RaMem: Contextual Reinstatement for Long-term Agentic Memory
Pith reviewed 2026-06-26 08:45 UTC · model grok-4.3
The pith
RaMem restores surrounding context to memory fragments so agents can judge whether they supply valid evidence for the current query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
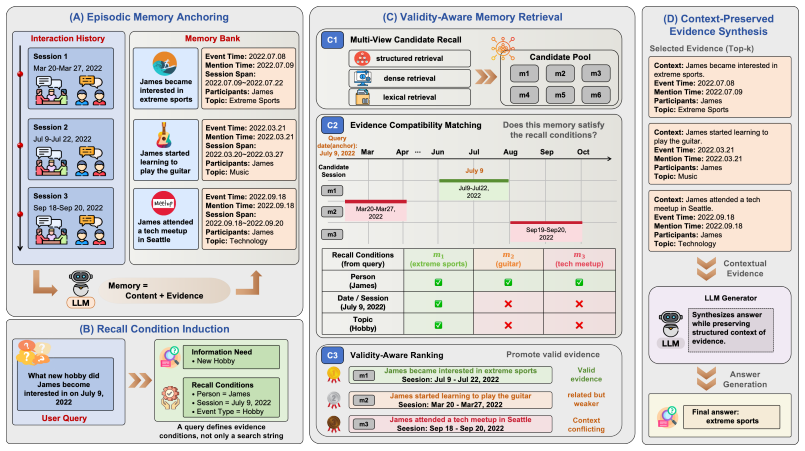
RaMem turns retrieved memory fragments into contextually verifiable evidence by coordinating evidence anchoring that records original episodic conditions, recall condition induction that extracts the conditions implied by the query, validity-aware retrieval that favors context-compatible items while keeping content-relevant fallbacks, and context-preserved synthesis that supplies the selected memories' structured context to the generator, producing consistent performance gains over strong baselines.
What carries the argument
The RaMem framework, which coordinates evidence anchoring, recall condition induction, validity-aware retrieval, and context-preserved synthesis to reinstate contextual verifiability around compressed memories.
If this is right
- Memory fragments become usable as evidence only when their original conditions match the query's implied conditions.
- Agents gain a fallback path that retains content-similar memories when no fully context-compatible memory exists.
- The same four-stage reinstatement applies across different LLM backbones without retraining.
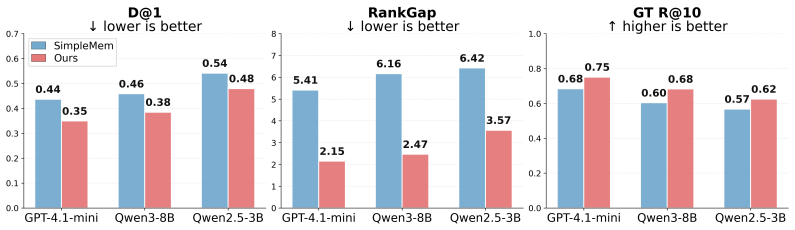
- Long-term agent performance on tasks that span multiple sessions improves by more than 10 percent F1 on average.
Where Pith is reading between the lines
- The reinstatement idea could be tested on retrieval-augmented generation pipelines outside explicit memory systems to see whether the same validity check reduces context mismatch errors.
- Real-world agent deployments with continuously evolving user states would reveal whether the reported benchmark gains persist when session boundaries and participant sets are noisier than in the test sets.
- If the anchoring stage proves costly, a lighter version that records only time and session identifiers might still capture most of the benefit.
Load-bearing premise
The four stages can be added to existing memory pipelines without introducing new errors or latency that cancel the reported gains, and the chosen benchmarks measure the intended context-collapse failures.
What would settle it
Running the same long-term memory benchmarks with and without the four stages and observing no F1 improvement or a net loss would falsify the claim of consistent gains.
Figures
read the original abstract
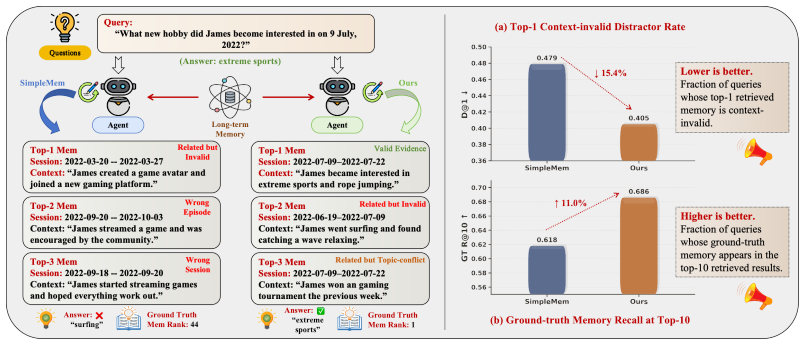
Long-term memory has become increasingly important for LLM agents that operate across extended interactions and evolving task contexts. Recent memory systems have made past experiences more persistent, compact, and retrievable, but retrieval alone does not ensure that a memory provides valid evidence for the current query. When experiences are compressed into reusable fragments, memories from different situations may appear equally relevant if they involve recurring entities or user states. We refer to this failure as context collapse: memories lose the surrounding context needed to judge whether they provide valid evidence for the current query. To address this problem, we propose Contextual Reinstatement for Agentic Memory (RaMem), a framework that turns retrieved memory fragments into contextually verifiable evidence. RaMem operates through four coordinated stages: (i) evidence anchoring grounds each memory in its original episodic conditions, especially event time, mention time, session span, and participants; (ii) recall condition induction derives the evidence conditions implied by the query; (iii) validity-aware retrieval uses these conditions to prioritize context-compatible memories while retaining content-relevant candidates as fallback evidence; and (iv) context-preserved synthesis keeps the selected memories' structured context available to the generator. Experiments on long-term memory benchmarks show that RaMem consistently improves performance over strong memory baselines, with average F1 gains of more than 10% across several backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 'context collapse'—where compressed long-term memories lose episodic context and supply invalid evidence despite entity or state matches—is a key limitation in LLM agent memory systems. It proposes RaMem, a four-stage framework (evidence anchoring, recall condition induction, validity-aware retrieval, context-preserved synthesis) to reinstate contextual verifiability, and reports that it yields average F1 gains exceeding 10% over strong memory baselines across multiple backbones on long-term memory benchmarks.
Significance. If the performance gains are attributable to the validity-aware mechanism rather than generic retrieval improvements, the work could meaningfully advance reliable long-horizon agentic systems by distinguishing content relevance from episodic validity. The staged approach is conceptually coherent and targets a plausible failure mode not explicitly handled by prior memory compression or retrieval methods.
major comments (2)
- [Experiments] Experiments section: the manuscript provides no indication that the chosen benchmarks were constructed, filtered, or analyzed to contain measurable rates of context-collapse cases (entity-matching memories differing in time, session span, or participants). Without this or ablations isolating validity-aware retrieval, the >10% F1 claim does not substantiate the central mechanism over alternative explanations.
- [Method] Method section (four stages): no analysis or controls are reported on whether the additional processing steps introduce new errors, latency, or context-preservation failures that could offset the claimed gains; the weakest assumption that the stages can be implemented without net negative effects therefore remains untested.
minor comments (2)
- [Abstract] Abstract: specific benchmark names, backbone models, and baseline systems are not named, reducing the ability to assess generality.
- Notation: the distinction between 'evidence conditions' and 'recall conditions' is introduced without a formal definition or example that would clarify how they differ from standard query expansion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the experimental validation of RaMem's central mechanism can be strengthened. We address each major comment below and will incorporate revisions to provide clearer substantiation.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript provides no indication that the chosen benchmarks were constructed, filtered, or analyzed to contain measurable rates of context-collapse cases (entity-matching memories differing in time, session span, or participants). Without this or ablations isolating validity-aware retrieval, the >10% F1 claim does not substantiate the central mechanism over alternative explanations.
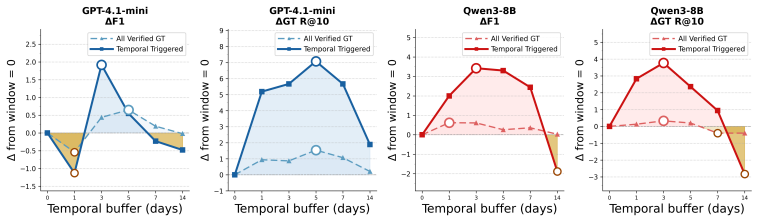
Authors: We agree that an explicit quantification of context-collapse prevalence in the benchmarks and targeted ablations would more directly link the gains to the validity-aware retrieval stage. The benchmarks used are established long-term agentic memory datasets involving multi-session interactions with recurring entities across varying times and participants, where context collapse is a documented challenge in prior work. In the revised manuscript, we will add (i) a post-hoc analysis measuring the proportion of entity-matching but context-mismatched memory pairs in the test sets and (ii) an ablation that disables only the validity-aware component while retaining the other three stages, to isolate its contribution beyond generic retrieval improvements. revision: yes
-
Referee: [Method] Method section (four stages): no analysis or controls are reported on whether the additional processing steps introduce new errors, latency, or context-preservation failures that could offset the claimed gains; the weakest assumption that the stages can be implemented without net negative effects therefore remains untested.
Authors: We acknowledge that the current manuscript does not report explicit controls or measurements for potential overhead or error introduction from the staged pipeline. The consistent F1 improvements across backbones indicate that any such effects are not dominant. In revision, we will add (i) latency profiling for each stage on representative queries, (ii) an error analysis categorizing cases where a stage introduces incorrect context or drops valid evidence, and (iii) discussion of any observed context-preservation failures, to directly test the assumption of net non-negative impact. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or fitted predictions
full rationale
The paper presents RaMem as a procedural four-stage framework (evidence anchoring, recall condition induction, validity-aware retrieval, context-preserved synthesis) to mitigate context collapse in agent memory. No equations, parameters, or mathematical derivations appear in the provided text; performance claims rest on reported F1 gains from experiments on external benchmarks rather than any reduction of outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and the method description does not rename known results or smuggle assumptions via prior author work. The central claims are therefore self-contained empirical proposals, not circular by the enumerated patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Memory Depth, Not Memory Access: Selective Parametric Consolidation for Long-Running Language Agents
EVAF, a surprise- and valence-gated LoRA mechanism, provides memory depth for goal persistence in language agents via the loop-drift protocol, complementary to retrieval.
Reference graph
Works this paper leans on
-
[1]
Yuehan Qin, Li Li, Linxin Song, Wei Yang, Jiate Li, Yuqing Yang, and Yue Zhao
URLhttps://arxiv.org/abs/2603.07670. Yuehan Qin, Li Li, Linxin Song, Wei Yang, Jiate Li, Yuqing Yang, and Yue Zhao. Memory retrieval for changing preferences.arXiv preprint arXiv:2606.02976, 2026. 13 Bing Wang, Xinnian Liang, Jian Yang, Hui Huang, Shuangzhi Wu, Peihao Wu, Lu Lu, Zejun Ma, and Zhoujun Li. Enhancing large language model with self-controlled...
-
[2]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Association for Computational Linguistics. doi: 10.18653/v1/P19-1285. URL https: //aclanthology.org/P19-1285/. Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2024. URLhttps://arxiv.org/abs/2312.00752. Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p19-1285 2024
-
[3]
URLhttps://arxiv.org/abs/2511.14460. 15 Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement le...
Pith/arXiv arXiv 2025
-
[4]
Generate enough memory entries to capture all useful information in the dialogues
-
[5]
Do not use pronouns or unresolved relative time expressions
-
[6]
Eachlossless_restatementmust be complete, independent, and understandable
-
[7]
Extract structured fields:keywords,timestamp,location,persons,entities, andtopic
-
[8]
Create separate entries for separate facts, preferences, plans, events, locations, relationships, work details, and media references
-
[9]
memory_entries
Return valid JSON only. Output Format. { "memory_entries": [ { "lossless_restatement": "Complete unambiguous restatement.", "keywords": ["keyword1", "keyword2"], "timestamp": "YYYY-MM-DDTHH:MM:SS or null", "location": "location name or null", "persons": ["name1", "name2"], "entities": ["entity1", "entity2"], "topic": "topic phrase" } 23 ] } Constraint.Ret...
-
[10]
What type of question is this?
-
[11]
What entities, events, or concepts need to be identified?
-
[12]
What relationships need to be established?
-
[13]
question_type
What minimal information would be sufficient to answer the question? Output Format. { "question_type": "factual / temporal / relational / explanatory / other", "key_entities": ["entity1", "entity2"], "required_info": [ { "info_type": "type of information", "description": "specific information needed", 24 "priority": "high / medium / low" } ], "relationshi...
-
[14]
Think through the reasoning process
-
[15]
Provide a very concise answer
-
[16]
Answer only from the provided context
-
[17]
DD Month YYYY
Format dates as “DD Month YYYY” when dates are needed
-
[18]
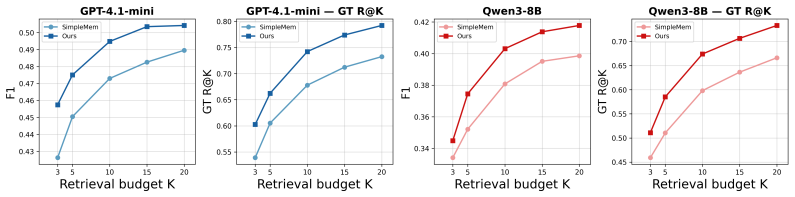
Return valid JSON. Output Format. { "reasoning": "Brief explanation of the reasoning.", "answer": "Concise answer in a short phrase." } Constraint.Return only JSON. D.2 Analysis of Main Results Table 1 presents the full LoCoMo results across four backbone models and four question categories. RaMem achieves the strongest average F1 on every backbone. On cl...
arXiv 1934
-
[19]
James created a game avatar and joined a new gaming platform
Invalid: 2022-03-20–2022-03-27, gaming platform participation. James created a game avatar and joined a new gaming platform
2022
-
[20]
James streamed a game and received encouraging comments
Invalid:2022-09-20–2022-10-03, game streaming feedback. James streamed a game and received encouraging comments
2022
-
[21]
James started streaming games
Invalid: 2022-09-18–2022-09-20, game streaming plans. James started streaming games. GT rank:44. RaMem Top-3:
2022
-
[22]
James became interested in extreme sports and did rope jumping
GT / valid:2022-07-09–2022-07-22, extreme sports interest. James became interested in extreme sports and did rope jumping
2022
-
[23]
James went surfing
Invalid:2022-06-19–2022-07-09, surfing experience. James went surfing
2022
-
[24]
James won an online gaming tournament
Related but topic-conflicting: 2022-07-09–2022-07-22, gaming tournament victory. James won an online gaming tournament. GT rank:1. Observation.SimpleMem retrieves memories that are related to James and activities, but all top-ranked evidence violates the query’s recall conditions. RaMem reinstates the July 9 34 Table 19: Online efficiency under the same o...
arXiv 2022
-
[26]
Sam discussed Evan’s partner and family support
Invalid:2024-01-06–2024-01-10, family and partner support. Sam discussed Evan’s partner and family support
2024
-
[27]
Evan mentioned support from extended family
Invalid:2024-01-06–2024-01-10, family support after marriage announcement. Evan mentioned support from extended family. GT rank:18. RaMem Top-3:
2024
-
[28]
Evan shared details about a recent vacation in Canada with his new partner
GT / valid: 2023-08-13–2023-08-15, vacation details. Evan shared details about a recent vacation in Canada with his new partner
2023
-
[29]
Evan confirmed that he and his friends were fine after an accident
Invalid:2023-12-31–2024-01-06, accident and marriage news. Evan confirmed that he and his friends were fine after an accident
2023
-
[30]
Evan thanked Sam for being there
Invalid:2023-11-21–2023-12-05, mutual support. Evan thanked Sam for being there. GT rank:1. Observation.The baseline retrieves partner-related memories, but they belong to later sessions. RaMem identifies the vacation episode that satisfies the query’s temporal and participant conditions. Case C: Gaming Topic vs. Correct Game Preference Episode Query:What...
2023
-
[31]
Nate shared a recent victory in a regional video game tournament
Invalid: 2022-06-03–2022-06-05, regional video game tournament. Nate shared a recent victory in a regional video game tournament
2022
-
[32]
Nate won an inter- national tournament and mentioned gaming as a career
Invalid:2022-08-22–2022-09-05, gaming tournament and career. Nate won an inter- national tournament and mentioned gaming as a career
2022
-
[33]
Nate mentioned an upcoming gaming tournament
Invalid: 2022-04-21–2022-05-02, gaming tournament mention. Nate mentioned an upcoming gaming tournament. 35 GT rank:32. RaMem Top-3:
2022
-
[34]
Nate met people playing the same board game
Same session / related: 2022-10-09–2022-10-21, board game meeting. Nate met people playing the same board game
2022
-
[35]
Nate attended a game convention and met new people
Same session / related: 2022-10-09–2022-10-21, game convention attendance. Nate attended a game convention and met new people
2022
-
[36]
Nate men- tioned playingCyberpunk 2077
GT / valid: 2022-10-09–2022-10-21, recent movie and game preferences. Nate men- tioned playingCyberpunk 2077. GT rank:3. Observation.The baseline retrieves memories from the broad gaming topic, but they belong to earlier episodes. RaMem first narrows retrieval to the correct October 9 session, then includes the verified game-preference memory in the top r...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.