Personalised novel and explainable matrix factorisation
Pith reviewed 2026-05-24 16:01 UTC · model grok-4.3
The pith
NEMF extends matrix factorization to trade off accuracy for novelty and explainability with minimal loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their NEMF model, by augmenting the matrix factorization objective with novelty and a new nDCG-based explainability metric, enables trading off performance on novelty and explainability against accuracy, achieving high accuracy alongside novel and explainable recommendations.
What carries the argument
NEMF, the novel and explainable matrix factorization model that jointly optimizes accuracy, novelty, and an nDCG-based explainability metric.
If this is right
- Recommendation systems can produce novel items that advance user exploration.
- Explanations can be provided for recommendations based on the explainability metric.
- Accuracy is only minimally compromised when adding novelty and explainability objectives.
- The nDCG metric can distinguish more explainable items from less explainable ones.
Where Pith is reading between the lines
- This method could generalize to other collaborative filtering techniques.
- Domain-specific adaptations of the explainability metric might improve performance in different recommendation contexts.
- Future work could explore dynamic adjustment of the trade-off parameters based on user preferences.
Load-bearing premise
The nDCG-based explainability metric correctly measures and ranks items by their explainability to users independently of accuracy, allowing joint optimization in matrix factorization without biasing the learned factors.
What would settle it
An experiment or user study showing that items with high nDCG explainability scores are not perceived as more explainable by users, or that optimizing for novelty and explainability causes a large drop in accuracy metrics.
Figures


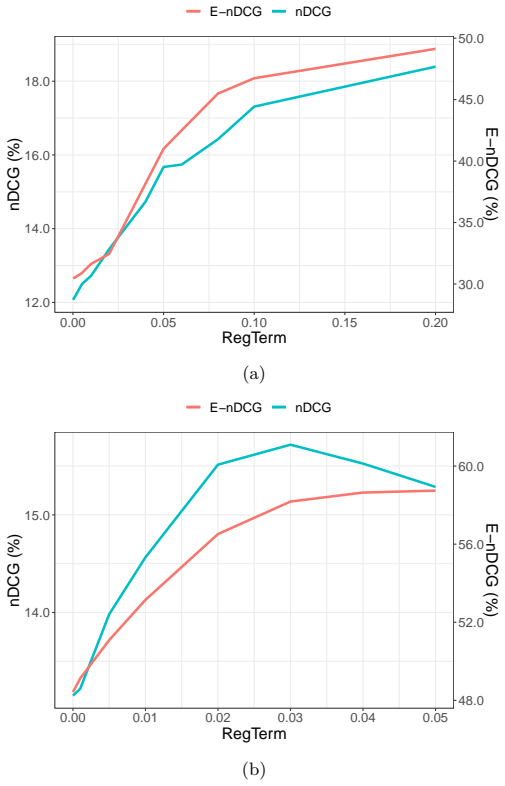
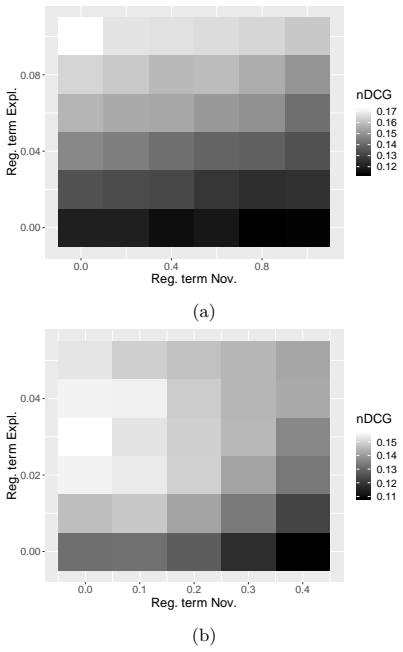
read the original abstract
Recommendation systems personalise suggestions to individuals to help them in their decision making and exploration tasks. In the ideal case, these recommendations, besides of being accurate, should also be novel and explainable. However, up to now most platforms fail to provide both, novel recommendations that advance users' exploration along with explanations to make their reasoning more transparent to them. For instance, a well-known recommendation algorithm, such as matrix factorisation (MF), optimises only the accuracy criterion, while disregarding other quality criteria such as the explainability or the novelty, of recommended items. In this paper, to the best of our knowledge, we propose a new model, denoted as NEMF, that allows to trade-off the MF performance with respect to the criteria of novelty and explainability, while only minimally compromising on accuracy. In addition, we recommend a new explainability metric based on nDCG, which distinguishes a more explainable item from a less explainable item. An initial user study indicates how users perceive the different attributes of these "user" style explanations and our extensive experimental results demonstrate that we attain high accuracy by recommending also novel and explainable items.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NEMF, a matrix factorization extension that jointly optimizes accuracy with novelty and a new nDCG-based explainability metric. It claims this enables trading off the three criteria such that novel and explainable items can be recommended while only minimally compromising accuracy, backed by experiments and an initial user study on explanation perception.
Significance. If the central claims hold after verification, the work would offer a concrete multi-objective MF formulation and a novel proxy metric for explainability, potentially useful for platforms seeking transparent and exploratory recommendations. The user study component provides direct evidence on user perception, which is a strength.
major comments (2)
- [Abstract and model definition] The nDCG-based explainability metric (introduced to distinguish more from less explainable items) is integrated into the NEMF objective alongside novelty; however, no quantitative check is described to confirm it ranks items independently of accuracy signals such as popularity or reconstruction error. If the metric correlates with these, the reported 'minimal compromise on accuracy' may be an artifact of the joint optimization rather than a controlled trade-off.
- [Abstract] The abstract asserts experimental results attaining high accuracy with novel/explainable items and an initial user study, but supplies no dataset details, baseline comparisons, error bars, or description of how the novelty-explainability trade-off weights are chosen or validated. This prevents assessment of whether the multi-objective fit avoids post-hoc selection bias.
minor comments (2)
- Notation for the trade-off parameters and the precise form of the NEMF loss function should be made explicit with equations to allow reproduction.
- The user study description would benefit from more detail on participant numbers, task design, and statistical analysis to strengthen the perception claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and model definition] The nDCG-based explainability metric (introduced to distinguish more from less explainable items) is integrated into the NEMF objective alongside novelty; however, no quantitative check is described to confirm it ranks items independently of accuracy signals such as popularity or reconstruction error. If the metric correlates with these, the reported 'minimal compromise on accuracy' may be an artifact of the joint optimization rather than a controlled trade-off.
Authors: We acknowledge that the manuscript does not include an explicit quantitative verification of the explainability metric's independence from accuracy signals. The metric is defined via nDCG on user-specific explanation lists derived from interaction history, which is conceptually distinct from global popularity or reconstruction error. To address the concern, we will add a correlation analysis (Spearman rank) between explainability scores, item popularity, and MF reconstruction errors in the revised version. revision: yes
-
Referee: [Abstract] The abstract asserts experimental results attaining high accuracy with novel/explainable items and an initial user study, but supplies no dataset details, baseline comparisons, error bars, or description of how the novelty-explainability trade-off weights are chosen or validated. This prevents assessment of whether the multi-objective fit avoids post-hoc selection bias.
Authors: The abstract is space-constrained and therefore omits these specifics, which are provided in the body: datasets in Section 4.1, baselines and comparisons in Sections 4.2 and 5, error bars (standard deviation over 5 runs) in all result figures, and weight selection via grid search on validation sets (detailed in Section 5.1) prior to test evaluation to avoid post-hoc bias. We will expand the abstract with a short clause on datasets and validation if permitted. revision: partial
Circularity Check
No circularity: derivation relies on external optimization and user study rather than self-definition
full rationale
The paper introduces NEMF as a multi-objective extension of matrix factorization and a new nDCG-based explainability metric. The central claim of trading off novelty/explainability against accuracy is presented as the outcome of joint optimization and experimental validation, not as a quantity defined in terms of itself. No equations reduce a reported prediction to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and the metric is motivated by a user study rather than renamed from prior results. The derivation chain therefore remains self-contained against the stated objectives.
Axiom & Free-Parameter Ledger
free parameters (1)
- novelty-explainability trade-off weights
axioms (2)
- domain assumption Matrix factorization objectives can be extended to include novelty and explainability terms while preserving the core low-rank approximation property.
- ad hoc to paper nDCG can serve as a valid proxy for item explainability that distinguishes more from less explainable items.
Reference graph
Works this paper leans on
-
[1]
B. Abdollahi and O. Nasraoui. Explainable matrix factorization for col- laborative filtering. In Proceedings of the 25th International Conference Companion on World Wide Web , WWW ’16 Companion, pages 5–6, 2016
work page 2016
-
[2]
B. Abdollahi and O. Nasraoui. Using explainability for constrained matrix factorization. In Proceedings of the Eleventh ACM Conference on Recom- mender Systems , RecSys ’17, pages 79–83, New York, NY, USA, 2017. ACM
work page 2017
-
[3]
M. Bilgic and R. Mooney. Explaining recommendations: Satisfaction vs. promotion. In Proccedings Recommender Systems Workshop (IUI Confer- ence), 2005
work page 2005
-
[4]
J. Carbonell and J. Goldstein. The use of MMR, diversity-based rerank- ing for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval - SIGIR 98 . ACM Press, 1998
work page 1998
-
[5]
P. Castells, N. J. Hurley, and S. Vargas. Novelty and diversity in recom- mender systems. In F. Ricci, L. Rokach, and B. Shapira, editors, Recom- mender Systems Handbook, 2nd edition , pages 881–918, 2015
work page 2015
-
[6]
C. Charles, M. Kolla, G. Cormack, O. Vechtomova, A. Ashkan, S. Buttcher, and I. MacKinnon. Novelty and diversity in information retrieval evalua- tion. In SIGIR Conference, SIGIR ’08, pages 659–666, 2008. 26
work page 2008
- [7]
-
[8]
P. Cremonesi, Y. Koren, and R. Turrin. Performance of recommender algorithms on top-n recommendation tasks. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys ’10, pages 39–46, New York, NY, USA, 2010. ACM
work page 2010
-
[9]
G. Friedrich and M. Zanker. A taxonomy for generating explanations in recommender systems. In AI Magazine. Citeseer, 2011
work page 2011
-
[10]
M. Ge, C. Delgado-Battenfeld, and D. Jannach. Beyond accuracy: Evalu- ating recommender systems by coverage and serendipity. In Proceedings of the Fourth ACM Conference on Recommender Systems , RecSys ’10, pages 257–260, New York, NY, USA, 2010. ACM
work page 2010
-
[11]
F. M. Harper and J. A. Konstan. The MovieLens Datasets. ACM Trans- actions on Interactive Intelligent Systems , 5(4):1–19, dec 2015
work page 2015
-
[12]
J. Herlocker, J. Konstan, and J. Riedl. Explaining collaborative filtering recommendations. In Computer Supported Cooperative Work , pages 241– 250, 2000
work page 2000
-
[13]
N. Hurley. Personalised ranking with diversity. In Proceedings of the Sev- enth ACM Conference on Recommender Systems , RecSys ’13, Hong Kong, China, 2013. ACM
work page 2013
-
[14]
D. Jannach, L. Lerche, I. Kamehkhosh, and M. Jugovac. What recom- menders recommend: An analysis of recommendation biases and possible countermeasures. User Modeling and User-Adapted Interaction, 25(5):427– 491, 2015
work page 2015
-
[15]
D. Jannach, P. Resnick, A. Tuzhilin, and M. Zanker. Recommender systems — beyond matrix completion. Commun. ACM, 59(11):94–102, Oct. 2016
work page 2016
-
[16]
M. Kaya and D. Bridge. Intent-aware diversification using item-based sub- profiles. In Proceedings of the Poster Track of the 11th ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, August 28, 2017. , 2017
work page 2017
- [17]
-
[18]
J. J. Louviere, T. N. Flynn, and R. T. Carson. Discrete choice experiments are not conjoint analysis. Journal of Choice Modelling , 3(3):57–72, 2010
work page 2010
-
[19]
M. Morup and L. H. Clemmensen. Multiplicative updates for the lasso. In Machine Learning for Signal Processing, 2007 IEEE Workshop on , pages 33–38. IEEE, 2007. 27
work page 2007
-
[20]
X. Ning and G. Karypis. Slim: Sparse linear methods for top-n recom- mender systems. In Data Mining (ICDM), 2011 IEEE 11th International Conference on, pages 497–506. IEEE, 2011
work page 2011
-
[21]
X. Ning and G. Karypis. Sparse linear methods with side information for top-n recommendations. In Proceedings of the sixth ACM conference on Recommender systems, pages 155–162. ACM, 2012
work page 2012
-
[22]
A. Papadimitriou, P. Symeonidis, and Y. Manolopoulos. A generalized taxonomy of explanations styles for traditional and social recommender systems. Data Mining and Knowledge Discovery , 24(3):555–583, 2012
work page 2012
-
[23]
S. Rendle, C. Freudenthaler, Z. Gantner, and S.-T. Lars. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty- Fifth Conference on Uncertainty in Artificial Intelligence , UAI ’09, pages 452–461, Arlington, Virginia, United States, 2009. AUAI Press
work page 2009
-
[24]
M. T. Ribeiro, S. Singh, and C. Guestrin. ”why should I trust you?”: Ex- plaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Min- ing, San Francisco, CA, USA, August 13-17, 2016 , pages 1135–1144, 2016
work page 2016
-
[25]
R. L. Santos, C. Macdonald, and I. Ounis. Exploiting query reformulations for web search result diversification. InProceedings of the 19th international conference on World wide web - WWW 10 . ACM Press, 2010
work page 2010
-
[26]
S. Vargas. New approaches to diversity and novelty in recommender sys- tems. In Fourth BCS-IRSG symposium on future directions in information access (FDIA 2011), Koblenz , volume 31, 2011
work page 2011
- [27]
-
[28]
S. Vargas and P. Castells. Rank and relevance in novelty and diversity metrics for recommender systems. In Proceedings of the Fifth ACM Con- ference on Recommender Systems , RecSys ’11, pages 109–116, New York, NY, USA, 2011. ACM
work page 2011
-
[29]
J. Wasilewski and N. Hurley. Incorporating diversity in a learning to rank recommender system. In Proceedings of the Twenty-Ninth International Flairs Conference, FLAIRS ’16, 2016
work page 2016
-
[30]
H. Yin, B. Cui, J. Li, J. Yao, and C. Chen. Challenging the long tail recommendation. Very Large Scale Data bases, 2012
work page 2012
-
[31]
Y. Zhen, W.-J. Li, and D.-Y. Yeung. Tagicofi: tag informed collaborative filtering. In Proceedings of the third ACM conference on Recommender systems, pages 69–76. ACM, 2009. 28
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.