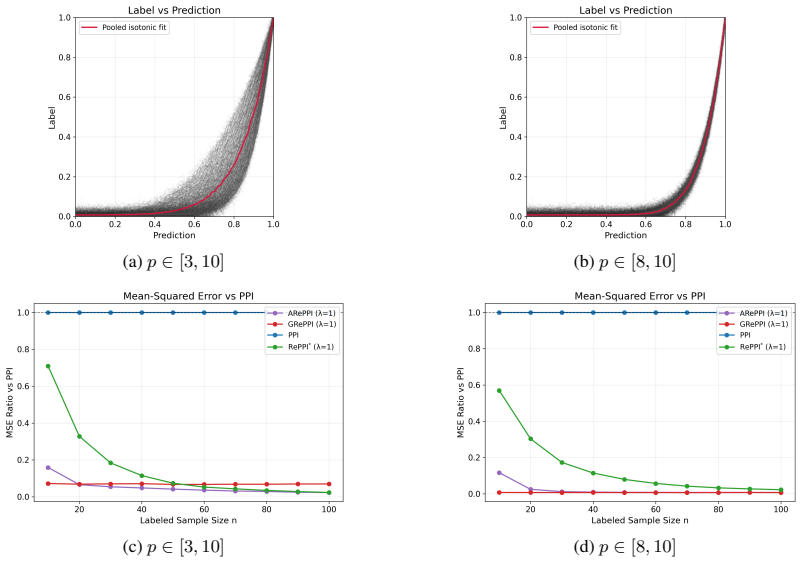
- Figure 4 (case study): axis labels on the confidence-interval-width plot are slightly compressed; increasing font size or adding a short caption note would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, including the recognition of its significance for AI evaluation and social-science applications, the value of the theoretical boundary conditions, and the practical utility of the case study. We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity detected
full rationale
The paper extends PPI with a multi-task recalibration framework and supplies an asymptotic proof that efficiency gains require nonlinear proxy-ground-truth structure while affine recalibrations are equivalent to the base proxy. These results are derived from standard statistical arguments (asymptotics, task-specific rectification) that remain independent of the paper's own fitted quantities or self-citations. No step reduces by construction to a parameter fit or prior self-citation; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Related tasks share a common structure in the proxy-ground-truth relationship that cross-task recalibration can exploit.
Forward citations
Cited by 1 Pith paper
-
Valid Inference with Synthetic Data via Task Exchangeability
Proposes task exchangeability as a condition for valid inference when using synthetic data in scientific research, with methods and extensions demonstrated on surveys and AI evaluations.
Reference graph
Works this paper leans on
-
[1]
PPI++: Efficient Prediction-Powered Inference
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023a. Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. PPI++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023b. Julia Angwin, Alondra Nelson, and Rina Palta. Seeking...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, et al. Foundational challenges in assuring alignment and safety of large language models.arXiv preprint arXiv:2404.09932,
-
[3]
Large-scale, longitudinal study of large language models during the 2024 US election season
Sarah H Cen, Andrew Ilyas, Hedi Driss, Charlotte Park, Aspen Hopkins, Chara Podimata, et al. Large-scale, longitudinal study of large language models during the 2024 US election season. arXiv preprint arXiv:2509.18446,
-
[4]
Precise model benchmarking with only a few observations
Riccardo Fogliato, Pratik Patil, Nil-Jana Akpinar, and Mathew Monfort. Precise model benchmarking with only a few observations. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9563–9575,
2024
-
[5]
Jessica Gronsbell, Jianhui Gao, Zachary R McCaw, Yaqi Shi, and David Cheng. Another look at statistical inference with machine learning-imputed data.arXiv preprint arXiv:2411.19908,
-
[6]
Predictions as Surrogates: Revisiting Surrogate Outcomes in the Age of AI
Wenlong Ji, Lihua Lei, and Tijana Zrnic. Predictions as surrogates: Revisiting surrogate outcomes in the age of AI.arXiv preprint arXiv:2501.09731,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reagan Mozer. PPI is the difference estimator: Recognizing the survey sampling roots of prediction- powered inference.arXiv preprint arXiv:2603.19160,
-
[8]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13387–13434,
2023
-
[9]
Demystifying prediction powered inference
Yilin Song, Dan M Kluger, Harsh Parikh, and Tian Gu. Demystifying prediction powered inference. arXiv preprint arXiv:2601.20819,
-
[10]
Calibeating Prediction-Powered Inference
Lars van der Laan and Mark van der Laan. Calibeating prediction-powered inference.arXiv preprint arXiv:2604.21260,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Meta-theorizing framing in communication research (1992–2022): Toward academic silos or professionalized specialization?Journal of Communication, 74(2): 101–116,
Dror Walter and Yotam Ophir. Meta-theorizing framing in communication research (1992–2022): Toward academic silos or professionalized specialization?Journal of Communication, 74(2): 101–116,
1992
-
[12]
Can LLMs ex- press their uncertainty? An empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs ex- press their uncertainty? An empirical evaluation of confidence elicitation in LLMs. InInternational Conference on Learning Representations, volume 2024, pages 23650–23678,
2024
-
[13]
Fix a recalibration map s and write the shorthands i :=s(X i)
15 A Missing Derivations and Proofs A.1 Derivation of Oracle VarianceV(s, λ) We derive the variance functional used in Section 2.4. Fix a recalibration map s and write the shorthands i :=s(X i). Letλ∈Rbe the scalar power-tuning coefficient. Using the shorthands ¯YL := 1 n X i∈L Yi,¯s L := 1 n X i∈L si,¯s N := 1 N X i∈[N] si, the power-tuned estimator from...
1952
-
[14]
This can also be rewritten as Var[ˆZ] = 1 n 1− n N S2 Z whereS 2 Z = 1 N−1 X i∈[N] (Zi − ¯Z)2 is the sample variance
we can express Var[¯ZL] = 1 n 1− n−1 N−1 σ2 Z, whereσ 2 Z = 1 N P i∈[N](Zi − ¯Z)2. This can also be rewritten as Var[ˆZ] = 1 n 1− n N S2 Z whereS 2 Z = 1 N−1 X i∈[N] (Zi − ¯Z)2 is the sample variance. We will approximate the latter with the plug-in estimate ˆS2 Z = 1 n−1 X i∈L (Zi − ¯ZL)2, that satisfies S2 Z =E[ ˆS2 Z] under simple random sampling (e.g.,...
2025
-
[15]
Substituting back and writing ρ2 N(Y, s) := Cov N(Y, s)2/(VarN(Y) VarN(s)) for the finite- population squared correlation, we get V ⋆(s) = 1 n 1− n N S2 Y 1−ρ 2 N(Y, s)
The minimizer is therefore λ⋆(s) = CovN(Y, s) VarN(s) . Substituting back and writing ρ2 N(Y, s) := Cov N(Y, s)2/(VarN(Y) VarN(s)) for the finite- population squared correlation, we get V ⋆(s) = 1 n 1− n N S2 Y 1−ρ 2 N(Y, s) . 16 A.2 Derivations for the Superpopulation Case The variance expression in Appendix A.1 differs from the standard superpopulation ...
2025
-
[16]
[2025], finite-population, mean-estimation adaptation) Require:Task datasetD (t) = ( ˆY (t) i , Y (t) i , O(t) i )N i=1, recalibration classH
Algorithm 3REPPI (Ji et al. [2025], finite-population, mean-estimation adaptation) Require:Task datasetD (t) = ( ˆY (t) i , Y (t) i , O(t) i )N i=1, recalibration classH. 1:Randomly splitL (t) evenly into two foldsAandB. 2:For eachF∈ {A, B}, fitˆs F ∈ Hon{( ˆY (t) i , Y (t) i )}i∈F so thatˆsF ( ˆY (t))≈E N[Y (t) | ˆY (t)].▷ collapses Steps 2–3 of Ji et al...
2025
-
[17]
Algorithm 2)
• AREPPI :r (t) i =Y (t) i − ˆλoof L(t) u(t) i (c.f. Algorithm 2). A few remarks. The SE plug-ins above treat ˆλ and ˆsas fixed, resulting in bias in small samples, and we empirically diagnose its small-n effect on coverage in Fig. 3 (a)–(d) when power tuning is used. We note in the experiments that power tuning is often not necessary if tasks are suffici...
2025
-
[18]
endogenous
Thus, for any given model, there is one fixed response for a given query. To focus our analysis on the most relevant factors, we systematically prune the models, base questions, and prompt variations from the original dataset. Models (M):We restrict our attention to the offline versions of three prominent models: GPT-4o, Claude-3.5-Sonnet, and Gemini-1.0-...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.