OnPoint: Offline-to-Online Multi-Level Distillation for Point-Supervised Online Temporal Action Localization
Pith reviewed 2026-07-02 15:42 UTC · model grok-4.3
The pith
Multi-level distillation from an offline teacher enables point-supervised online temporal action localization in streaming videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
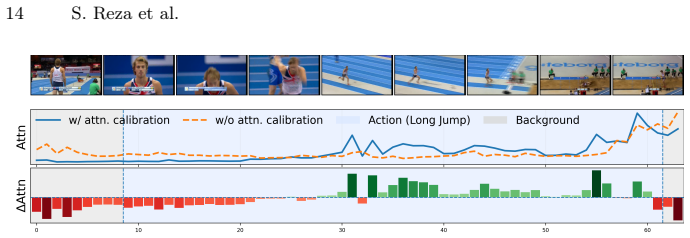
OnPoint is an offline-to-online multi-level distillation framework that transfers knowledge from a point-supervised offline teacher to an online student via pseudo-segment instance distillation, class-activation sequence distillation, and anticipatory window-level distillation. The framework incorporates original point labels into student training and refines anchor decoding with actionness-guided attention calibration. Experiments on five datasets demonstrate that this method consistently outperforms strong baselines for point-supervised online temporal action localization.
What carries the argument
The multi-level distillation process consisting of pseudo-segment instance distillation, class-activation sequence distillation, and anticipatory window-level distillation that bridges the offline teacher and online student.
If this is right
- The online student model can localize actions without needing the full video at once.
- Performance on point-supervised online TAL improves compared to existing baselines.
- Robustness is enhanced by using the original point labels during training.
- Anchor decoding benefits from actionness-guided attention calibration.
Where Pith is reading between the lines
- This method might allow point supervision to be applied to other online video tasks beyond action localization.
- Future work could explore reducing the reliance on the offline teacher by making the distillation more efficient.
- Deployment in live surveillance systems could become feasible with minimal labeling effort.
Load-bearing premise
The offline teacher, trained solely on point labels, generates sufficiently accurate pseudo-segments and activation sequences to effectively train the online student.
What would settle it
Training the online student with the distillation and observing no improvement over direct training on point labels alone, or poor performance on streaming test videos despite good offline teacher results.
Figures




read the original abstract
Temporal Action Localization (TAL) typically relies on segment annotations or offline access to full videos, limiting scalability and online use. We introduce Point-Supervised Online TAL (POTAL), which localizes actions in streaming videos using only one temporal point per instance. To solve POTAL, we propose OnPoint, an offline-to-online multi-level distillation framework that transfers knowledge from a point-supervised offline teacher to an online student via (i) pseudo-segment instance distillation, (ii) class-activation sequence distillation, and (iii) anticipatory window-level distillation. We further improve robustness by incorporating the original point labels into student training and by refining anchor decoding with actionness-guided attention calibration. Experiments on five datasets show OnPoint consistently outperforms strong baselines, establishing a solid foundation for POTAL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Point-Supervised Online Temporal Action Localization (POTAL), a setting for localizing actions in streaming videos using only one temporal point per instance. It proposes OnPoint, an offline-to-online multi-level distillation framework that transfers knowledge from a point-supervised offline teacher to an online student via pseudo-segment instance distillation, class-activation sequence distillation, and anticipatory window-level distillation. The approach retains original point labels during student training and uses actionness-guided attention calibration for anchor decoding, claiming consistent outperformance over strong baselines on five datasets.
Significance. If the empirical claims hold, the work is significant for establishing the POTAL task and providing a concrete three-component distillation pipeline that bridges offline point-supervised models with online inference constraints. This could enable more scalable real-time video analysis with minimal annotation, addressing limitations of both full segment supervision and offline full-video access.
major comments (1)
- [Abstract] Abstract: the central claim that 'Experiments on five datasets show OnPoint consistently outperforms strong baselines' is unsupported because the manuscript supplies no quantitative results, tables, figures, experimental protocol, dataset details, baseline descriptions, or metrics. This absence prevents verification of the outperformance claim, which is load-bearing for the paper's contribution.
Simulated Author's Rebuttal
We thank the referee for identifying this critical issue with the abstract's unsupported claim. We agree that the experimental outperformance must be substantiated with concrete results, protocols, and metrics in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments on five datasets show OnPoint consistently outperforms strong baselines' is unsupported because the manuscript supplies no quantitative results, tables, figures, experimental protocol, dataset details, baseline descriptions, or metrics. This absence prevents verification of the outperformance claim, which is load-bearing for the paper's contribution.
Authors: We fully acknowledge the validity of this comment. The manuscript text available for review consists only of the abstract and does not include any experimental sections, tables, figures, dataset details, baselines, metrics, or protocols. This omission means the central claim cannot be verified from the provided content. We will revise the manuscript by adding a complete experimental section that reports results on the five datasets, including all quantitative tables, figures, evaluation protocols, dataset descriptions, baseline implementations, and metrics to directly support the abstract claim. revision: yes
Circularity Check
No significant circularity; derivation is a forward engineering proposal
full rationale
The paper introduces a concrete three-component distillation pipeline (pseudo-segment instance distillation, class-activation sequence distillation, anticipatory window-level distillation) plus point-label retention and actionness-guided decoding for point-supervised online TAL. No equations, fitted parameters, or self-citation chains are present in the abstract or stated construction that reduce the claimed outputs to the inputs by definition. The method is presented as an empirical engineering contribution evaluated on five datasets; the central claims do not rely on uniqueness theorems, ansatzes smuggled via prior self-work, or renaming of known results. The reader's assessment of score 0.0 is confirmed: the argument remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An offline model trained with single-point labels can generate pseudo-segments and activation sequences sufficiently accurate to train a functional online student.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the ieee conference on computer vision and pattern recognition
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the ieee conference on computer vision and pattern recognition. pp. 961–970 (2015)
2015
-
[2]
Celdrán,F.J.,Jiménez-Ruescas,J.,Lobato,C.,Salazar,L.,Sánchez-Margallo,J.A., Sánchez-Margallo, F.M., González, P.: Use of augmented reality for training assis- tanceinlaparoscopicsurgery:scopingliteraturereview.JournalofMedicalInternet Research27, e58108 (2025)
2025
-
[3]
Chen, L., Yang, T., Zhang, X., Zhang, W., Sun, J.: Points as queries: Weakly semi- supervisedobjectdetectionbypoints.In:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition. pp. 8823–8832 (2021)
2021
-
[4]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
International Journal of Computer Vision130(1), 33–55 (2022)
Damen, D., Doughty, H., Farinella, G.M., Furnari, A., Kazakos, E., Ma, J., Molti- santi, D., Munro, J., Perrett, T., Price, W., et al.: Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100. International Journal of Computer Vision130(1), 33–55 (2022)
2022
-
[6]
In: Proceedings of the Thirty-Second Interna- tional Joint Conference on Artificial Intelligence
Du, D., Li, E., Si, L., Xu, F., Sun, F.: Timestamp-supervised action segmentation from the perspective of clustering. In: Proceedings of the Thirty-Second Interna- tional Joint Conference on Artificial Intelligence. pp. 690–698 (2023)
2023
-
[7]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Guermal, M., Ali, A., Dai, R., Brémond, F.: Joadaa: joint online action detection and action anticipation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6889–6898 (2024)
2024
-
[8]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Gupta, A., Mittal, G., Magooda, A., Yu, Y., Taylor, G.W., Chen, M.: Losa: long- short-range adapter for scaling end-to-end temporal action localization. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2092–2102. IEEE (2025)
2025
-
[9]
in the wild
Idrees, H., Zamir, A.R., Jiang, Y.G., Gorban, A., Laptev, I., Sukthankar, R., Shah, M.: The thumos challenge on action recognition for videos “in the wild”. Computer Vision and Image Understanding155, 1–23 (2017)
2017
-
[10]
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Jiang, C., Dehghan, M., Jagersand, M.: Understanding contexts inside robot and human manipulation tasks through vision-language model and ontology system in video streams. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 8366–8372. IEEE (2020)
2020
-
[11]
In: European Conference on Computer Vision
Kang, H., Hyun, J., An, J., Yu, Y., Kim, S.J.: Actionswitch: Class-agnostic de- tection of simultaneous actions in streaming videos. In: European Conference on Computer Vision. pp. 383–400. Springer (2024)
2024
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kang, H., Kim, K., Ko, Y., Kim, S.J.: Cag-qil: Context-aware actionness grouping via q imitation learning for online temporal action localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13729–13738 (2021)
2021
-
[13]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Kim, H., Lee, S., Kang, H., Im, S.: Offline-to-online knowledge distillation for video instance segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 159–168 (2024)
2024
-
[14]
In: European Conference on Computer Vision
Kim, Y.H., Kang, H., Kim, S.J.: A sliding window scheme for online temporal action localization. In: European Conference on Computer Vision. pp. 653–669. Springer (2022) Point-Supervised Online Temporal Action Localization 17
2022
-
[15]
Pattern Recognition131, 108871 (2022)
Kim, Y.H., Nam, S., Kim, S.J.: 2pesnet: Towards online processing of temporal action localization. Pattern Recognition131, 108871 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Lee, P., Byun, H.: Learning action completeness from points for weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 13648–13657 (2021)
2021
-
[17]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Li, J., Liu, X., Zhu, B., Jiao, J., Tomizuka, M., Tang, C., Zhan, W.: Guided online distillation: Promoting safe reinforcement learning by offline demonstration. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 7447–7454. IEEE (2024)
2024
-
[18]
In: Proceedings of the European conference on computer vision (ECCV)
Li,Y.,Liu,M.,Rehg,J.M.:Intheeyeofbeholder:Jointlearningofgazeandactions in first person video. In: Proceedings of the European conference on computer vision (ECCV). pp. 619–635 (2018)
2018
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C., Xu, C., Luo, D., Wang, Y., Tai, Y., Wang, C., Li, J., Huang, F., Fu, Y.: Learning salient boundary feature for anchor-free temporal action localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 3320–3329 (2021)
2021
-
[20]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: Bmn: Boundary-matching network for temporal action proposal generation. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 3889–3898 (2019)
2019
-
[21]
In: Proceedings of the European conference on computer vision (ECCV)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: Bsn: Boundary sensitive network for temporal action proposal generation. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
2018
-
[22]
In: International Conference on Case-Based Reasoning
Liu, H., Liu, Q., Wu, L., Shi, M., Cui, Z.: Offline-to-online: Case-based knowledge distillation with large language models for reinforcement learning. In: International Conference on Case-Based Reasoning. pp. 142–156. Springer (2025)
2025
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Liu, M., Wang, L., Zhou, S., Xia, K., Sun, X., Hua, G.: Boosting point-supervised temporal action localization through integrating query reformation and optimal transport. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 13865–13875 (2025)
2025
-
[24]
In: European Conference on Computer Vision
Liu, M., Wang, L., Zhou, S., Xia, K., Wu, Q., Zhang, Q., Hua, G.: Stepwise multi- grained boundary detector for point-supervised temporal action localization. In: European Conference on Computer Vision. pp. 333–349. Springer (2024)
2024
-
[25]
IEEE transactions on image processing 31, 6937–6950 (2022)
Liu, Y., Wang, L., Wang, Y., Ma, X., Qiao, Y.: Fineaction: A fine-grained video dataset for temporal action localization. IEEE transactions on image processing 31, 6937–6950 (2022)
2022
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Y., Liu, Y., Jiang, C., Lyu, K., Wan, W., Shen, H., Liang, B., Fu, Z., Wang, H., Yi, L.: Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21013–21022 (2022)
2022
-
[27]
In: European conference on computer vision
Ma, F., Zhu, L., Yang, Y., Zha, S., Kundu, G., Feiszli, M., Shou, Z.: Sf-net: Single- frame supervision for temporal action localization. In: European conference on computer vision. pp. 420–437. Springer (2020)
2020
-
[28]
Advances in Neural Information Processing Systems37, 81808–81835 (2024)
Nie, M., Ding, D., Wang, C., Guo, Y., Han, J., Xu, H., Zhang, L.: Slowfocus: Enhancing fine-grained temporal understanding in video llm. Advances in Neural Information Processing Systems37, 81808–81835 (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Patel, D., Babazaki, Y., Nagase, Y., Melvin, I., Min, M.R.: Distilling offline ac- tion detection models into real-time streaming models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6205– 6214 (2026) 18 S. Reza et al
2026
-
[30]
IEEE Robotics and Automation Letters (2024)
Patsch, C., Wu, Y., Salihu, D., Zakour, M., Steinbach, E.: Tscl: Timestamp super- vised contrastive learning for action segmentation. IEEE Robotics and Automation Letters (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Qing, Z., Su, H., Gan, W., Wang, D., Wu, W., Wang, X., Qiao, Y., Yan, J., Gao, C., Sang, N.: Temporal context aggregation network for temporal action proposal refinement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 485–494 (2021)
2021
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Reza, S., Song, X., Yu, H., Lin, Z., Moghaddam, M., Camps, O.: Reef: Relevance- aware and efficient llm adapter for video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 2617–2628 (June 2025)
2025
-
[33]
arXiv preprint arXiv:2305.11365 (2023)
Reza, S., Sundareshan, B., Moghaddam, M., Camps, O.: Enhancing trans- former backbone for egocentric video action segmentation. arXiv preprint arXiv:2305.11365 (2023)
-
[34]
In: European Conference on Computer Vision
Reza, S., Zhang, Y., Moghaddam, M., Camps, O.: Hat: History-augmented anchor transformer for online temporal action localization. In: European Conference on Computer Vision. pp. 205–222. Springer (2024)
2024
-
[35]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Shao, J., Wang, X., Quan, R., Zheng, J., Yang, J., Yang, Y.: Action sensitivity learning for temporal action localization. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 13457–13469 (2023)
2023
-
[36]
In: European conference on computer vision
Shi, D., Zhong, Y., Cao, Q., Zhang, J., Ma, L., Li, J., Tao, D.: React: Tempo- ral action detection with relational queries. In: European conference on computer vision. pp. 105–121. Springer (2022)
2022
-
[37]
IEEE Transactions on circuits and systems for video technology28(5), 1212–1231 (2017)
Shih, H.C.: A survey of content-aware video analysis for sports. IEEE Transactions on circuits and systems for video technology28(5), 1212–1231 (2017)
2017
-
[38]
In: European Conference on Computer Vision
Song, Y., Kim, D., Cho, M., Kwak, S.: Online temporal action localization with memory-augmented transformer. In: European Conference on Computer Vision. pp. 74–91. Springer (2024)
2024
-
[39]
arXiv preprint arXiv:2211.04905 (2022)
Tang, T.N., Park, J., Kim, K., Sohn, K.: Simon: a simple framework for online temporal action localization. arXiv preprint arXiv:2211.04905 (2022)
-
[40]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[41]
The Visual Computer29(10), 983–1009 (2013)
Vishwakarma, S., Agrawal, A.: A survey on activity recognition and behavior un- derstanding in video surveillance. The Visual Computer29(10), 983–1009 (2013)
2013
-
[42]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(4), 2171–2190 (2023)
Wang, B., Zhao, Y., Yang, L., Long, T., Li, X.: Temporal action localization in the deep learning era: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence46(4), 2171–2190 (2023)
2023
-
[43]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Wang, J., Chen, G., Huang, Y., Wang, L., Lu, T.: Memory-and-anticipation trans- former for online action understanding. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 13824–13835 (2023)
2023
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Q., Zhang, Y., Zheng, Y., Pan, P.: Rcl: Recurrent continuous localization for temporal action detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13566–13575 (2022)
2022
-
[45]
IEEE Access8, 70477– 70487 (2020)
Xia, H., Zhan, Y.: A survey on temporal action localization. IEEE Access8, 70477– 70487 (2020)
2020
-
[46]
IEEE Transactions on Multimedia25, 9425–9436 (2023)
Xia, K., Wang, L., Shen, Y., Zhou, S., Hua, G., Tang, W.: Exploring action centers for temporal action localization. IEEE Transactions on Multimedia25, 9425–9436 (2023)
2023
-
[47]
Pattern Recognition129, 108725 (2022) Point-Supervised Online Temporal Action Localization 19
Xia, K., Wang, L., Zhou, S., Hua, G., Tang, W.: Dual relation network for temporal action localization. Pattern Recognition129, 108725 (2022) Point-Supervised Online Temporal Action Localization 19
2022
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xia, K., Wang, L., Zhou, S., Zheng, N., Tang, W.: Learning to refactor action and co-occurrence features for temporal action localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13884– 13893 (2022)
2022
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xia, Z., Cheng, J., Liu, S., Hu, Y., Wang, S., Zhang, Y., Dang, L.: Realigning confidence with temporal saliency information for point-level weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18440–18450 (2024)
2024
-
[50]
In: Proceedings of the IEEE international conference on computer vision
Xu, H., Das, A., Saenko, K.: R-c3d: Region convolutional 3d network for tem- poral activity detection. In: Proceedings of the IEEE international conference on computer vision. pp. 5783–5792 (2017)
2017
-
[51]
IEEE Access12, 191808–191827 (2024)
Yoo, S., Reza, S., Tarashiyoun, H., Ajikumar, A., Moghaddam, M.: Ai-integrated ar as an intelligent companion for industrial workers: a systematic review. IEEE Access12, 191808–191827 (2024)
2024
-
[52]
In: European Conference on Computer Vision
Zhang, C.L., Wu, J., Li, Y.: Actionformer: Localizing moments of actions with transformers. In: European Conference on Computer Vision. pp. 492–510. Springer (2022)
2022
-
[53]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Zhang, H., Wang, X., Xu, X., Qing, Z., Gao, C., Sang, N.: Hr-pro: Point-supervised temporal action localization via hierarchical reliability propagation. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. vol. 38(7), pp. 7115–7123 (2024)
2024
-
[54]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Q., Fang, J., Yuan, R., Tang, X., Qi, Y., Zhang, K., Yuan, C.: Weakly supervised temporal action localization via dual-prior collaborative learning guided by multimodal large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24139–24148 (2025) Supplementary Materials This supplement provides additional ...
2025
-
[55]
label": class_label,
in our evaluation. As noted in [14], ActivityNet v1.3 is not well-suited for the Online TAL setting because its videos typically contain only a single action instance that spans most of the video duration. This contradicts the primary objective of On-TAL, which is to detect multiple, potentially overlapping action instances in a streaming environment. Hyp...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.