OpenRCA 2.0: From Outcome Labels to Causal Process Supervision
Pith reviewed 2026-06-26 04:26 UTC · model grok-4.3
The pith
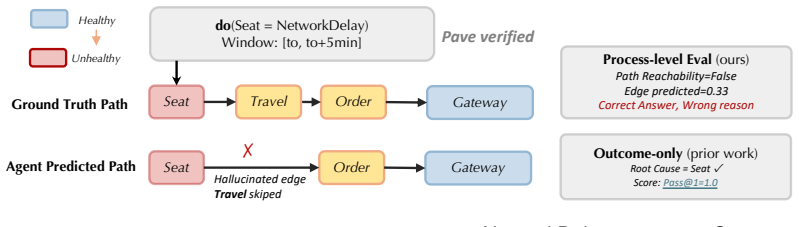
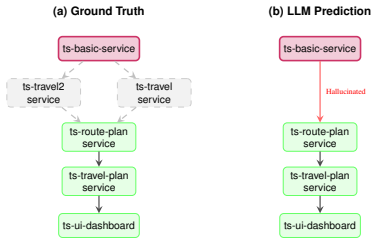
Step-wise causal annotations reveal LLM agents ground correct root-cause services in verified paths in only 61.5 percent of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
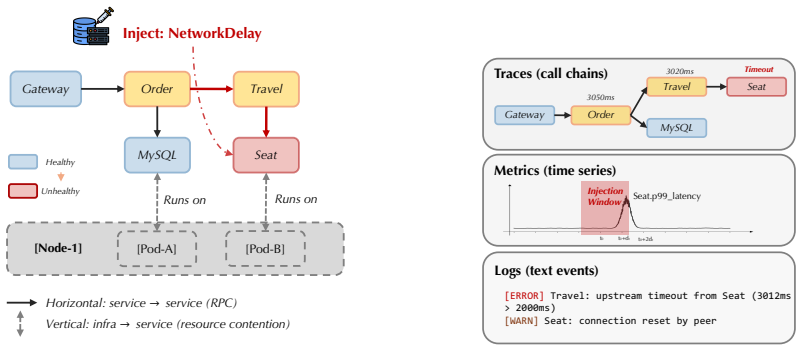
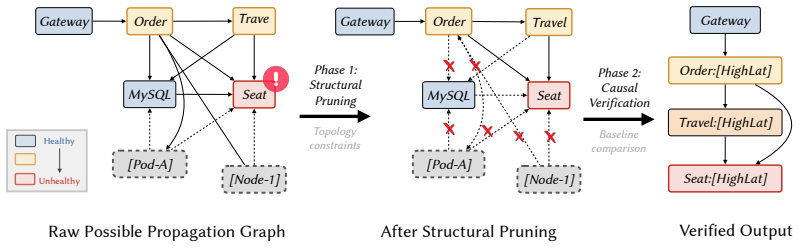
The PAVE protocol reconstructs causal propagation paths from known fault injection interventions using forward verification from cause to effect rather than backward inference from symptoms. Applying it creates OpenRCA 2.0, the first cross-system RCA benchmark with step-wise causal annotations. Across 11 frontier LLMs, recovering the exact root-cause set succeeds in only 20.7 percent of cases. Agents identify at least one correct root-cause service in 76.0 percent of cases but ground that service in a verified causal propagation path to the observed symptom in only 61.5 percent. Outcome-only evaluation hides this failure mode; step-wise causal ground truth is required for trustworthy LLM-bas
What carries the argument
The PAVE protocol, which reconstructs causal propagation paths using known interventions from fault injection experiments through forward verification from cause to effect.
If this is right
- Exact recovery of the complete root-cause set occurs in roughly one-fifth of cases across current frontier models.
- The 14.5 percentage point gap between naming a correct service and verifying its causal path to the symptom persists under relaxed criteria.
- Outcome-only benchmarks systematically underestimate the difficulty of producing reliable RCA diagnoses.
- Agent training and evaluation must incorporate supervision on intermediate causal propagation steps rather than final outcomes alone.
Where Pith is reading between the lines
- If path reconstruction proves harder than service identification, methods that explicitly supervise intermediate reasoning steps during training could narrow the observed grounding gap.
- The same distinction between naming a correct entity and tracing its causal role may appear in other multi-step diagnostic domains such as medical or network troubleshooting.
- The low exact-match rate suggests that simply scaling model size without changes to supervision signals is unlikely to close the performance shortfall on path-grounded RCA.
Load-bearing premise
The PAVE protocol accurately captures complete and unbiased causal structures without missing paths or artifacts from the injection process.
What would settle it
A direct comparison in which the same LLM agents are evaluated on identical RCA instances once with only outcome labels and once with the requirement to output the full verified causal path, checking whether the 14.5-point gap between service identification and path grounding disappears.
Figures
read the original abstract
Root cause analysis (RCA) poses a holistic test of LLM agentic capabilities, such as long-context understanding, multi-step reasoning, and tool use. However, existing datasets suffer from a fundamental gap: they label only the root cause, not the propagation path connecting it to the observed symptom, which largely simplifies the task to naive pattern matching. To support rigorous evaluation, we introduce PAVE, a step-wise labeling protocol that leverages known interventions from fault injection to reconstruct causal propagation paths. The mechanism is forward verification: reasoning from cause to effect rather than inferring backward from symptoms. Applying PAVE yields OpenRCA 2.0 (500 instances), the first cross-system RCA benchmark with step-wise causal annotations for LLM agents. Across 11 frontier LLMs, recovering the exact root-cause set succeeds in only 20.7% of cases on average. To locate where this difficulty lies, we relax the criterion and find what we call the ungrounded diagnosis: agents identify at least one correct root-cause service in 76.0% of cases, but ground that service in a verified causal propagation path to the observed symptom in only 61.5%. Outcome-only evaluation hides this failure mode; step-wise causal ground truth is the missing piece for trustworthy LLM-based RCA agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the PAVE protocol, which reconstructs causal propagation paths via forward verification from known fault-injection interventions, to create OpenRCA 2.0—a 500-instance cross-system RCA benchmark with step-wise causal annotations. It evaluates 11 frontier LLMs and reports that exact root-cause set recovery averages 20.7%, while agents identify at least one correct root-cause service in 76.0% of cases but ground that service in a verified causal path in only 61.5%, arguing that outcome-only labels hide this failure mode.
Significance. If the ground-truth paths are reliable, the work supplies a concrete, falsifiable demonstration that current LLM agents frequently produce ungrounded diagnoses in RCA settings and supplies the first publicly described step-wise causal benchmark for the task. The distinction between service identification and path grounding is a useful diagnostic lens for agent evaluation.
major comments (2)
- [Abstract] Abstract: the central performance gap (76.0 % service hit vs. 61.5 % grounded path) is presented as evidence of a distinct failure mode, yet the manuscript supplies no quantitative check (e.g., comparison against observational causal discovery, expert review, or held-out interventions) that the PAVE-reconstructed paths are complete and free of injection-specific artifacts. This validation is load-bearing for interpreting the gap as a property of the models rather than of the reference.
- [Dataset section] Dataset section: no information is provided on inter-annotator agreement for the causal-path labels, the selection criteria used to arrive at the final 500 instances, or the distribution of systems and fault types. These details are required to assess whether the reported averages are robust to selection effects or label noise.
minor comments (1)
- [Abstract] The abstract states results to one decimal place but does not indicate whether the 500 instances are balanced across systems; adding this context would improve interpretability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance gap (76.0 % service hit vs. 61.5 % grounded path) is presented as evidence of a distinct failure mode, yet the manuscript supplies no quantitative check (e.g., comparison against observational causal discovery, expert review, or held-out interventions) that the PAVE-reconstructed paths are complete and free of injection-specific artifacts. This validation is load-bearing for interpreting the gap as a property of the models rather than of the reference.
Authors: The PAVE protocol reconstructs paths via forward verification from known fault-injection interventions, providing an interventional (not observational) basis that directly tests each propagation step from cause to observed symptom. This design is intended to ensure completeness and minimize injection-specific artifacts. We will revise the abstract and methods to more explicitly articulate how the forward-verification mechanism itself serves as the quantitative check and to include any expert review or held-out validation steps performed. We view this as a clarification rather than a fundamental change to the protocol. revision: partial
-
Referee: [Dataset section] Dataset section: no information is provided on inter-annotator agreement for the causal-path labels, the selection criteria used to arrive at the final 500 instances, or the distribution of systems and fault types. These details are required to assess whether the reported averages are robust to selection effects or label noise.
Authors: The referee correctly notes that these details are absent from the current Dataset section. We will expand the section to report inter-annotator agreement statistics for the causal-path labels, describe the selection criteria applied to reach the final 500 instances, and provide the distribution of systems and fault types. These additions will allow readers to evaluate robustness to selection effects and label noise. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper constructs OpenRCA 2.0 by applying the PAVE protocol (forward verification from known fault-injection interventions) to produce step-wise causal labels, then measures LLM performance directly on the resulting 500 instances. No equations, fitted parameters, self-citations used as load-bearing premises, or derivations appear in the provided text. All reported figures (20.7 %, 76.0 %, 61.5 %) are raw empirical counts on the newly labeled data; the central claims do not reduce to prior quantities by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fault injection experiments provide complete and accurate causal propagation paths without missing links or injection artifacts.
invented entities (2)
-
PAVE protocol
no independent evidence
-
OpenRCA 2.0 dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Openrca: Can large language models locate the root cause of software failures? InThe Thirteenth International Conference on Learning Representations, 2025
Junjielong Xu, Qinan Zhang, Zhiqing Zhong, Shilin He, Chaoyun Zhang, Qingwei Lin, Dan Pei, Pinjia He, Dongmei Zhang, and Qi Zhang. Openrca: Can large language models locate the root cause of software failures? InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[2]
Aiopslab: A holistic framework to evaluate ai agents for enabling autonomous clouds
Yinfang Chen, Manish Shetty, Gagan Somashekar, Minghua Ma, Yogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia Wang, and Saravan Rajmohan. Aiopslab: A holistic framework to evaluate ai agents for enabling autonomous clouds. InMLSys, 2025. URL https:// openreview.net/forum?id=3EXBLwGxtq
2025
-
[3]
Yinfang Chen, Jiaqi Pan, Jackson Clark, Yiming Su, Noah Zheutlin, Bhavya Bhavya, Rohan Arora, Yu Deng, Saurabh Jha, and Tianyin Xu. Stratus: A multi-agent system for autonomous reliability engineering of modern clouds.arXiv preprint arXiv:2506.02009v2, 05 2025. URL https://arxiv.org/abs/2506.02009v2
arXiv 2025
-
[4]
Thinkfl: Self-refining failure localization for microservice systems via reinforcement fine-tuning.ACM Transactions on Software Engineering and Methodology,
Lingzhe Zhang, Yunpeng Zhai, Tong Jia, Chiming Duan, Siyu Yu, Jinyang Gao, Bolin Ding, Zhonghai Wu, and Ying Li. Thinkfl: Self-refining failure localization for microservice systems via reinforcement fine-tuning.ACM Transactions on Software Engineering and Methodology,
-
[5]
URLhttps://doi.org/10.1145/3789262
doi: 10.1145/3789262. URLhttps://doi.org/10.1145/3789262
-
[6]
Fault analysis and debugging of microservice systems: Industrial survey, benchmark system, and empirical study.IEEE Transactions on Software Engineering, 47(2):243–260, 2018
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Wenhai Li, and Dan Ding. Fault analysis and debugging of microservice systems: Industrial survey, benchmark system, and empirical study.IEEE Transactions on Software Engineering, 47(2):243–260, 2018
2018
-
[7]
Rcaeval: A bench- mark for root cause analysis of microservice systems with telemetry data
Luan Pham, Hongyu Zhang, Huong Ha, Flora Salim, and Xiuzhen Zhang. Rcaeval: A bench- mark for root cause analysis of microservice systems with telemetry data. InCompanion Proceedings of the ACM on Web Conference 2025, pages 777–780, 2025
2025
-
[8]
Aoyang Fang, Songhan Zhang, Yifan Yang, Haotong Wu, Junjielong Xu, Xuyang Wang, Rui Wang, Manyi Wang, Qisheng Lu, and Pinjia He. Rethinking the evaluation of microservice rca with a fault propagation-aware benchmark.arXiv preprint arXiv:2510.04711v2, 10 2025. URL https://arxiv.org/abs/2510.04711v2
arXiv 2025
-
[9]
Cambridge university press, 2009
Judea Pearl.Causality. Cambridge university press, 2009
2009
-
[10]
Wei Liu, Siya Qi, Yali Du, and Yulan He. Self-play only evolves when self-synthetic pipeline ensures learnable information gain.arXiv preprint arXiv:2603.02218v1, 02 2026. URL https://arxiv.org/abs/2603.02218v1
Pith/arXiv arXiv 2026
-
[11]
https://github.com/delimitrou/DeathStarBench/tree/master,
Deathstarbench. https://github.com/delimitrou/DeathStarBench/tree/master,
-
[12]
Accessed: 2026-02-10
2026
-
[13]
https://github.com/open-telemetry/opentelemetry-demo,
Opentelemetry demo. https://github.com/open-telemetry/opentelemetry-demo,
-
[14]
Accessed: 2026-05-05
2026
-
[15]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[16]
Self-balancing agentic AI: Test-time diffusion and context engineering re-imagined for deep research.https://github.com/thinkdepthai/Deep_Research, 2025
Paichun Lin. Self-balancing agentic AI: Test-time diffusion and context engineering re-imagined for deep research.https://github.com/thinkdepthai/Deep_Research, 2025
2025
-
[17]
Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments
Guangba Yu, Pengfei Chen, Hongyang Chen, Zijie Guan, Zicheng Huang, Linxiao Jing, Tianjun Weng, Xinmeng Sun, and Xiaoyun Li. Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments. InProceedings of the Web Conference 2021, pages 3087–3098, 2021. 10
2021
-
[18]
Songhan Zhang, Aoyang Fang, Yifan Yang, Ruiyi Cheng, Xiaoying Tang, and Pinjia He. Dynacausal: Dynamic causality-aware root cause analysis for distributed microservices.arXiv preprint arXiv:2510.22613v1, 10 2025. URLhttps://arxiv.org/abs/2510.22613v1
arXiv 2025
-
[19]
MIT press, 2000
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, prediction, and search. MIT press, 2000
2000
-
[20]
Root cause analysis of failures in microservices through causal discovery.Advances in Neural Information Processing Systems, 35:31158–31170, 2022
Azam Ikram, Sarthak Chakraborty, Subrata Mitra, Shiv Saini, Saurabh Bagchi, and Murat Kocaoglu. Root cause analysis of failures in microservices through causal discovery.Advances in Neural Information Processing Systems, 35:31158–31170, 2022
2022
-
[21]
Root cause analysis of anomalies in multivariate time series through granger causal discovery
Xiao Han, Saima Absar, Lu Zhang, and Shuhan Yuan. Root cause analysis of anomalies in multivariate time series through granger causal discovery. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[22]
Zeyan Li, Nengwen Zhao, Shenglin Zhang, Yongqian Sun, Pengfei Chen, Xidao Wen, Minghua Ma, and Dan Pei. Constructing large-scale real-world benchmark datasets for aiops.arXiv preprint arXiv:2208.03938v1, 08 2022. URLhttps://arxiv.org/abs/2208.03938v1
arXiv 2022
-
[23]
Nezha: Interpretable fine-grained root causes analysis for microservices on multi-modal observability data
Guangba Yu, Pengfei Chen, Yufeng Li, Hongyang Chen, Xiaoyun Li, and Zibin Zheng. Nezha: Interpretable fine-grained root causes analysis for microservices on multi-modal observability data. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 553–565, 2023
2023
-
[24]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[25]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275v1, 11 2022. URL https://arxiv.org/abs/2211.14275v1
Pith/arXiv arXiv 2022
-
[26]
Versaprm: Multi-domain process reward model via synthetic reasoning data
Thomas Zeng, Shuibai Zhang, Shutong Wu, Christian Classen, Daewon Chae, Ethan Ewer, Minjae Lee, Heeju Kim, Wonjun Kang, Jackson Kunde, et al. Versaprm: Multi-domain process reward model via synthetic reasoning data. InForty-second International Conference on Machine Learning
-
[27]
Dynamic and generalizable process reward modeling
Zhangyue Yin, Qiushi Sun, Zhiyuan Zeng, Qinyuan Cheng, Xipeng Qiu, and Xuan-Jing Huang. Dynamic and generalizable process reward modeling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4203–4233, 2025
2025
-
[28]
Applicable Levels
Yibo Yan, Jiamin Su, Jianxiang He, Fangteng Fu, Xu Zheng, Yuanhuiyi Lyu, Kun Wang, Shen Wang, Qingsong Wen, and Xuming Hu. A survey of mathematical reasoning in the era of multimodal large language model: Benchmark, method & challenges. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11798–11827, 2025. 11 Appendix organization...
2025
-
[29]
query_parquet_files: DuckDB SQL on parquets in this case dir
-
[30]
list_tables_in_directory: list parquets
-
[31]
get_schema: column types of a parquet
-
[32]
## Hard limits •Tool-call budget: aim for∼50 calls; extend if the evidence genuinely warrants it
think_tool: REQUIRED after each query; summarize, plan next step. ## Hard limits •Tool-call budget: aim for∼50 calls; extend if the evidence genuinely warrants it. Hard cap is 100, at which point the runtime forces a stop. •Spend the budget efficiently: list_tables_in_directory once, get_schema on the files you actually plan to query, then spend the rest ...
-
[33]
list_tables_in_directory to confirm the parquet files
-
[34]
get_schema on the relevant ones (start with abnormal_traces)
-
[35]
Diff abnormal vs normal: error rates, latency, status codes, log levels
-
[36]
Trace the call chain (parent_span_id→span_id) to find the earliest service whose own work, not its dependency’s, went wrong
-
[37]
Agent Contract
Decide every root cause and every propagation edge. More than one root cause is possible; note each separately when evidence supports it. USER: RCA_ANAL YSIS_UP {incident_description} 24 F.4.2 Synthesis Phase SYSTEM: COMPRESS_FINDINGS_SP You are an RCA synthesizer. Today’s date is {date}. Your job: convert the investigation messages above into a single ST...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.