Diverse Thinking Schemata Elicit Better Reasoning in Large Language Models
Pith reviewed 2026-06-27 17:02 UTC · model grok-4.3
The pith
Diverse thinking schemata improve reasoning performance in large language models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
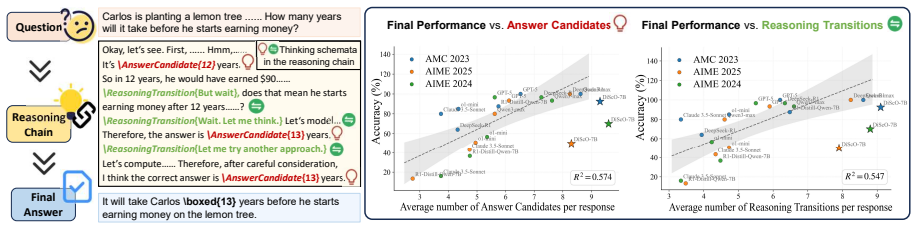
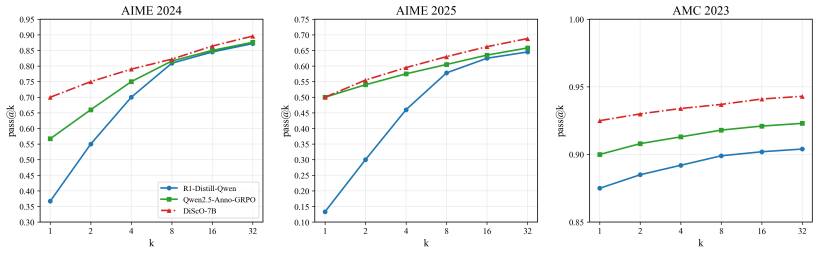
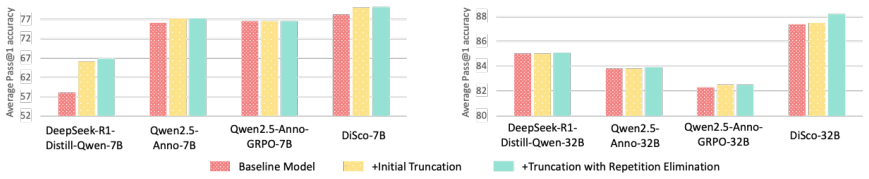
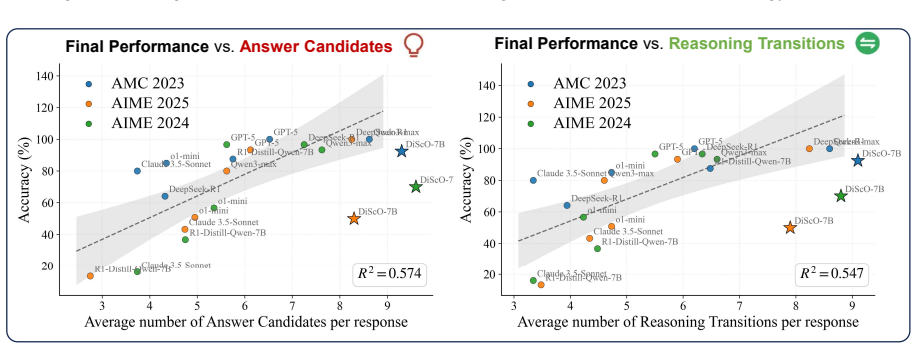
Diverse thinking schemata elicit better reasoning. The authors define thinking schemata as reasoning transitions and answer candidates, observe their diversity correlates with performance, and show that the DiScO framework, which adds schemata awareness, applies reinforcement learning to promote diversity, and promotes diverse inference, outperforms group relative policy optimization on math benchmarks and improves recovery from erroneous attempts.
What carries the argument
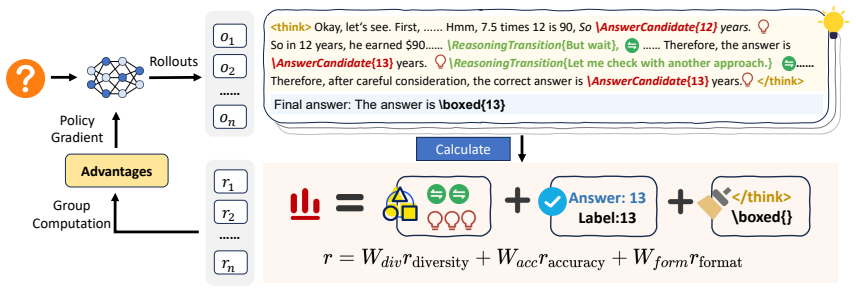
DiScO, the Diverse Schemata Policy Optimization framework that builds awareness of reasoning transitions and answer candidates, then uses reinforcement learning and inference-time promotion to increase their diversity.
If this is right
- Consistent outperformance over standard group relative policy optimization on mathematical reasoning benchmarks.
- Improved ability to recover from erroneous initial attempts, as shown in human-annotated analyses.
- Scaling along the diversity dimension emerges as a promising direction for reasoning models.
- Models gain the capacity to produce a wider range of solution paths.
Where Pith is reading between the lines
- Similar diversity mechanisms could be tested on other complex tasks like logical deduction or multi-step planning.
- Combining diversity training with model scaling might yield additive benefits.
- The correlation observed could inspire new metrics for evaluating reasoning quality beyond final accuracy.
Load-bearing premise
The observed correlation between thinking schemata diversity and performance is causal and can be increased beneficially by the DiScO mechanisms.
What would settle it
Running the DiScO method on a benchmark and finding no accuracy gain or even a drop compared to the baseline group relative policy optimization.
Figures





read the original abstract
Large reasoning models (LRMs) have attracted increasing attention for their ability to solve complex mathematical problems by generating extended reasoning chains. In this work, we focus on two critical yet underexplored aspects of the reasoning process: reasoning transitions capturing the distinct transitions between reasoning steps and answer candidates reflecting the variety of solution paths produced by the model. We collectively define these two aspects as thinking schemata. We observe a correlation between the diversity of thinking schemata and model performance, which motivates us to enhance diversity as a means to further improve reasoning potential. To this end, we propose Diverse Schemata Policy Optimization (DiScO), a framework that first endows the model with schemata awareness, then encourages diversity through reinforcement learning, and further promotes diverse reasoning at inference time. Experiments on multiple mathematical reasoning benchmarks demonstrate that DiScO consistently outperforms standard group relative policy optimization. Beyond accuracy, human-annotated analyses show that DiScO substantially improves the model's ability to recover from erroneous initial attempts. Overall, our work suggests the important role that diversity of the thinking schemata plays and points to scaling along the diversity dimension as a promising research direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes a correlation between the diversity of 'thinking schemata' (reasoning transitions between steps and variety of answer candidates) and performance in large reasoning models on mathematical tasks. It introduces the DiScO framework, which first builds schemata awareness, then applies reinforcement learning to encourage diversity, and finally promotes diverse reasoning at inference time. The central empirical claims are that DiScO consistently outperforms standard group relative policy optimization (GRPO) on multiple math benchmarks and that human-annotated analysis shows substantially better recovery from erroneous initial attempts.
Significance. If the performance gains can be causally attributed to increased beneficial diversity rather than generic RL or generation-length effects, the work identifies a new, potentially scalable axis for improving reasoning in LRMs beyond conventional policy optimization. The emphasis on both quantitative accuracy and qualitative recovery behavior is a positive feature.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments: The claim that DiScO 'consistently outperforms' GRPO and improves error recovery rests on an initial correlation plus end-to-end results, but the manuscript provides no ablations that hold total compute, generation length, and non-diversity RL components fixed while varying only the diversity objective. Without such controls the performance delta cannot be attributed specifically to diversity of thinking schemata, which is load-bearing for the central causal claim.
- [Human-annotated analyses] Human-annotated analyses: The recovery analysis is presented as evidence that DiScO improves recovery from erroneous attempts, yet the description does not report inter-annotator agreement, blinding procedures, or any quantification of whether the recovered paths actually exhibit higher schemata diversity. This leaves open the possibility of annotation bias and weakens the qualitative support for the diversity mechanism.
minor comments (1)
- [Abstract] The abstract refers to 'multiple mathematical reasoning benchmarks' without naming them or reporting per-benchmark numbers; adding this information would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, acknowledging where the manuscript is limited and outlining planned revisions to strengthen the causal claims and qualitative analysis.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The claim that DiScO 'consistently outperforms' GRPO and improves error recovery rests on an initial correlation plus end-to-end results, but the manuscript provides no ablations that hold total compute, generation length, and non-diversity RL components fixed while varying only the diversity objective. Without such controls the performance delta cannot be attributed specifically to diversity of thinking schemata, which is load-bearing for the central causal claim.
Authors: We agree that the absence of ablations isolating the diversity objective while controlling for total compute, generation length, and other RL components limits the strength of the causal attribution. The current results demonstrate end-to-end gains from the full DiScO pipeline and an initial correlation between schemata diversity and performance, but do not fully disentangle the diversity term from other factors. In the revised manuscript we will add controlled ablations that apply RL with matched compute budgets and generation lengths but omit the diversity-promoting objective, allowing direct comparison to standard GRPO and clarifying the specific contribution of thinking schemata diversity. revision: yes
-
Referee: [Human-annotated analyses] Human-annotated analyses: The recovery analysis is presented as evidence that DiScO improves recovery from erroneous attempts, yet the description does not report inter-annotator agreement, blinding procedures, or any quantification of whether the recovered paths actually exhibit higher schemata diversity. This leaves open the possibility of annotation bias and weakens the qualitative support for the diversity mechanism.
Authors: We concur that the human-annotated recovery analysis requires additional methodological details to rule out bias and to link improvements directly to increased schemata diversity. The current manuscript reports that DiScO improves recovery from erroneous initial attempts but does not include inter-annotator agreement statistics, blinding information, or quantitative diversity metrics on the recovered paths. In revision we will report inter-annotator agreement, describe the blinding protocol, and add measurements confirming that recovered paths under DiScO exhibit measurably higher diversity in reasoning transitions and answer candidates. revision: yes
Circularity Check
No circularity: empirical correlation and framework are independent of results
full rationale
The paper first defines thinking schemata as reasoning transitions and answer candidates, reports an observed correlation with performance, then introduces the DiScO framework (awareness + RL diversity objective + inference promotion) and evaluates it empirically against GRPO on benchmarks plus human recovery analysis. No step reduces a claimed prediction to a fitted parameter by construction, no self-citation chain supports a uniqueness theorem or ansatz, and the central performance claim rests on external benchmark comparisons rather than tautological redefinition of inputs. The derivation chain is therefore self-contained against the stated experimental evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sohyun An, Ruochen Wang, Tianyi Zhou, and Cho- Jui Hsieh
Think inside the json: Reinforcement strat- egy for strict llm schema adherence.arXiv preprint arXiv:2502.14905. Sohyun An, Ruochen Wang, Tianyi Zhou, and Cho- Jui Hsieh. 2025. Don’t think longer, think wisely: Optimizing thinking dynamics for large reasoning models.arXiv preprint arXiv:2505.21765. Anthropic. 2025. Introducing claude 3.5 son- net. https:/...
-
[2]
Reasoning with Exploration: An Entropy Perspective
Reasoning with exploration: An entropy per- spective.arXiv preprint arXiv:2506.14758. Patricia W Cheng and Keith J Holyoak. 1985. Prag- matic reasoning schemas.Cognitive psychology, 17(4):391–416. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question an- swering?...
work page internal anchor Pith review Pith/arXiv arXiv 1985
-
[3]
arXiv preprint arXiv:2505.10185
The cot encyclopedia: Analyzing, predicting, and controlling how a reasoning model will think. arXiv preprint arXiv:2505.10185. Jia Li, Edward Beeching, Lewis Tunstall, Ben Lip- kin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, and 1 oth- ers. 2024. Numinamath: The largest public dataset in ai4maths with 860k pairs ...
-
[4]
InAd- vances in Neural Information Processing Systems, volume 37, pages 95266–95290
MMLU-pro: A more robust and challenging multitask language understanding benchmark. InAd- vances in Neural Information Processing Systems, volume 37, pages 95266–95290. 2024a. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language ...
-
[5]
Yao Yao, Zuchao Li, and Hai Zhao
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Yao Yao, Zuchao Li, and Hai Zhao. 2024. Got: Effec- tive graph-of-thought reasoning in language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2901–2921. Adam Younsi, Ahmed Attia...
-
[6]
arXiv preprint arXiv:2506.01347 , year=
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. 2025. The surprisin...
-
[7]
An- swerCandidate
to obtain deterministic and precise genera- tions. For Pass@k, which requires multiple sam- ples per prompt to assess exploration across at- tempts, we use stochastic sampling with tempera- ture 0.6 and top-p 0.8. To ensure fair comparison, all models are evaluated under identical decoding configurations within each setting and share the same inference pr...
2024
-
[8]
The reasoning chain is enclosed within tags, i.e., reasoning chain here
First thinks about the reasoning chain in the mind and then provides the user with the answer. The reasoning chain is enclosed within tags, i.e., reasoning chain here . If the final answer is obtained, use \boxed{} to represent it
-
[9]
DO NOT label all the possible intermediate results, ONLY label the ones that could be the final answers, no matter it’s correct or wrong
Label all segments that are potentially final results in the reasoning chain with \AnswerCandidate format. DO NOT label all the possible intermediate results, ONLY label the ones that could be the final answers, no matter it’s correct or wrong. Label as many as you could
-
[10]
Let’s do that division: 1800 ÷ 36
An example of the \AnswerCandidate annotation: “Wait, 5 times 360 is 1800, and 1800 divided by 36. Let’s do that division: 1800 ÷ 36. Hmm, 36 times 50 is 1800, right? Because 36 x 50 is
-
[12]
Label as many as you could
Label all segments that indicate a shift in reasoning within the text reasoning chain using the \ReasoningTransition format. Label as many as you could
-
[13]
\ReasoningTransition{Wait, hold on}
An example of the \ReasoningTransition annotation: “\ReasoningTransition{Wait, maybe} I messed up the daily progress. \ReasoningTransition{Wait, hold on}. If the original total time is T days, then when they switch to the new equipment after 1/3 of the tunnel is done, which took T/3 days, and then the remaining 2/3 is done at a slower daily rate." ### Que...
-
[14]
DO NOT label all the possible intermediate results, ONLY label the ones that could be the final answers, no matter it’s correct or wrong
Label all segments that are potentially final results in the reasoning chain with \AnswerCandidate{} format. DO NOT label all the possible intermediate results, ONLY label the ones that could be the final answers, no matter it’s correct or wrong. Label as many as you could
-
[15]
Let’s do that division: 1800 ÷ 36
An example of the \AnswerCandidate{} annotation: “Wait, 5 times 360 is 1800, and 1800 divided by 36. Let’s do that division: 1800 ÷ 36. Hmm, 36 times 50 is 1800, right? Because 36 x 50 is
-
[16]
Therefore, the degrees for cherry pie would be \AnswerCandidate{50} degrees."
So, 1800 ÷ 36 = \AnswerCandidate{50}. Therefore, the degrees for cherry pie would be \AnswerCandidate{50} degrees."
-
[17]
Label as many as you could
Label all segments that indicate a shift in reasoning within the text reasoning chain using the \ReasoningTransition{} format. Label as many as you could
-
[18]
An example of the \ReasoningTransition{} annotation: “\ReasoningTransition{Wait, maybe} I messed up the daily progress.\ReasoningTransition{Wait, hold on}. If the original total time is T days, then when they switch to the new equipment after 1/3 of the tunnel is done, which took T/3 days, and then the remaining 2/3 is done at a slower daily rate"
-
[19]
Wait,”, “Let me try another approach,
DO NOT change other parts and keep them exactly the same as the the original solution. ### original solution: {solution} ### Result: Figure 7: Labeling prompt used for annotating candidate answers and reasoning transitions. Human labeling instructions You will be shown a sequence of mathematical reasoning chains, each one already annotated by an automatic...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.