A Tutorial on World Models and Physical AI
Pith reviewed 2026-06-27 07:26 UTC · model grok-4.3
The pith
World models are unified through a shared predictive structure that differentiates explicit from implicit representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
This tutorial presents a coherent framework in which diverse world modeling approaches are unified through shared predictive structure and differentiated by how such structure is represented and exploited.
What carries the argument
The coherent framework that unifies explicit and implicit world models by shared predictive structure and differentiates them by representation and exploitation.
Load-bearing premise
Explicit and implicit world models share a common predictive structure that can organize the entire literature into one coherent framework.
What would settle it
A demonstration that the predictive mechanisms underlying explicit rollout models and implicit representation models have no measurable overlap or unifying features.
Figures


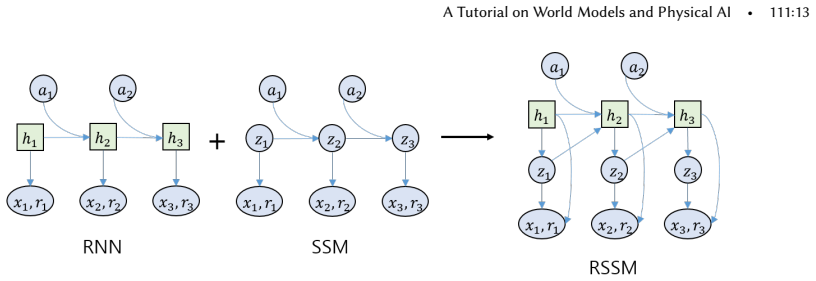
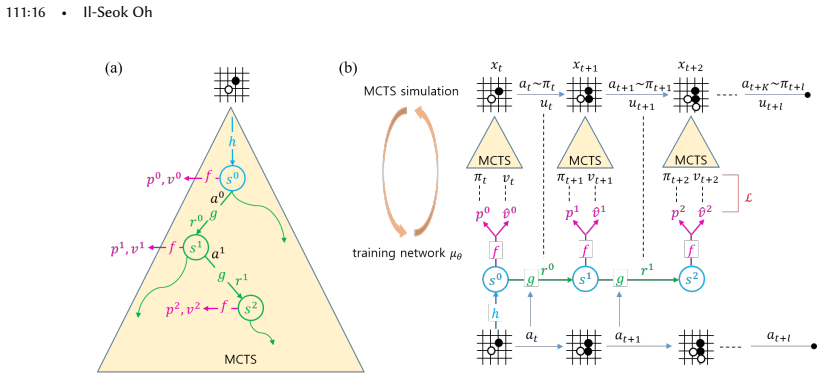
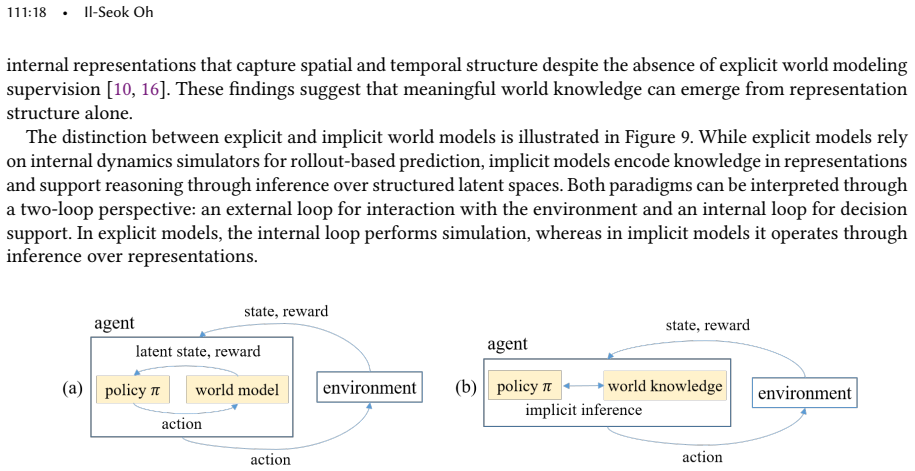

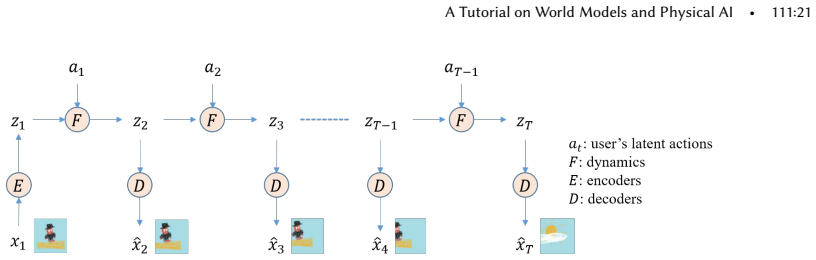


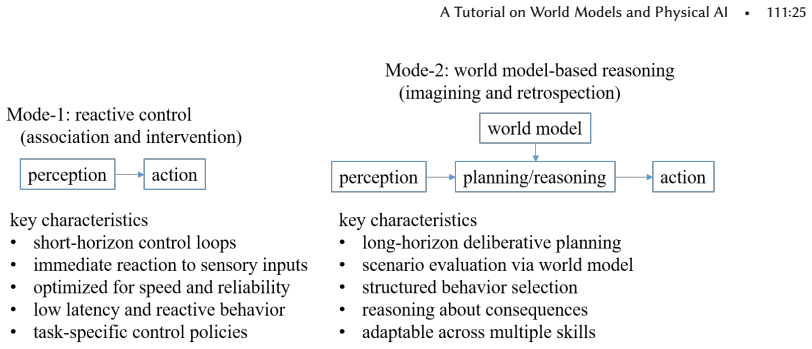



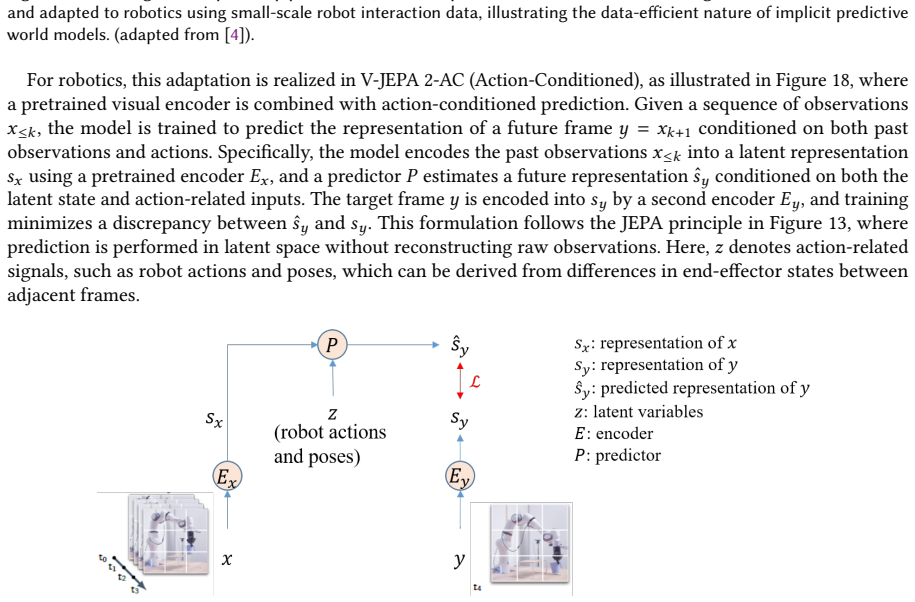
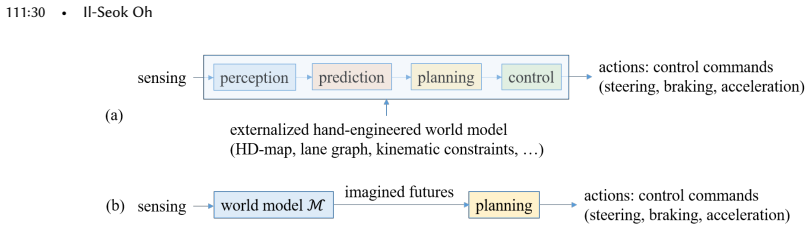
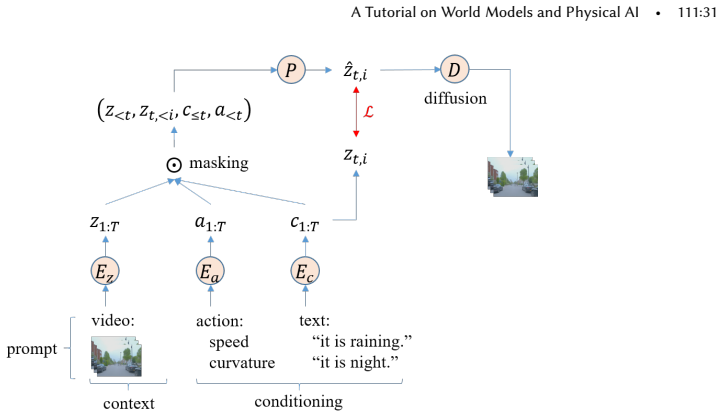
read the original abstract
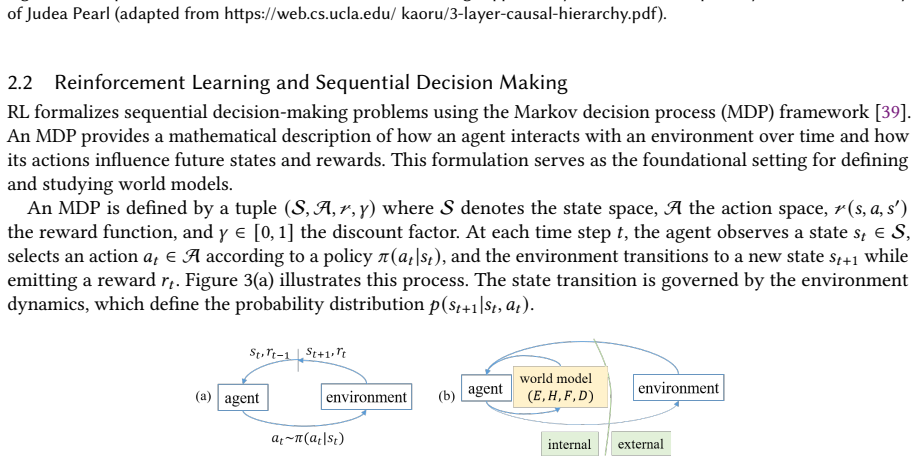
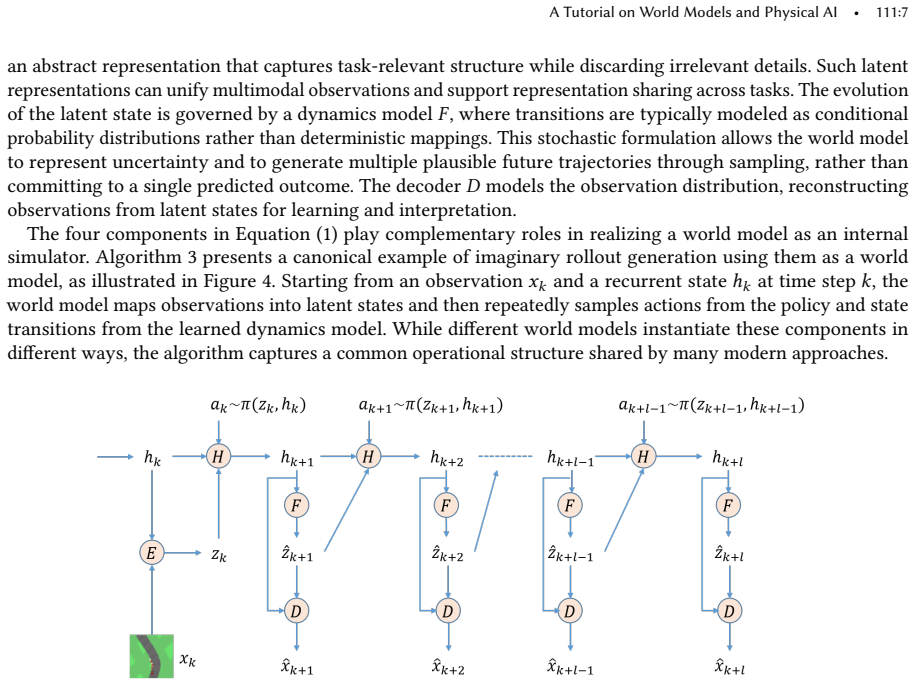
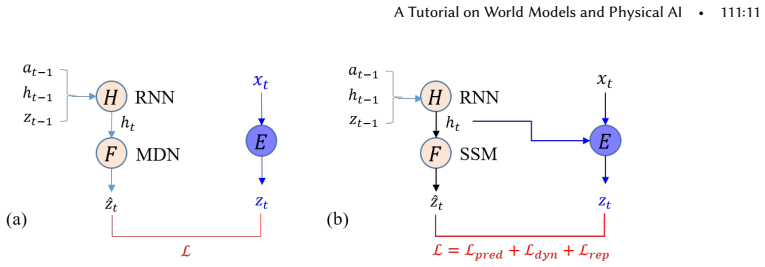
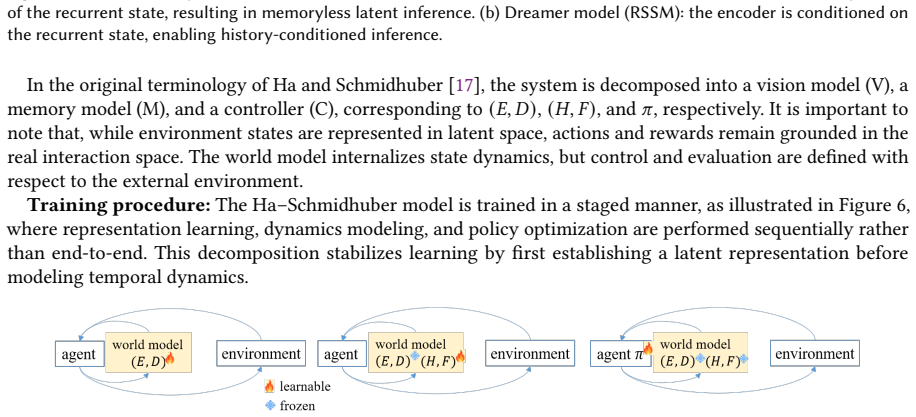
World modeling is emerging as a central principle for building intelligent systems capable of prediction, reasoning, and decision making. A central distinction can be drawn between explicit world models, which learn structured dynamics for rollout-based reasoning and planning, and implicit world models, which encode predictive structure within scalable learned representations. These complementary paradigms provide a foundation for physical AI in domains such as robotics and autonomous driving, enabling intelligence beyond reactive control under real-world constraints. Recent foundation models further suggest a pathway toward unified systems integrating perception, prediction, and action. Despite rapid progress, major challenges remain in hierarchical reasoning, long-horizon planning, and autonomous goal formation, which are critical for advancing toward artificial general intelligence. This tutorial presents a coherent framework in which diverse world modeling approaches are unified through shared predictive structure and differentiated by how such structure is represented and exploited.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This tutorial claims to present a coherent organizational framework that unifies explicit world models (structured dynamics for rollout-based reasoning and planning) and implicit world models (predictive structure encoded in scalable representations) through their shared predictive structure, while differentiating them by representation and exploitation; it positions this as foundational for physical AI in robotics and autonomous driving, notes pathways via foundation models, and identifies open challenges in hierarchical reasoning, long-horizon planning, and autonomous goal formation.
Significance. If the proposed taxonomy accurately and non-selectively captures the literature, the tutorial would provide a useful synthesis for researchers seeking to connect disparate world-modeling paradigms; as a review rather than a source of new theorems or experiments, its value lies in expository organization rather than discovery.
minor comments (1)
- [Abstract] Abstract: the final sentence states the unification claim but does not preview the specific criteria (e.g., representation type, exploitation mechanism) used to differentiate approaches, which would help readers anticipate the framework's structure.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the tutorial and their recommendation to accept. The review accurately captures the manuscript's intent to provide an expository synthesis unifying explicit and implicit world models through predictive structure for physical AI applications.
Circularity Check
Tutorial synthesis carries no derivation chain
full rationale
This is a review/tutorial paper whose sole claim is an expository unification of existing literature via a shared predictive-structure taxonomy. No equations, fitted parameters, formal derivations, or new predictions appear; the abstract and structure position the work as synthesis rather than discovery. Consequently none of the enumerated circularity patterns can apply, and the paper is self-contained as an organizational exercise.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025.Gemini Robotics: bringing AI into the physical world
Saminda Abeyruwan et al. 2025.Gemini Robotics: bringing AI into the physical world. arXiv:2503.20020 [cs.RO]
Pith/arXiv arXiv 2025
-
[2]
2025.Cosmos world foundation model platform for physical AI
Niket Agarwal et al. 2025.Cosmos world foundation model platform for physical AI. arXiv:2501.03575 [cs.CV]
Pith/arXiv arXiv 2025
-
[3]
Mahmoud Assran et al. 2023. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2023
-
[4]
2025.V-JEPA 2: self-supervised video models enable understanding, prediction and planning
Mido Assran et al. 2025.V-JEPA 2: self-supervised video models enable understanding, prediction and planning. arXiv:2506.09985 [cs.AI]
Pith/arXiv arXiv 2025
-
[5]
2024.Revisiting feature prediction for learning visual representations from video
Adrien Bardes et al. 2024.Revisiting feature prediction for learning visual representations from video. arXiv:2404.08471 [cs.CV]
Pith/arXiv arXiv 2024
-
[6]
2021.On the opportunities and risks of foundation models
Rishi Bommasani et al. 2021.On the opportunities and risks of foundation models. arXiv:2108.07258 [cs.LG]
Pith/arXiv arXiv 2021
-
[7]
2024.Genie: generative interactive environments
Jake Bruce et al. 2024.Genie: generative interactive environments. arXiv:2402.15391 [cs.LG]
arXiv 2024
-
[8]
2023.Sparks of artificial general intelligence: early experiments with GPT-4
Sebastien Bubeck et al. 2023.Sparks of artificial general intelligence: early experiments with GPT-4. arXiv:2303.12712 [cs.CL]
Pith/arXiv arXiv 2023
-
[9]
Jingtao Ding et al. 2025. Understanding world or predicting future? a comprehensive survey of world models.Comput. Surveys58, 3 (Sept. 2025), 1–38. doi:10.1145/3746449
-
[10]
Jie Feng et al. 2025.A survey of large language model-powered spatial intelligence across scales: advances in embodied agents, smart cities, and earth science. arXiv:2504.09848 [cs.AI]
arXiv 2025
-
[11]
2023.Foundation models in robotics: applications, challenges, and the future
Roya Firoozi et al. 2023.Foundation models in robotics: applications, challenges, and the future. arXiv:2312.07843 [cs.RO]
arXiv 2023
-
[12]
2025.Embodied AI agents: modeling the world
Pascale Fung et al. 2025.Embodied AI agents: modeling the world. arXiv:2506.22355 [cs.AI]
arXiv 2025
-
[13]
2025.Foundation models in autonomous driving: a survey on scenario generation and scenario analysis
Yuan Gao et al . 2025.Foundation models in autonomous driving: a survey on scenario generation and scenario analysis. arXiv:2506.11526 [cs.RO]
arXiv 2025
-
[14]
2024.Octo: open-source generalist robot policy
Dibya Ghosh et al. 2024.Octo: open-source generalist robot policy. arXiv:2405.12213 [cs.RO]
Pith/arXiv arXiv 2024
-
[15]
Yanchen Guan et al. 2024. World models for autonomous driving: an initial survey.IEEE Transactions on Intelligent Vehicles(May 2024), 1–17. doi:10.1109/TIV.2024.3398357
-
[16]
Wes Gurnee and Max Tegmark. 2024. Language models represent space and time. InInternational Conference on Learning Representations
2024
-
[17]
David Ha and Jurgen Schmidhuber. 2018.World models. arXiv:1803.10122 [cs.LG] ACM Comput. Surv., Vol. 58, No. 4, Article 111. Publication date: August 2026. A Tutorial on World Models and Physical AI•111:35
Pith/arXiv arXiv 2018
-
[18]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2025. Mastering diverse domains through world models.Nature640, 17 (April 2025), 647–665. doi:10.1038/s41586-025-08744-2
-
[19]
2018.A Thousand Brains: A New Theory of Intelligence
Jeff Hawkins. 2018.A Thousand Brains: A New Theory of Intelligence. Basic Books, New York, NY
2018
-
[20]
Kaiming He et al. 2022. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2022
-
[21]
2025.ASAP: aligning simulation and real-world physics for learning agile humanoid whole-body skills
Tairan He et al . 2025.ASAP: aligning simulation and real-world physics for learning agile humanoid whole-body skills. arXiv:2502.01143 [cs.RO]
arXiv 2025
-
[22]
Dan Hendrycks et al. 2025.A definition of AGI. arXiv:2510.18212 [cs.AI]
arXiv 2025
-
[23]
Yi-Hsuan Hsiao et al . 2025. Aerobatic maneuvers in insect-scale flapping-wing aerial robots via deep-learned robust tube model predictive control.Science Advances11, 49 (December 2025), 1–13. doi:10.1126/sciadv.aea8716
-
[24]
2023.GAIA-1: a generative world model for autonomous driving
Anthony Hu et al. 2023.GAIA-1: a generative world model for autonomous driving. arXiv:2309.17080 [cs.CV]
Pith/arXiv arXiv 2023
-
[25]
1983.Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness
Philip Nicholas Johnson-Laird. 1983.Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press, Cambridge, MA
1983
-
[26]
2011.Thinking, Fast and Slow
Daniel Kahneman. 2011.Thinking, Fast and Slow. Macmillan, New York, NY
2011
-
[27]
2024.DROID: a large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky et al. 2024.DROID: a large-scale in-the-wild robot manipulation dataset. arXiv:2403.12945 [cs.RO]
Pith/arXiv arXiv 2024
-
[28]
2025.3D and 4D world modeling: a survey
Lingdong Kong et al. 2025.3D and 4D world modeling: a survey. arXiv:2509.07996 [cs.CV]
arXiv 2025
-
[29]
Kristofer D. Kusano et al. 2025. Comparison of Waymo rider-only crash rates by crash type to human benchmarks at 56.7 million miles. Traffic Injury Prevention26, 1 (May 2025), S8–S20. doi:10.1080/15389588.2025.2499887
-
[30]
Yann LeCun. 2022. A path towards autonomous machine intelligence. https://openreview.net/pdf?id=BZ5a1r-kVsf Open Review
2022
-
[31]
Moerland, Joost Broekens, Aske Plaat, and Catholijn M
Thomas M. Moerland, Joost Broekens, Aske Plaat, and Catholijn M. Jonker. 1983. Model-based reinforcement learning: a survey. Foundations and Trends in Machine Learning16, 1 (Jan. 1983), 1–118. doi:10.1561/2200000086
-
[32]
2023.Open X-Embodiment: robotic learning datasets and RT-X models
Abby O’Neill et al. 2023.Open X-Embodiment: robotic learning datasets and RT-X models. arXiv:2310.08864 [cs.RO]
Pith/arXiv arXiv 2023
-
[33]
2009.Causality: Models, Reasoning, and Inference(2nd
Judea Pearl. 2009.Causality: Models, Reasoning, and Inference(2nd. ed.). Cambridge University Press, London, England
2009
-
[34]
R. Quian Quiroga, L. Reddy, G. Kreiman, C. Koch, and I. Fried. 2005. Invariant visual representation by single neurons in the human brain.Nature435, 23 (June 2005), 1102–1107. doi:10.1038/nature03687
-
[35]
2025.GAIA-2: a controllable multi-view generative world model for autonomous driving
Lloyd Russel et al. 2025.GAIA-2: a controllable multi-view generative world model for autonomous driving. arXiv:2503.20523 [cs.CV]
Pith/arXiv arXiv 2025
-
[36]
Julian Schrittwieser et al. 2020. Mastering Atari, Go, and chess and shogi by planning with a learned model.Nature588, 24 (December 2020), 604–612. doi:10.1038/s41586-020-03051-4
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[37]
David Silver et al. 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.Science362, 6419 (December 2018), 1140–1144. doi:10.1126/science.aar6404
-
[38]
2025.HITTER: a humanoid table tennis robot via hierarchical planning and learning
Zhi Su et al. 2025.HITTER: a humanoid table tennis robot via hierarchical planning and learning. arXiv:2508.21043 [cs.RO]
arXiv 2025
-
[39]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. 2018.Reinforcement Learning: An Introduction(2nd. ed.). The MIT Press, London, England
2018
-
[40]
Ashish Vaswani et al. 2017. Attention is all you need. InAdvances in Neural Information Processing Systems
2017
-
[41]
Wayve. 2025. GAIA-3: scaling world models to power safety and evaluation. https://wayve.ai/thinking/gaia-3. Blog post
2025
-
[42]
Jason Wei et al. 2022. Chain-of-thougth prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems
2022
-
[43]
Philipp Wu et al. 2022. DayDreamer: world models for physical robot learning. InProceedings of the Conference on Robot Learning
2022
-
[44]
Cong Zhang, Bangyang Wei, Yang Liu, , and Samuel Labi. 2026. World model-based long-tail and scenario-specific generation for autonomous driving.Journal of Intelligent and Connected Vehicles(2026). doi:10.26599/JICV.2026.9210080
-
[45]
Jingyuan Zhao et al. 2025. A survey of autonomous driving from a deep learning perspective.Comput. Surveys57, 10 (May 2025), 1–60. doi:10.1145/3729420
-
[46]
2023.A survey of large language models
Wayne Xin Zhao et al. 2023.A survey of large language models. arXiv:2303.18223 [cs.CL]
Pith/arXiv arXiv 2023
-
[47]
Haoran Zhu, Zhenyuan Dong, Kristi Topollai, Beiyao Sha, and Anna Choromanska. 2025.Self-supervised representation learning with joint embedding predictive architecture for automotive LiDAR object detection. arXiv:2501.04969 [cs.RO]
arXiv 2025
-
[48]
2024.Is Sora a world simulator? A comprehensive survey on general world models and beyond
Zheng Zhu et al. 2024.Is Sora a world simulator? A comprehensive survey on general world models and beyond. arXiv:2405.03520 [cs.CV]
arXiv 2024
-
[49]
Yongshuo Zong, Oisin Mac Aodha, and Timothy M. Hospedales. 2025. Self-supervised multimodal learning: a survey.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 7 (July 2025), 5299–5318. doi:10.1109/TPAMI.2024.3429301 Received 20 February 2026; revised 12 March 2026; accepted 5 June 2026 ACM Comput. Surv., Vol. 58, No. 4, Article 111. Publ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.