Few-Shot Resampling for Scalable Statistically-Sound Data Mining
Pith reviewed 2026-06-28 23:51 UTC · model grok-4.3
The pith
FewRS validates data mining results statistically using only a few resampled datasets via a new bound on test statistic deviation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FewRS is a resampling-based approach that requires generating and analyzing only an extremely small number of resampled datasets to assess the statistical significance of data mining results, providing rigorous guarantees on the probability of false discoveries through a novel bound to the supremum deviation of the test statistics.
What carries the argument
The novel bound to the supremum deviation of test statistics representing the quality of data mining results, which enables rigorous false-discovery control with few resamples.
If this is right
- The method applies to every situation where resampling-based significance testing is used.
- Running time drops by up to two orders of magnitude relative to prior resampling approaches.
- High statistical power is retained on standard tasks such as pattern mining and network analysis.
- Statistical validation becomes practical for large-scale real-world datasets.
Where Pith is reading between the lines
- The same bound might support significance testing in domains outside data mining that already rely on resampling.
- Integration into existing mining software could add statistical validation with low extra cost.
- If the bound generalizes, it could reduce the number of resamples even further for specific test statistics.
Load-bearing premise
The novel bound on the supremum deviation of the test statistics is both valid and sufficiently tight to deliver the claimed rigorous guarantees on the probability of false discoveries when only a few resamples are used.
What would settle it
A dataset and mining task where FewRS with the stated small number of resamples produces a rate of false discoveries higher than the bound guarantees.
Figures
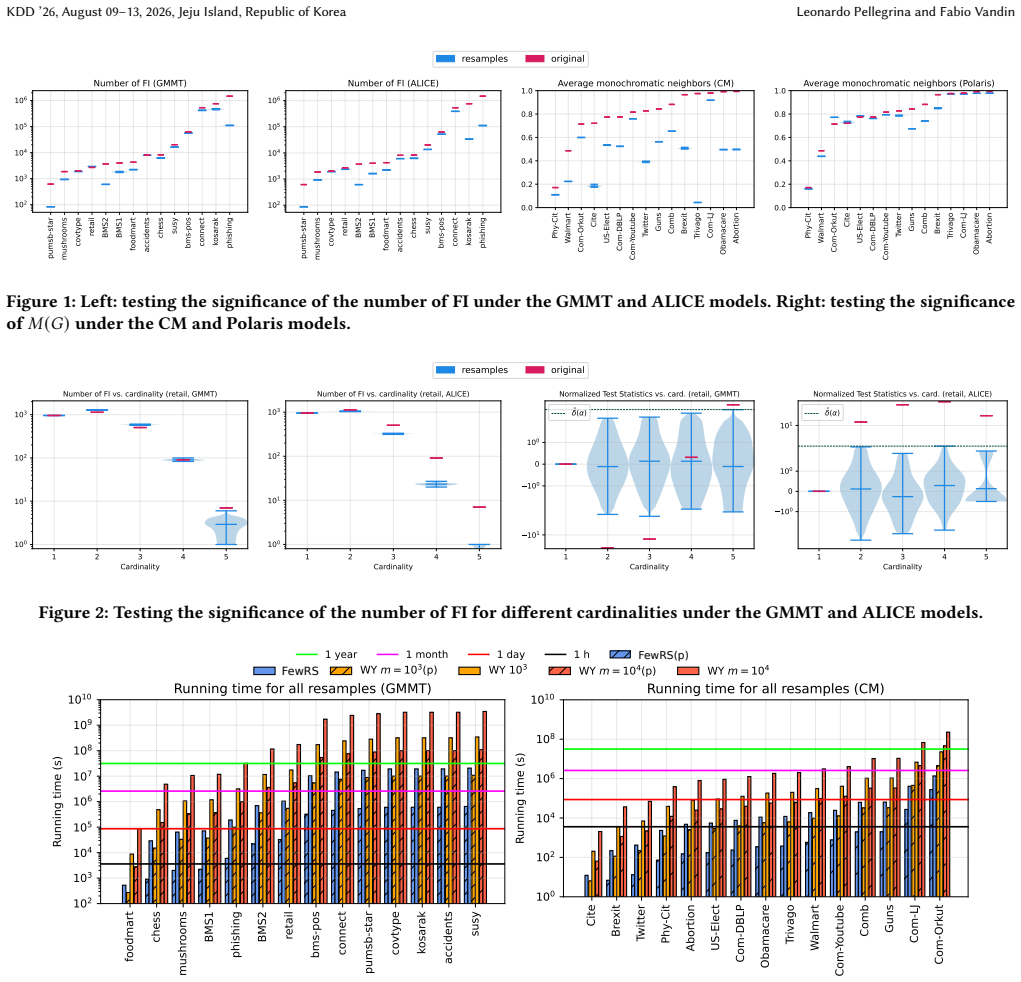
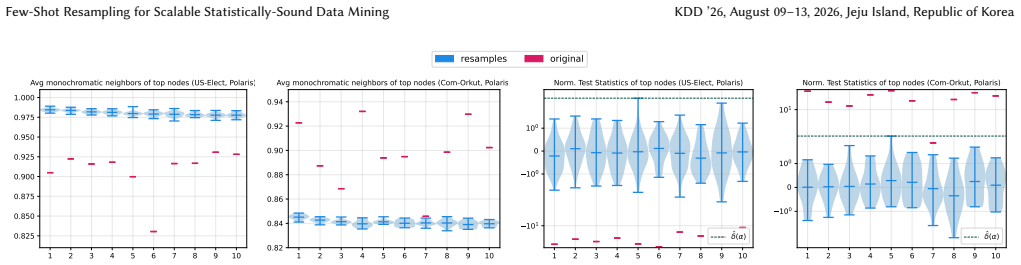
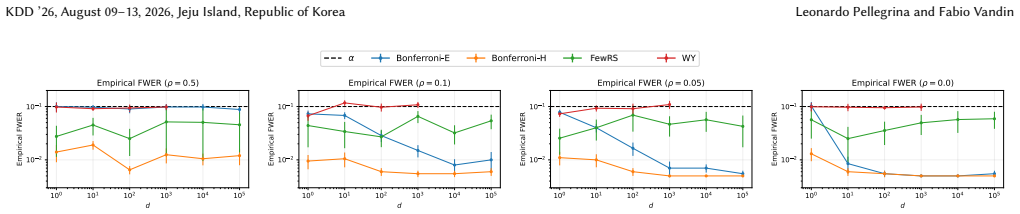
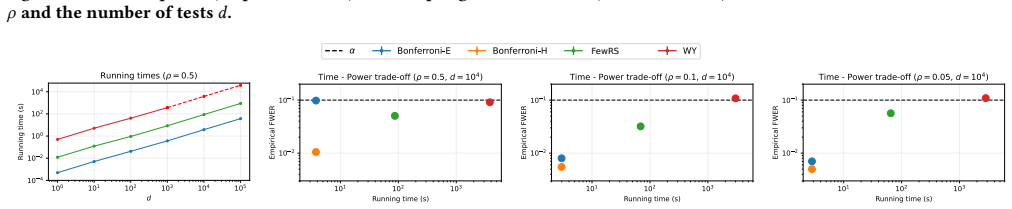
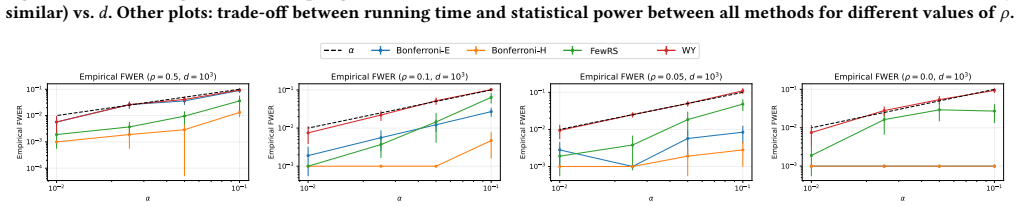
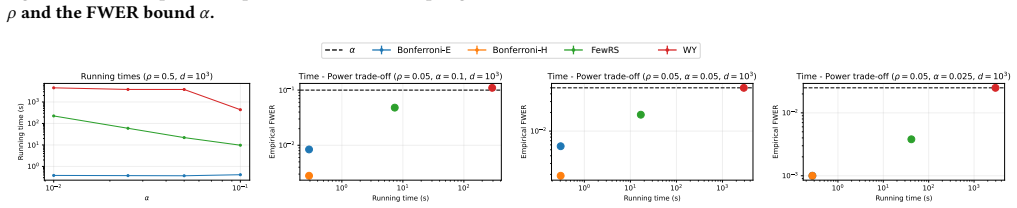
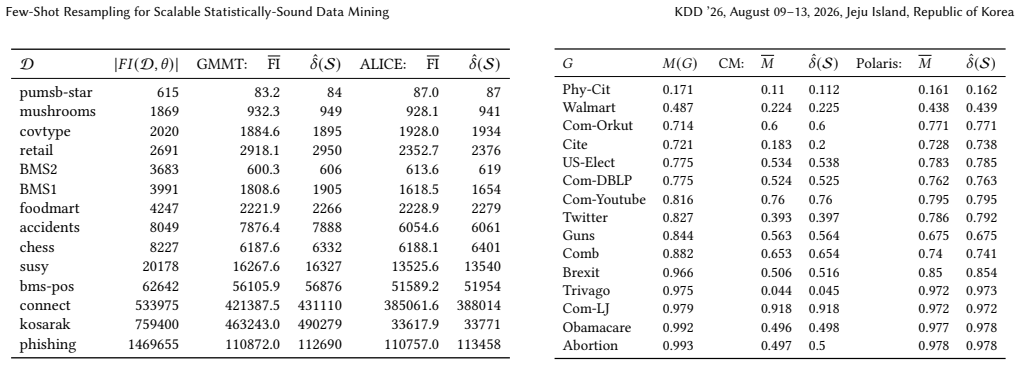
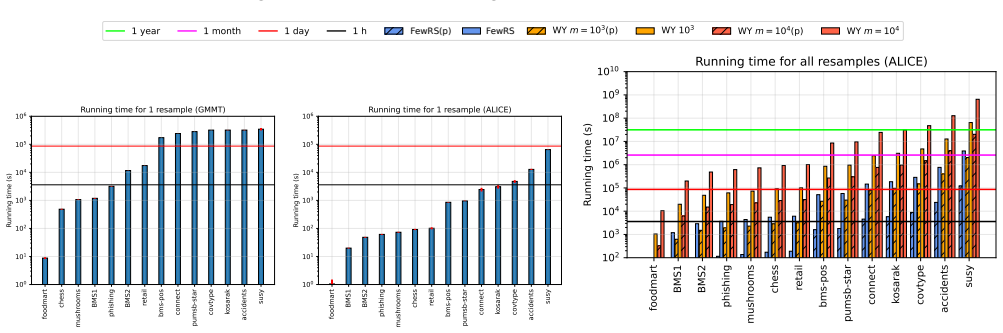
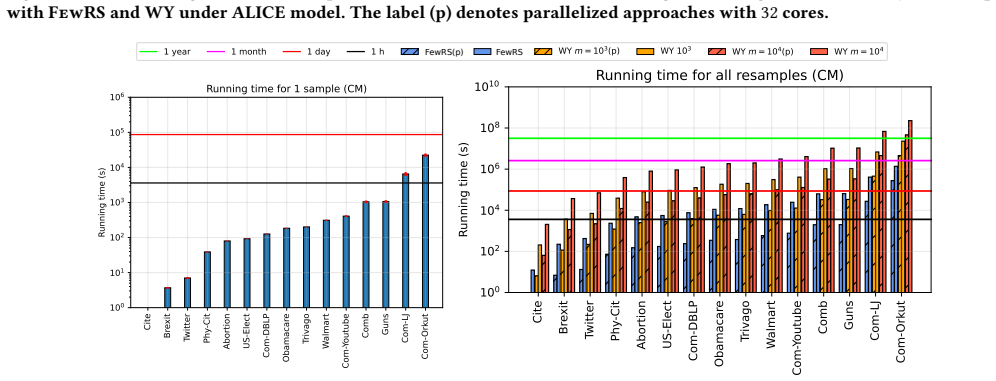
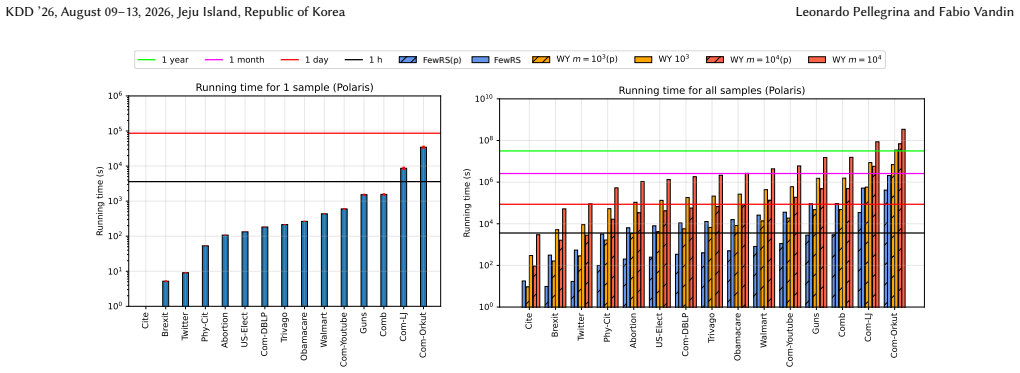
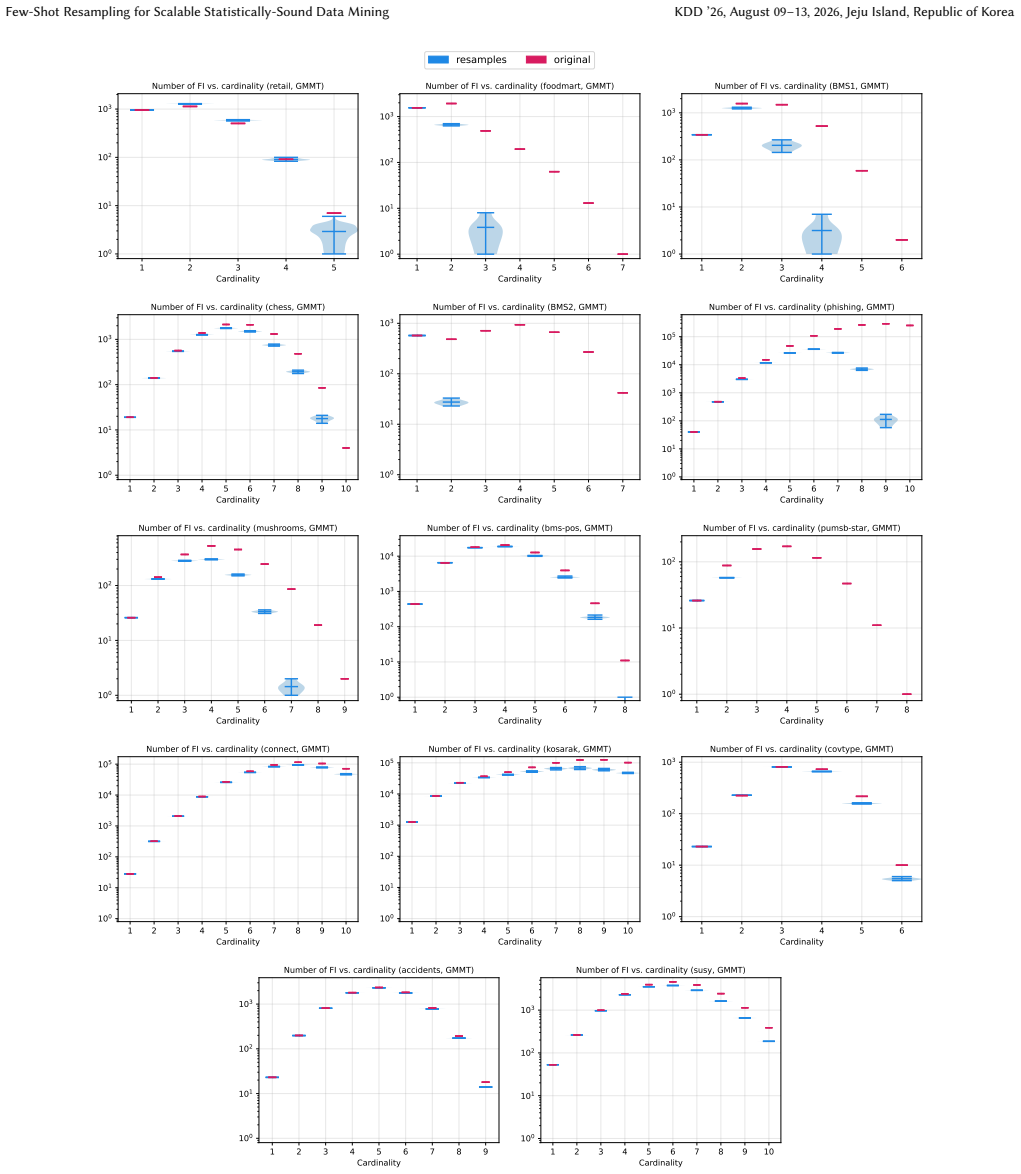
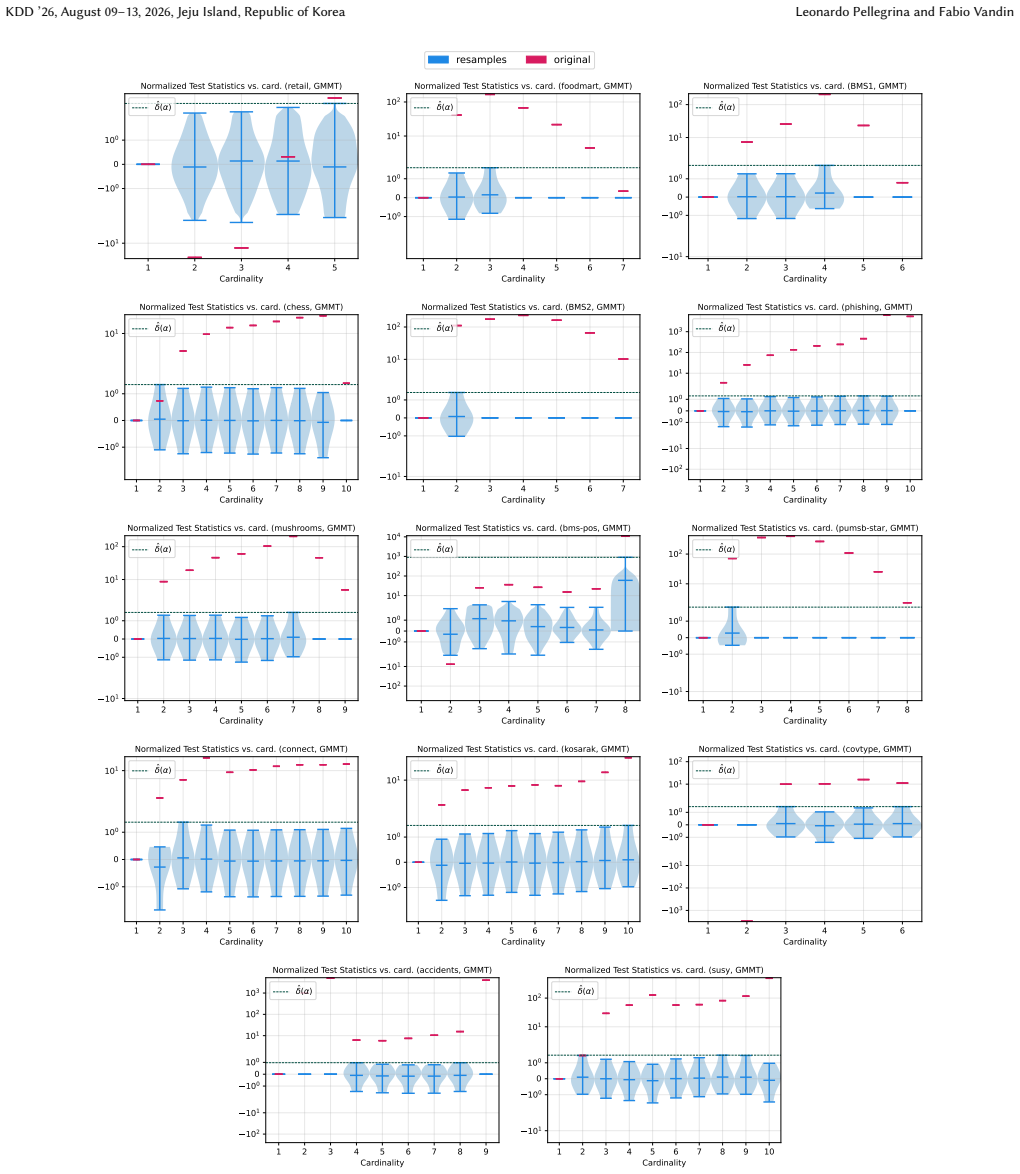
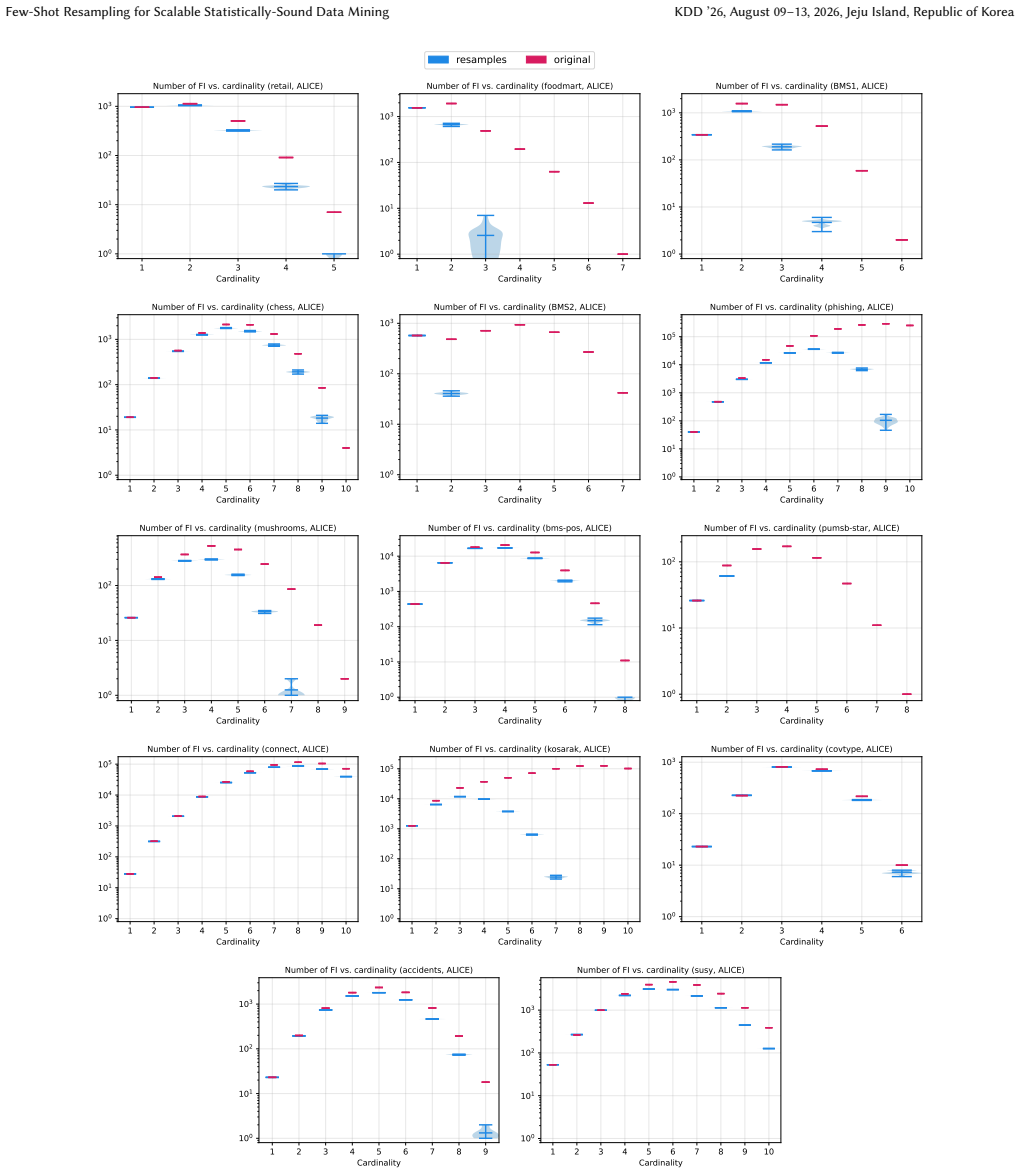
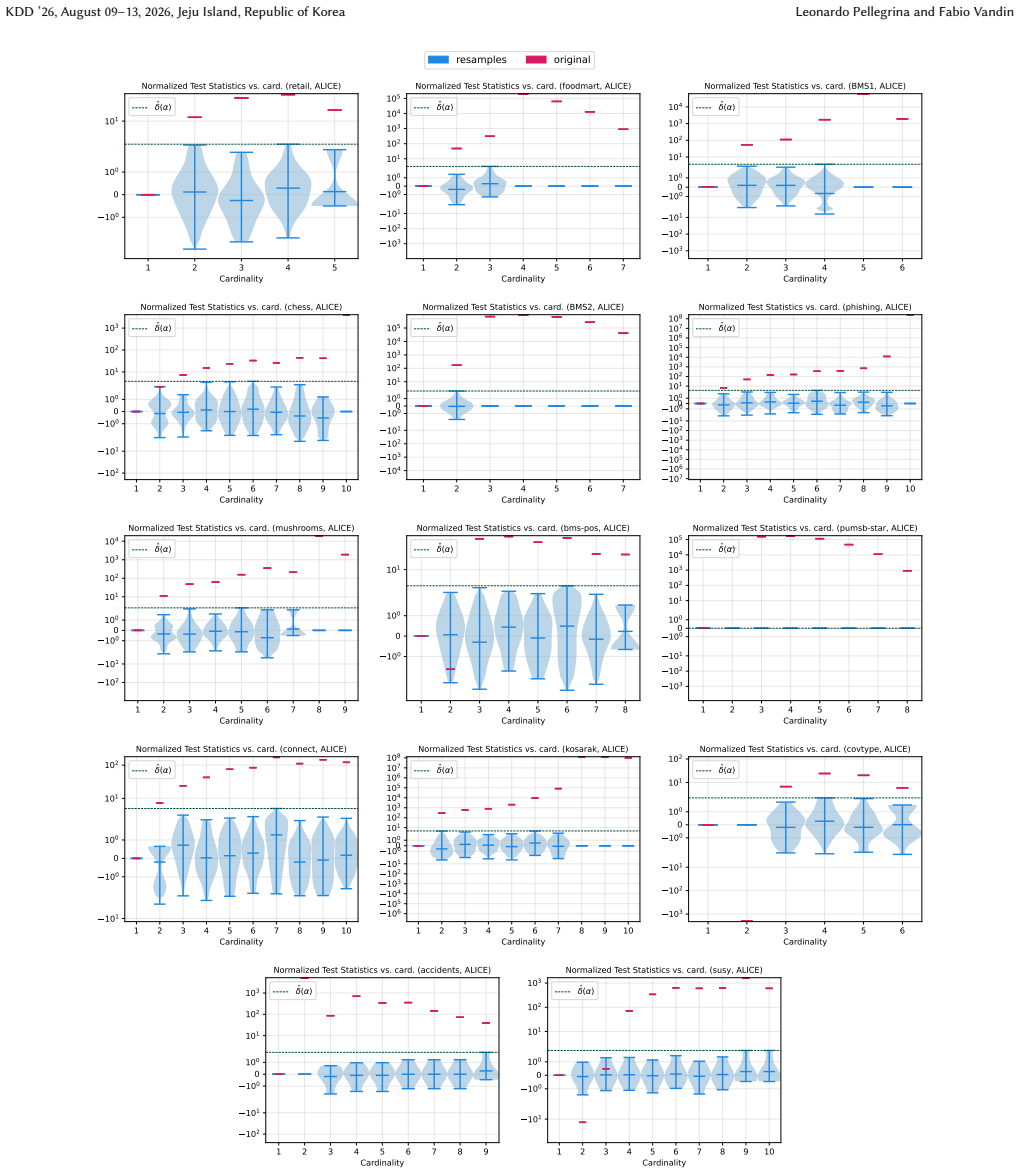
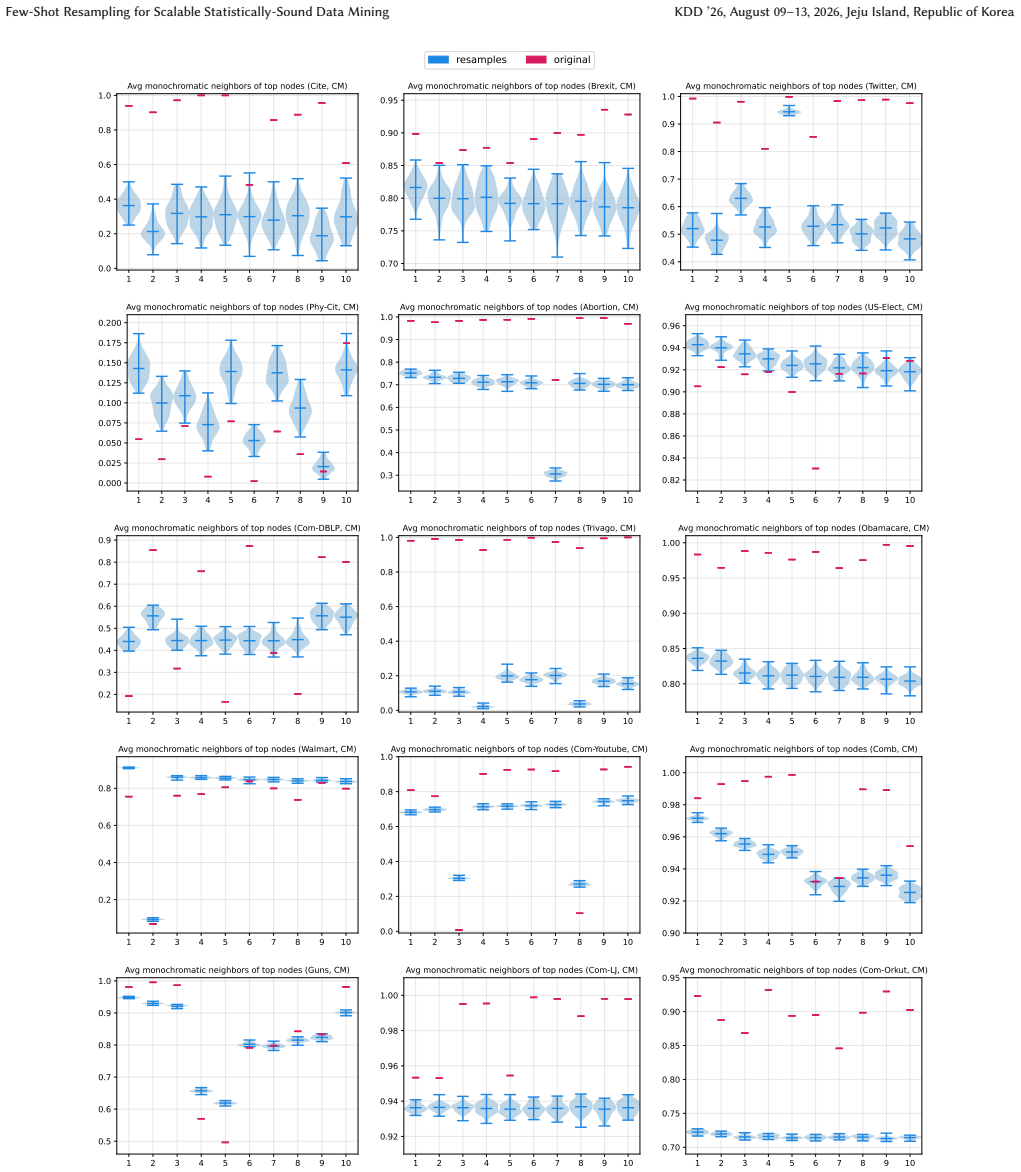
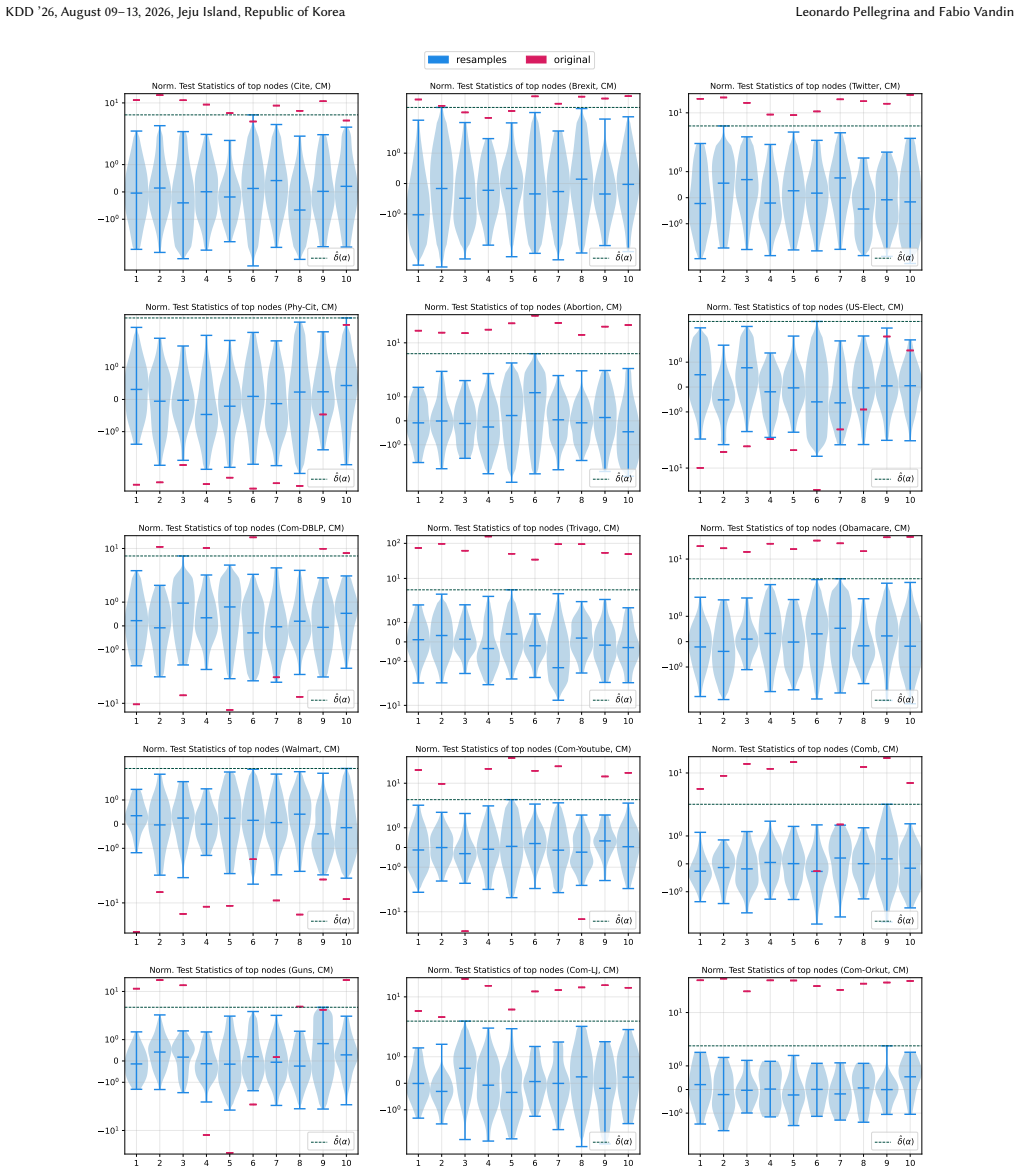
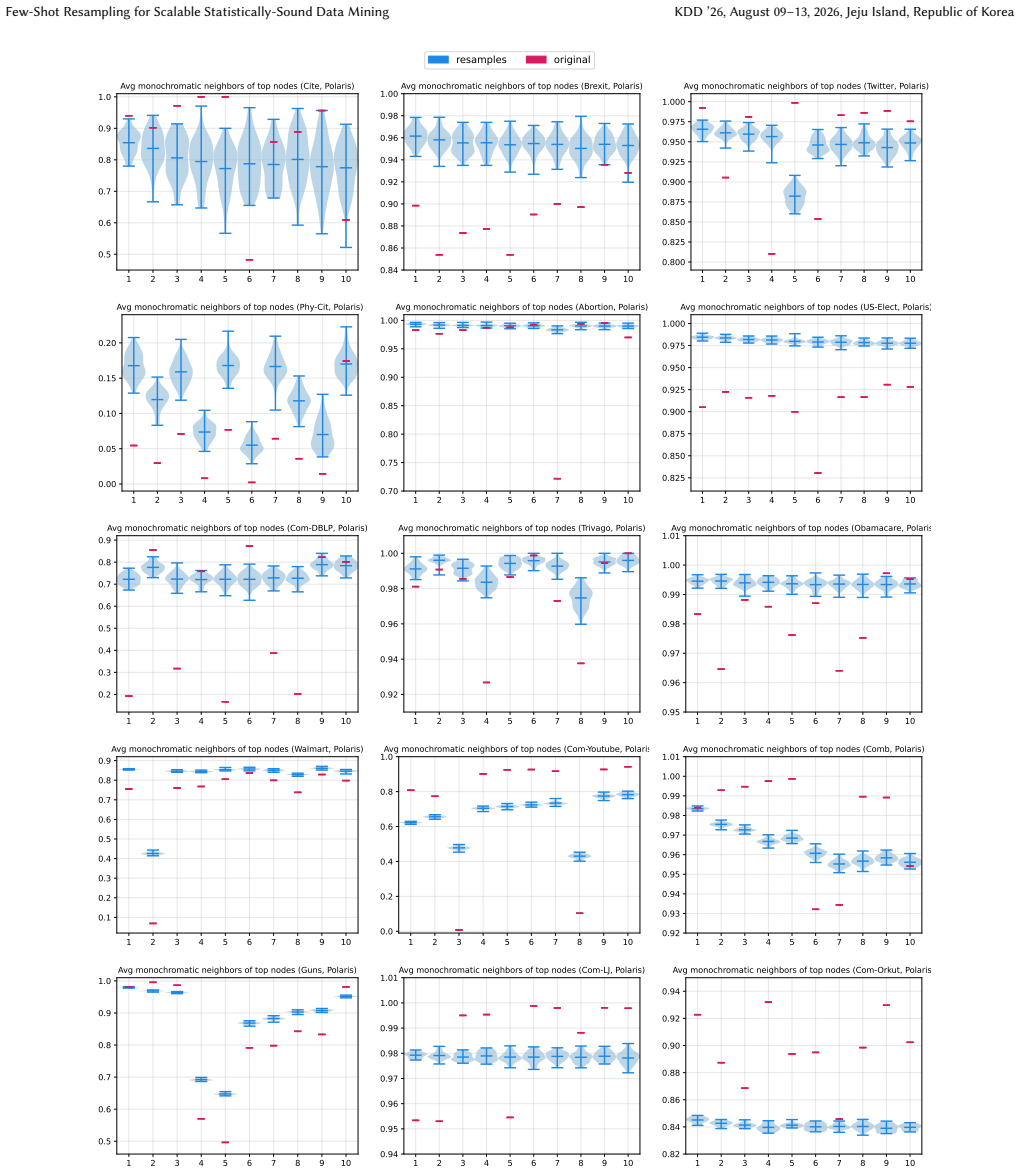
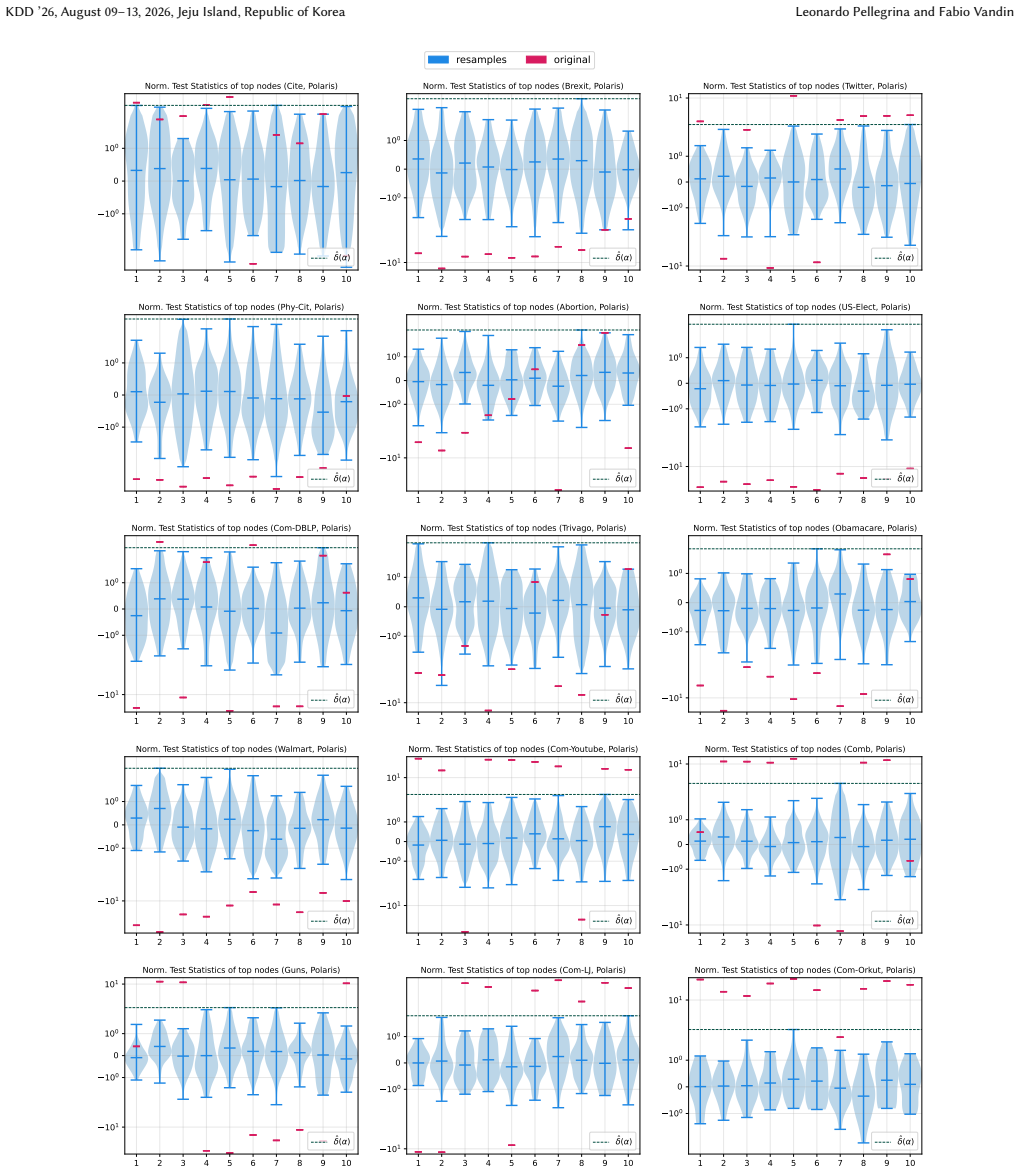
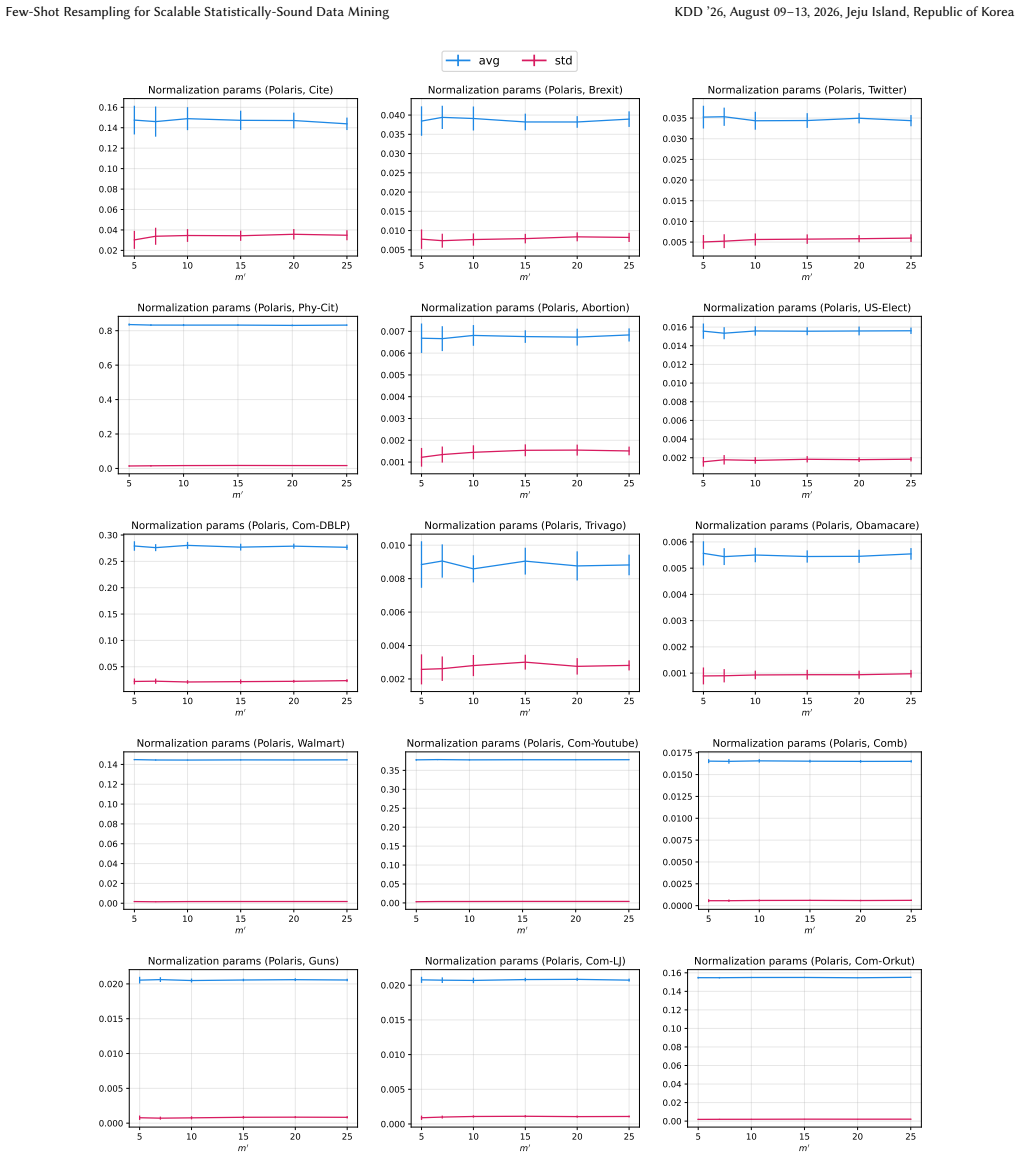
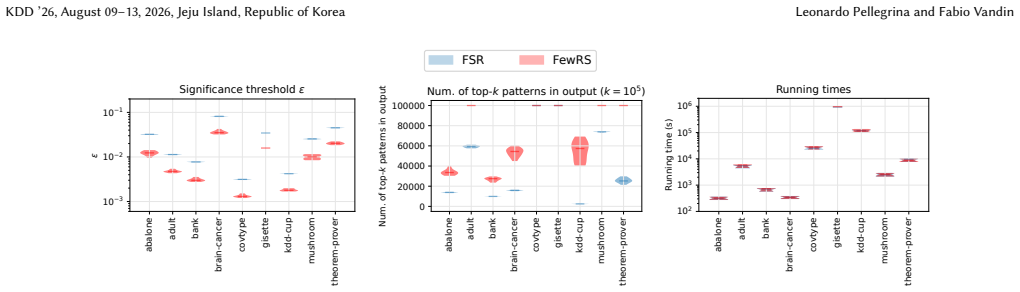
read the original abstract
A key step in knowledge discovery is the evaluation of data mining results. In several applications, including pattern mining, graph analysis, and others, this step includes the evaluation of the statistical significance of the results, to avoid spurious discoveries due only to noise or random fluctuations in the data. While specialized procedures have been developed for some specific applications, resampling-based approaches are widely used, in particular for complex analyses where analytical results cannot be derived. However, current resampling-based approaches require the generation and analysis of thousands of resampled datasets, and are therefore impractical for large datasets or computationally intensive analyses. In this paper, we introduce FewRS, a simple and effective resampling-based approach to assess the statistical significance of data mining results with rigorous guarantees on the probability of false discoveries. Our approach can be used in every situation where resampling-based approaches are applied. FewRS builds on our derivation of a novel bound to the supremum deviation of test statistics representing the quality of data mining results. We prove that FewRS needs to generate and analyze an extremely small number of resampled datasets, leading to a highly scalable approach with wide applicability. We test our approach on common tasks such as pattern mining and network analysis. In all cases, our approach results in a reduction of up to two orders of magnitude in running time compared to the state of the art, while preserving high statistical power, enabling the statistical validation of data mining results on large-scale real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FewRS, a resampling-based method for assessing statistical significance of data mining results (e.g., pattern mining, graph analysis). It derives a novel bound on the supremum deviation of test statistics to prove that only an extremely small number of resampled datasets suffice for rigorous control of false-discovery probability, yielding up to two orders of magnitude speedup over standard resampling while preserving statistical power and wide applicability.
Significance. If the central bound is valid and tight, the result would enable statistically sound validation on large-scale datasets where current resampling methods are computationally prohibitive, with direct impact on knowledge discovery pipelines.
major comments (2)
- [theoretical derivation of the bound] The section deriving the novel supremum-deviation bound: the proof must explicitly state regularity conditions on the test-statistic process and demonstrate that dependence induced by the data-mining procedure itself is accounted for; without these, the claimed rigorous guarantee on false-discovery probability when reducing resamples by 1-2 orders of magnitude cannot be verified.
- [theoretical derivation of the bound] Any implicit union bound or dependence on the number of candidate patterns must be shown not to grow with the pattern space; otherwise the bound would fail to deliver the stated control on false discoveries for realistic data-mining tasks.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on the theoretical aspects of the supremum-deviation bound. We address each major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: The section deriving the novel supremum-deviation bound: the proof must explicitly state regularity conditions on the test-statistic process and demonstrate that dependence induced by the data-mining procedure itself is accounted for; without these, the claimed rigorous guarantee on false-discovery probability when reducing resamples by 1-2 orders of magnitude cannot be verified.
Authors: We agree that explicit statements improve verifiability. In the revision we will add a dedicated paragraph stating the regularity conditions (bounded test statistics in [0,1] and exchangeability of resamples under the null) and clarify that the supremum is taken over the entire (possibly data-dependent) pattern space, so the bound holds uniformly regardless of any dependence structure induced by the mining procedure itself. revision: yes
-
Referee: Any implicit union bound or dependence on the number of candidate patterns must be shown not to grow with the pattern space; otherwise the bound would fail to deliver the stated control on false discoveries for realistic data-mining tasks.
Authors: The derivation controls the supremum deviation directly via a concentration result that does not rely on a union bound whose size scales with the pattern space cardinality. The probability statement is therefore independent of the number of patterns. We will insert an explicit remark in the proof section confirming this property and noting that the bound remains valid for arbitrarily large pattern spaces. revision: yes
Circularity Check
No significant circularity; derivation presented as independent bound
full rationale
The provided text (abstract and description) presents the core contribution as a novel derivation of a bound on the supremum deviation of test statistics, which then justifies using few resamples. No equations, proofs, or self-citations are shown that would allow any quantity to reduce to a fitted parameter or prior result by construction. The central claim therefore retains independent mathematical content outside any input data or self-referential definitions. This is the expected honest outcome when no load-bearing reduction can be exhibited from quoted paper text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maryam Abuissa, Alexander Lee, and Matteo Riondato. 2023. ROhAN: Row-order agnostic null models for statistically-sound knowledge discovery.Data Mining and Knowledge Discovery37, 4 (2023), 1692–1718
2023
-
[2]
Rakesh Agrawal, Tomasz Imieliński, and Arun Swami. 1993. Mining association rules between sets of items in large databases. InProceedings of the 1993 ACM SIGMOD international conference on Management of data. 207–216
1993
-
[3]
Mohammad Al Hasan and Mohammed J Zaki. 2009. Output space sampling for graph patterns.Proceedings of the VLDB Endowment2, 1 (2009), 730–741
2009
-
[4]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological)57, 1 (1995), 289–300
1995
-
[5]
Mario Boley, Claudio Lucchese, Daniel Paurat, and Thomas Gärtner. 2011. Direct local pattern sampling by efficient two-step random procedures. InProceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 582–590
2011
-
[6]
Béla Bollobás. 1980. A probabilistic proof of an asymptotic formula for the number of labelled regular graphs.European Journal of Combinatorics1, 4 (1980), 311–316
1980
-
[7]
Carlo Bonferroni. 1936. Teoria statistica delle classi e calcolo delle probabilita. Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commericiali di Firenze8 (1936), 3–62
1936
-
[8]
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. 2021. The echo chamber effect on social media.Proceedings of the national academy of sciences118, 9 (2021), e2023301118
2021
-
[9]
Michael Conover, Jacob Ratkiewicz, Matthew Francisco, Bruno Gonçalves, Filippo Menczer, and Alessandro Flammini. 2011. Political polarization on twitter. In Proceedings of the international aaai conference on web and social media, Vol. 5. 89–96
2011
-
[10]
Sebastian Dalleiger and Jilles Vreeken. 2022. Discovering significant patterns under sequential false discovery control. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 263–272
2022
-
[11]
Lamine Diop. 2022. High average-utility itemset sampling under length con- straints. InPacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 134–148
2022
-
[12]
Lamine Diop, Cheikh Talibouya Diop, Arnaud Giacometti, Dominique Li, and Arnaud Soulet. 2018. Sequential pattern sampling with norm constraints. In2018 IEEE International Conference on Data Mining (ICDM). IEEE, 89–98
2018
-
[13]
Bailey K Fosdick, Daniel B Larremore, Joel Nishimura, and Johan Ugander. 2018. Configuring random graph models with fixed degree sequences.Siam Review60, 2 (2018), 315–355
2018
-
[14]
Kiran Garimella, Gianmarco De Francisci Morales, Aristides Gionis, and Michael Mathioudakis. 2018. Quantifying controversy on social media.ACM Transactions on Social Computing1, 1 (2018), 1–27
2018
-
[15]
Arnaud Giacometti and Arnaud Soulet. 2018. Dense neighborhood pattern sam- pling in numerical data. InProceedings of the 2018 SIAM International Conference on Data Mining. SIAM, 756–764
2018
-
[16]
Aristides Gionis, Heikki Mannila, Taneli Mielikäinen, and Panayiotis Tsaparas
-
[17]
Assessing data mining results via swap randomization.ACM Transactions on Knowledge Discovery from Data (TKDD)1, 3 (2007), 14–es
2007
-
[18]
Sandra González-Bailón, David Lazer, Pablo Barberá, Meiqing Zhang, Hunt All- cott, Taylor Brown, Adriana Crespo-Tenorio, Deen Freelon, Matthew Gentzkow, Andrew M Guess, et al. 2023. Asymmetric ideological segregation in exposure to political news on Facebook.Science381, 6656 (2023), 392–398
2023
-
[19]
Wilhelmiina Hämäläinen and Geoffrey I Webb. 2019. A tutorial on statistically sound pattern discovery.Data Mining and Knowledge Discovery33 (2019), 325– 377
2019
-
[20]
2022.Data mining: concepts and techniques
Jiawei Han, Jian Pei, and Hanghang Tong. 2022.Data mining: concepts and techniques. Morgan kaufmann
2022
-
[21]
Yosef Hochberg. 1988. A sharper Bonferroni procedure for multiple tests of significance.Biometrika75, 4 (1988), 800–802
1988
-
[22]
Sture Holm. 1979. A simple sequentially rejective multiple test procedure.Scan- dinavian journal of statistics(1979), 65–70
1979
-
[23]
Steedman Jenkins, Stefan Walzer-Goldfeld, and Matteo Riondato. 2022. SPEck: mining statistically-significant sequential patterns efficiently with exact sampling. Data Mining and Knowledge Discovery36, 4 (2022), 1575–1599
2022
-
[24]
Adam Kirsch, Michael Mitzenmacher, Andrea Pietracaprina, Geppino Pucci, Eli Upfal, and Fabio Vandin. 2012. An efficient rigorous approach for identifying statistically significant frequent itemsets.Journal of the ACM (JACM)59, 3 (2012), 1–22
2012
-
[25]
2020.Mining of massive data sets
Jure Leskovec, Anand Rajaraman, and Jeffrey David Ullman. 2020.Mining of massive data sets. Cambridge university press
2020
-
[26]
Felipe Llinares-López, Mahito Sugiyama, Laetitia Papaxanthos, and Karsten Borg- wardt. 2015. Fast and memory-efficient significant pattern mining via permuta- tion testing. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 725–734
2015
-
[27]
Nicolai Meinshausen, Marloes H Maathuis, and Peter Bühlmann. 2011. Asymp- totic optimality of the Westfall-Young permutation procedure for multiple testing under dependence.The Annals of Statistics(2011), 3369–3391
2011
-
[28]
Shin-ichi Minato, Takeaki Uno, Koji Tsuda, Aika Terada, and Jun Sese. 2014. A fast method of statistical assessment for combinatorial hypotheses based on frequent itemset enumeration. InECML PKDD 2014. Springer
2014
-
[29]
2017.Probability and computing: Random- ization and probabilistic techniques in algorithms and data analysis
Michael Mitzenmacher and Eli Upfal. 2017.Probability and computing: Random- ization and probabilistic techniques in algorithms and data analysis. Cambridge university press
2017
-
[30]
Mark EJ Newman. 2003. Mixing patterns in networks.Physical review E67, 2 (2003), 026126
2003
-
[31]
Leonardo Pellegrina, Matteo Riondato, and Fabio Vandin. 2019. Hypothesis Testing and Statistically-sound Pattern Mining. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19). ACM, New York, NY, USA, 3215–3216
2019
-
[32]
Leonardo Pellegrina, Matteo Riondato, and Fabio Vandin. 2019. SPuManTE: Significant Pattern Mining with Unconditional Testing. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19). ACM, New York, NY, USA, 1528–1538
2019
-
[33]
Leonardo Pellegrina and Fabio Vandin. 2020. Efficient mining of the most signifi- cant patterns with permutation testing.Data Mining and Knowledge Discovery 34 (2020), 1201–1234
2020
-
[34]
Leonardo Pellegrina and Fabio Vandin. 2024. Efficient Discovery of Significant Patterns with Few-Shot Resampling.Proceedings of the VLDB Endowment17, 10 (2024), 2668–2680
2024
-
[35]
Peter H Peskun. 1973. Optimum monte-carlo sampling using markov chains. Biometrika60, 3 (1973), 607–612
1973
-
[36]
Giulia Preti, Gianmarco de Francisci Morales, and Matteo Riondato. 2024. Alice and the Caterpillar: A more descriptive null model for assessing data mining results.Knowledge and Information Systems66, 3 (2024), 1917–1954
2024
-
[37]
Giulia Preti, Matteo Riondato, Aristides Gionis, and Gianmarco De Fran- cisci Morales. 2025. Polaris: Sampling from the Multigraph Configuration Model with Prescribed Color Assortativity. InProceedings of the Eighteenth ACM Inter- national Conference on Web Search and Data Mining. 30–39
2025
- [38]
-
[39]
2016.Introduction to data mining
Pang-Ning Tan, Michael Steinbach, and Vipin Kumar. 2016.Introduction to data mining. Pearson Education India
2016
-
[40]
Aika Terada, Hanyoung Kim, and Jun Sese. 2015. High-speed Westfall-Young permutation procedure for genome-wide association studies. InProceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics. 17–26
2015
-
[41]
Aika Terada, Mariko Okada-Hatakeyama, Koji Tsuda, and Jun Sese. 2013. Sta- tistical significance of combinatorial regulations.Proceedings of the National Academy of Sciences110, 32 (2013), 12996–13001
2013
-
[42]
Andrea Tonon and Fabio Vandin. 2019. Permutation strategies for mining signifi- cant sequential patterns. In2019 IEEE International Conference on Data Mining (ICDM). IEEE, 1330–1335
2019
-
[43]
Geoffrey I Webb. 2006. Discovering significant rules. InProceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. 434–443
2006
-
[44]
Geoffrey I Webb. 2007. Discovering significant patterns.Machine learning68 (2007), 1–33
2007
-
[45]
Geoffrey I Webb. 2008. Layered critical values: a powerful direct-adjustment approach to discovering significant patterns.Machine Learning71 (2008), 307– 323
2008
-
[46]
Peter H Westfall and James F Troendle. 2008. Multiple testing with minimal assumptions.Biometrical Journal: Journal of Mathematical Methods in Biosciences 50, 5 (2008), 745–755
2008
-
[47]
max 𝐴∈ A {𝐴(D 0)} ≤𝛿(𝛼) −𝜀 𝑖
Peter H Westfall and S Stanley Young. 1993.Resampling-based multiple testing: Examples and methods for p-value adjustment. John Wiley & Sons. A Appendix In this appendix we provide additional theoretical results, proofs, and experimental results that could not fit in the main manuscript. Proof of Lemma 1 [46]. From the definition of the null hypothe- ses,...
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.