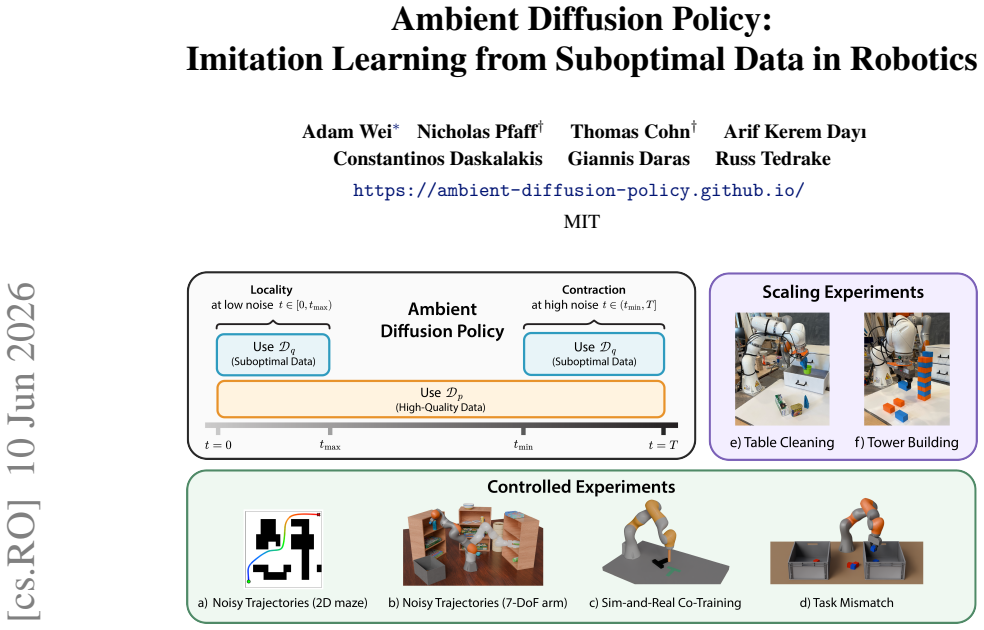
Ambient Diffusion Policy: Imitation Learning from Suboptimal Data in Robotics
Pith reviewed 2026-06-27 09:51 UTC · model grok-4.3
The pith
Ambient Diffusion Policy learns robot behaviors from suboptimal data by restricting its contribution to only high and low diffusion times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
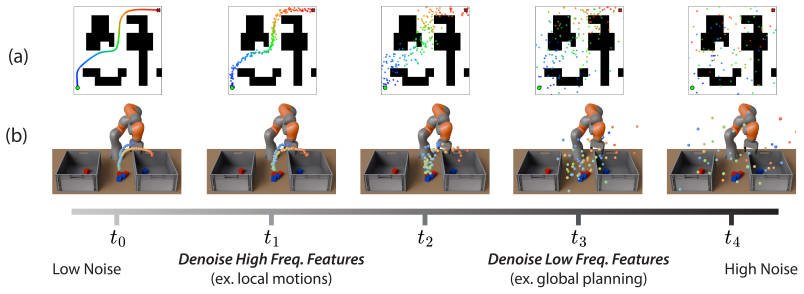
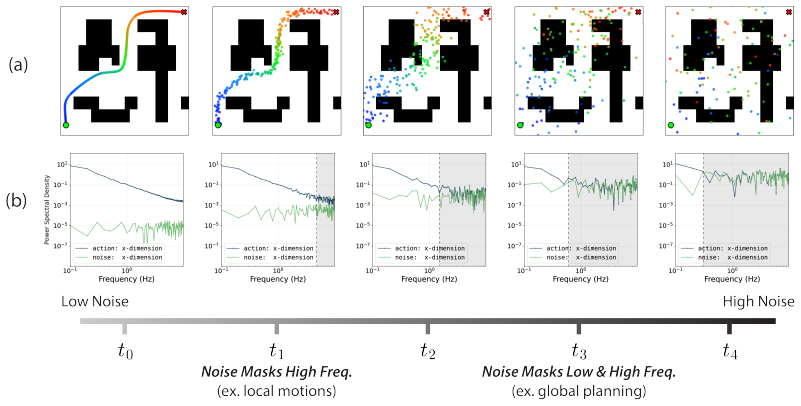
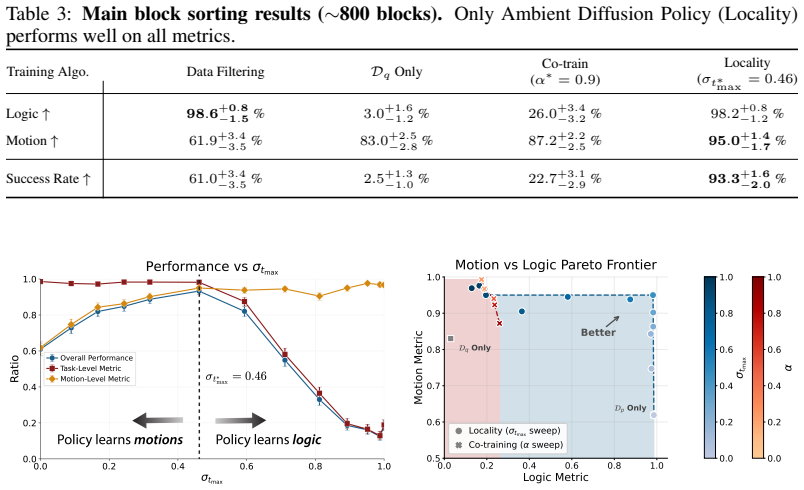
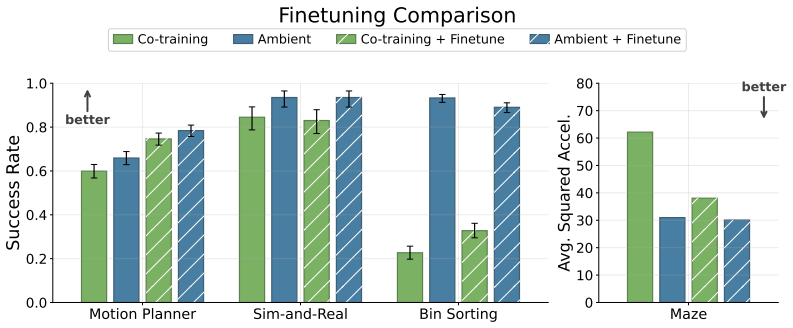
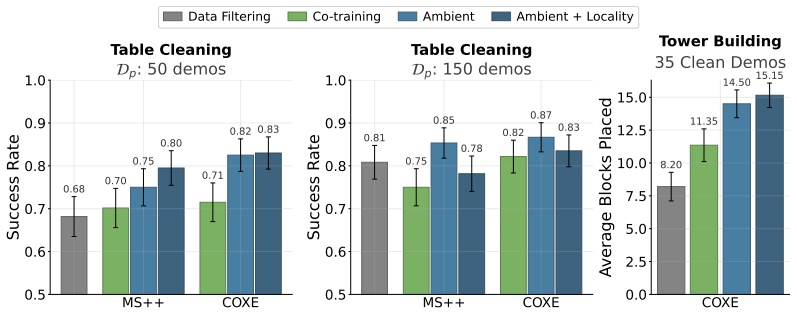
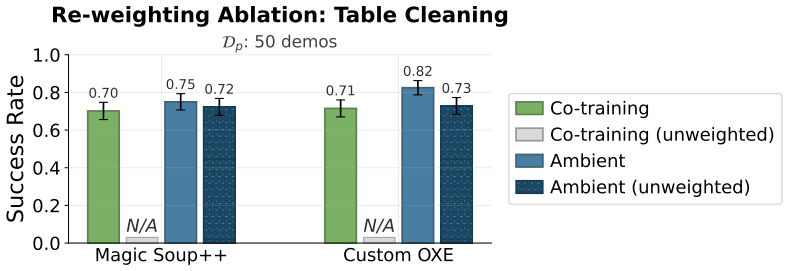
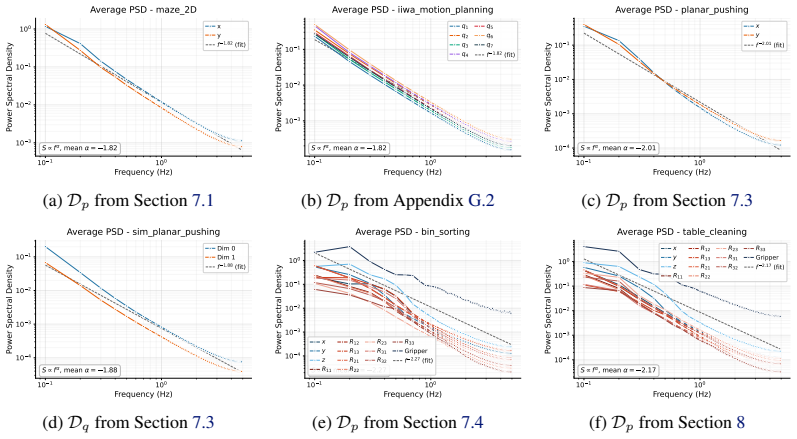
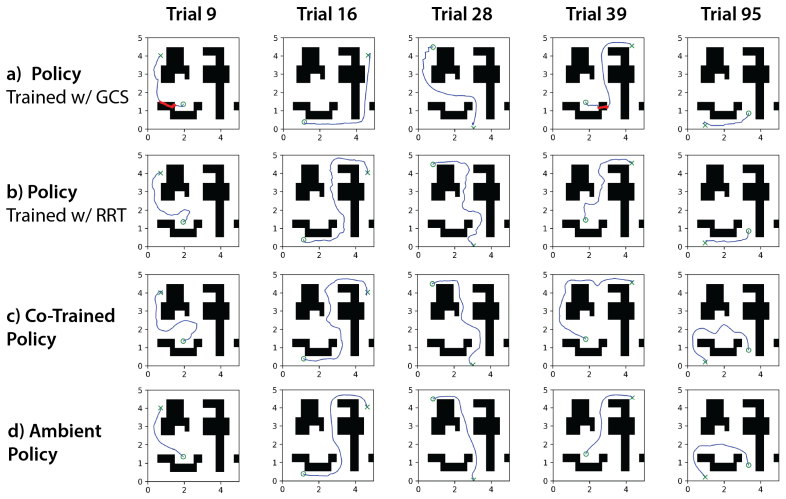
Ambient Diffusion Policy restricts the contribution of suboptimal data during training to only the high and low diffusion times. This restriction is justified by first observing that robot action data exhibits a spectral power law, which induces a global-to-local hierarchy and locality on the optimal Diffusion Policy. The method is shown to extract only useful features from arbitrary suboptimal sources including noisy trajectories, sim-to-real gaps, task mismatches, and large-scale mixtures, outperforming co-training baselines.
What carries the argument
Ambient Diffusion Policy, which adds noise-dependent data usage by restricting suboptimal data to high and low diffusion times to exploit the global-to-local hierarchy and locality induced by the spectral power law in robot action data.
If this is right
- The method works across noisy trajectories, sim-to-real gaps, task mismatches, and heterogeneous mixtures.
- It outperforms existing co-training baselines by up to 33 percent when scaled to large datasets like Open X-Embodiment.
- It increases the utility of suboptimal demonstrations without requiring manual separation of features.
- It expands the range of data sources that can be used for imitation learning in robotics.
Where Pith is reading between the lines
- The same noise-dependent restriction might transfer to diffusion models outside robotics, such as those for planning or generation tasks.
- The spectral power law observation could motivate similar time-based data weighting in other sequential models.
- Data collection pipelines might incorporate automatic checks for spectral properties to decide which demonstrations to include at which noise levels.
Load-bearing premise
Robot action data exhibits a spectral power law that creates a global-to-local hierarchy and locality allowing useful features from suboptimal data to be isolated at high and low diffusion times without loss.
What would settle it
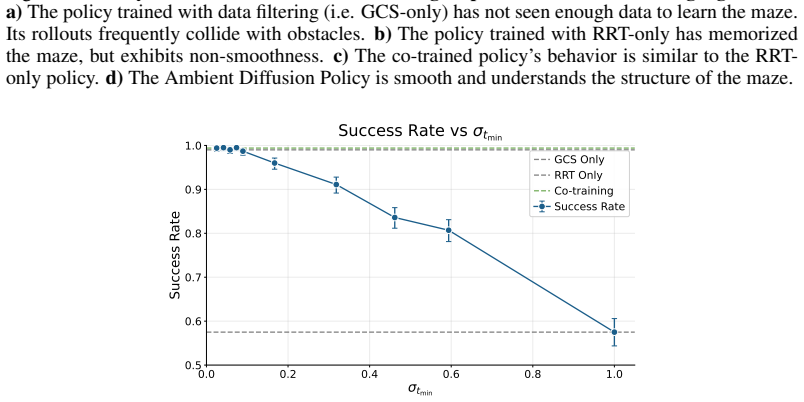
Measure whether performance improves, stays the same, or degrades when suboptimal data is allowed at medium diffusion times instead of being restricted; the claim requires that medium times add net harm.
Figures



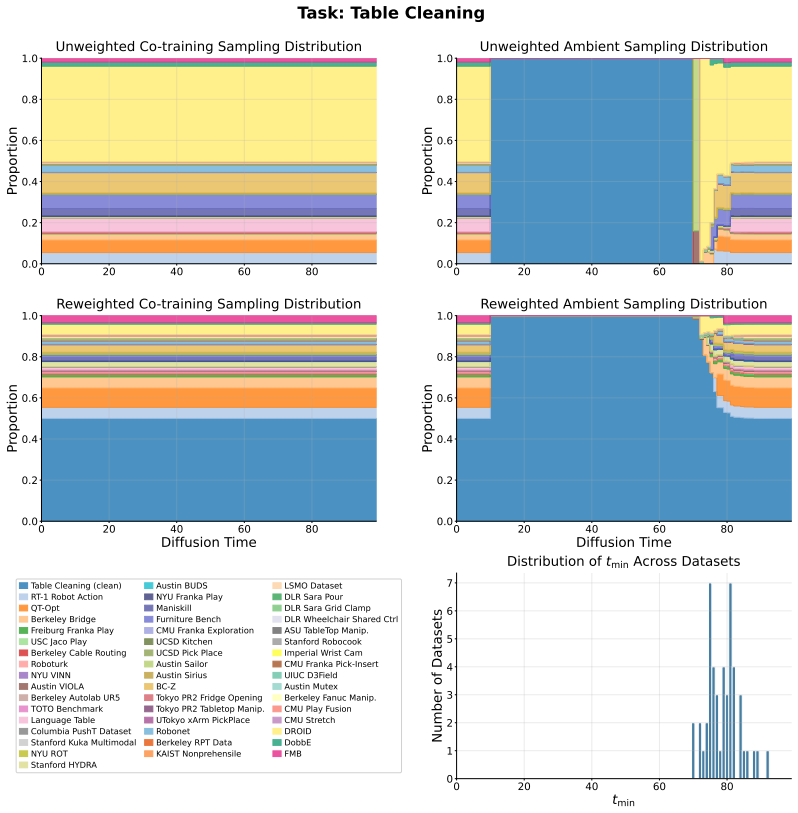
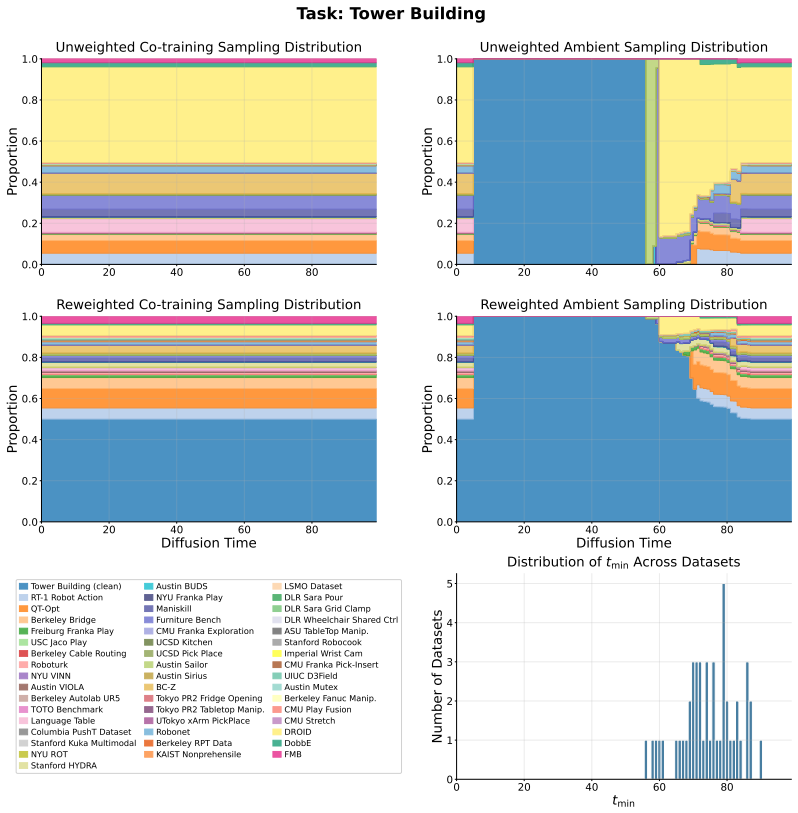
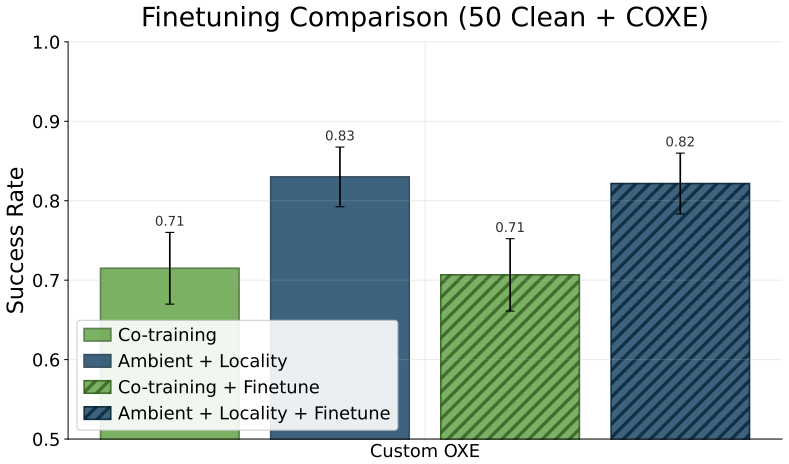
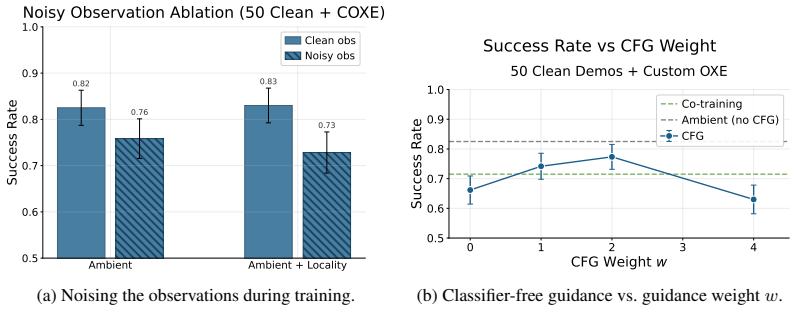
read the original abstract
We propose Ambient Diffusion Policy, a simple and principled method for imitation learning from suboptimal data in robotics. High-quality, task-specific robot data is expensive and time-consuming to collect, while suboptimal datasets with lower-quality or out-of-distribution demonstrations are abundant. Existing methods that co-train on both data sources in robotics often fail to separate the meaningful and the harmful features in the suboptimal samples. In contrast, our method extracts only the useful features by introducing a new axis to co-training in robotics: noise-dependent data usage. Ambient Diffusion Policy restricts the contribution of suboptimal data during training to only the high and low diffusion times. To rigorously justify our approach, we first observe that robot action data exhibits a spectral power law. This induces two important properties on the optimal Diffusion Policy that we exploit: a global-to-local hierarchy and locality. We theoretically formalize this discussion using a simplified model. Our experiments validate Ambient Diffusion Policy on four types of suboptimal action data (noisy trajectories, sim-to-real gap, task mismatch, and large-scale data mixtures) across six tasks. The results show that it effectively learns from arbitrary sources of suboptimal data. Notably, it outperforms existing co-training baselines by up to 33% when scaled to Open X-Embodiment - a large dataset with heterogeneous data quality and unstructured distribution shifts. Overall, Ambient Diffusion Policy increases the utility of suboptimal demonstrations and expands the set of usable data sources in robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
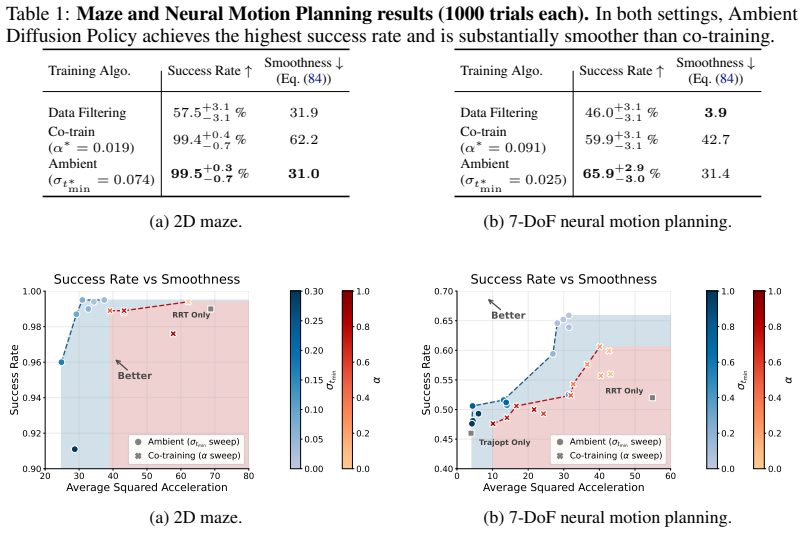
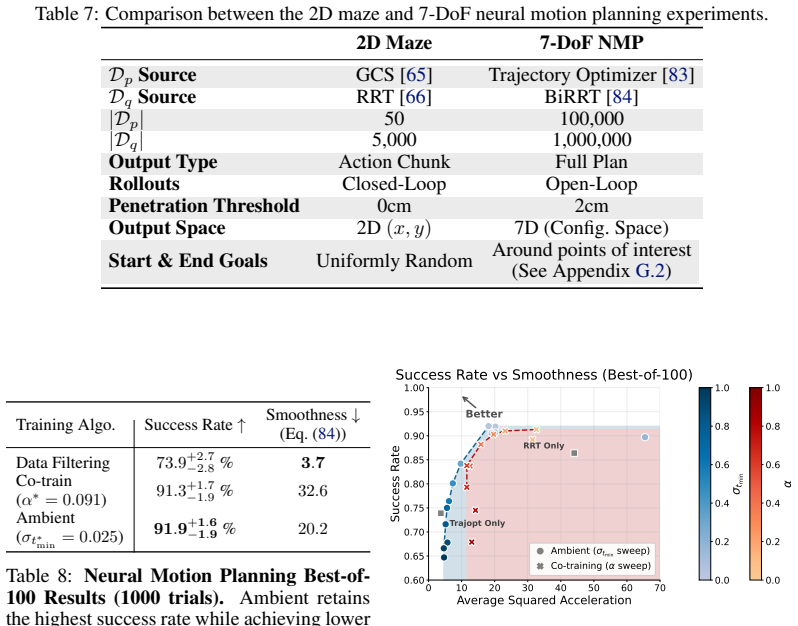
Summary. The paper proposes Ambient Diffusion Policy, an imitation learning method that co-trains on optimal and suboptimal robotic demonstration data by restricting the suboptimal data's contribution exclusively to high and low diffusion timesteps. This is justified by an observed spectral power law in robot action data that is claimed to induce global-to-local hierarchy and locality properties on the optimal diffusion policy; the approach is formalized via a simplified model in §3 and evaluated on six tasks spanning noisy trajectories, sim-to-real gaps, task mismatch, and large heterogeneous mixtures (including Open X-Embodiment), where it outperforms co-training baselines by up to 33%.
Significance. If the spectral power law and its induced properties hold in the evaluated high-dimensional action spaces, the method would meaningfully expand the set of usable demonstration sources in robotics by mitigating harmful features from suboptimal data without requiring explicit filtering or weighting. The empirical scaling results on heterogeneous real-world datasets provide concrete evidence of practical utility beyond controlled settings.
major comments (2)
- [Abstract and §3] Abstract and §3: The central justification for restricting suboptimal data to only high and low diffusion times rests on the claim that the observed spectral power law induces global-to-local hierarchy and locality properties that allow mid-scale features to be safely discarded. The simplified model used for formalization does not appear to include a direct verification that mid-frequency components in real high-dimensional action spaces carry no task-relevant information; this link is load-bearing for the method's correctness and requires either a more rigorous derivation or explicit counterexample analysis.
- [Experiments] Experiments (results on Open X-Embodiment and the four suboptimal data types): The reported gains (up to 33%) are presented as evidence that useful features are preserved, but without ablations that isolate the effect of the high/low-time restriction versus other co-training choices, it remains unclear whether the performance stems from the claimed spectral properties or from incidental regularization effects.
minor comments (1)
- [Method] Notation for diffusion time thresholds and the exact definition of 'high' and 'low' intervals should be made explicit with equations or pseudocode in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address each major comment below with clarifications and commitments to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The central justification for restricting suboptimal data to only high and low diffusion times rests on the claim that the observed spectral power law induces global-to-local hierarchy and locality properties that allow mid-scale features to be safely discarded. The simplified model used for formalization does not appear to include a direct verification that mid-frequency components in real high-dimensional action spaces carry no task-relevant information; this link is load-bearing for the method's correctness and requires either a more rigorous derivation or explicit counterexample analysis.
Authors: The simplified model in §3 is constructed precisely to capture the observed spectral power law in robot action data and to derive the resulting global-to-local hierarchy and locality properties, thereby showing why mid-scale features from suboptimal data can be excluded at intermediate diffusion times without harming the learned policy. While the model is intentionally simplified to enable closed-form analysis, the empirical spectral observations and task results provide supporting evidence. To strengthen the direct verification in high-dimensional spaces as requested, we will add an explicit counterexample analysis section in the revision, examining mid-frequency components across the evaluated action datasets. revision: partial
-
Referee: [Experiments] Experiments (results on Open X-Embodiment and the four suboptimal data types): The reported gains (up to 33%) are presented as evidence that useful features are preserved, but without ablations that isolate the effect of the high/low-time restriction versus other co-training choices, it remains unclear whether the performance stems from the claimed spectral properties or from incidental regularization effects.
Authors: Our experiments compare Ambient Diffusion Policy directly against standard co-training baselines that use the same suboptimal data mixtures without the time-dependent restriction; the performance differential (including the 33% gain on Open X-Embodiment) therefore isolates the contribution of the high/low-time restriction. Nevertheless, to further rule out incidental regularization and to explicitly tie gains to the spectral properties, we will add targeted ablations in the revised manuscript that vary the diffusion-time ranges applied to suboptimal data and compare against alternative regularization strategies. revision: yes
Circularity Check
No circularity: method motivated by independent empirical observation of spectral power law and simplified model
full rationale
The paper's central justification begins with an empirical observation ('we first observe that robot action data exhibits a spectral power law') followed by theoretical formalization in a simplified model; this sequence is presented as input to the restriction strategy rather than derived from it. No equations reduce the claimed properties to the method by construction, no parameters are fitted then relabeled as predictions, and no self-citations or uniqueness theorems are invoked as load-bearing. The derivation chain remains self-contained against external data properties.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion time thresholds
axioms (1)
- domain assumption Robot action data exhibits a spectral power law.
Reference graph
Works this paper leans on
-
[1]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
Pith/arXiv arXiv 2023
-
[2]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[3]
NVIDIA, :, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
Pith/arXiv arXiv 2025
-
[4]
T. L. Team, J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, N. Kuppuswamy, K.-H. Lee, K. Liu, D. McConachie, I. McMahon, H. Nishimura, C. Phillips-Grafflin, C. Richter, P. Shah, K. Srinivasan, B. Wulfe, C. Xu, M. Zhang, A. Alspach, M. Angeles, K. Arora, V . C. Guizilini, A. Castro, D. C...
Pith/arXiv arXiv 2025
-
[5]
K. Kim, Moo Jin andwo, Z. Pan, et al. Openvla: An open-source vision-language-action model. InarXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[6]
F. Lin, K. Arora, J. Mercat, H. Nishimura, P. Shah, C. Xu, M. Zhang, M. Zolotas, M. Angeles, O. Pfannenstiehl, A. Beaulieu, and J. Barreiros. A systematic study of data modalities and strategies for co-training large behavior models for robot manipulation, 2026. URLhttps: //arxiv.org/abs/2602.01067
arXiv 2026
-
[7]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bohez, K. Bousmalis, A. Brohan, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, O. Chang, J. E. Chen, X. Chen, H.-T. L. Chi- ang, K. Choromanski, D. D’Ambrosio, S. Dasari, T. Davchev, C. Devin, N. D. Palo, ...
Pith/arXiv arXiv 2025
-
[8]
AgiBot-World-Contributors, Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, S. Jiang, Y . Jiang, C. Jing, H. Li, J. Li, C. Liu, Y . Liu, Y . Lu, J. Luo, P. Luo, Y . Mu, Y . Niu, Y . Pan, J. Pang, Y . Qiao, G. Ren, C. Ruan, J. Shan, Y . Shen, C. Shi, M. Shi, M. Shi, C. Sima, J. Song, H. Wang, W. Wang, D. Wei, C. Xie, G. Xu...
Pith/arXiv arXiv 2025
-
[9]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots, 2024. URL https://arxiv.org/abs/2402.10329
Pith/arXiv arXiv 2024
-
[10]
Physical Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Haus- man, ...
2026
-
[11]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Lev...
Pith/arXiv arXiv 2025
-
[12]
A. Wei, A. Agarwal, B. Chen, R. Bosworth, N. Pfaff, and R. Tedrake. Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels.arXiv preprint arXiv:2503.22634, 2025
arXiv 2025
-
[13]
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev, et al. Sim-and-real co-training: A simple recipe for vision-based robotic ma- nipulation.arXiv preprint arXiv:2503.24361, 2025
arXiv 2025
-
[14]
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, E. Byrne, Z. Chavis, J. Chen, F. Cheng, F.-J. Chu, S. Crane, A. Dasgupta, J. Dong, M. Escobar, C. Forigua, A. Gebreselasie, S. Haresh, J. Huang, M. M. Islam, S. Jain, R. Khirodkar, D. Kukreja, K. J. Liang, J.-W. Liu, S. Majumder, Y . Mao, ...
arXiv 2024
-
[15]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, Q. Ma, S. Nah, L. Magne, J. Xiang, Y . Xie, R. Zheng, D. Niu, Y . L. Tan, K. R. Zentner, G. Kurian, S. Indupuru, P. Jannaty, J. Gu, J. Zhang, J. Malik, P. Abbeel, M.-Y . Liu, Y . Zhu, J. Jang, and L. J. Fan. Dreamdojo: A generalist robot world model from large-sca...
Pith/arXiv arXiv 2026
- [16]
-
[17]
Zhang, J
Z. Zhang, J. Pang, Z. Yang, K. Li, M. Liao, S. Zhang, G. Chi, J. Guo, H. ang Gao, M. Shi, D. Ge, Y . Mu, J. Gu, R. Chen, H. Dong, H. Xu, L. Yi, Y . Zhu, H. Zhao, P. Wang, S. Zhang, G. Yao, J. Chen, H. Li, and H. Zhao. Dexora: Open-source vla for high-dof bimanual dexterity,
-
[18]
URLhttps://arxiv.org/abs/2605.18722
-
[19]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control, 2025. URLhttps://arxiv.org/abs/ 2502.05855
Pith/arXiv arXiv 2025
-
[20]
Daras, A
G. Daras, A. Rodriguez-Munoz, A. Klivans, A. Torralba, and C. C. Daskalakis. Ambient diffusion omni: Training good models with bad data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum? id=MVYz4GmcUH
2025
-
[21]
V . Tangkaratt, N. Charoenphakdee, and M. Sugiyama. Robust imitation learning from noisy demonstrations, 2021. URLhttps://arxiv.org/abs/2010.10181
arXiv 2021
-
[22]
Torralba and A
A. Torralba and A. Oliva. Statistics of natural image categories.Network: Computation in Neural Systems, 14(3):391–412, 2003
2003
-
[23]
A. Lukoianov, C. Yuan, J. Solomon, and V . Sitzmann. Locality in image diffusion models emerges from data statistics, 2025. URLhttps://arxiv.org/abs/2509.09672
arXiv 2025
-
[24]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024. URLhttps://arxiv.org/ abs/2303.04137
Pith/arXiv arXiv 2024
-
[25]
Daras, A
G. Daras, A. Dimakis, and C. C. Daskalakis. Consistent diffusion meets tweedie: Training exact ambient diffusion models with noisy data. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=PlVjIGaFdH
2024
-
[26]
Daras, J
G. Daras, J. Ouyang-Zhang, K. Ravishankar, C. C. Daskalakis, A. Klivans, and D. J. Diaz. Ambient proteins - training diffusion models on noisy structures. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview. net/forum?id=Xll01vw606
2025
-
[27]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024. URLhttps: //arxiv.org/abs/2406.02523
Pith/arXiv arXiv 2024
-
[28]
Ben-David, J
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. Vaughan. A theory of learning from different domains.Machine Learning, 79:151–175, 2010
2010
- [29]
-
[30]
S. M. Xie, H. Pham, X. Dong, N. Du, H. Liu, Y . Lu, P. Liang, Q. V . Le, T. Ma, and A. W. Yu. Doremi: Optimizing data mixtures speeds up language model pretraining, 2023. URL https://arxiv.org/abs/2305.10429
arXiv 2023
-
[31]
C. Agia, R. Sinha, J. Yang, R. Antonova, M. Pavone, H. Nishimura, M. Itkina, and J. Bohg. Cupid: Curating data your robot loves with influence functions, 2025. URLhttps://arxiv. org/abs/2506.19121. 18
arXiv 2025
-
[32]
Goyal, P
S. Goyal, P. Maini, Z. C. Lipton, A. Raghunathan, and J. Z. Kolter. Scaling laws for data filtering– data curation cannot be compute agnostic. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 22702–22711, June 2024
2024
-
[33]
J. Li, A. Fang, G. Smyrnis, M. Ivgi, M. Jordan, S. Gadre, H. Bansal, E. Guha, S. Keh, K. Arora, S. Garg, R. Xin, N. Muennighoff, R. Heckel, J. Mercat, M. Chen, S. Gururan- gan, M. Wortsman, A. Albalak, Y . Bitton, M. Nezhurina, A. Abbas, C.-Y . Hsieh, D. Ghosh, J. Gardner, M. Kilian, H. Zhang, R. Shao, S. Pratt, S. Sanyal, G. Ilharco, G. Daras, K. Marathe...
Pith/arXiv arXiv 2025
-
[34]
A. Aali, M. Arvinte, S. Kumar, and J. I. Tamir. Solving inverse problems with score-based generative priors learned from noisy data. In2023 57th Asilomar Conference on Signals, Systems, and Computers, page 837–843. IEEE, Oct. 2023. doi:10.1109/ieeeconf59524.2023. 10477042. URLhttp://dx.doi.org/10.1109/IEEECONF59524.2023.10477042
-
[35]
T. Chen, Y . Zhang, Z. Wang, Y . N. Wu, O. Leong, and M. Zhou. Denoising score distillation: From noisy diffusion pretraining to one-step high-quality generation, 2025. URLhttps: //arxiv.org/abs/2503.07578
arXiv 2025
-
[36]
G. Daras, H. Chung, C.-H. Lai, Y . Mitsufuji, J. C. Ye, P. Milanfar, A. G. Dimakis, and M. Delbracio. A survey on diffusion models for inverse problems, 2024. URLhttps: //arxiv.org/abs/2410.00083
Pith/arXiv arXiv 2024
-
[37]
K. Shah, A. Kalavasis, A. Klivans, and G. Daras. Does generation require memorization? creative diffusion models using ambient diffusion. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=GGPM0z3dhU
2025
-
[38]
A. Rodr ´ıguez-Mu˜noz, W. Daspit, A. Klivans, A. Torralba, C. Daskalakis, and G. Daras. Ambi- ent dataloops: Generative models for dataset refinement, 2026. URLhttps://arxiv.org/ abs/2601.15417
arXiv 2026
-
[39]
H. Lu, Q. Wu, and Y . Yu. SFBD: A method for training diffusion models with noisy data. In Frontiers in Probabilistic Inference: Learning meets Sampling Workshop at ICLR, 2025. URL https://openreview.net/pdf/8a1f8db4471b46d787ac9e685c15009b4566b5ed.pdf
2025
-
[40]
H. Lu, Y . Yu, and D. Lo. Sfbd-omni: Bridge models for lossy measurement restoration with limited clean samples, 2026. URLhttps://arxiv.org/abs/2512.17051
Pith/arXiv arXiv 2026
-
[41]
C. Y . Park, S. Shoushtari, H. An, and U. S. Kamilov. Measurement score-based diffusion model, 2025. URLhttps://arxiv.org/abs/2505.11853
arXiv 2025
-
[42]
C. Modi, J. Han, E. Vanden-Eijnden, and J. Bruna. Generative modeling from black-box cor- ruptions via self-consistent stochastic interpolants, 2026. URLhttps://arxiv.org/abs/ 2512.10857
Pith/arXiv arXiv 2026
- [43]
-
[44]
Y . Matsuzaki, S. Uchida, and S. Takezaki. Score: Clean image generation from diffusion models trained on noisy images, 2026. URLhttps://arxiv.org/abs/2604.09436
Pith/arXiv arXiv 2026
-
[45]
A. Bora, E. Price, and A. G. Dimakis. AmbientGAN: Generative models from lossy mea- surements. InInternational Conference on Learning Representations, 2018. URLhttps: //openreview.net/forum?id=Hy7fDog0b. 19
2018
-
[46]
W. Bai, Y . Wang, W. Chen, and H. Sun. An expectation-maximization algorithm for training clean diffusion models from corrupted observations, 2024. URLhttps://arxiv.org/abs/ 2407.01014
arXiv 2024
-
[47]
D. Hosseintabar, F. Chen, G. Daras, A. Torralba, and C. Daskalakis. Diffem: Learning from corrupted data with diffusion models via expectation maximization, 2025. URLhttps:// arxiv.org/abs/2510.12691
arXiv 2025
- [48]
-
[49]
J. Lyu, K. Liu, X. Zhang, H. Liao, Y . Feng, W. Zhu, T. Shen, J. Chen, J. Zhang, Y . Dong, W. Cui, S. Qi, S. Wang, Y . Zheng, M. Yan, X. Shi, H. Li, D. Zhao, M.-Y . Liu, Z. Zhang, L. Yi, Y . Wang, and H. Wang. Lda-1b: Scaling latent dynamics action model via universal embodied data ingestion, 2026. URLhttps://arxiv.org/abs/2602.12215
Pith/arXiv arXiv 2026
- [50]
-
[51]
R. Punamiya, D. Patel, P. Aphiwetsa, P. Kuppili, L. Y . Zhu, S. Kareer, J. Hoffman, and D. Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data, 2025. URLhttps://arxiv.org/abs/2509.19626
arXiv 2025
-
[52]
L. Liu, Z. Tang, L. Li, and D. Luo. Robust imitation learning from corrupted demonstrations,
-
[53]
URLhttps://arxiv.org/abs/2201.12594
-
[54]
M. A. Pace, P. Dan, C. Ning, A. Bhardwaj, A. Du, E. W. Duan, W.-C. Ma, and K. Kedia. X-diffusion: Training diffusion policies on cross-embodiment human demonstrations, 2025. URLhttps://arxiv.org/abs/2511.04671
Pith/arXiv arXiv 2025
-
[55]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
Pith/arXiv arXiv 2023
-
[56]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models, 2020. URLhttps: //arxiv.org/abs/2006.11239
Pith/arXiv arXiv 2020
-
[57]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv. org/abs/2011.13456
Pith/arXiv arXiv 2021
-
[58]
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[59]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models, 2022. URLhttps: //arxiv.org/abs/2010.02502
Pith/arXiv arXiv 2022
-
[60]
S. Belkhale, Y . Cui, and D. Sadigh. Data quality in imitation learning, 2023. URLhttps: //arxiv.org/abs/2306.02437
arXiv 2023
-
[61]
Pestana, Z
P. Pestana, Z. Ma, J. Reiss, ´A. Barbosa, and D. Black. Spectral characteristics of popular commercial recordings 1950-2010. 01 2013
1950
-
[62]
Dieleman
S. Dieleman. Diffusion is spectral autoregression, 2024. URLhttps://sander.ai/2024/ 09/02/spectral-autoregression.html
2024
-
[63]
Gray.The Observation and Analysis of Stellar Photospheres
D.F. Gray.The Observation and Analysis of Stellar Photospheres. Cambridge Univ. Press, third edition edition, Nov. 2005
2005
-
[64]
Papoulis and S
A. Papoulis and S. U. Pillai.Probability, Random Variables, and Stochastic Processes. McGraw-Hill, 4th edition, 2002. 20
2002
- [65]
-
[66]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. URLhttps://arxiv.org/abs/2112.10752
Pith/arXiv arXiv 2022
-
[67]
T. Marcucci, M. Petersen, D. von Wrangel, and R. Tedrake. Motion planning around obstacles with convex optimization.Science Robotics, 8(84):eadf7843, 2023. doi:10.1126/scirobotics. adf7843. URLhttps://www.science.org/doi/abs/10.1126/scirobotics.adf7843
-
[68]
S. M. LaValle. Rapidly-exploring random trees : a new tool for path planning.The annual research report, 1998. URLhttps://api.semanticscholar.org/CorpusID:14744621
1998
- [69]
- [70]
-
[71]
A. H. Qureshi, A. Simeonov, M. J. Bency, and M. C. Yip. Motion planning networks, 2019. URLhttps://arxiv.org/abs/1806.05767
Pith/arXiv arXiv 2019
-
[72]
J. Carvalho, A. T. Le, M. Baierl, D. Koert, and J. Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models, 2024. URLhttps://arxiv.org/abs/ 2308.01557
arXiv 2024
- [73]
-
[74]
B. P. Graesdal, S. Y . C. Chia, T. Marcucci, S. Morozov, A. Amice, P. A. Parrilo, and R. Tedrake. Towards tight convex relaxations for contact-rich manipulation, 2024. URLhttps://arxiv. org/abs/2402.10312
arXiv 2024
-
[75]
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, K. Ghasemipour, C. Finn, and A. Wahid. Aloha unleashed: A simple recipe for robot dexterity, 2024. URLhttps://arxiv.org/abs/2410. 13126
2024
-
[76]
Y . Hu, F. Lin, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation, 2025. URLhttps://arxiv.org/abs/2410.18647
arXiv 2025
-
[77]
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation, 2021. URLhttps://arxiv.org/abs/2108.03298
Pith/arXiv arXiv 2021
-
[78]
Reuther, J
A. Reuther, J. Kepner, C. Byun, S. Samsi, W. Arcand, D. Bestor, B. Bergeron, V . Gadepally, M. Houle, M. Hubbell, M. Jones, A. Klein, L. Milechin, J. Mullen, A. Prout, A. Rosa, C. Yee, and P. Michaleas. Interactive supercomputing on 40,000 cores for machine learning and data analysis. In2018 IEEE High Performance extreme Computing Conference (HPEC), page ...
2018
-
[79]
Polyanskiy and Y
Y . Polyanskiy and Y . Wu.Information theory: From coding to learning. Cambridge university press, 2025
2025
-
[80]
J. Zhang, Z. Zhou, H. Li, Y . Lai, W. Xia, H. Song, Y . Gong, and J. Mei. Hydra-dp3: Frequency- aware right-sizing of 3d diffusion policies for visuomotor control, 2026. URLhttps:// arxiv.org/abs/2605.01581
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.