GitReq: A Gold Standard Dataset for Software Quality Requirements
Pith reviewed 2026-06-26 12:19 UTC · model grok-4.3
The pith
The paper builds and releases GitReq, a dataset of 6302 expert-labeled GitHub requirements across eight ISO-aligned quality categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
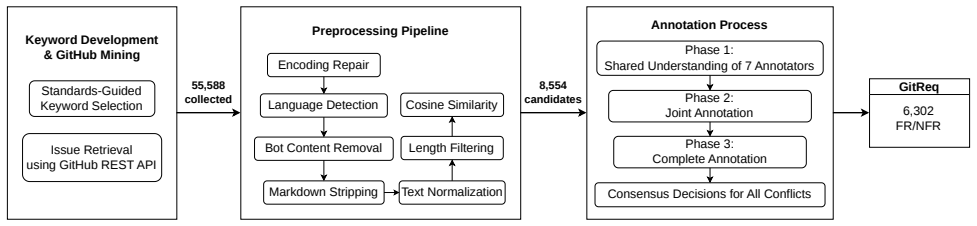
The authors construct GitReq by applying category-specific triple-signal mining to 55588 raw GitHub issues from 4080 repositories, running separate preprocessing for non-functional and functional requirements with per-category parameters, and obtaining expert labels on 6302 items that achieve Fleiss' Kappa of approximately 0.72. They also report zero-shot LLM baselines, with the strongest model reaching macro-averaged F1 of 0.641. The full dataset and materials are released publicly to support research on automated requirement classification and software quality analysis.
What carries the argument
Category-specific triple-signal GitHub mining together with separate NFR and FR preprocessing pipelines and expert human annotation.
If this is right
- Automated classifiers for the eight categories can now be trained and compared against a shared, publicly validated set.
- Studies of how quality requirements appear in real developer discussions gain a standardized collection from thousands of repositories.
- Zero-shot and fine-tuned LLM performance on requirement classification can be measured directly against the provided baselines.
- Tools for early detection of performance, security, and other issues in open-source projects can draw on the labeled examples.
Where Pith is reading between the lines
- The dataset could serve as a testbed for checking whether models trained on one category transfer to others within the same collection.
- Future mining efforts might adapt the triple-signal approach to additional issue trackers or to closed-source project data.
- The separate NFR and FR pipelines suggest that mixed requirement text requires distinct handling to avoid category confusion.
- Researchers could examine label distributions across repositories to test whether quality concerns vary systematically by project size or domain.
Load-bearing premise
The mining signals, preprocessing choices, and expert labels together produce an accurate and representative collection of quality requirements without major selection bias or labeling mistakes.
What would settle it
A random sample of the released dataset showing a high rate of incorrect category assignments or a clear pattern of missing common quality concerns from other repositories would undermine the claim of a reliable gold-standard resource.
Figures
read the original abstract
GitHub issue trackers contain millions of developer-written quality concerns, including performance bottlenecks and security vulnerabilities, yet no publicly available GitHub dataset classifies these into fine-grained software quality categories. We construct and release GitReq GitHub Requirement Issue, comprising 6,302 expert-validated requirements mined from 55,588 raw GitHub candidates across 4,080 repositories, labeled across eight ISO/IEC 25010:2011-aligned categories: Performance, Security, Portability, Availability, Fault-tolerance, Scalability, Maintainability, and a Functional baseline. Dataset construction involved category-specific triple-signal GitHub mining, separate non-functional requirement (NFR) and functional requirement (FR) preprocessing pipelines with per-category parameters, and expert human annotation achieving substantial inter-annotator agreement (Fleiss' Kappa~=~0.72). Zero-shot evaluation with four large language models (LLMs) establishes baselines, with GPT-5.2 reaching the highest macro-averaged F1 of 0.641. GitReq is publicly released with full materials to advance research in automated requirement classification and software quality analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GitReq, a publicly released dataset of 6,302 expert-validated GitHub issues labeled as software quality requirements across eight ISO/IEC 25010:2011-aligned categories (Performance, Security, Portability, Availability, Fault-tolerance, Scalability, Maintainability, and Functional). The data were mined from 55,588 raw candidates in 4,080 repositories using category-specific triple-signal GitHub mining, separate NFR/FR preprocessing pipelines with per-category parameters, and expert annotation that achieved Fleiss' Kappa of 0.72; zero-shot LLM baselines are also reported, with the best model reaching macro F1 of 0.641.
Significance. If the construction pipeline yields a representative and accurately labeled collection, the dataset would address a documented gap in publicly available fine-grained GitHub data for quality-requirement classification, supporting downstream work on automated tools and software-quality analysis. The public release together with full materials and LLM baselines is a concrete contribution that lowers the barrier for reproducible research in this area.
major comments (2)
- [Dataset construction and annotation sections] The central claim that the resulting set constitutes a 'gold standard' rests on the assertion that the triple-signal mining plus expert annotation produces an accurate and representative collection without major selection bias or labeling errors. However, the manuscript provides insufficient detail on data exclusion criteria, the precise definition of the three signals per category, and any post-annotation error analysis or disagreement resolution protocol; these omissions are load-bearing for the validity of the released labels.
- [Preprocessing pipelines] The per-category parameters used in the separate NFR and FR preprocessing pipelines are described only at a high level; without explicit values or a sensitivity analysis, it is difficult to assess whether the final 6,302-item count and category distribution are robust or could shift substantially under reasonable alternative parameter choices.
minor comments (2)
- [Abstract and evaluation section] Clarify the exact model referred to as 'GPT-5.2' in the abstract and results; if this is a non-standard or internal designation, state the public model identifier used for the reported F1 score.
- [Abstract] The abstract states the dataset is 'publicly released with full materials'; the manuscript should include a direct link or DOI to the repository and confirm that the raw mined candidates, annotation guidelines, and inter-annotator raw data are included.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our dataset construction and preprocessing details. We address each major comment below, agreeing that expansions are warranted to strengthen the manuscript's transparency.
read point-by-point responses
-
Referee: [Dataset construction and annotation sections] The central claim that the resulting set constitutes a 'gold standard' rests on the assertion that the triple-signal mining plus expert annotation produces an accurate and representative collection without major selection bias or labeling errors. However, the manuscript provides insufficient detail on data exclusion criteria, the precise definition of the three signals per category, and any post-annotation error analysis or disagreement resolution protocol; these omissions are load-bearing for the validity of the released labels.
Authors: We agree that additional explicit details are required to fully support the gold-standard claim. In the revised manuscript we will expand the Dataset Construction section with: (1) the complete list of data exclusion criteria applied after initial mining, (2) precise, category-by-category definitions and examples of each of the three signals, and (3) a description of the post-annotation error analysis performed together with the exact protocol used to resolve annotator disagreements. These additions will be accompanied by references to the released annotation guidelines and raw agreement data. revision: yes
-
Referee: [Preprocessing pipelines] The per-category parameters used in the separate NFR and FR preprocessing pipelines are described only at a high level; without explicit values or a sensitivity analysis, it is difficult to assess whether the final 6,302-item count and category distribution are robust or could shift substantially under reasonable alternative parameter choices.
Authors: We acknowledge that the current description of per-category parameters is insufficiently detailed. In the revision we will add an appendix table that enumerates every explicit parameter value used in both the NFR and FR pipelines for each of the eight categories. We will also include a limited sensitivity analysis on the most influential parameters (e.g., keyword thresholds and repository filters) to demonstrate that the final dataset size and category distribution remain stable under modest perturbations. revision: yes
Circularity Check
No significant circularity
full rationale
This is a dataset construction and release paper. The central claims consist of counts of mined and annotated issues (6,302 from 55,588 candidates), category alignment to an external ISO standard, reported Fleiss' Kappa of ~0.72, and zero-shot LLM baseline scores on the released dataset. No equations, fitted parameters, predictions, or derivations appear. No self-citations are invoked as load-bearing premises for any uniqueness theorem or ansatz. The pipeline (triple-signal mining + expert annotation) is asserted to produce the dataset; the reported statistics are direct outputs of that process rather than reductions to the inputs by construction. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-category parameters
axioms (1)
- domain assumption ISO/IEC 25010:2011 defines the eight quality categories used for labeling
Reference graph
Works this paper leans on
-
[1]
ISO/IEC 25010:2011 System and software quality models,
ISO/IEC, “ISO/IEC 25010:2011 System and software quality models,” 2011
2011
-
[2]
Software defect reduction top 10 list,
B. W. Boehm and V . R. Basili, “Software defect reduction top 10 list,” Computer, vol. 34, no. 1, pp. 135–137, Jan. 2001
2001
-
[3]
Chung, B
L. Chung, B. A. Nixon, E. Yu, and J. Mylopoulos,Non-Functional Requirements in Software Engineering. Boston, MA: Springer, 1999
1999
-
[4]
On non-functional requirements,
M. Glinz, “On non-functional requirements,” inRE ’07, pp. 21–26
-
[5]
NoRBERT: Transfer learning for requirements classification,
T. Hey, J. Keim, J. Koziolek, and W. F. Tichy, “NoRBERT: Transfer learning for requirements classification,” inRE ’20, pp. 169–179
-
[6]
PURE: A dataset of public requirements documents,
A. Ferrari, G. O. Spagnolo, and S. Gnesi, “PURE: A dataset of public requirements documents,” inRE ’17, pp. 502–505
-
[7]
GitHub REST API documentation,
GitHub, “GitHub REST API documentation,” 2024. [Online]. Available: https://docs.github.com/en/rest
2024
-
[8]
ftfy: Fixes text for you,
R. Speer, “ftfy: Fixes text for you,” 2023. [Online]. Available: https: //github.com/rspeer/python-ftfy
2023
-
[9]
langdetect: Language detection library,
M. Danil ´ak, “langdetect: Language detection library,” 2021. [Online]. Available: https://github.com/Mimino666/langdetect
2021
-
[10]
LLaMA: Open and efficient foundation language models,
H. Touvronet al., “LLaMA: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[11]
Gemma Team at Google DeepMind, “Gemma 3 Technical Report,”arXiv preprint arXiv:2503.19786, 2025
Pith/arXiv arXiv 2025
-
[12]
A. Q. Jianget al., “Mistral 7B,”arXiv preprint arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[13]
Automatic multi-class non-functional software require- ments classification using neural networks,
C. Bakeret al., “Automatic multi-class non-functional software require- ments classification using neural networks,” inCOMPSAC ’19, vol. 2, pp. 610–615
-
[14]
J. Cleland-Huanget al., “nfr [Data set],” Zenodo, 2007. http://doi.org/ 10.5281/zenodo.268542
-
[15]
PRCBERT: Prompt learning for requirement classification using BERT-based pretrained language models,
X. Luo, Y . Xue, Z. Xing, and J. Sun, “PRCBERT: Prompt learning for requirement classification using BERT-based pretrained language models,” inASE ’22, pp. 1–12
-
[16]
Measuring nominal scale agreement among many raters,
J. L. Fleiss, “Measuring nominal scale agreement among many raters,” Psychological Bulletin, vol. 76, no. 5, pp. 378–382, 1971
1971
-
[17]
A four-dimension gold standard dataset for opinion mining in software engineering,
M. Islamet al., “A four-dimension gold standard dataset for opinion mining in software engineering,” inMSR ’24, pp. 487–491
-
[18]
PROMISE exp: A dataset for software requirements classification,
D. Limaet al., “PROMISE exp: A dataset for software requirements classification,” inSBES ’19, pp. 427–436
-
[19]
FR NFR: Functional and non-functional re- quirements dataset,
S. Idate and M. Rao, “FR NFR: Functional and non-functional re- quirements dataset,” Mendeley Data, V1, 2024. https://doi.org/10.17632/ 4ysx9fyzv4.1
2024
-
[20]
NICE: A multi-label non-functional requirements classification dataset with interpretable explanations,
A. Rejithkumar and A. Anish, “NICE: A multi-label non-functional requirements classification dataset with interpretable explanations,” in ICSE ’25
-
[21]
A semantic preprocessing framework for breaking news detection to support future drone journalism services,
M. Niarchoset al., “A semantic preprocessing framework for breaking news detection to support future drone journalism services,”Future Internet, vol. 14, no. 1, p. 26, Jan. 2022
2022
-
[22]
Introducing GPT-5,
OpenAI, “Introducing GPT-5,” 2025. [Online]. Available: https://openai. com/index/introducing-gpt-5/
2025
-
[23]
GitReq Dataset and Evaluation Prompt, 2026. [Online]. Available: https: //doi.org/10.6084/m9.figshare.31669477
-
[24]
Tool competition
R. Kalliset al., “Tool competition”, inNLBSE ’23, pp. 1–8
-
[25]
Zero-shot learning for require- ments classification: An exploratory study,
W. Alhoshan, A. Ferrari, and L. Zhao, “Zero-shot learning for require- ments classification: An exploratory study,”Information and Software Technology, vol. 159, p. 107-202
-
[26]
Robust or overfitted? Investigating the general- ization of pretrained models in requirement classification,
F. Kamal and M. Islam, “Robust or overfitted? Investigating the general- ization of pretrained models in requirement classification,” inESEM ’25, pp. 414–420
-
[27]
Decoding the Decoders: An Empirical Study of Reverse Engineering Questions on Stack Exchange,
M. Islamet al., “Decoding the Decoders: An Empirical Study of Reverse Engineering Questions on Stack Exchange,”IEEE TPS-ISA, Pittsburgh, PA, USA, 2025, pp. 226-236
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.