TA-RAG: Tone-Aware Retrieval-Augmented Generation for Peer-Support Health Communication
Pith reviewed 2026-06-27 22:32 UTC · model grok-4.3
The pith
TA-RAG adds four prompt-based tone controls to standard RAG so outputs become stigma-free, readable, recipient-tailored, and empathetic for HIV peer support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TA-RAG operationalises tone across four core components—stigma-free rewriting, readability adjustment, recipient adaptation, and empathy rephrasing—and shows through component-level tests on HIV-specific questions and an empathy dataset that each component improves its targeted communication quality while preserving key content.
What carries the argument
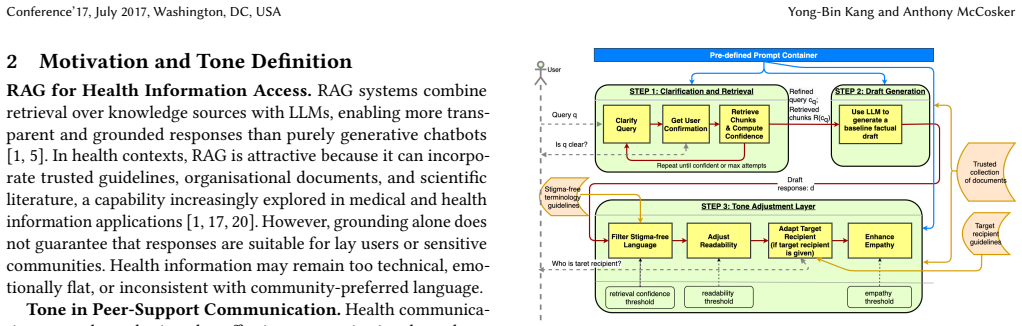
The TA-RAG pipeline, which inserts explicit prompt instructions for the four tone components into an otherwise standard retrieval-augmented generation flow.
If this is right
- RAG systems can meet peer-support standards for HIV communication without retraining the underlying language model.
- Each of the four tone components can be applied or omitted independently depending on the required output qualities.
- Preservation of key content allows factual grounding from trusted documents to remain intact while tone is adjusted.
- The approach extends to other health topics where stigma, readability, and empathy matter.
Where Pith is reading between the lines
- The same four-component structure could be reused for other sensitive domains such as mental-health or chronic-illness peer support.
- Real-world deployment would still require user testing with actual peer supporters to confirm the component tests translate to conversation quality.
- Because the method is prompt-only, it can be updated quickly when terminology guidance or empathy standards change.
Load-bearing premise
Component-level tests on the listed HIV and empathy datasets are enough to show that the four tone controls will produce appropriate outputs inside real peer-support conversations.
What would settle it
A direct comparison of TA-RAG outputs against un-controlled RAG outputs in live peer-support sessions that measures rates of stigmatizing language, reading-grade level, recipient fit, and perceived empathy.
Figures

read the original abstract
Retrieval-augmented generation (RAG) successfully grounds large language model (LLM) outputs in trusted documents, but factual grounding alone is insufficient for sensitive peer-support health communication. In domains such as HIV peer support, responses must also be accessible, stigma-free, empathetic, and tailored to the recipient. This paper presents TA-RAG, a lightweight, prompt-based tone-aware RAG framework that embeds explicit tone control into a RAG pipeline without requiring model fine-tuning. We operationalise tone across four core components: stigma-free rewriting, readability adjustment, recipient adaptation, and empathy rephrasing. We evaluate TA-RAG through component-level tests using questions derived from HIV Online Learning Australia (HOLA), UNAIDS terminology guidance, readability metrics, peer-support standards from National Association of People with HIV Australia (NAPWHA), and a public empathy dataset. Results show that the TA-RAG's components improve their targeted communication quality while preserving key content. These findings emphasise that prompt-based tone control is a potential direction for making RAG outputs suitable for sensitive peer-support health communication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TA-RAG, a lightweight prompt-based RAG framework that adds explicit tone control for sensitive peer-support health communication (e.g., HIV) via four components: stigma-free rewriting, readability adjustment, recipient adaptation, and empathy rephrasing. It reports component-level evaluations on questions derived from HOLA, UNAIDS, NAPWHA, readability metrics, and a public empathy dataset, claiming that the components improve targeted communication qualities while preserving key content.
Significance. If the central empirical claims were supported by integrated results, the work would provide a practical, no-fine-tuning route to make RAG outputs suitable for empathy- and stigma-sensitive domains; the prompt-only design and grounding in peer-support standards are clear strengths.
major comments (2)
- [Abstract] Abstract: the statement that 'Results show that the TA-RAG's components improve their targeted communication quality while preserving key content' is presented without any quantitative metrics, baselines, statistical tests, or effect sizes, leaving the central claim unsupported in the manuscript.
- [Evaluation] Evaluation (component tests): the four tone controls are assessed only in isolation on separate question sets; no end-to-end pipeline results, retrieval-interaction measurements, or target-user/expert ratings of joint outputs in multi-turn dialogues are reported, so it is not shown that the controls compound or conflict when operating together inside the RAG system.
minor comments (1)
- [Abstract] Abstract: the description of the four components could be tightened to avoid overlap between 'recipient adaptation' and 'empathy rephrasing'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key opportunities to strengthen the empirical presentation and evaluation design. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'Results show that the TA-RAG's components improve their targeted communication quality while preserving key content' is presented without any quantitative metrics, baselines, statistical tests, or effect sizes, leaving the central claim unsupported in the manuscript.
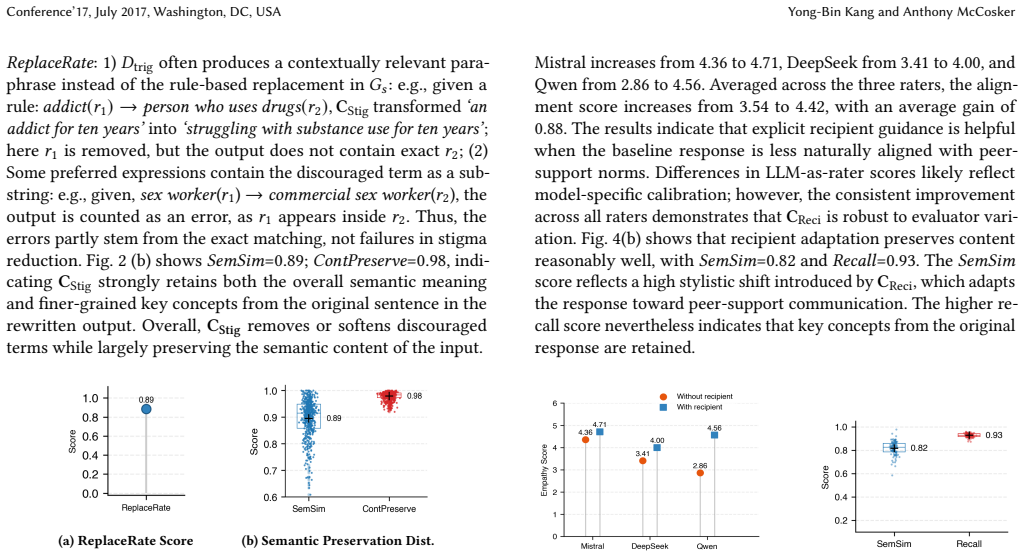
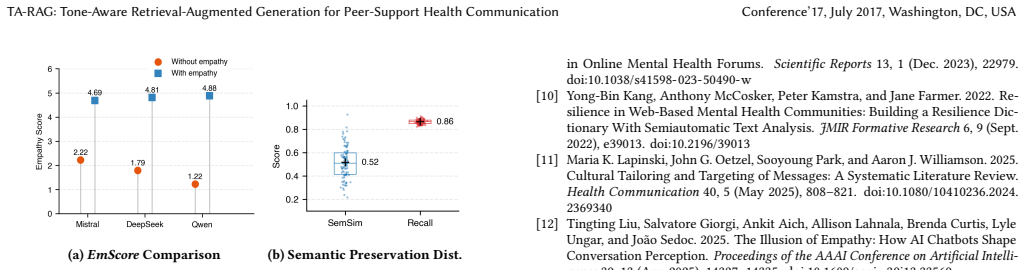
Authors: We agree that the abstract would be strengthened by explicit quantitative support. The manuscript body reports component-level metrics including readability scores (Flesch-Kincaid), stigma-free terminology adherence rates, empathy dataset scores, and content preservation via semantic similarity measures, along with comparisons to baselines. We will revise the abstract to include representative quantitative results, baselines, and effect sizes drawn from these evaluations. revision: yes
-
Referee: [Evaluation] Evaluation (component tests): the four tone controls are assessed only in isolation on separate question sets; no end-to-end pipeline results, retrieval-interaction measurements, or target-user/expert ratings of joint outputs in multi-turn dialogues are reported, so it is not shown that the controls compound or conflict when operating together inside the RAG system.
Authors: Component-level evaluation was selected to isolate and attribute effects of each tone control, consistent with modular system analysis. We acknowledge that integrated end-to-end results, retrieval interactions, and multi-turn joint-output assessments would provide additional validation of compounding or conflicts. We will revise the manuscript to add an integrated pipeline example with combined outputs and a limitations discussion on multi-turn settings. Comprehensive target-user or expert ratings of joint outputs would require new studies outside the current work. revision: partial
Circularity Check
No circularity; empirical component tests are independent of framework definition
full rationale
The paper describes a prompt-based TA-RAG framework and reports results from separate component-level evaluations on HIV-related and empathy datasets. No mathematical derivations, fitted parameters, or predictions appear; the central claim is simply that the described tone controls improve targeted metrics on the chosen test sets while preserving content. This reporting does not reduce to self-definition, self-citation chains, or renaming of inputs, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt engineering can reliably control specific aspects of LLM output tone such as empathy and stigma avoidance.
Reference graph
Works this paper leans on
-
[1]
Amugongo, Paola Mascheroni, Sarah Brooks, Susanne Doering, and Jan Seidel
Lucia M. Amugongo, Paola Mascheroni, Sarah Brooks, Susanne Doering, and Jan Seidel. 2025. Retrieval Augmented Generation for Large Language Models in Healthcare: A Systematic Review.PLOS Digital Health4, 6 (2025), e0000877. doi:10.1371/journal.pdig.0000877
-
[2]
Rigmor C Berg, Samantha Page, and Anita Øgård Repål. 2021. The effectiveness of peer-support for people living with HIV: A systematic review and meta-analysis. PLoS One16, 6 (2021), e0252623. doi:10.1371/journal.pone.0252623
-
[3]
Nadine Bol, Eline Suzanne Smit, and Mia Liza A. Lustria. 2020. Tailored health communication: Opportunities and challenges in the digital era.Digital Health 6 (2020), 2055207620958913. arXiv:https://doi.org/10.1177/2055207620958913 doi:10.1177/2055207620958913 PMID: 33029355
-
[4]
Challener, An Wen, Jung Wei Fan, Hongfang Liu, John O’Horo, and Michael Nyman
Douglas W. Challener, An Wen, Jung Wei Fan, Hongfang Liu, John O’Horo, and Michael Nyman. 2025. Flesch-Kincaid Grade Level Readability Scores to Evaluate Readability of Clinical Documentation During an Electronic Health Record Transition.Advances in Health Informatics Science and Practice1, 1 (2025), VBWY7913. doi:10.63116/VBWY7913
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2024
-
[6]
Riley Grossman and Yi Chen. 2026. Zero-shot Large Language Models for Auto- matic Readability Assessment. arXiv:2604.24470 [cs.CL] https://arxiv.org/abs/ 2604.24470
Pith/arXiv arXiv 2026
-
[7]
Health Equity Matters. 2024. Appropriate Language Guide. Published 23 May 2024. Available at https://www.healthequitymatters.org.au/media-guide/ appropriate-language-guide
2024
-
[8]
Yong-Bin Kang, Abdur Rahim Mohammad Forkan, Abhik Banerjee, Prem Prakash Jayaraman, Anthony McCosker, Sungsoo Kim, Natalie Wieland, and Liz Kollias
-
[9]
Comparative Analysis of Large Language Models for Automated Question Generation From Video-Based Learning Content.IEEE Transactions on Artificial Intelligence7, 5 (2026), 2594–2609. doi:10.1109/TAI.2025.3620274
-
[10]
Yong-Bin Kang, Anthony McCosker, and Jane Farmer. 2023. Leveraging Stylom- etry Analysis to Identify Unique Characteristics of Peer Support User Groups in Online Mental Health Forums.Scientific Reports13, 1 (Dec. 2023), 22979. doi:10.1038/s41598-023-50490-w
-
[11]
Yong-Bin Kang, Anthony McCosker, Peter Kamstra, and Jane Farmer. 2022. Re- silience in Web-Based Mental Health Communities: Building a Resilience Dic- tionary With Semiautomatic Text Analysis.JMIR Formative Research6, 9 (Sept. 2022), e39013. doi:10.2196/39013
-
[12]
Maria K. Lapinski, John G. Oetzel, Sooyoung Park, and Aaron J. Williamson. 2025. Cultural Tailoring and Targeting of Messages: A Systematic Literature Review. Health Communication40, 5 (May 2025), 808–821. doi:10.1080/10410236.2024. 2369340
-
[13]
Tingting Liu, Salvatore Giorgi, Ankit Aich, Allison Lahnala, Brenda Curtis, Lyle Ungar, and João Sedoc. 2025. The Illusion of Empathy: How AI Chatbots Shape Conversation Perception.Proceedings of the AAAI Conference on Artificial Intelli- gence39, 13 (Apr. 2025), 14327–14335. doi:10.1609/aaai.v39i13.33569
-
[14]
Mia Liza A. Lustria. 2017. Message Tailoring in Health and Risk Messaging. InOxford Research Encyclopedia of Communication. Oxford University Press. doi:10.1093/acrefore/9780190228613.013.323
-
[15]
2023.Approaches and Best Practice Models of Care for Advancing the Quality of Life for People with HIV in Australia
Kirsty Machon, Hiero Badge, and Brent Allan. 2023.Approaches and Best Practice Models of Care for Advancing the Quality of Life for People with HIV in Australia. Technical Report. HIV Online Learning Australia (HOLA). https://napwha.org. au/ausqol/
2023
-
[16]
National Association of People with HIV Australia (NAPWHA). 2020. Australian HIV Peer Support Standards. https://napwha.org.au/wp-content/uploads/2020/ 04/NAPWHA-Australian-Peer-Support-Standards.pdf Accessed: 2026-05-22
2020
-
[17]
Nembhard, Guy David, Imad Ezzeddine, Dana Betts, and Jennifer Radin
Ingrid M. Nembhard, Guy David, Imad Ezzeddine, Dana Betts, and Jennifer Radin
-
[18]
doi:10.1111/1475-6773.14016 Epub 2022 Jul 15
A Systematic Review of Research on Empathy in Health Care.Health Services Research58, 2 (April 2023), 250–263. doi:10.1111/1475-6773.14016 Epub 2022 Jul 15
-
[19]
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of GPT-4 on Medical Challenge Problems. arXiv:2303.13375 [cs.CL] https://arxiv.org/abs/2303.13375
Pith/arXiv arXiv 2023
-
[20]
Amit Sharma, Irene W. Lin, Adam S. Miner, et al. 2023. Human–AI Collaboration Enables More Empathic Conversations in Text-Based Peer-to-Peer Mental Health Support.Nature Machine Intelligence5 (2023), 46–57. doi:10.1038/s42256-022- 00593-2
-
[21]
Jocelyn Shen, Daniella DiPaola, Safinah Ali, Maarten Sap, Hae Won Park, and Cynthia Breazeal. 2024. Empathy Toward Artificial Intelligence Versus Human Experiences and the Role of Transparency in Mental Health and Social Support Chatbot Design: Comparative Study.JMIR Mental Health11 (2024), e62679. doi:10.2196/62679
-
[22]
A. J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, et al. 2023. Large language models in medicine.Nature Medicine29 (2023), 1930–1940. doi:10.1038/s41591- 023-02448-8
-
[23]
H. Tran, Z. Yao, W. S. Jang, S. Sultana, A. Chang, Y. Zhang, and H. Yu. 2025. MedReadCtrl: Personalizing medical text generation with readability-controlled instruction learning.medRxiv(Jul 2025), 2025.07.09.25331239. doi:10.1101/2025. 07.09.25331239 Preprint
-
[24]
2024.UNAIDS Terminology Guidelines
UNAIDS. 2024.UNAIDS Terminology Guidelines. Technical Report. UNAIDS. Pub- lished 1 July 2024. Available at https://www.unaids.org/en/resources/documents/ 2024/terminology_guidelines
2024
-
[25]
World Health Organization. 2022.Consolidated Guidelines on HIV, Viral Hepatitis and Sexually Transmitted Infections: Prevention, Diagnosis, Treatment and Care for Key Populations. Technical Report. World Health Organization. https: //www.who.int/publications/i/item/9789240053274
arXiv 2022
-
[26]
Jordyn Young, Laala M. Jawara, Diep N. Nguyen, Brian Daly, Jina Huh-Yoo, and Afsaneh Razi. 2024. The Role of AI in Peer Support for Young People: A Study of Preferences for Human- and AI-Generated Responses.arXiv preprint arXiv:2405.02711(2024)
arXiv 2024
-
[27]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[28]
InInternational Con- ference on Learning Representations (ICLR)
BERTScore: Evaluating Text Generation with BERT. InInternational Con- ference on Learning Representations (ICLR). https://openreview.net/forum?id= SkeHuCVFDr
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.