FedUP: One-Shot Federated Unlearning via Centroid-Guided Plug-in Filters
Pith reviewed 2026-06-26 00:50 UTC · model grok-4.3
The pith
FedUP performs one-shot federated unlearning by training pluggable filters on DP-protected class centroids at the server.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
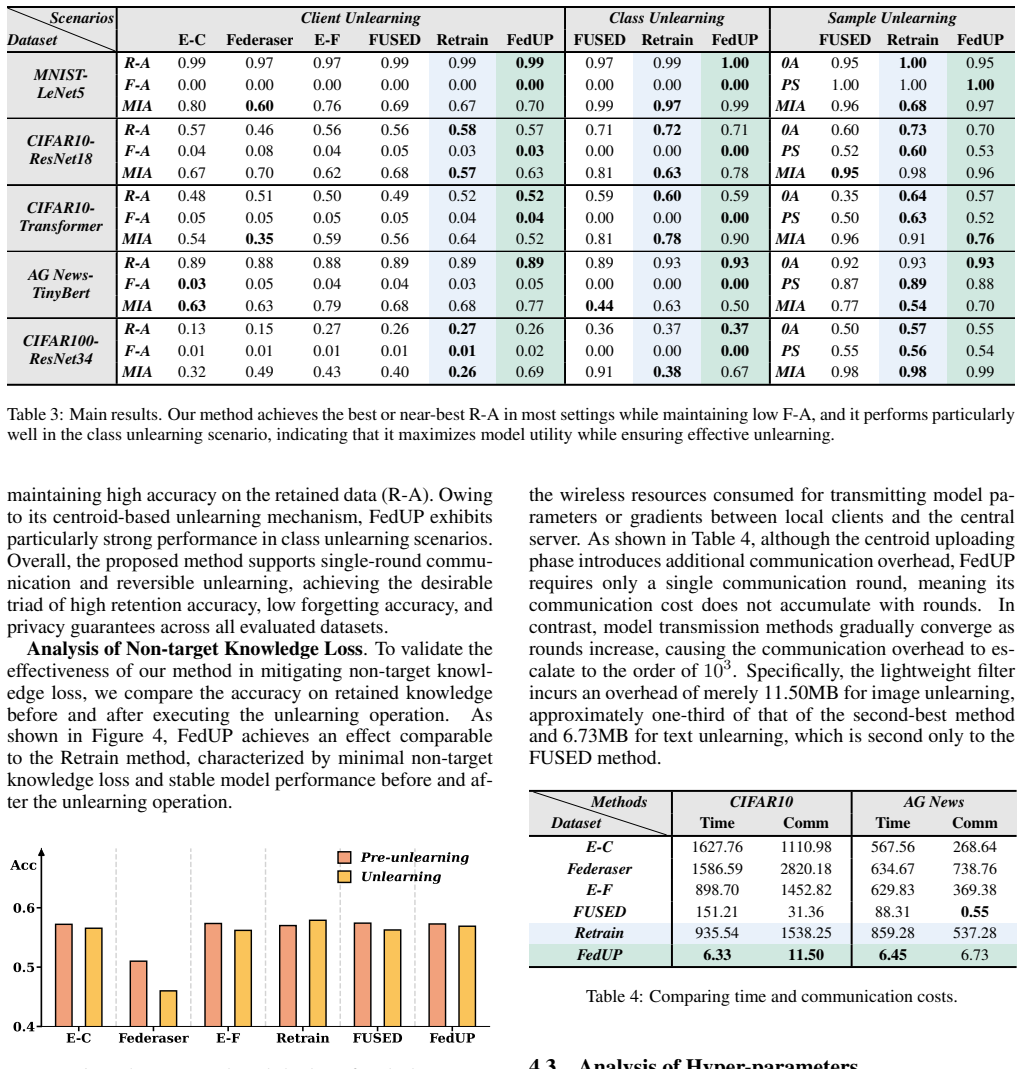
FedUP is a one-shot federated unlearning framework that utilizes lightweight pluggable filters trained at the server side on differentially private protected class centroid samples, freezing the original model parameters to screen out target data while preserving performance on non-target data, bypassing multi-round communication and complex retraining.
What carries the argument
Lightweight pluggable filters that act as a knowledge funnel, trained on DP-protected class centroid samples.
If this is right
- Reduces unlearning latency from minutes to seconds.
- Provides inherent reversibility by simply removing the filters to restore forgotten knowledge.
- Achieves superior unlearning precision and efficiency on image and text tasks.
- Minimizes non-target knowledge loss compared to existing methods.
Where Pith is reading between the lines
- The method could extend to other decentralized learning scenarios requiring data removal.
- Server-side filter training might reduce client-side computational burden in privacy-sensitive applications.
- Further tests could check if the centroid approach scales to very large models or datasets with many classes.
Load-bearing premise
That training lightweight pluggable filters on DP-protected class centroid samples is sufficient to screen out target data while preserving original model performance on non-target data.
What would settle it
Demonstrating that the pluggable filters do not sufficiently remove the influence of the target data from the model's outputs on held-out examples, or that they degrade performance on non-target data more than claimed.
Figures


read the original abstract
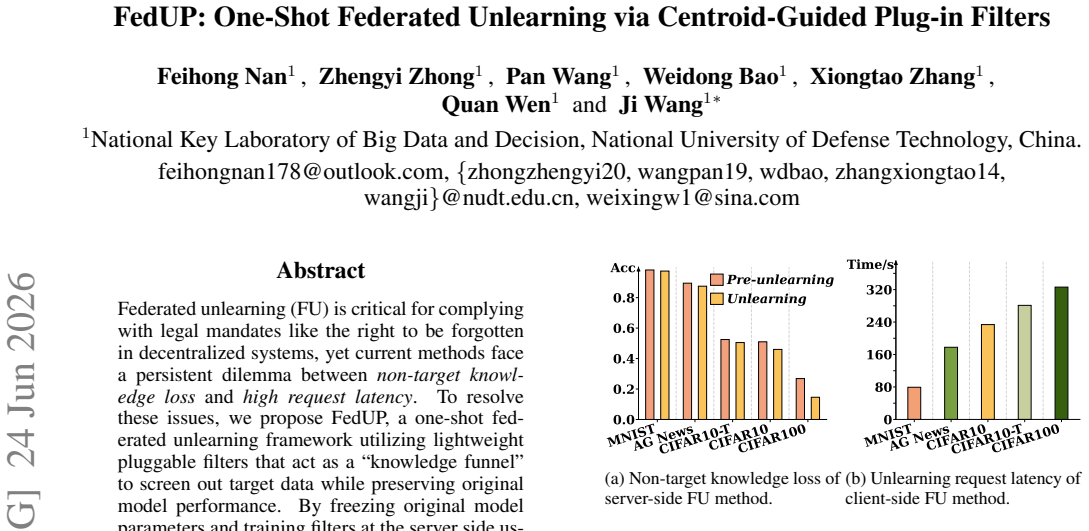
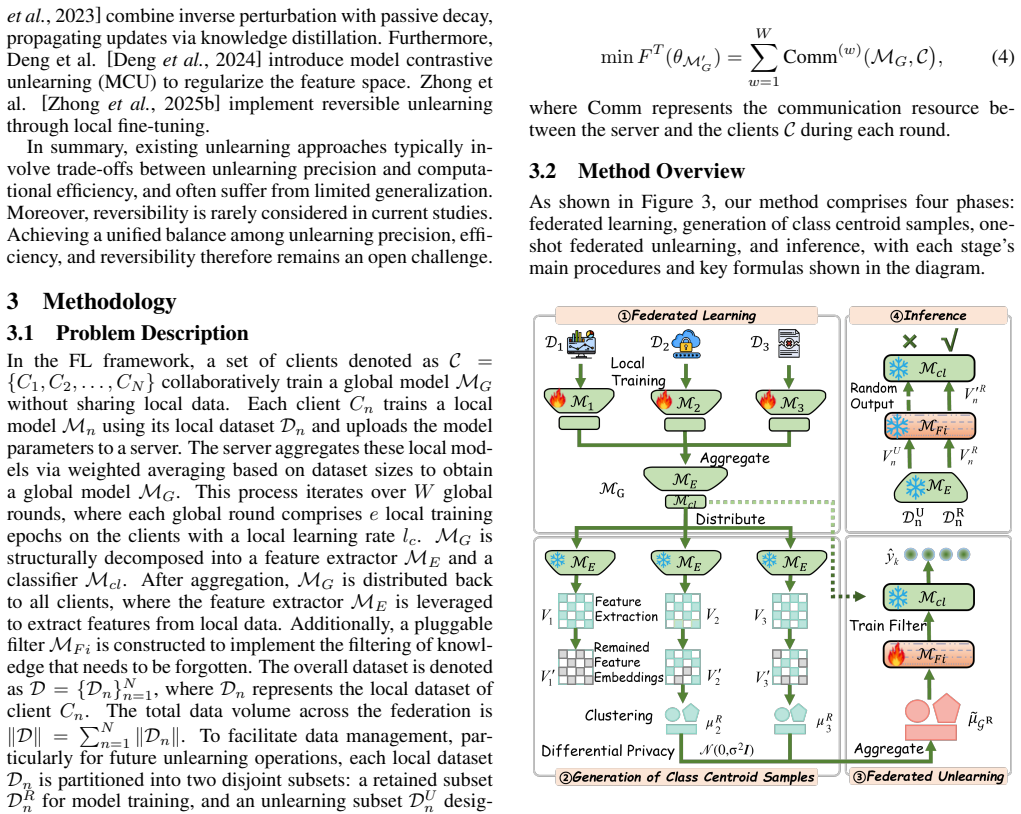
Federated unlearning (FU) is critical for complying with legal mandates like the right to be forgotten in decentralized systems, yet current methods face a persistent dilemma between non-target knowledge loss and high request latency. To resolve these issues, we propose FedUP, a one-shot federated unlearning framework utilizing lightweight pluggable filters that act as a "knowledge funnel" to screen out target data while preserving original model performance. By freezing original model parameters and training filters at the server side using differentially private (DP)-protected class centroid samples, FedUP bypasses the need for multi-round client-server communication and complex retraining, reducing unlearning latency from minutes to mere seconds. Additionally, the framework's pluggable architecture ensures inherent reversibility, enabling the seamless restoration of forgotten knowledge by simply removing the filters. Extensive experiments on diverse image and text tasks demonstrate that FedUP effectively reduces non-target knowledge loss and achieves superior unlearning precision and efficiency across various scenarios. Code is available at: https://github.com/suows/FedUP-code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedUP, a one-shot federated unlearning framework that freezes the original model parameters and trains lightweight pluggable filters at the server using differentially private class centroid samples. These filters act as a knowledge funnel to screen out the influence of target data, eliminating the need for multi-round client-server communication and complex retraining. The approach claims to reduce unlearning latency from minutes to seconds while preserving non-target performance, with inherent reversibility by removing the filters. Experiments on image and text tasks are reported to demonstrate reduced non-target knowledge loss and superior unlearning precision and efficiency.
Significance. If the central claim holds, FedUP would represent a meaningful advance in practical federated unlearning by achieving one-shot operation and reversibility with minimal communication overhead. The availability of reproducible code at https://github.com/suows/FedUP-code is a positive contribution that supports verification.
major comments (1)
- [Abstract and method description] The core technical assumption—that filters trained exclusively on DP-protected class centroid samples (first-moment statistics per class) are sufficient to isolate and remove the influence of specific target instances without collateral effects on non-target data sharing the same class labels—is not supported by any derivation or information-theoretic argument in the manuscript. This is load-bearing for the preservation guarantee and unlearning precision claims, as centroids discard higher-order moments and client-level heterogeneity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on the theoretical underpinnings of FedUP. We provide a point-by-point response below.
read point-by-point responses
-
Referee: [Abstract and method description] The core technical assumption—that filters trained exclusively on DP-protected class centroid samples (first-moment statistics per class) are sufficient to isolate and remove the influence of specific target instances without collateral effects on non-target data sharing the same class labels—is not supported by any derivation or information-theoretic argument in the manuscript. This is load-bearing for the preservation guarantee and unlearning precision claims, as centroids discard higher-order moments and client-level heterogeneity.
Authors: We acknowledge the validity of this observation. The manuscript does not include a formal derivation or information-theoretic analysis demonstrating that class centroids are sufficient to isolate target influence without affecting non-target data in the same class. Our approach is primarily empirical, relying on the training of filters on DP-protected centroids to approximate the removal of target knowledge while minimizing impact on shared class representations. To address this, we will revise the manuscript to include a new subsection discussing the assumptions underlying the centroid-based filtering, the implications of using first-moment statistics, and how client heterogeneity is mitigated through the server-side training process. We will also emphasize the empirical results showing reduced non-target knowledge loss compared to baselines. This revision will clarify the heuristic nature of the method without claiming theoretical guarantees. revision: partial
Circularity Check
No circularity: empirical method proposal with no self-referential derivations
full rationale
The paper presents FedUP as a practical one-shot unlearning framework that freezes the backbone and trains pluggable filters on DP-protected class centroids at the server. All claims rest on the architectural description and reported experiments rather than any mathematical derivation, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations appear that reduce a claimed result to its own inputs by construction, and the method is offered as an engineering solution validated empirically on image and text tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine unlearning
[Bourtouleet al., 2021 ] Lucas Bourtoule, Varun Chan- drasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE,
2021
-
[2]
Efficient repair of polluted machine learning systems via causal unlearning
[Caoet al., 2018 ] Yinzhi Cao, Alexander Fangxiao Yu, An- drew Aday, Eric Stahl, Jon Merwine, and Junfeng Yang. Efficient repair of polluted machine learning systems via causal unlearning. InASIACCS ’18: Proceedings of the 2018 on Asia Conference on Computer and Communica- tions Security,
2018
-
[3]
Graph unlearning
[Chenet al., 2022 ] Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. Graph unlearning. InProceedings of the 2022 ACM SIGSAC conference on computer and communica- tions security, pages 499–513,
2022
-
[4]
A guide to the califor- nia consumer privacy act of 2018.SSRN Electronic Jour- nal, Dec
[de la Torre, 2018] Lydia de la Torre. A guide to the califor- nia consumer privacy act of 2018.SSRN Electronic Jour- nal, Dec
2018
-
[5]
Enable the right to be forgotten with federated client unlearning in medical imaging
[Denget al., 2024 ] Zhipeng Deng, Luyang Luo, and Hao Chen. Enable the right to be forgotten with federated client unlearning in medical imaging. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 240–250. Springer,
2024
-
[6]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
[Golatkaret al., 2020 ] Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312,
2020
-
[7]
Amnesiac machine learning
[Graveset al., 2021 ] Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amnesiac machine learning. InProceed- ings of the AAAI Conference on Artificial Intelligence, vol- ume 35, pages 11516–11524,
2021
-
[8]
Certified data re- moval from machine learning models.arXiv preprint arXiv:1911.03030,
[Guoet al., 2019 ] Chuan Guo, Tom Goldstein, Awni Han- nun, and Laurens Van Der Maaten. Certified data re- moval from machine learning models.arXiv preprint arXiv:1911.03030,
-
[9]
Adaptive machine unlearning.Advances in Neural Information Processing Systems, 34:16319–16330,
[Guptaet al., 2021 ] Varun Gupta, Christopher Jung, Seth Neel, Aaron Roth, Saeed Sharifi-Malvajerdi, and Chris Waites. Adaptive machine unlearning.Advances in Neural Information Processing Systems, 34:16319–16330,
2021
-
[10]
Federated unlearning: How to efficiently erase a client in fl? Jul
[Halimiet al., 2022 ] Anisa Halimi, Swanand Kadhe, Ambr- ish Rawat, and Nathalie Baracaldo. Federated unlearning: How to efficiently erase a client in fl? Jul
2022
-
[11]
Deep residual learning for image recog- nition
[Heet al., 2016 ] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778,
2016
-
[12]
Certified unlearning for federated recommendation.ACM Transactions on Information Systems, 43(2):1–29,
[Huynhet al., 2025 ] Thanh Trung Huynh, Trong Bang Nguyen, Thanh Toan Nguyen, Phi Le Nguyen, Hongzhi Yin, Quoc Viet Hung Nguyen, and Thanh Tam Nguyen. Certified unlearning for federated recommendation.ACM Transactions on Information Systems, 43(2):1–29,
2025
-
[13]
Unveiling and mitigating untargeted poisoning attacks on federated knowledge graph embedding
[Jianget al., 2026 ] Wenzheng Jiang, Ke Liang, Wenke Huang, Xiongtao Zhang, Zhenxing Xu, Guancheng Wan, Cheston Tan, Flint Xiaofeng Fan, and Ji Wang. Unveiling and mitigating untargeted poisoning attacks on federated knowledge graph embedding. InProceedings of the ACM Web Conference 2026, pages 2569–2580,
2026
-
[14]
Tinybert: Distilling bert for natural language under- standing
[Jiaoet al., 2020 ] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language under- standing. InFindings of the association for computational linguistics: EMNLP 2020, pages 4163–4174,
2020
-
[15]
Learning multiple layers of features from tiny im- ages
[Krizhevskyet al., 2009 ] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny im- ages
2009
-
[16]
Exact un- learning of finetuning data via model merging at scale
[Kuoet al., 2025 ] Kevin Kuo, Amrith Setlur, Kartik Srini- vas, Aditi Raghunathan, and Virginia Smith. Exact un- learning of finetuning data via model merging at scale. arXiv preprint arXiv:2504.04626,
-
[17]
Towards un- bounded machine unlearning.Advances in neural infor- mation processing systems, 36:1957–1987,
[Kurmanjiet al., 2023 ] Meghdad Kurmanji, Peter Triantafil- lou, Jamie Hayes, and Eleni Triantafillou. Towards un- bounded machine unlearning.Advances in neural infor- mation processing systems, 36:1957–1987,
2023
-
[18]
Gradient-based learning ap- plied to document recognition.Proceedings of the IEEE, 86(11):2278–2324,
[LeCunet al., 2002 ] Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning ap- plied to document recognition.Proceedings of the IEEE, 86(11):2278–2324,
2002
-
[19]
Federated learning on non-iid data silos: An experimental study
[Liet al., 2022 ] Qinbin Li, Yiqun Diao, Quan Chen, and Bingsheng He. Federated learning on non-iid data silos: An experimental study. In2022 IEEE 38th international conference on data engineering (ICDE), pages 965–978. IEEE,
2022
-
[20]
Machine unlearning: Taxonomy, metrics, applications, challenges, and prospects.IEEE Transactions on Neural Networks and Learning Systems,
[Liet al., 2025 ] Na Li, Chunyi Zhou, Yansong Gao, Hui Chen, Zhi Zhang, Boyu Kuang, and Anmin Fu. Machine unlearning: Taxonomy, metrics, applications, challenges, and prospects.IEEE Transactions on Neural Networks and Learning Systems,
2025
-
[21]
Federaser: Enabling ef- ficient client-level data removal from federated learning models
[Liuet al., 2021 ] Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. Federaser: Enabling ef- ficient client-level data removal from federated learning models. In2021 IEEE/ACM 29th International Sympo- sium on Quality of Service (IWQOS), pages 1–10. IEEE,
2021
-
[22]
The right to be forgotten in federated learning: An efficient realization with rapid retraining
[Liuet al., 2022 ] Yi Liu, Lei Xu, Xingliang Yuan, Cong Wang, and Bo Li. The right to be forgotten in federated learning: An efficient realization with rapid retraining. InIEEE INFOCOM 2022-IEEE conference on computer communications, pages 1749–1758. IEEE,
2022
-
[23]
A survey on federated unlearning: Challenges, methods, and future directions.ACM Computing Surveys, 57(1):1– 38,
[Liuet al., 2024 ] Ziyao Liu, Yu Jiang, Jiyuan Shen, Minyi Peng, Kwok-Yan Lam, Xingliang Yuan, and Xiaoning Liu. A survey on federated unlearning: Challenges, methods, and future directions.ACM Computing Surveys, 57(1):1– 38,
2024
-
[24]
Learn to forget: Machine un- learning via neuron masking.IEEE Transactions on De- pendable and Secure Computing, 20(4):3194–3207,
[Maet al., 2022 ] Zhuo Ma, Yang Liu, Ximeng Liu, Jian Liu, Jianfeng Ma, and Kui Ren. Learn to forget: Machine un- learning via neuron masking.IEEE Transactions on De- pendable and Secure Computing, 20(4):3194–3207,
2022
-
[25]
Communication-efficient learn- ing of deep networks from decentralized data.arXiv: Learning,arXiv: Learning, Feb
[McMahanet al., 2016 ] H.Brendan McMahan, Ei- derB Moore, Daniel Ramage, Seth Hampson, and BlaiseAg¨ueray Arcas. Communication-efficient learn- ing of deep networks from decentralized data.arXiv: Learning,arXiv: Learning, Feb
2016
-
[26]
Fedunran: On-device federated unlearning via random labels
[Moraet al., 2024 ] Alessio Mora, Luca Dominici, and Paolo Bellavista. Fedunran: On-device federated unlearning via random labels. In2024 IEEE International Conference on Big Data (BigData), pages 7955–7960. IEEE,
2024
-
[27]
A survey of machine unlearning.ACM Transactions on Intelligent Sys- tems and Technology, 16(5):1–46,
[Nguyenet al., 2025 ] Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning.ACM Transactions on Intelligent Sys- tems and Technology, 16(5):1–46,
2025
-
[28]
Federated unlearning with gradient descent and conflict mitigation
[Panet al., 2025 ] Zibin Pan, Zhichao Wang, Chi Li, Kaiyan Zheng, Boqi Wang, Xiaoying Tang, and Junhua Zhao. Federated unlearning with gradient descent and conflict mitigation. InProceedings of the AAAI Conference on Ar- tificial Intelligence, volume 39, pages 19804–19812,
2025
-
[29]
Cross-silo prototypical cal- ibration for federated learning with non-iid data
[Qiet al., 2023 ] Zhuang Qi, Lei Meng, Zitan Chen, Han Hu, Hui Lin, and Xiangxu Meng. Cross-silo prototypical cal- ibration for federated learning with non-iid data. InPro- ceedings of the 31st ACM international conference on mul- timedia, pages 3099–3107,
2023
-
[30]
Cross- training with multi-view knowledge fusion for heteroge- nous federated learning.arXiv e-prints, pages arXiv–2405,
[Qiet al., 2024 ] Zhuang Qi, Lei Meng, Weihao He, Ruohan Zhang, Yu Wang, Xin Qi, and Xiangxu Meng. Cross- training with multi-view knowledge fusion for heteroge- nous federated learning.arXiv e-prints, pages arXiv–2405,
2024
-
[31]
Privacy preservation in federated learning: An insightful survey from the gdpr per- spective.Computers & Security, 110:102402,
[Truonget al., 2021 ] Nguyen Truong, Kai Sun, Siyao Wang, Florian Guitton, and YiKe Guo. Privacy preservation in federated learning: An insightful survey from the gdpr per- spective.Computers & Security, 110:102402,
2021
-
[32]
Attention is all you need.Advances in neural information processing systems, 30,
[Vaswaniet al., 2017 ] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30,
2017
-
[33]
Federated unlearning via class-discriminative pruning
[Wanget al., 2022 ] Junxiao Wang, Song Guo, Xin Xie, and Heng Qi. Federated unlearning via class-discriminative pruning. InProceedings of the ACM web conference 2022, pages 622–632,
2022
-
[34]
Bfu: Bayesian federated unlearning with parameter self-sharing
[Wanget al., 2023b ] Weiqi Wang, Zhiyi Tian, Chenhan Zhang, An Liu, and Shui Yu. Bfu: Bayesian federated unlearning with parameter self-sharing. InProceedings of the 2023 ACM Asia Conference on Computer and Com- munications Security, pages 567–578,
2023
-
[35]
Federated learning with dif- ferential privacy: Algorithms and performance analysis
[Weiet al., 2020 ] Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. Federated learning with dif- ferential privacy: Algorithms and performance analysis. IEEE transactions on information forensics and security, 15:3454–3469,
2020
-
[36]
Federated unlearning with knowledge distillation
[Wuet al., 2022 ] Chen Wu, Sencun Zhu, and Prasenjit Mi- tra. Federated unlearning with knowledge distillation. arXiv preprint arXiv:2201.09441,
-
[37]
Exact-fun: an exact and efficient federated unlearning approach
[Xionget al., 2023 ] Zuobin Xiong, Wei Li, Yingshu Li, and Zhipeng Cai. Exact-fun: an exact and efficient federated unlearning approach. In2023 IEEE International Confer- ence on Data Mining (ICDM), pages 1439–1444. IEEE,
2023
-
[38]
Erase then rectify: A training- free parameter editing approach for cost-effective graph unlearning
[Yanget al., 2025 ] Zhe-Rui Yang, Jindong Han, Chang- Dong Wang, and Hao Liu. Erase then rectify: A training- free parameter editing approach for cost-effective graph unlearning. InProceedings of the AAAI Conference on Ar- tificial Intelligence, volume 39, pages 13044–13051,
2025
-
[39]
Character-level convolutional networks for text classification.Advances in neural information processing systems, 28,
[Zhanget al., 2015 ] Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28,
2015
-
[40]
[Zhonget al., 2022 ] Zhengyi Zhong, Weidong Bao, Ji Wang, Xiaomin Zhu, and Xiongtao Zhang. Flee: A hierarchical federated learning framework for distributed deep neural network over cloud, edge, and end device.ACM Trans- actions on Intelligent Systems and Technology (TIST), 13(5):1–24,
2022
-
[41]
Heterogeneous federated knowledge graph embed- ding learning and unlearning
[Zhuet al., 2023 ] Xiangrong Zhu, Guangyao Li, and Wei Hu. Heterogeneous federated knowledge graph embed- ding learning and unlearning. InProceedings of the ACM web conference 2023, pages 2444–2454, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.