Performance Gap Analysis between Latin and Arabic Scripts HTR
Pith reviewed 2026-06-26 21:25 UTC · model grok-4.3
The pith
Arabic script HTR maintains a 5-7 CER point gap over Latin even after full data and label cleaning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
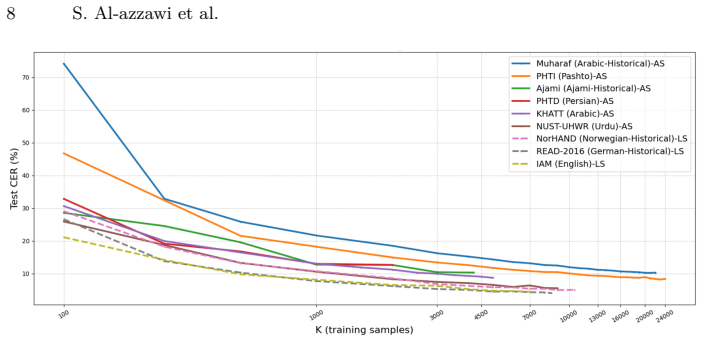
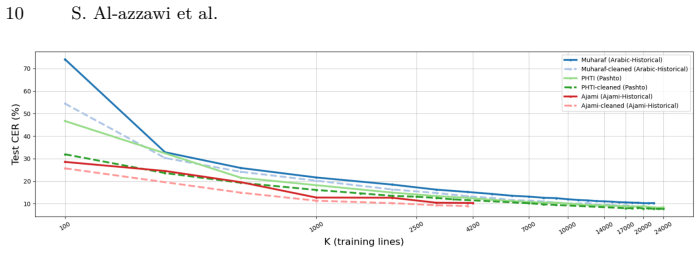
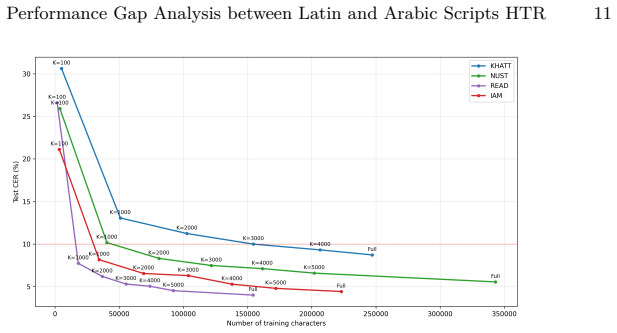
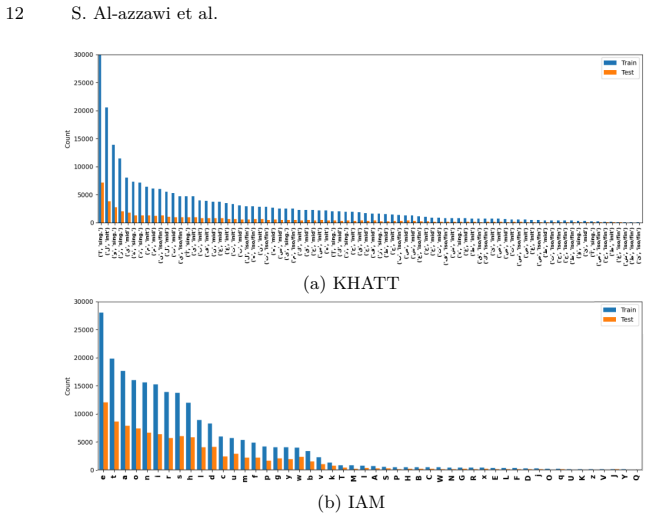
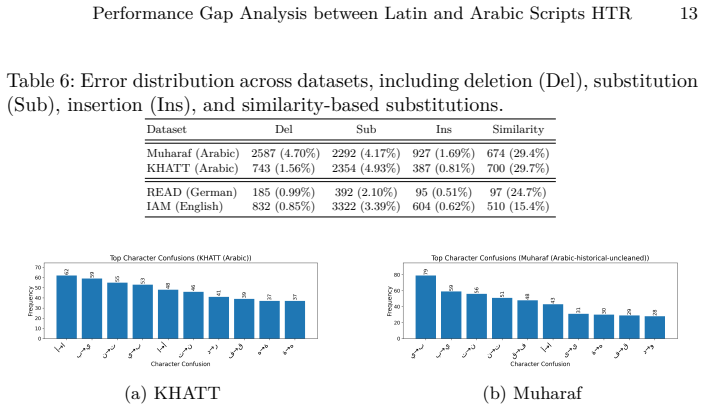
Across nine datasets and controlled training sizes the character error rate gap between Arabic and Latin scripts remains large at low data volumes, decreases with added samples, and persists at 5-7 points even at full scale. Cleaning annotation errors lowers rates on both sides and reduces the gap without closing it. The same number of training lines supplies less effective coverage for Arabic because of greater visual variability, Arabic character distributions are more heavy-tailed, and roughly 30 percent of Arabic substitution errors arise from visually similar characters versus about 15 percent in Latin.
What carries the argument
Unified CRNN model trained at matched data scales (K in 100, 500, 1000, …, full) on nine line-level datasets, followed by label cleaning and breakdown of substitution errors by visual similarity.
If this is right
- Increasing training data reduces but does not eliminate the performance gap.
- Label cleaning lowers error rates on both scripts and narrows the difference without removing it.
- A fixed number of text lines gives less coverage for Arabic than for Latin because of higher visual variability.
- Arabic character frequency distributions are markedly more heavy-tailed than Latin ones.
- Substitution errors caused by visually similar characters account for about 30 percent of Arabic mistakes versus 15 percent in Latin.
Where Pith is reading between the lines
- Future work could test whether targeted data augmentation for visually similar Arabic characters closes more of the gap than simply adding raw volume.
- The observed line-to-character equivalence trade-off suggests script-specific sampling rules when building new training sets.
- Repeating the controlled comparison on additional scripts would show whether the same pattern of persistent gap and substitution errors appears elsewhere.
Load-bearing premise
That the cleaning step and the single model choice have removed enough dataset-specific differences for any leftover gap to be attributed to script-intrinsic properties such as visual variability.
What would settle it
Re-annotating the same datasets to identical quality standards or training a new architecture and measuring no remaining 5-7 CER gap would show the difference is not script-intrinsic.
Figures


read the original abstract
Recent studies have shown that handwritten text recognition (HTR) systems perform worse on Arabic-script datasets than on Latin-script data. However, the reasons for this gap are still not well understood due to the lack of controlled comparisons. In this work, we present a comprehensive study of Arabic and Latin scripts HTR using a unified CRNN model for line-level HTR across nine datasets (including KHATT (Arabic), Muharaf (Arabic), NUST-UHWR (Urdu), PHTD (Persian), IAM (English), READ-2016 (German), and others) and di ferent training sizes (K in {100, 500, 1000, 2000, ..., Kfull}). Our results show the performance gap remains: it is large in low-resource settings, decreases with more data, but remains even at full scale, with a consistent difference of 5-7 CER points. We show that annotation quality matters, as many datasets contain labeling errors. Cleaning reduces error rates and narrows the gap, but does not eliminate it. In addition, we find that a fixed number of training samples provides less effective coverage in Arabic due to higher visual variability, requiring more data to learn similar representations. We compare recognition across datasets in terms of the number of text lines and the number of characters, showing an equivalence trade-off. We compare character frequency distributions across scripts and show that Arabic is significantly more heavy-tailed than Latin. Our error analysis reveals that around 30 percent of substitution errors in Arabic datasets (e.g., KHATT) are caused by confusion between visually similar characters, compared to about 15 percent in Latin-script datasets such as IAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical comparison of line-level HTR performance between Arabic-script (KHATT, Muharaf, NUST-UHWR, PHTD) and Latin-script (IAM, READ-2016 and others) datasets using a single CRNN architecture. It performs training-size sweeps (K=100 to full), an annotation-cleaning ablation, character-frequency analysis, and substitution-error breakdown. The central claim is that a 5-7 CER performance gap persists at full scale even after cleaning, narrows with more data, and is attributable to script-intrinsic factors including higher visual variability and heavier-tailed character distributions in Arabic scripts.
Significance. If the attribution to script properties survives controls for collection practices, the work supplies useful evidence on why Arabic-script HTR remains harder, quantifies the data-scaling behavior, and demonstrates that label cleaning narrows but does not close the gap. The unified-model protocol, systematic size sweeps, cleaning ablation, and error-type breakdown are concrete strengths that make the empirical pattern reproducible and falsifiable.
major comments (2)
- [Datasets] Datasets section: the claim that the remaining 5-7 CER gap after cleaning can be attributed to script-intrinsic properties (visual variability, heavy-tailed distributions) is load-bearing for the central conclusion, yet the paper provides no quantification or matching of collection practices (scan quality, writer demographics, document type, preprocessing) across the nine datasets. IAM (modern English) versus KHATT (historical Arabic) differ in acquisition conditions that can produce CER differences independently of script; the cleaning ablation addresses only label errors.
- [Results] Results section (full-scale comparison): the reported consistent 5-7 CER gap is presented without statistical tests or confidence intervals, so it is unclear whether the difference exceeds variability due to random seeds or test-set sampling.
minor comments (2)
- [Abstract] Abstract: 'di ferent' is a typographical error for 'different'.
- [Results] The phrase 'equivalence trade-off' between number of text lines and number of characters is used without a precise definition or supporting figure/table reference.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point by point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Datasets] Datasets section: the claim that the remaining 5-7 CER gap after cleaning can be attributed to script-intrinsic properties (visual variability, heavy-tailed distributions) is load-bearing for the central conclusion, yet the paper provides no quantification or matching of collection practices (scan quality, writer demographics, document type, preprocessing) across the nine datasets. IAM (modern English) versus KHATT (historical Arabic) differ in acquisition conditions that can produce CER differences independently of script; the cleaning ablation addresses only label errors.
Authors: We agree this is a substantive limitation. While the study controls for architecture, training size, and label noise via the cleaning ablation, it does not quantify or match acquisition conditions, writer demographics, or preprocessing across the nine datasets. IAM and KHATT, for example, differ in historical vs. modern content and scanning conditions. We will revise the discussion to explicitly note this potential confound, soften the attribution language from 'script-intrinsic properties' to 'factors that remain after controlling for label quality and model architecture, and are consistent with script-related differences such as character distributions,' and add a paragraph on the need for future matched-collection experiments. The multi-dataset pattern and character-frequency analysis still provide supporting evidence, but we accept that stronger causal attribution would require additional controls. revision: partial
-
Referee: [Results] Results section (full-scale comparison): the reported consistent 5-7 CER gap is presented without statistical tests or confidence intervals, so it is unclear whether the difference exceeds variability due to random seeds or test-set sampling.
Authors: We accept this point. The revised manuscript will add bootstrap-derived 95% confidence intervals on the full-scale CER differences and paired statistical tests (e.g., Wilcoxon or t-tests on per-run differences) to establish whether the 5-7 point gap is statistically reliable beyond seed and sampling variability. revision: yes
Circularity Check
No circularity: direct empirical measurements on held-out sets
full rationale
The paper reports CER results from training a standard CRNN on named public datasets (IAM, KHATT, etc.) at varying sizes, after label cleaning. All performance numbers and gap claims (5-7 CER points) are direct test-set measurements. No equations, fitted parameters renamed as predictions, self-citation chains, uniqueness theorems, or ansatzes appear in the derivation. The central attribution to script properties is an interpretation of the measurements, not a reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single CRNN architecture without script-specific modifications provides a fair comparison between Latin and Arabic HTR performance.
Reference graph
Works this paper leans on
-
[1]
A human-in-the-loop Label error detection framework applied to Arabic-script HTR datasets
Sana Al-azzawi, Elisa Barney, and Marcus Liwicki. A human-in-the-loop Label error detection framework applied to Arabic-script HTR datasets. arXiv preprint arXiv:2601.16713, 2026
-
[2]
Cross-Lingual Learning within Arabic Script for Low-Resource HTR
Sana Al-azzawi, Elisa Barney, and Marcus Liwicki. Cross-lingual learning within Arabic script for low-resource HTR. arXiv preprint arXiv:2605.02089 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Sana Al-azzawi, Chang Liu, Nudrat Habib, Elisa Barney, and Marcus Liwicki. Understanding cross-language transfer improvements in low-resource htr: The role of sequence modeling. arXiv preprint arXiv:2605.05900 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Dataset and ground truth for handwritten text in four different scripts
Alireza Alaei, Umapada Pal, and P Nagabhushan. Dataset and ground truth for handwritten text in four different scripts. International Journal of Pattern Recognition and Artificial Intelligence , 26(04):1253001, 2012
2012
-
[5]
A comparative study of four handwritten text recognition models in Arabic script
Feras Aljishi, Raed Mughaus, Hamzah Luqman, and Mohammad Tanvir Parvez. A comparative study of four handwritten text recognition models in Arabic script. Ingenierie des Systemes d’Information , 29(6):2243, 2024
2024
-
[6]
NorHand v3/Dataset for Handwritten Text Recognition in Norwegian (2023)
Y Beyer and PE Solberg. NorHand v3/Dataset for Handwritten Text Recognition in Norwegian (2023)
2023
-
[7]
HATFormer: historic handwritten Arabic text recognition with trans- formers
Adrian Chan, Anupam Mijar, Mehreen Saeed, Chau-Wai Wong, and Akram Khater. HATFormer: historic handwritten Arabic text recognition with trans- formers. arXiv preprint arXiv:2410.02179 , 2024
-
[8]
Meta-dan: Towards an efficient prediction strategy for page-level handwritten text recognition
Denis Coquenet. Meta-dan: Towards an efficient prediction strategy for page-level handwritten text recognition. Pattern Recognition, 177:113373, 2026
2026
-
[9]
Applying center loss to neural networks for sequence prediction: A study for handwriting recognition
Simon Corbillé and Elisa H Barney Smith. Applying center loss to neural networks for sequence prediction: A study for handwriting recognition. In International Joint Conference on Neural Networks (IJCNN) . IEEE, 2025
2025
-
[10]
Handwrit- ten text recognition: a survey
Carlos Garrido-Munoz, Antonio Rios-Vila, and Jorge Calvo-Zaragoza. Handwrit- ten text recognition: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[11]
PHTI: Pashto handwritten text imagebase for deep learning applications
Ibrar Hussain, Riaz Ahmad, Siraj Muhammad, Khalil Ullah, Habib Shah, and Abdallah Namoun. PHTI: Pashto handwritten text imagebase for deep learning applications. IEEE Access, 10:113149–113157, 2022. Performance Gap Analysis between Latin and Arabic Scripts HTR 15
2022
-
[12]
Domain adaptation based pipeline for character classification and handwritten text recog- nition
Florent Imbert, Simon Corbillé, Hui Han, and Elisa H Barney Smith. Domain adaptation based pipeline for character classification and handwritten text recog- nition. International Journal on Document Analysis and Recognition , 2026
2026
-
[13]
TrOCR: Transformer-based optical character recognition with pre-trained models
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. TrOCR: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI conference on artificial intelligence , volume 37, pages 13094–13102, 2023
2023
-
[14]
HTR-VT: Handwritten text recognition with vision transformer
Yuting Li, Dexiong Chen, Tinglong Tang, and Xi Shen. HTR-VT: Handwritten text recognition with vision transformer. Pattern Recognition, 158:110967, 2025
2025
-
[15]
KHATT: An open Arabic offline handwritten text database
Sabri A Mahmoud, Irfan Ahmad, Wasfi G Al-Khatib, Mohammad Alshayeb, Mo- hammad Tanvir Parvez, Volker Märgner, and Gernot A Fink. KHATT: An open Arabic offline handwritten text database. Pattern Recognition, 47(3):1096–1112, 2014
2014
-
[16]
A unified architecture for Urdu printed and handwritten text recognition
Arooba Maqsood, Nauman Riaz, Adnan Ul-Hasan, and Faisal Shafait. A unified architecture for Urdu printed and handwritten text recognition. In International Conference on Document Analysis and Recognition, pages 116–130. Springer, 2023
2023
-
[17]
The IAM-database: an English sentence database for offline handwriting recognition
U-V Marti and Horst Bunke. The IAM-database: an English sentence database for offline handwriting recognition. International Journal on Document Analysis and Recognition, 5(1):39–46, 2002
2002
-
[18]
Multi-cnn voting method for improved arabic handwritten digits classification
Areeg Fahad Rasheed, M Zarkoosh, and Sana Sabah Al-Azzawi. Multi-cnn voting method for improved arabic handwritten digits classification. In 2023 9th Interna- tional Conference on Computer and Communication Engineering (ICCCE) , pages 205–210. IEEE, 2023
2023
-
[19]
Best practices for a handwritten text recognition system
George Retsinas, Giorgos Sfikas, Basilis Gatos, and Christophoros Nikou. Best practices for a handwritten text recognition system. In International Workshop on Document Analysis Systems , pages 247–259. Springer, 2022
2022
-
[20]
Conv-transformer architecture for unconstrained off- line Urdu handwriting recognition
Nauman Riaz, Haziq Arbab, Arooba Maqsood, Khuzaeymah Nasir, Adnan Ul- Hasan, and Faisal Shafait. Conv-transformer architecture for unconstrained off- line Urdu handwriting recognition. International Journal on Document Analysis and Recognition (IJDAR), 25(4), 2022
2022
-
[21]
Muharaf: Manuscripts of handwritten Ara- bic dataset for cursive text recognition
Mehreen Saeed, Adrian Chan, Anupam Mijar, Gerges Habchi, Carlos Younes, Chau-Wai Wong, and Akram Khater. Muharaf: Manuscripts of handwritten Ara- bic dataset for cursive text recognition. Advances in Neural Information Processing Systems, 37:58525–58538, 2024
2024
-
[22]
Advance- ments and challenges in Arabic optical character recognition: A comprehensive survey
Mahmoud Salaheldin Kasem, Mohamed Mahmoud, and Hyun-Soo Kang. Advance- ments and challenges in Arabic optical character recognition: A comprehensive survey. ACM Computing Surveys , 58(4):1–37, 2025
2025
-
[23]
ICFHR2016 Competition on handwritten text recognition on the READ dataset
Joan Andreu Sánchez, Verónica Romero, Alejandro H Toselli, and Enrique Vi- dal. ICFHR2016 Competition on handwritten text recognition on the READ dataset. In 2016 15th International conference on frontiers in handwriting recog- nition (ICFHR) , pages 630–635. IEEE, 2016
2016
-
[24]
A convolutional recursive deep architecture for unconstrained Urdu handwriting recognition
Noor ul Sehr Zia, Muhammad Ferjad Naeem, Syed Muhammad Kumail Raza, Muhammad Mubasher Khan, Adnan Ul-Hasan, and Faisal Shafait. A convolutional recursive deep architecture for unconstrained Urdu handwriting recognition. Neural Computing and Applications , 34(2):1635–1648, 2022
2022
-
[25]
Persian language, April 2026
Wikipedia contributors. Persian language, April 2026. Accessed: 2026-04-29
2026
-
[26]
A Handwritten text recognition dataset for Ajami manuscripts in Fulfulde and Hausa
Oreen Yousuf, Abdulmalik Aminu, Musa Salih Muhammad, Bashir Usman, Mustapha Kurfi Hashim, Joakim Nivre, Beáta Megyesi, and Christian Høgel. A Handwritten text recognition dataset for Ajami manuscripts in Fulfulde and Hausa. In International Conference on Document Analysis and Recognition , pages 620–
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.