Algometrics: Forecasting Under Algorithmic Feedback
Pith reviewed 2026-06-30 21:22 UTC · model grok-4.3
The pith
Deployment risk cannot be identified from passive historical data alone in algorithmic markets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
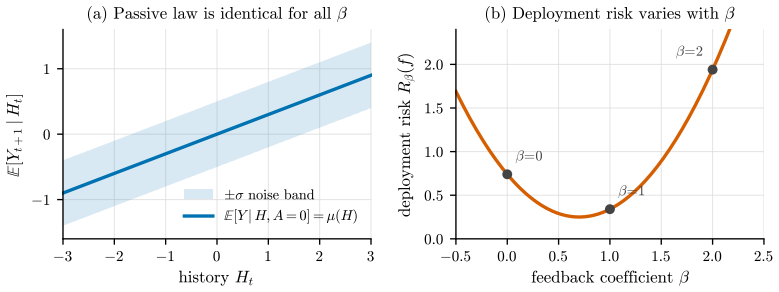
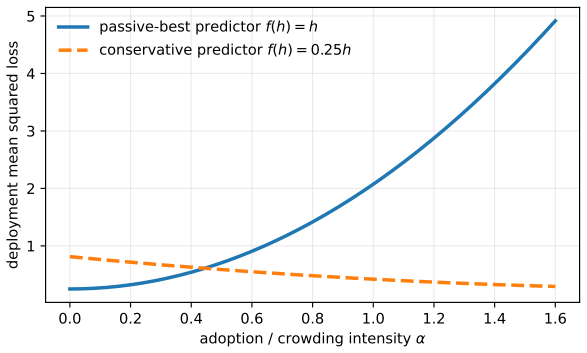
In the algometrics framework for time series whose evolution depends on the predictive algorithms forecasting them, deployment risk is not identifiable from passive historical data alone: even in a one-step linear feedback model, infinitely many algorithm-mediated environments induce the same historical law while implying different deployment risks for the same forecaster. Historical model rankings can invert under crowding, and randomized actions identify short-horizon linear feedback with a finite-sample bound.
What carries the argument
The algometrics framework that separates historical risk under passive forecasting from deployment risk when forecasts drive actions.
If this is right
- Historical model rankings can invert when similar algorithms are adopted at scale.
- Randomized or instrumented actions recover short-horizon linear feedback parameters.
- A finite-sample bound exists for estimating deployment risk from such actions.
- Time-series benchmarks in algorithmic markets should report feedback sensitivity in addition to predictive accuracy.
Where Pith is reading between the lines
- The same non-identifiability may appear in multi-step or nonlinear feedback settings common in real markets.
- Regulators could require disclosure of feedback sensitivity for deployed forecasting systems.
- Existing time-series benchmarks in finance or recommendation systems may systematically understate operational risk.
- Extending the framework to partial identification bounds could yield practical robustness checks without full randomization.
Load-bearing premise
The non-identifiability and ranking-inversion results are derived under a one-step linear feedback model.
What would settle it
A concrete dataset from a market with known one-step linear feedback in which every possible environment consistent with the observed history produces the identical deployment risk for a fixed forecaster.
Figures
read the original abstract
In algorithmic markets, predictive models become part of the data-generating process they aim to forecast. Once their outputs are converted into trades, allocations, execution schedules, or risk controls, they change the future data on which they are evaluated. I introduce algometrics, a framework for time series whose evolution depends on the predictive algorithms forecasting them. The framework distinguishes historical risk, measured under passive forecasting, from deployment risk, measured when forecasts drive actions. I prove three results. First, deployment risk is not identifiable from passive historical data alone: even in a one-step linear feedback model, infinitely many algorithm-mediated environments induce the same historical law while implying different deployment risks for the same forecaster. Second, historical model rankings can invert under crowding, so a predictor with lower passive error can have higher deployment error once similar algorithms are adopted. Third, randomized or instrumented actions identify short-horizon linear feedback, and I derive a finite-sample bound for deployment-risk estimation. These results suggest that time-series benchmarks in algorithmic markets should report feedback sensitivity alongside predictive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the algometrics framework for time series whose evolution depends on the predictive algorithms forecasting them. It distinguishes historical risk (under passive forecasting) from deployment risk (when forecasts drive actions). Three results are proved: (1) in a one-step linear feedback model, deployment risk is not identifiable from passive historical data alone, as infinitely many algorithm-mediated environments can induce the same historical law but imply different deployment risks; (2) historical model rankings can invert under crowding; (3) randomized or instrumented actions identify short-horizon linear feedback, with a derived finite-sample bound for deployment-risk estimation. The results suggest that time-series benchmarks in algorithmic markets should report feedback sensitivity alongside predictive accuracy.
Significance. If the derivations hold, the work identifies a structural limitation in using passive historical data to evaluate forecasters whose outputs affect the data-generating process, with direct implications for benchmark design in algorithmic markets. The explicit scoping of the non-identifiability and ranking-inversion claims to the one-step linear case, together with the constructive identification result and finite-sample bound, provides a clear, falsifiable foundation. The proofs for the three results constitute a substantive theoretical contribution.
minor comments (2)
- [Abstract] The abstract states the three results but does not name the specific sections or theorems where the proofs appear; adding explicit cross-references (e.g., 'Theorem 3.2') would improve navigation.
- Notation for the linear feedback parameters (e.g., the matrix or scalar governing the one-step effect) should be introduced with a short table or equation block early in the model section to aid readers.
Simulated Author's Rebuttal
We thank the referee for their supportive review, clear summary of the contributions, and recommendation to accept the manuscript.
Circularity Check
No significant circularity identified
full rationale
The paper's core claims are theoretical identifiability results: deployment risk is not recoverable from passive historical data alone because infinitely many linear-feedback environments can share the same observed law while differing in deployment risk; historical rankings can invert under crowding; and instrumented actions yield finite-sample bounds for short-horizon feedback. These statements are derived directly from the one-step linear model assumptions without any reduction of a claimed prediction to a fitted parameter, without self-definitional loops, and without load-bearing self-citations. The results are explicitly scoped to the minimal linear case and presented as existence proofs rather than empirical fits or renamings of known quantities. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption One-step linear feedback model
invented entities (1)
-
algometrics framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
David Byrd, Maria Hybinette, and Tucker H
doi: 10.1111/jofi.13477. David Byrd, Maria Hybinette, and Tucker H. Balch. Abides: Towards high-fidelity multi-agent market simulation. InProceedings of the 2020 ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, pages 11–22,
-
[2]
The Econometrics Journal , volume =
doi: 10.1111/ectj.12097. Rama Cont and Jean-Philippe Bouchaud. Herd behavior and aggregate fluctuations in financial markets. Macroeconomic Dynamics, 4(2):170–196,
-
[3]
When do systematic strategies decay?Quantitative Finance, 22 (11):1955–1969,
Antoine Falck, Adam Rej, and David Thesmar. When do systematic strategies decay?Quantitative Finance, 22 (11):1955–1969,
1955
-
[4]
Shihao Gu, Bryan Kelly, and Dacheng Xiu
doi: 10.1080/14697688.2022.2098810. Shihao Gu, Bryan Kelly, and Dacheng Xiu. Empirical asset pricing via machine learning.The Review of Financial Studies, 33(5):2223–2273,
-
[5]
Moritz Hardt and Celestine Mendler-Dünner
doi: 10.1093/rfs/hhaa009. Moritz Hardt and Celestine Mendler-Dünner. Performative prediction: Past and future.arXiv preprint arXiv:2310.16608,
-
[6]
Strategic classification
Moritz Hardt, Nimrod Megiddo, Christos Papadimitriou, and Mary Wootters. Strategic classification. In Proceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science, pages 111–122,
2016
-
[7]
doi: 10.1111/jofi.13298. Amir E. Khandani and Andrew W. Lo. What happened to the quants in august 2007? evidence from factors and transactions data.Journal of Financial Markets, 14(1):1–46,
-
[8]
Performative market making.arXiv preprint arXiv:2508.04344,
Charalampos Kleitsikas, Stefanos Leonardos, and Carmine Ventre. Performative market making.arXiv preprint arXiv:2508.04344,
-
[9]
doi: 10.1016/j.jfineco.2021.10.006. R. David McLean and Jeffrey Pontiff. Does academic research destroy stock return predictability?The Journal of Finance, 71(1):5–32,
-
[10]
Xiao Yang, Weiqing Liu, Dong Zhou, Jiang Bian, and Tie-Yan Liu
doi: 10.1093/rfs/hhm014. Xiao Yang, Weiqing Liu, Dong Zhou, Jiang Bian, and Tie-Yan Liu. Qlib: An AI-oriented quantitative investment platform,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.