SFKD: Spatial--Frequency Joint-Aware Heterogeneous Knowledge Distillation via Multi-Level Wavelet Spectral Interaction
Pith reviewed 2026-07-03 16:00 UTC · model grok-4.3
The pith
Heterogeneous knowledge distillation preserves transferable spatial semantics by decoupling representations with multi-level wavelet transforms and frequency filtering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
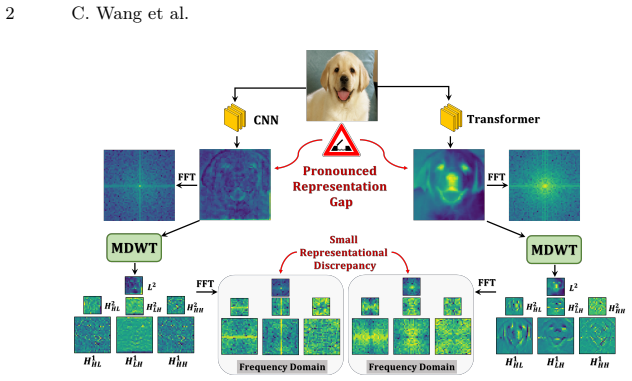
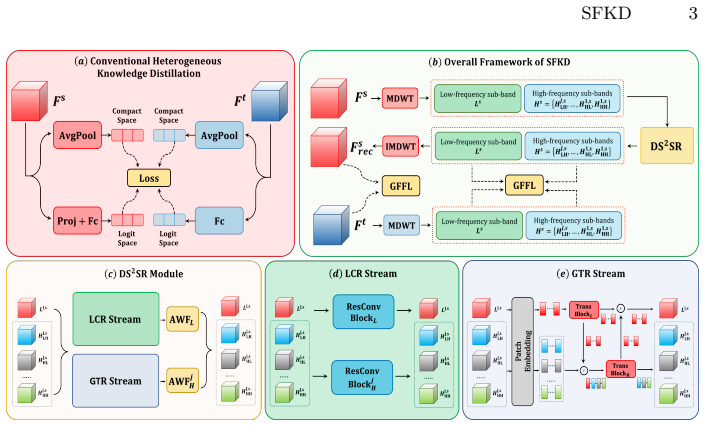
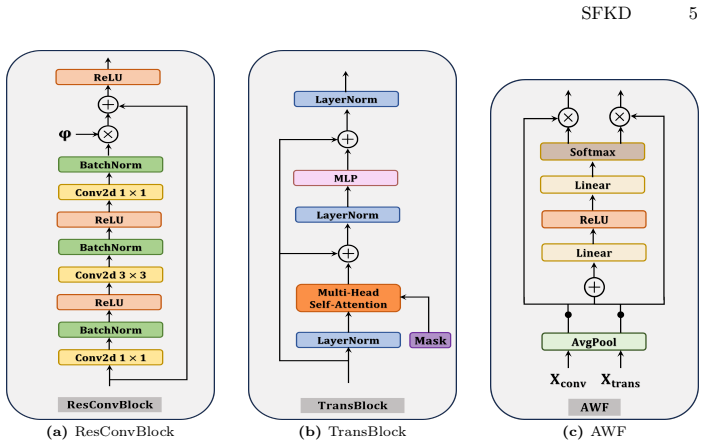
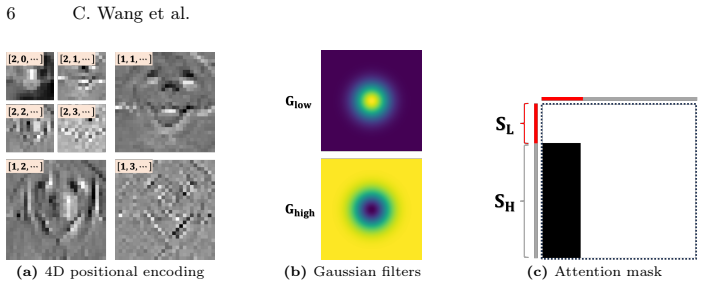
The SFKD framework applies multi-level discrete wavelet transform to explicitly decouple spatial information in heterogeneous representations. The resulting wavelet sub-bands are refined by a dual-stream dual-stage refinement module and combined with a Gaussian-filtered frequency loss to selectively capture informative global information, leveraging the complementary properties of wavelet spatial locality and Fourier global energy distributions to enable effective knowledge transfer despite architecture-specific biases.
What carries the argument
Multi-level discrete wavelet transform to decouple spatial information in heterogeneous representations, refined by dual-stream dual-stage module and integrated with Gaussian-filtered frequency loss.
Load-bearing premise
The spatial information encoded in heterogeneous representations contains transferable global structural semantics that can be recovered by multi-level discrete wavelet transform without introducing artifacts that harm distillation performance.
What would settle it
If the proposed method yields lower accuracy than existing heterogeneous distillation baselines on image classification benchmarks such as CIFAR-100 or ImageNet when distilling from a CNN teacher to a Vision Transformer student, the claim of superiority via wavelet-frequency interaction would be falsified.
Figures
read the original abstract
Most existing knowledge distillation methods focus on homogeneous models (e.g., CNN-to-CNN), thereby overlooking the flexibility and potential of knowledge transfer across heterogeneous models. Due to intrinsic inductive bias discrepancies between heterogeneous models that cause spatial distribution inconsistencies, prior heterogeneous distillation methods often weaken or discard spatial information in heterogeneous representations. However, the spatial information in representations often encodes transferable global structural semantics as well as architecture-specific local details, and therefore should not be directly ignored. To better leverage the spatial information encoded in heterogeneous representations, we propose a Spatial-Frequency Joint-Aware Heterogeneous Knowledge Distillation framework (SFKD). By leveraging the complementary properties of wavelet transform spatial locality and Fourier representations in characterizing global energy distributions, we first apply multi-level discrete wavelet transform to explicitly decouple spatial information. The resulting wavelet sub-bands are further refined by a dual-stream dual-stage refinement module, and finally combined with a Gaussian-filtered frequency loss to selectively capture informative global information. Extensive experiments on multiple benchmark datasets under both homogeneous and heterogeneous models demonstrate the superiority of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SFKD, a Spatial-Frequency Joint-Aware Heterogeneous Knowledge Distillation framework. It applies multi-level discrete wavelet transform to decouple spatial information in heterogeneous representations, refines the resulting sub-bands via a dual-stream dual-stage module, and combines them with a Gaussian-filtered frequency loss to capture global energy distributions, claiming improved performance over prior methods on multiple benchmark datasets for both homogeneous and heterogeneous teacher-student pairs.
Significance. If the reported gains prove robust under controlled hyper-parameter sweeps and fair architectural comparisons, the work would offer a practical engineering contribution to heterogeneous distillation by explicitly preserving transferable global structural semantics that prior methods often discard due to inductive-bias mismatches. The use of complementary wavelet locality and Fourier global descriptors is a reasonable incremental step, though it rests entirely on empirical validation rather than a parameter-free derivation or theoretical guarantee.
minor comments (3)
- [Experiments] The abstract states that experiments demonstrate superiority, but the experimental section should include explicit ablation tables isolating the contribution of the dual-stream dual-stage refinement module versus the Gaussian-filtered frequency loss alone (e.g., Table X, rows for each component).
- Clarify the exact number of wavelet decomposition levels, the choice of wavelet basis, and any hyper-parameters of the Gaussian filter; these choices appear to affect the spatial-frequency interaction and should be reported with sensitivity analysis.
- [Experiments] Ensure all reported metrics include standard deviations over multiple random seeds and list the precise teacher-student architecture pairs (CNN-to-Transformer, etc.) with baseline re-implementations under identical training protocols.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our SFKD framework and the recommendation of minor revision. The assessment correctly identifies the empirical nature of the contribution and the use of wavelet-Fourier complementarity for heterogeneous distillation. No major comments were enumerated in the report, so we provide no point-by-point rebuttals below.
Circularity Check
No significant circularity detected
full rationale
The paper proposes an incremental engineering framework (SFKD) for heterogeneous knowledge distillation that combines multi-level discrete wavelet transform with Fourier-based frequency loss and a dual-stream refinement module. All load-bearing claims rest on empirical superiority demonstrated via experiments on external benchmark datasets under homogeneous and heterogeneous settings. No mathematical derivation chain, uniqueness theorem, or parameter-fitting step is presented that reduces by construction to self-defined quantities or self-citations. The method is externally falsifiable through standard distillation benchmarks and does not invoke self-referential definitions or ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Wavelet sub-bands obtained from multi-level discrete wavelet transform on heterogeneous representations encode both global structural semantics and architecture-specific local details that are useful for distillation.
- domain assumption Complementary properties of wavelet spatial locality and Fourier global energy distributions allow selective capture of informative global information via Gaussian filtering.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Chen, P., Liu, S., Zhao, H., Jia, J.: Distilling knowledge via knowledge review. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 5008–5017 (2021) 2, 14, 1, 4 16 C. Wang et al
2021
-
[2]
Mathematics of computation19(90), 297–301 (1965) 10
Cooley, J.W., Tukey, J.W.: An algorithm for the machine calculation of complex fourier series. Mathematics of computation19(90), 297–301 (1965) 10
1965
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) 1, 3, 8, 9, 13
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Du, P., Li, H., Xu, H., Jeon, P.B., Lee, D., Ji, D., Yang, R., Zhu, F.: Diffusion transformer meets multi-level wavelet spectrum for single image super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19700–19710 (2025) 7, 2
2025
-
[5]
In: European conference on computer vision
Finder, S.E., Amoyal, R., Treister, E., Freifeld, O.: Wavelet convolutions for large receptive fields. In: European conference on computer vision. pp. 363–380. Springer (2024) 7, 2
2024
-
[6]
Georg-August- Universitat, Gottingen
Haar, A.: Zur theorie der orthogonalen funktionensysteme. Georg-August- Universitat, Gottingen. (1909) 6
1909
-
[7]
Advances in Neural Information Processing Systems36, 79570–79582 (2023) 3, 5, 12, 13, 14, 1, 4, 7
Hao, Z., Guo, J., Han, K., Tang, Y., Hu, H., Wang, Y., Xu, C.: One-for-all: Bridge the gap between heterogeneous architectures in knowledge distillation. Advances in Neural Information Processing Systems36, 79570–79582 (2023) 3, 5, 12, 13, 14, 1, 4, 7
2023
-
[8]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 1, 3
2016
-
[9]
In: Proceedings of the IEEE/CVF international conference on computer vision
Heo,B.,Kim,J.,Yun,S.,Park,H.,Kwak,N.,Choi,J.Y.:Acomprehensiveoverhaul of feature distillation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1921–1930 (2019) 2, 14, 1, 4
1921
-
[10]
Distilling the Knowledge in a Neural Network
Hinton, G.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015) 2, 12, 13, 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., An- dreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017) 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Advances in Neural Information Processing Systems35, 33716– 33727 (2022) 2, 12, 13, 14, 1, 4
Huang, T., You, S., Wang, F., Qian, C., Xu, C.: Knowledge distillation from a stronger teacher. Advances in Neural Information Processing Systems35, 33716– 33727 (2022) 2, 12, 13, 14, 1, 4
2022
-
[13]
IEEE Transactions on Multimedia26, 7058–7073 (2024) 7, 9
Huang, Y., Huang, J., Liu, J., Yan, M., Dong, Y., Lv, J., Chen, C., Chen, S.: Wavedm: Wavelet-based diffusion models for image restoration. IEEE Transactions on Multimedia26, 7058–7073 (2024) 7, 9
2024
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jiang, L., Dai, B., Wu, W., Loy, C.C.: Focal frequency loss for image reconstruc- tion and synthesis. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13919–13929 (2021) 11, 3
2021
-
[15]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009) 3
2009
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, G., Wang, Q., Yan, K., Ding, S., Gao, Y., Xia, G.S.: Fuse before transfer: Knowledge fusion for heterogeneous distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3445–3454 (2025) 3, 5, 12, 13, 14, 15, 1, 2, 4
2025
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, J., Hassani, A., Walton, S., Shi, H.: Convmlp: Hierarchical convolutional mlps for vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6307–6316 (2023) 2, 1
2023
-
[18]
Neural Networks177, 106378 (2024) 7, 2 SFKD 17
Li, J., Cheng, B., Chen, Y., Gao, G., Shi, J., Zeng, T.: Ewt: Efficient wavelet- transformer for single image denoising. Neural Networks177, 106378 (2024) 7, 2 SFKD 17
2024
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12581–12600 (2023) 2, 1
Li, K., Wang, Y., Zhang, J., Gao, P., Song, G., Liu, Y., Li, H., Qiao, Y.: Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12581–12600 (2023) 2, 1
2023
-
[20]
arXiv preprint arXiv:2304.11832 (2023) 2, 11, 14, 15, 1, 4
Liu, D., Kan, M., Shan, S., Chen, X.: Function-consistent feature distillation. arXiv preprint arXiv:2304.11832 (2023) 2, 11, 14, 15, 1, 4
-
[21]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021) 1, 3
2021
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11976–11986 (2022) 1, 3
2022
-
[23]
Elsevier (1999) 7, 14
Mallat, S.: A wavelet tour of signal processing. Elsevier (1999) 7, 14
1999
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Miao, Y., Deng, J., Han, J.: Waveface: Authentic face restoration with efficient frequency recovery. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6583–6592 (2024) 7, 9
2024
-
[25]
Proceedings of the IEEE69(5), 529–541 (2005) 11, 3, 6
Oppenheim, A.V., Lim, J.S.: The importance of phase in signals. Proceedings of the IEEE69(5), 529–541 (2005) 11, 3, 6
2005
- [26]
-
[27]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3967–3976 (2019) 2, 12, 13, 1, 4
2019
-
[28]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peng, B., Jin, X., Liu, J., Li, D., Wu, Y., Liu, Y., Zhou, S., Zhang, Z.: Corre- lation congruence for knowledge distillation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5007–5016 (2019) 2, 12, 13, 1, 4
2019
-
[29]
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., Dosovitskiy, A.: Do vision transformers see like convolutional neural networks? Advances in neural informa- tion processing systems34, 12116–12128 (2021) 3, 7
2021
-
[30]
FitNets: Hints for Thin Deep Nets
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550 (2014) 2, 12, 13, 1, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
International journal of computer vision115, 211–252 (2015) 3
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recog- nition challenge. International journal of computer vision115, 211–252 (2015) 3
2015
-
[32]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv2: In- verted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4510–4520 (2018) 1, 3
2018
-
[33]
SIAM (1996) 7, 14
Strang, G., Nguyen, T.: Wavelets and filter banks. SIAM (1996) 7, 14
1996
-
[34]
Tian, Y., Krishnan, D., Isola, P.: Contrastive representation distillation. arXiv preprint arXiv:1910.10699 (2019) 2, 12, 13, 14, 1, 4
-
[35]
Advances in neural information processing systems34, 24261–24272 (2021) 1, 3
Tolstikhin, I.O., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., Yung, J., Steiner, A., Keysers, D., Uszkoreit, J., et al.: Mlp-mixer: An all- mlp architecture for vision. Advances in neural information processing systems34, 24261–24272 (2021) 1, 3
2021
-
[36]
IEEE transactions on pattern analysis and machine intelligence45(4), 5314–5321 (2022) 1, 3
Touvron, H., Bojanowski, P., Caron, M., Cord, M., El-Nouby, A., Grave, E., Izac- ard, G., Joulin, A., Synnaeve, G., Verbeek, J., et al.: Resmlp: Feedforward networks for image classification with data-efficient training. IEEE transactions on pattern analysis and machine intelligence45(4), 5314–5321 (2022) 1, 3
2022
-
[37]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021) 1, 3 18 C. Wang et al
2021
-
[38]
In: Wavelet applications in signal and image processing V
Unser, M.A.: Ten good reasons for using spline wavelets. In: Wavelet applications in signal and image processing V. vol. 3169, pp. 422–431. SPIE (1997) 7, 9, 14, 6
1997
-
[39]
Vetterli, M., Kovacevic, J.: Wavelets and subband coding, vol. 87. Prentice Hall PTR Englewood Cliffs, NJ (1995) 7, 9, 14, 6
1995
-
[40]
IEEE Transactions on Circuits and Systems for Video Technology (2025) 7, 9
Wang, Q., Li, Z., Zhang, S., Chi, N., Dai, Q.: Wavefusion: A novel wavelet vision transformer with saliency-guided enhancement for multimodal image fusion. IEEE Transactions on Circuits and Systems for Video Technology (2025) 7, 9
2025
-
[41]
arXiv preprint arXiv:2405.18524 (2024) 3, 5, 1
Wu, H., Xiao, L., Zhang, X., Miao, Y.: Aligning in a compact space: Con- trastive knowledge distillation between heterogeneous architectures. arXiv preprint arXiv:2405.18524 (2024) 3, 5, 1
-
[42]
In: European conference on computer vision
Yao, T., Pan, Y., Li, Y., Ngo, C.W., Mei, T.: Wave-vit: Unifying wavelet and trans- formers for visual representation learning. In: European conference on computer vision. pp. 328–345. Springer (2022) 7, 2
2022
-
[43]
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928 (2016) 14, 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J.: Decoupled knowledge distillation. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 11953–11962 (2022) 2, 12, 13, 14, 1, 4 SFKD: Spatial–Frequency Joint-Aware Heterogeneous Knowledge Distillation via Multi-Level Wavelet Spectral Interaction (Appendix) Cuipeng Wang1,2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.