KCSAT-ML: Probing Reasoning Models with Nationwide-Cohort Human Difficulty
Pith reviewed 2026-06-27 13:06 UTC · model grok-4.3
The pith
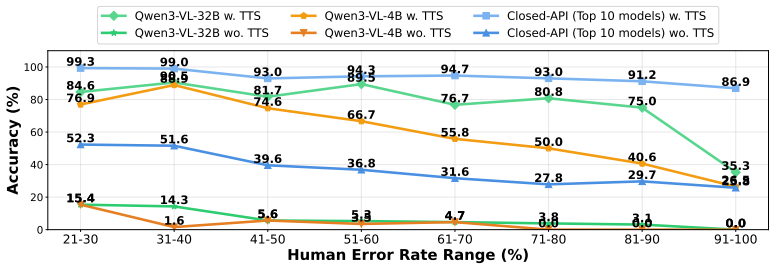
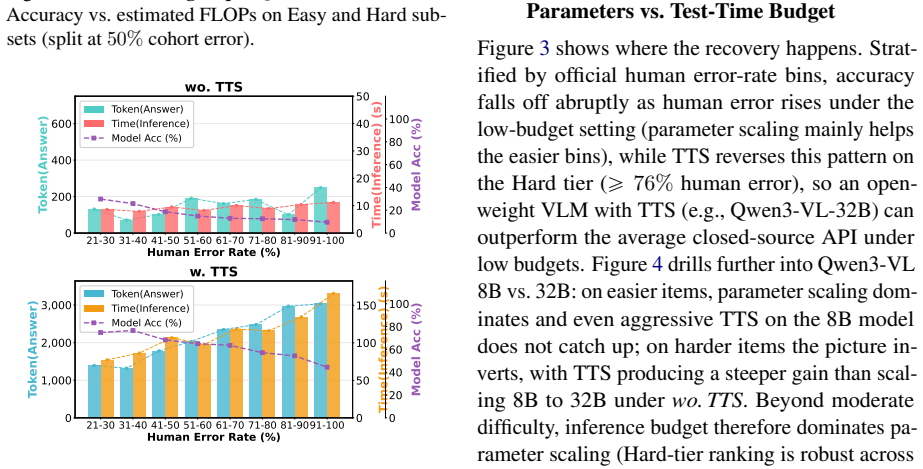
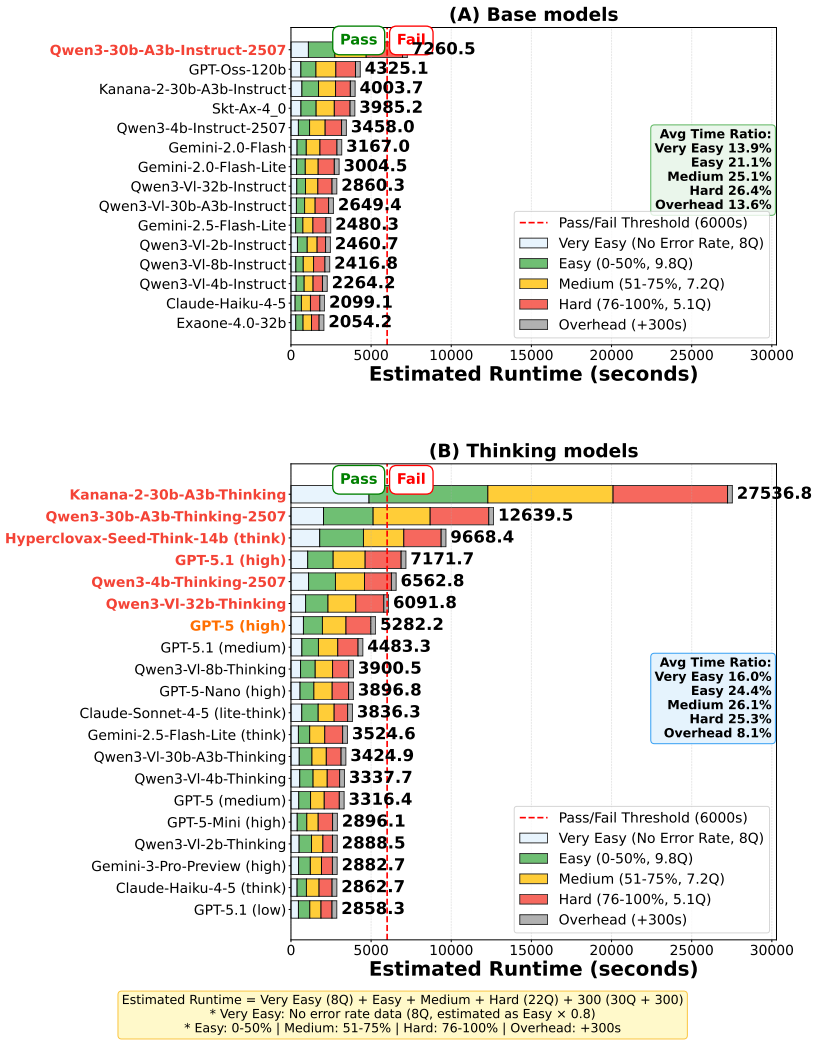
Models' accuracy collapses on items humans find hardest at low budgets, while test-time scaling increases tokens linearly with human error rates but yields non-monotonic accuracy gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
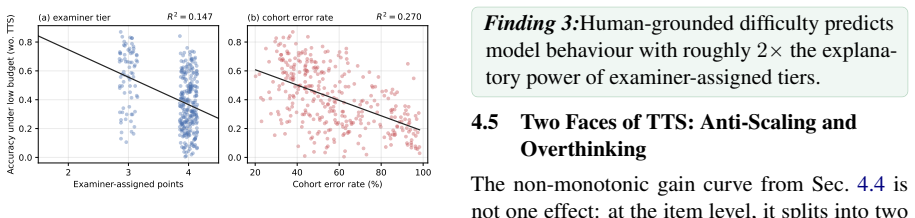
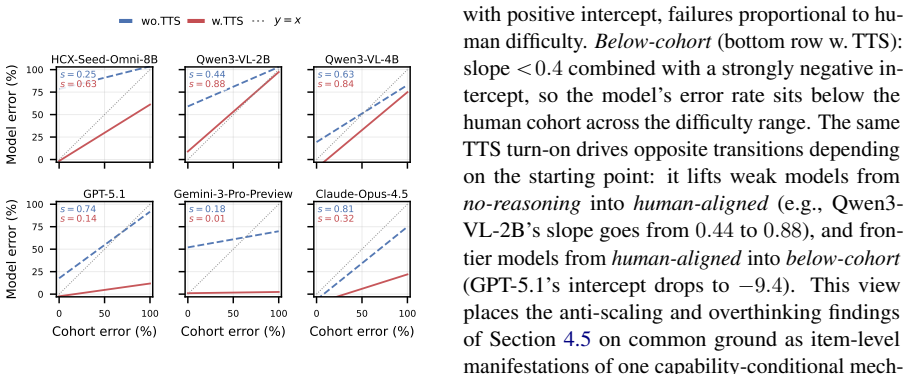
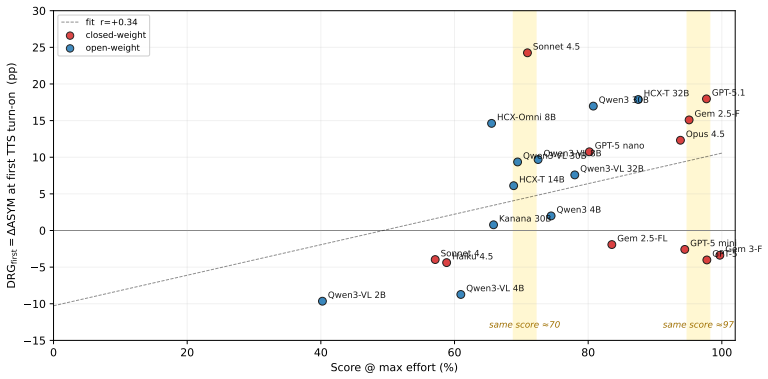
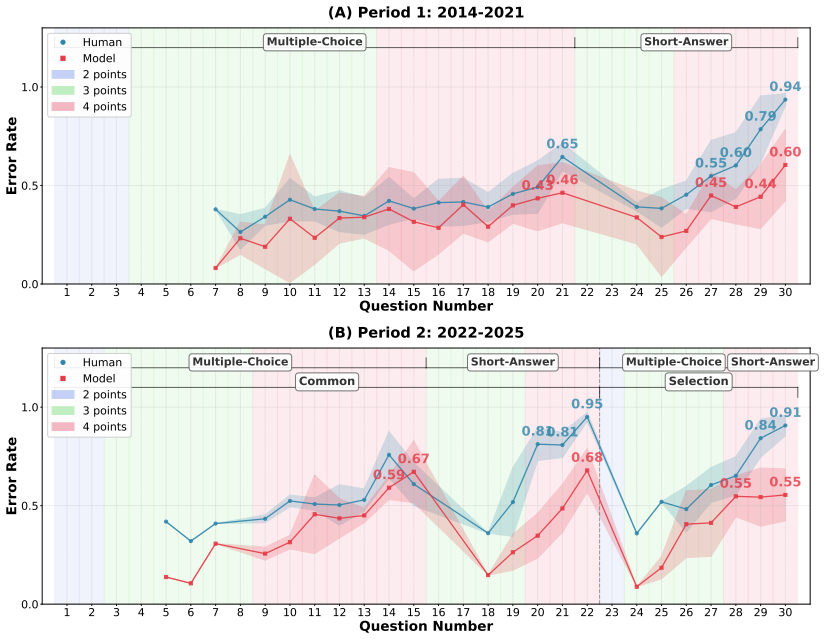
KCSAT-ML supplies 664 math problems with official per-item error rates from large human cohorts, together with the DRG metric that quantifies how well model errors match human difficulty patterns. This combination shows low-budget accuracy collapses on the high-human-error tail at every model size, test-time scaling raises token use roughly linearly with cohort error rate while accuracy gains follow a non-monotonic curve, and within a single family TTS flips between anti-scaling on the hardest items and overthinking on easier ones. Models with near-identical accuracy can occupy opposite positions on the DRG scale.
What carries the argument
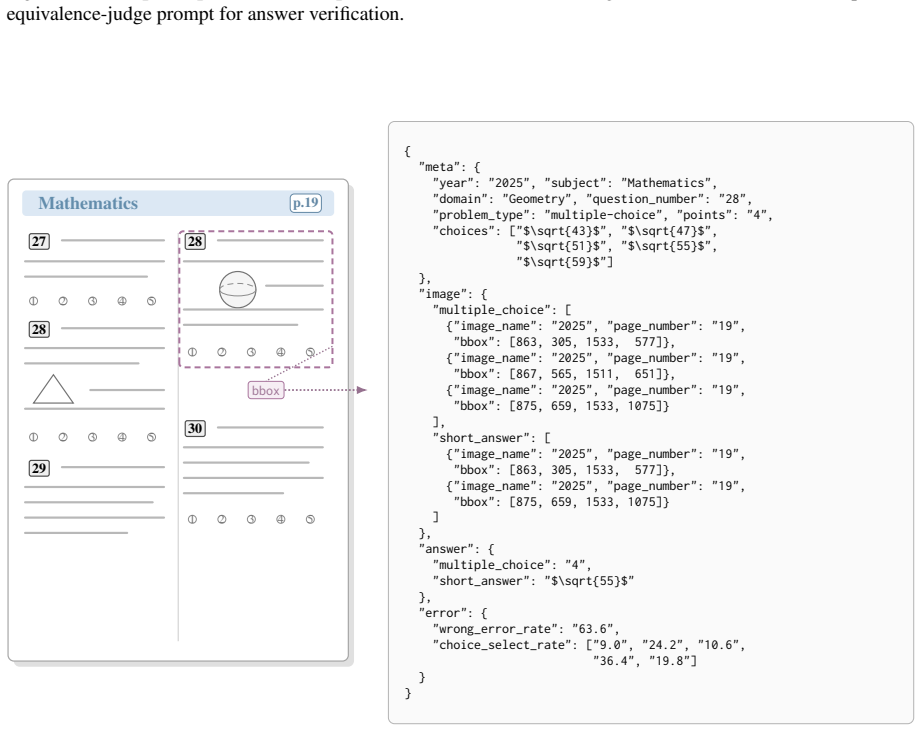
The KCSAT-ML benchmark of exam problems carrying nationwide human error rates, paired with the Difficulty-aligned Reasoning Gain metric that measures alignment between model and human mistake patterns.
If this is right
- Low-budget accuracy collapses on the high-human-error tail at every model size.
- Test-time scaling raises token use roughly linearly with cohort error rate while accuracy gains follow a non-monotonic curve.
- Within a single family, TTS flips between anti-scaling on the hardest items and overthinking on easier ones.
- Models with near-identical accuracy can sit at near-opposite DRG values.
Where Pith is reading between the lines
- Training objectives could reward alignment between model errors and human difficulty distributions in addition to raw accuracy.
- Similar cohort-based difficulty signals could be collected for exams in other subjects to test whether the scaling patterns generalize.
- Inference procedures might incorporate early estimates of item difficulty to reduce overthinking on easy problems while sustaining effort on hard ones.
- Aggregate accuracy scores alone are insufficient for comparing reasoning behavior across models.
Load-bearing premise
Nationwide cohort error rates from the Korean exam provide an unbiased, model-independent measure of item difficulty that can be directly compared to model error patterns.
What would settle it
A model achieving high accuracy on the high-human-error items at low token budgets, without exposure to the exam data, would challenge the reported collapse pattern.
Figures




read the original abstract
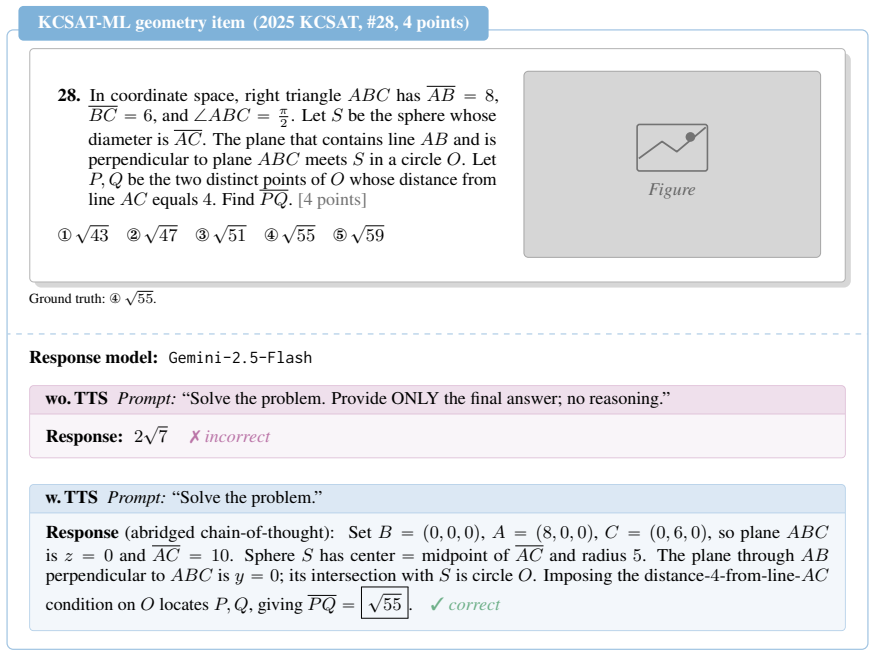
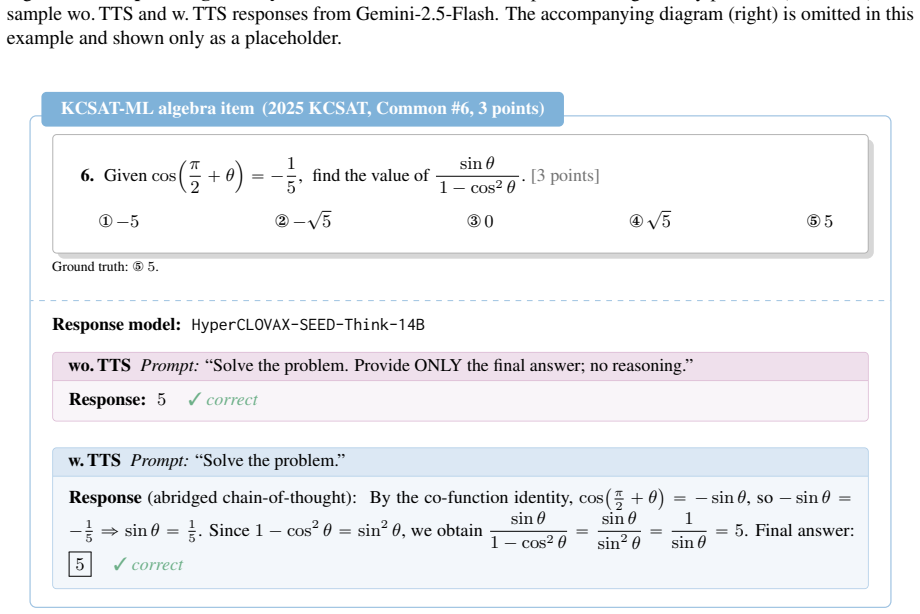
Math reasoning benchmarks have proliferated, yet most lack a per-item difficulty signal grounded in actual human performance. We introduce KCSAT-ML, a decade (2014-2025) of Korean College Scholastic Ability Test (KCSAT; Suneung) mathematics: 664 problems with a 339-item core set carrying official per-item error rates from nationwide cohorts of hundreds of thousands of examinees. We pair the benchmark with Difficulty-aligned Reasoning Gain (DRG): a score-orthogonal metric that asks whether a model's mistakes concentrate on the items humans found hard, or on items humans found easy. Together they expose, across a wide range of VLMs (and LLMs via OCR), three patterns: (i) low-budget accuracy collapses on the high-human-error tail at every model size; (ii) test-time scaling (TTS) raises token use roughly linearly with cohort error rate, while accuracy gains follow a non-monotonic curve; (iii) within a single family, TTS flips between anti-scaling on the hardest items and overthinking on easier ones -- two faces of the same alignment failure. On DRG, models with near-identical accuracy can sit at near-opposite values: one model gets wrong what humans also find hard, while another solves the hardest items yet fails on items humans find easy -- a contrast that aggregate accuracy hides. Our code and dataset builder will be open-sourced at https://github.com/naver-ai/KCSAT-ML.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KCSAT-ML, a benchmark of 664 KCSAT mathematics problems (339-item core) with official per-item error rates from large nationwide human cohorts (2014-2025), and proposes the Difficulty-aligned Reasoning Gain (DRG) metric claimed to be score-orthogonal. It reports three patterns across VLMs/LLMs: (i) low-budget accuracy collapses on the high-human-error tail at every model size; (ii) test-time scaling increases token use linearly with cohort error rate but accuracy gains are non-monotonic; (iii) within a model family, TTS flips between anti-scaling on hardest items and overthinking on easier ones. Models with similar accuracy can show opposite DRG values.
Significance. If the nationwide cohort error rates provide an exogenous, model-independent difficulty axis and DRG is verifiably orthogonal without contamination artifacts, the benchmark would offer a useful human-grounded probe for reasoning alignment that aggregate accuracy metrics miss, with potential to expose scaling limitations on difficult items.
major comments (2)
- [Methods / Data construction] The central claims (accuracy collapse on high-error tail, linear TTS token scaling, within-family sign flip, and DRG orthogonality) all treat KCSAT error rates as an unbiased exogenous difficulty measure. No validation is provided that problems/solutions have not appeared in Common Crawl-scale training data via Korean web forums, textbooks, or exam-prep sites; differential memorization could produce the exact observed patterns without any reasoning alignment. This assumption is load-bearing and requires explicit checks (e.g., contamination audits or exclusion criteria) in the methods.
- [DRG definition (likely §3 or §4)] DRG is presented as score-orthogonal by construction, yet the abstract provides no equations, exclusion criteria, or validation that it is independent of accuracy; the reader's note indicates full methods are needed to confirm it does not reduce to fitted parameters or self-referential definitions.
minor comments (2)
- [Abstract] The abstract states the dataset builder will be open-sourced but does not specify the exact release contents (e.g., raw cohort statistics, OCR pipeline, or per-item metadata) needed for reproducibility.
- [Results] No table or figure numbers are referenced in the provided abstract for the three reported patterns; cross-referencing to specific results would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing methodological rigor. We address each major point below and will incorporate revisions to strengthen the claims regarding data validity and metric transparency.
read point-by-point responses
-
Referee: [Methods / Data construction] The central claims (accuracy collapse on high-error tail, linear TTS token scaling, within-family sign flip, and DRG orthogonality) all treat KCSAT error rates as an unbiased exogenous difficulty measure. No validation is provided that problems/solutions have not appeared in Common Crawl-scale training data via Korean web forums, textbooks, or exam-prep sites; differential memorization could produce the exact observed patterns without any reasoning alignment. This assumption is load-bearing and requires explicit checks (e.g., contamination audits or exclusion criteria) in the methods.
Authors: We agree that explicit contamination validation is necessary to confirm the error rates function as an exogenous, model-independent difficulty axis. The per-item error rates derive directly from official nationwide human cohorts (hundreds of thousands of examinees per year), independent of model training. However, the original submission did not include dedicated audits for leakage via Common Crawl, Korean forums, textbooks, or prep sites. In revision we will add a data-construction subsection reporting systematic searches for problem/solution overlaps, explicit exclusion criteria, and re-computed results on the decontaminated core set to verify that the reported patterns persist. revision: yes
-
Referee: [DRG definition (likely §3 or §4)] DRG is presented as score-orthogonal by construction, yet the abstract provides no equations, exclusion criteria, or validation that it is independent of accuracy; the reader's note indicates full methods are needed to confirm it does not reduce to fitted parameters or self-referential definitions.
Authors: Section 3 of the manuscript already contains the full DRG definition and the construction that enforces score-orthogonality via normalization against human error rates. To address the concern about transparency, we will (i) add a concise equation and orthogonality statement to the abstract, (ii) expand the methods with explicit exclusion criteria and empirical validation (correlation tables across models showing near-zero dependence on aggregate accuracy), and (iii) include additional checks confirming DRG does not collapse to fitted or self-referential parameters. revision: yes
Circularity Check
No significant circularity; empirical benchmark with definitional metric
full rationale
The paper introduces KCSAT-ML as an external benchmark grounded in nationwide human cohort error rates (2014-2025 KCSAT data) and defines DRG explicitly as a score-orthogonal metric. Reported patterns are direct observational comparisons of model accuracy and token usage against these human rates, with no equations, fitted parameters, or derivations that reduce to inputs by construction. No self-citations are invoked as load-bearing premises, and the orthogonality of DRG is stated upfront rather than derived as a result. The analysis remains self-contained against the provided benchmark data without any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nationwide KCSAT per-item error rates constitute an unbiased proxy for human difficulty independent of model training distributions.
invented entities (1)
-
Difficulty-aligned Reasoning Gain (DRG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang. 2024. https://doi.org/10.48550/arXiv.2412.09078 Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning . In International Conference on Machine Learning
-
[2]
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2024. Do Not Think That Much for 2+3=? On the Overthinking of o1-Like LLMs . arXiv preprint arXiv:2412.21187
Pith/arXiv arXiv 2024
-
[3]
DeepSeek-AI . 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning . arXiv preprint arXiv:2501.12948
Pith/arXiv arXiv 2025
-
[4]
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. 2024. https://doi.org/10.48550/arXiv.2410.07985 Omni-MATH: A Universal Olympiad Level Mathematic Benchm...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.07985 2024
-
[5]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Z. Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. https://doi.org/10.48550/arXiv.2402.14008 OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems . In Annual Meeting of the...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.14008 2024
-
[6]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving With the MATH Dataset . In NeurIPS
2021
-
[7]
Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong
Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, C. Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong. 2025. https://doi.org/10.48550/arXiv.2501.19324 Reward-Guided Speculative Decoding for Efficient LLM Reasoning . In International Conference on Machine Learning
-
[8]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let's Verify Step by Step . In International Conference on Learning Representations
2024
-
[9]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun yue Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2023. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts . In International Conference on Learning Representations
2023
-
[10]
McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, and 1 others
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, and 1 others. 2023. Inverse Scaling: When Bigger Isn't Better . Transactions on Machine Learning Research (TMLR)
2023
-
[11]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Fei-Fei Li, Hanna Hajishirzi, Luke S. Zettlemoyer, Percy Liang, Emmanuel J. Candès, and Tatsunori Hashimoto. 2025. https://doi.org/10.48550/arXiv.2501.19393 s1: Simple test-time scaling . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.19393 2025
-
[12]
Sanghee Park and Geewook Kim. 2025. https://doi.org/10.18653/v1/2025.naacl-short.56 Evaluating multimodal generative AI with K orean educational standards . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 671--688, Alb...
-
[13]
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma Gongque, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, Runfeng Qiao, Yifan Zhang, Xiao Zong, Yida Xu, Muxi Diao, Zhimin Bao, Chen Li, and Honggang Zhang. 2024. https://doi.org/10.48550/arXiv.2407.01284 We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reaso...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.01284 2024
-
[14]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. https://doi.org/10.48550/arXiv.2408.03314 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters . arXiv preprint arXiv:2408.03314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[15]
Guijin Son, Seungone Kim, Catherine Arnett, and 1 others. 2026. Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs . arXiv preprint arXiv:2605.09063
Pith/arXiv arXiv 2026
-
[16]
Schuurmans, Quoc Le, Ed H
Xuezhi Wang, Jason Wei, D. Schuurmans, Quoc Le, Ed H. Chi, and Denny Zhou. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models . In International Conference on Learning Representations
2022
-
[17]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022 a . Emergent Abilities of Large Language Models . Transactions on Machine Learning Research
2022
-
[18]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, F. Xia, Quoc Le, and Denny Zhou. 2022 b . Chain of Thought Prompting Elicits Reasoning in Large Language Models . In Neural Information Processing Systems
2022
-
[19]
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. 2025. https://doi.org/10.48550/arXiv.2505.13417 AdaptThink: Reasoning Models Can Learn When to Think . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.