Interpreting Brain Responses to Language with Sparse Features from Language Models
Pith reviewed 2026-06-27 22:15 UTC · model grok-4.3
The pith
Brain responses during language processing are best explained by the most general features encoded in language model representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
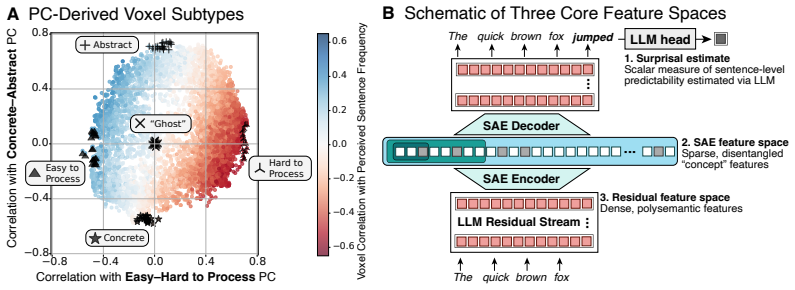
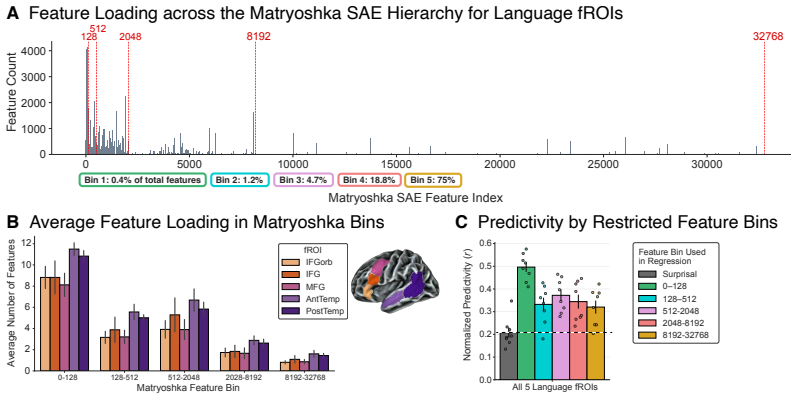
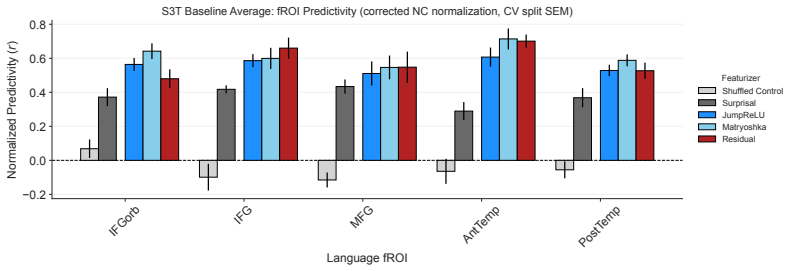
Augmented Sparse Encoding Models that substitute hierarchically-organized sparse autoencoder features from language models for dense hidden states, while including surprisal, recover prior voxel interpretations and identify a people-related population. The fronto-temporal human language network is predicted by a common set of these features across regions, with frontal areas relatively well explained by surprisal alone. Brain responses are best explained by the features that capture the most general information encoded in LM representations, indicating a nontrivial correspondence between brain and LM language representation.
What carries the argument
Augmented Sparse Encoding Models, which replace dense LM hidden states with hierarchically-organized sparse autoencoder features and add surprisal as an explicit predictor to distinguish primary from idiosyncratic variation in LM representations.
If this is right
- Voxel populations can be interpreted as tuned to processing difficulty, meaning abstractness, and people-related content.
- A common set of features predicts responses across the fronto-temporal language network.
- Frontal regions are relatively well explained by surprisal alone even without LM features.
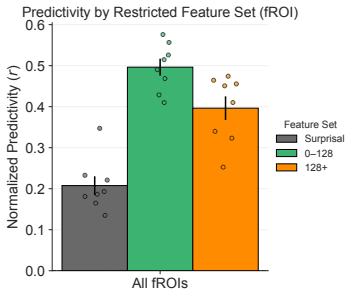
- Brain responses are not predictable from an arbitrary set of LM features but align with those capturing general information.
Where Pith is reading between the lines
- The method could extend to test whether the same general features predict responses across different language models or tasks.
- It raises the possibility that brains selectively represent shared linguistic structure while filtering model-specific details.
- Sparse features might enable more precise mapping of individual differences in language cortex by focusing on interpretable dimensions.
Load-bearing premise
The sparse autoencoder features extracted from one language model and training regime are stable enough to identify which features capture the most general information across language models.
What would settle it
Brain responses being predicted equally well or better by a random selection of sparse autoencoder features rather than the subset identified as capturing the most general LM information.
Figures
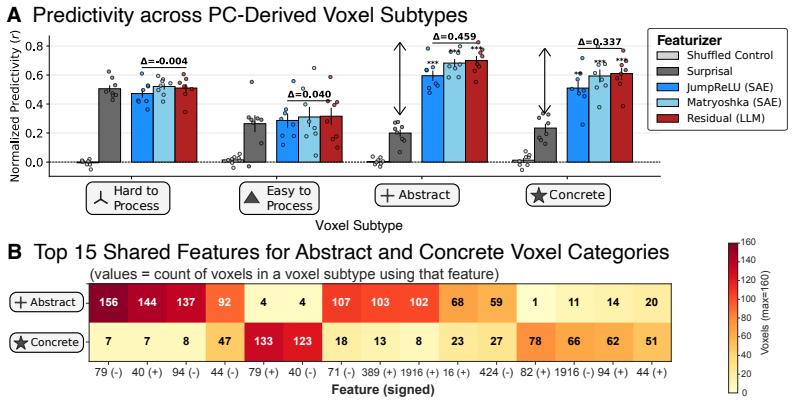
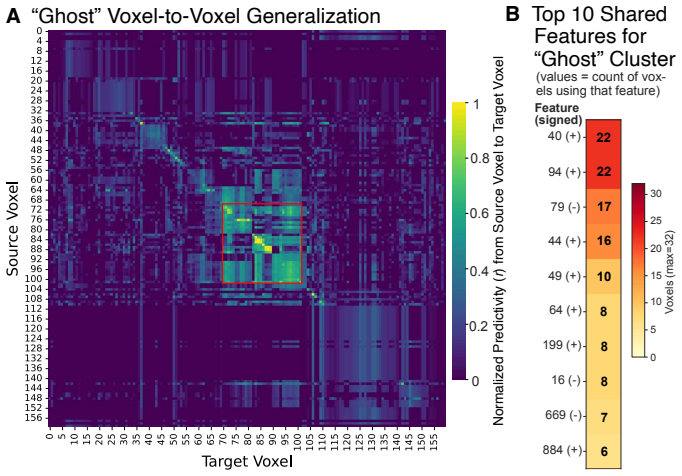
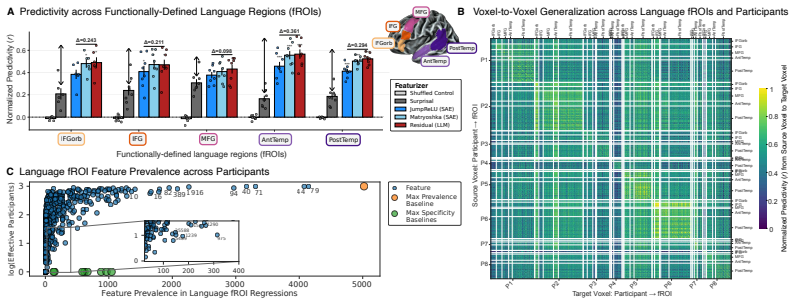

read the original abstract
A central goal of cognitive neuroscience is to characterize the features that are represented by human language cortex. Artificial language models (LMs) have emerged as a powerful tool to address this challenge, but studies relating biological and artificial representations are often criticized as relating one black box to another. The present work introduces Augmented Sparse Encoding Models, an encoding framework that replaces dense LM hidden states with hierarchically-organized sparse autoencoder (SAE) features, while explicitly including surprisal as a predictor. Using this approach, we (i) produce interpretations of neural responses and (ii) test whether model-brain alignment reflects primary or idiosyncratic variation in LM representations. Using a high-field 7T fMRI dataset of eight participants listening to 200 linguistically diverse sentences, we first validate our modeling framework by recovering previous interpretations of voxel populations tuned to processing difficulty and meaning abstractness. We then interpret a previously-uncharacterized (but reliable) voxel population and find that it is tuned to people-related content. Next, we show that the fronto-temporal human language network is predicted by a common set of features across its constituent regions, but find that frontal regions are relatively well-explained by surprisal alone, even in the absence of LM-based features. Finally, we show that brain responses during language processing are not merely predictable from an arbitrary set of LM features. Rather, brain responses are best explained by the features that tend to capture the most general information encoded in LM representations, suggesting a nontrivial correspondence between brain and LM language representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Augmented Sparse Encoding Models, which replace dense LM hidden states with hierarchically-organized sparse autoencoder (SAE) features while including surprisal as a predictor. On 7T fMRI data from eight participants listening to 200 sentences, the approach recovers prior voxel interpretations (processing difficulty, meaning abstractness), identifies a new reliable people-related population, shows that a common feature set predicts the fronto-temporal language network (with frontal regions relatively well-explained by surprisal alone), and reports that brain responses align best with SAE features capturing the most general LM information rather than arbitrary features.
Significance. If the central empirical claims hold after addressing the noted issues, the work offers a concrete method for moving beyond black-box LM-brain comparisons by linking neural responses to interpretable sparse features, while also quantifying the contribution of surprisal. The recovery of known populations plus the generality result would strengthen evidence for nontrivial correspondence between brain and LM representations.
major comments (3)
- [Abstract / Results] Abstract and final Results section: the claim that brain responses are best explained specifically by the 'most general' SAE features (rather than arbitrary ones) rests on ranking features within a single LM and training regime; the manuscript does not report training comparable SAEs on additional LMs, measuring feature overlap, or testing whether the general subset retains superior predictive power when the underlying LM changes, leaving the distinction between primary and idiosyncratic variation tied to one representation space.
- [Methods] Methods section: data exclusion criteria for participants or trials, voxel selection thresholds, and statistical controls for multiple comparisons when identifying the new people-related population are not described; without these, it is impossible to evaluate whether post-hoc selection or family-wise error issues affect the reliability of the recovered and novel interpretations.
- [Results] Results on encoding performance: the superiority of general over arbitrary features is presented as supporting a nontrivial correspondence, but the section does not report effect sizes, confidence intervals, or formal statistical tests comparing the two conditions, which are needed to establish that the difference is load-bearing rather than marginal.
minor comments (2)
- [Figure 2 / Methods] Figure legends and Methods: the number of SAE layers, dictionary size, and sparsity level are referenced but the exact hyperparameter values and sensitivity analyses are not tabulated, making it difficult to assess reproducibility of the hierarchical organization.
- [Introduction / Methods] Notation: the distinction between 'Augmented' encoding models and standard SAE encoding is introduced without an explicit equation contrasting the two predictor sets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate missing methodological details and improved statistical reporting. The first comment concerns scope rather than an error in the reported analysis.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and final Results section: the claim that brain responses are best explained specifically by the 'most general' SAE features (rather than arbitrary ones) rests on ranking features within a single LM and training regime; the manuscript does not report training comparable SAEs on additional LMs, measuring feature overlap, or testing whether the general subset retains superior predictive power when the underlying LM changes, leaving the distinction between primary and idiosyncratic variation tied to one representation space.
Authors: The analysis isolates the effect of feature generality versus arbitrariness inside the representation space of one standard LM. This directly tests whether alignment reflects primary rather than idiosyncratic variation within that space. Extending the comparison across multiple LMs would require substantial additional computation and is outside the present scope; we will add an explicit limitations paragraph noting this boundary. revision: partial
-
Referee: [Methods] Methods section: data exclusion criteria for participants or trials, voxel selection thresholds, and statistical controls for multiple comparisons when identifying the new people-related population are not described; without these, it is impossible to evaluate whether post-hoc selection or family-wise error issues affect the reliability of the recovered and novel interpretations.
Authors: We apologize for the omission from the main text. Participant and trial exclusion followed standard motion and outlier criteria (none excluded beyond these); voxels were selected at the top decile of cross-validated variance explained; multiple comparisons for the people-tuned population were controlled with FDR at q < 0.05. These details appear in the supplement; we will move them into the main Methods section. revision: yes
-
Referee: [Results] Results on encoding performance: the superiority of general over arbitrary features is presented as supporting a nontrivial correspondence, but the section does not report effect sizes, confidence intervals, or formal statistical tests comparing the two conditions, which are needed to establish that the difference is load-bearing rather than marginal.
Authors: We agree that effect-size and inferential statistics are required. The revised Results section will report Cohen’s d, participant-level 95 % confidence intervals, and paired t-test (or Wilcoxon) results comparing general-feature versus arbitrary-feature encoding performance across the eight participants. revision: yes
Circularity Check
Empirical encoding comparisons are independent of fitted brain parameters
full rationale
The paper's core results consist of empirical encoding performance comparisons between different SAE feature sets and surprisal on held-out fMRI data. These comparisons do not reduce by the paper's equations to quantities defined solely from parameters fitted to the same brain dataset. Feature generality is assessed from LM-internal properties prior to brain modeling, and validation against prior interpretations uses external benchmarks rather than self-referential definitions. No load-bearing step equates a claimed prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- SAE sparsity level and dictionary size
- Number of SAE layers and feature hierarchy
axioms (2)
- domain assumption Linear mapping from LM features plus surprisal to fMRI BOLD is sufficient to recover interpretable voxel tunings.
- domain assumption The 'most general' LM features can be identified by some selection criterion that is independent of the brain data.
Reference graph
Works this paper leans on
-
[1]
AlKhamissi, B., Tuckute, G., Tang, Y ., Binhuraib, T. O. A., Bosselut, A., and Schrimpf, M. From language to cognition: How llms outgrow the human language network. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 24332–24350,
2025
-
[2]
Antonello, R., Turek, J
URL https: //transformer-circuits.pub/2025/attribution-graphs/methods.html. Antonello, R., Turek, J. S., V o, V ., and Huth, A. Low-dimensional structure in the space of language representations is reflected in brain responses.Advances in neural information processing systems, 34:8332–8344,
2025
-
[3]
Antonello, R., Singh, C., Jain, S., Hsu, A., Guo, S., Gao, J., Yu, B., and Huth, A. Generative causal testing to bridge data-driven models and scientific theories in language neuroscience.arXiv preprint arXiv:2410.00812,
-
[4]
URL https://www.science.org/doi/10.1126/science. aav9436. Benara, V ., Singh, C., Morris, J. X., Antonello, R. J., Stoica, I., Huth, A. G., and Gao, J. Crafting interpretable embeddings for language neuroscience by asking llms questions.Advances in neural information processing systems, 37:124137,
-
[5]
Bussmann, B., Nabeshima, N., Karvonen, A., and Nanda, N
https://transformer-circuits.pub/2023/monosemantic- features/index.html. Bussmann, B., Nabeshima, N., Karvonen, A., and Nanda, N. Learning multi-level features with matryoshka sparse autoencoders. InForty-second International Conference on Machine Learning,
2023
-
[6]
G., Malik-Moraleda, S., Tuckute, G., and Fedorenko, E
13 de Varda, A. G., Malik-Moraleda, S., Tuckute, G., and Fedorenko, E. Multilingual computational models reveal shared brain responses to 21 languages.bioRxiv, pp. 2025–02,
2025
-
[7]
org/doi/prev/20100421-aop/pdf/10.1152/jn.00032.2010
URL https://journals.physiology. org/doi/prev/20100421-aop/pdf/10.1152/jn.00032.2010. Fedorenko, E., Blank, I. A., Siegelman, M., and Mineroff, Z. Lack of selectivity for syntax relative to word meanings throughout the language network.Cognition, 203:104348,
-
[8]
Guo, D., Wu, J., and Yiu, S. M. Sparse autoencoders map brain-llm alignment onto cortical semantic topography.arXiv preprint arXiv:2605.23035,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URL https: //www.biorxiv.org/content/10.1101/2024.12.26.629294v1.abstract. Hu, J., Small, H., Kean, H., Takahashi, A., Zekelman, L., Kleinman, D., Ryan, E., Nieto-Castañón, A., Ferreira, V ., and Fedorenko, E. Precision fmri reveals that the language-selective network supports both phrase-structure building and lexical access during language production.Ce...
-
[10]
Kleinman, T. W. and Goldstein, A. Back to the feature: Toward a feature-centric account of brain– lm alignment. InICLR 2026 Workshop on Representational Alignment (Re {\textasciicircum} 4-Align). Kumar, S., Sumers, T. R., Yamakoshi, T., Goldstein, A., Hasson, U., Norman, K. A., Griffiths, T. L., Hawkins, R. D., and Nastase, S. A. Shared functional special...
2026
-
[11]
Lamarre, M., Chen, C., and Deniz, F
URLhttps: //www.nature.com/articles/s41467-024-49173-5. Lamarre, M., Chen, C., and Deniz, F. Attention weights accurately predict language representations in the brain. InFindings of the Association for Computational Linguistics: EMNLP 2022, pp. 4513–4529,
2022
-
[12]
Luo, Y ., Zhan, Y ., Jiang, J., Liu, T., Wu, M., Zhou, Z., and Dong, B. From atoms to trees: Building a structured feature forest with hierarchical sparse autoencoders.arXiv preprint arXiv:2602.11881,
-
[13]
and Toneva, M
Merlin, G. and Toneva, M. Language models and brains align due to more than next-word prediction and word-level information. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 18431–18454. Association for Computational Linguistics,
2024
-
[14]
Miao, Z., Jung, H., Kragel, P
URLhttps://aclanthology.org/2024.emnlp-main.1024/. Miao, Z., Jung, H., Kragel, P. A., Bo, K., Sadil, P., Lindquist, M. A., and Wager, T. D. Common and distinct neural correlates of social interaction processing and theory of mind in narratives.Nature Communications,
2024
-
[15]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
URL https://elifesciences.org/articles/77599. Rajamanoharan, S., Lieberum, T., Sonnerat, N., Conmy, A., Varma, V ., Kramár, J., and Nanda, N. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Saxe, R., Brett, M., and Kanwisher, N
doi: 10.1016/S1053-8119(03) 00230-1. Saxe, R., Brett, M., and Kanwisher, N. Divide and conquer: a defense of functional localizers. Neuroimage, 30(4):1088–1096,
-
[17]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Language in brains, minds, and machines.An- nual Review of Neuroscience, 47, 2024a
Tuckute, G., Kanwisher, N., and Fedorenko, E. Language in brains, minds, and machines.An- nual Review of Neuroscience, 47, 2024a. URL https://www.annualreviews.org/content/ journals/10.1146/annurev-neuro-120623-101142?TRACK=RSS. Tuckute, G., Sathe, A., Srikant, S., Taliaferro, M., Wang, M., Schrimpf, M., Kay, K., and Fedorenko, E. Driving and suppressing ...
-
[19]
doi: https://doi.org/10.1101/2025.05.21. 65533. Wehbe, L., Blank, I. A., Shain, C., Futrell, R., Levy, R., von der Malsburg, T., Smith, N., Gibson, E., and Fedorenko, E. Incremental language comprehension difficulty predicts activity in the language network but not the multiple demand network.Cerebral Cortex, 31(9):4006–4023,
-
[20]
and Gallant, J
Zeng, A. and Gallant, J. Disentangling superpositions: Interpretable brain encoding model with sparse concept atoms.bioRxiv, pp. 2025–11,
2025
-
[21]
functional localizer
17 A Detailed Voxel Selection Procedure We selected voxels of interest in two main ways: one based on the two principal components (PCs) of sentence-evoked responses identified by Tuckute et al. (2025), and the other one based on whether a voxel is part of the fronto-temporal language network (Fedorenko et al., 2010). PC-derived subtypes (Hard-to-Process,...
2025
-
[22]
deduplicated
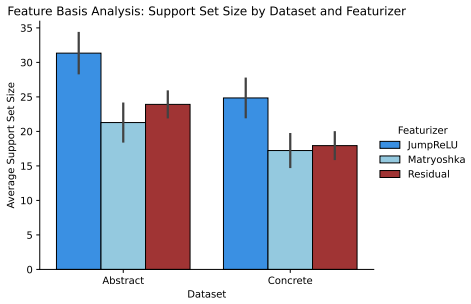
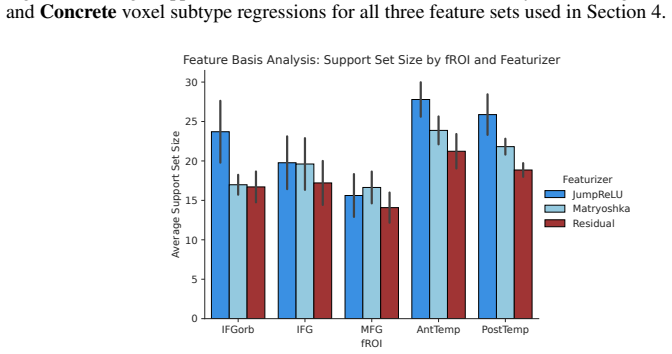
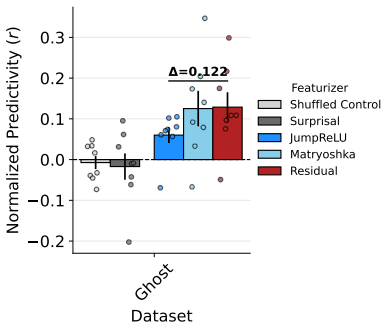
D Feature Set Support Size In Fig. 7, we present the average support size (i.e., number of features) resulting from LASSO- based feature selection using residual stream, JumpReLU, and Matryoshka feature sets forAbstract andConcretevoxel subtypes. When including processing difficulty voxel subtypes, the average Matryoshka support size is 18 features. In Fi...
2022
-
[23]
These features broadly reflect the interpretations of the PCs that have been identified in Tuckute et al. (2025). Features -79, -94, +389, and +40 are all concordant withAbstractvoxels, which are predominantly located in the language network. Features 44 and 71 are both driven more by sentences comprised of fewer tokens, and are thus suppressed by more co...
2025
-
[24]
N non-zero
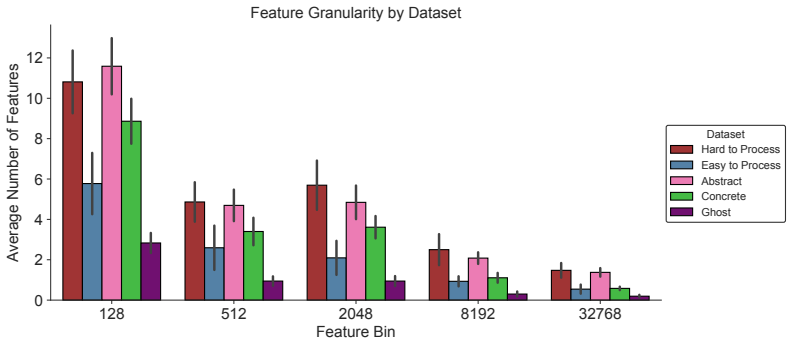
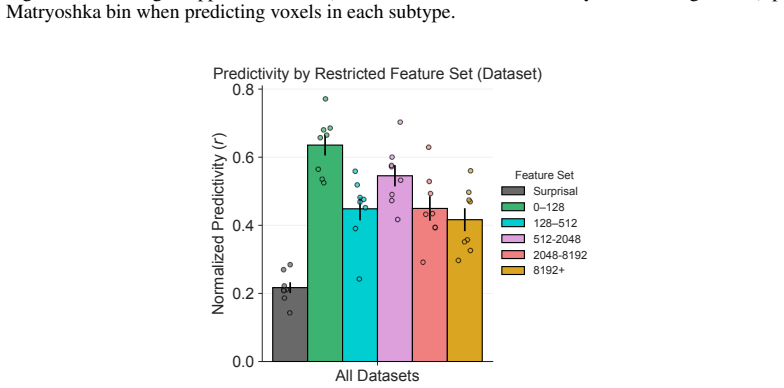
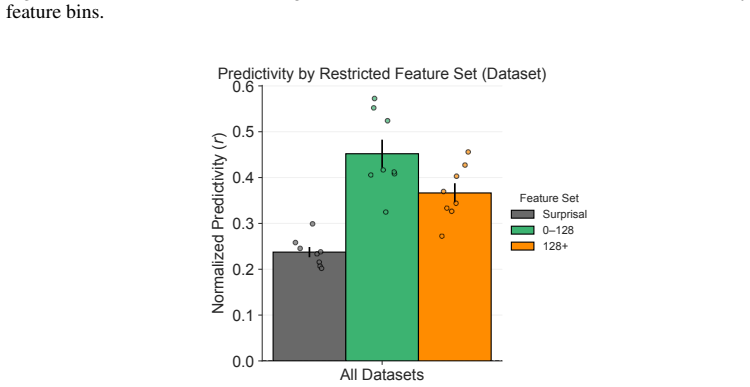
24 128 512 2048 8192 32768 Feature Bin 0 2 4 6 8 10 12Average Number of Features Feature Granularity by Dataset Dataset Hard to Process Easy to Process Abstract Concrete Ghost Figure 14: Average support set sizes (number of features selected by LASSO regression) per Matryoshka bin when predicting voxels in each subtype. All Datasets 0.0 0.2 0.4 0.6 0.8Nor...
2048
-
[25]
Max fires
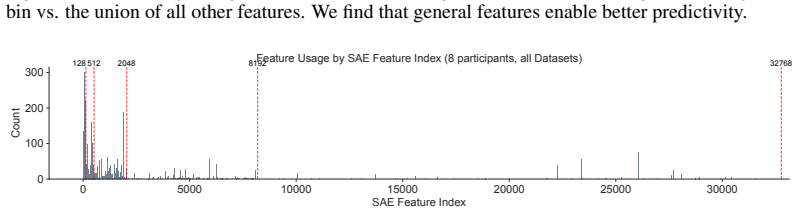
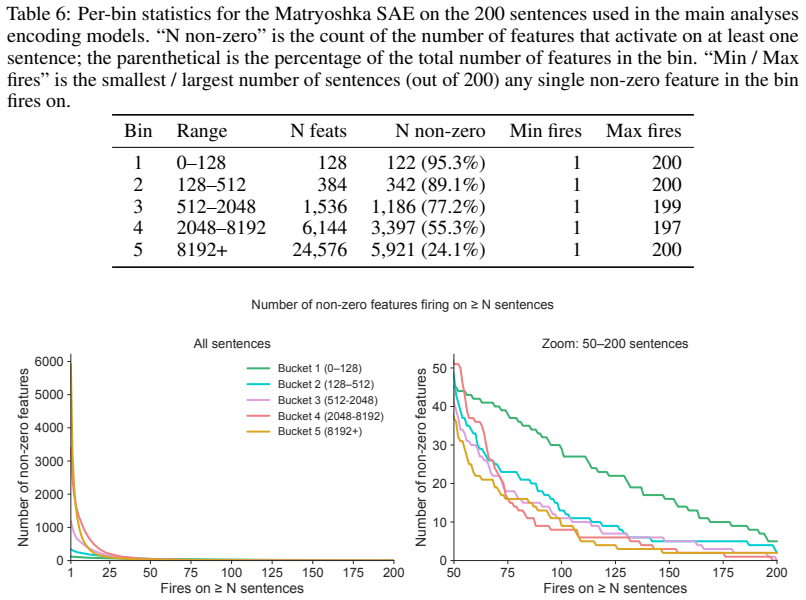
any single non-zero feature in the bin fires on. Bin Range N feats N non-zero Min fires Max fires 1 0–128 128 122 (95.3%) 1 200 2 128–512 384 342 (89.1%) 1 200 3 512–2048 1,536 1,186 (77.2%) 1 199 4 2048–8192 6,144 3,397 (55.3%) 1 197 5 8192+ 24,576 5,921 (24.1%) 1 200 1 25 50 75 100 125 150 175 200 Fires on ≥ N sentences 0 1000 2000 3000 4000 5000 6000Nu...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.