OmniGen-AR: AutoRegressive Any-to-Image Generation
Pith reviewed 2026-06-27 17:03 UTC · model grok-4.3
The pith
A single autoregressive model generates images from text, depth, segmentation, or prior images using one shared visual tokenizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
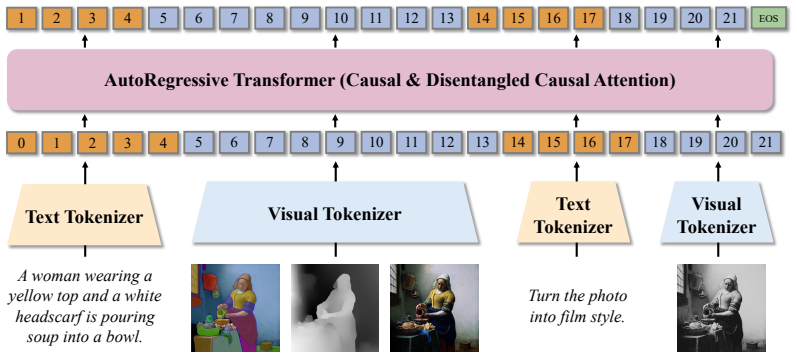
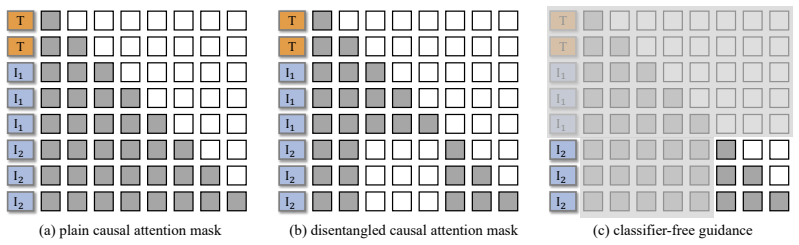
OmniGen-AR is presented as a unified autoregressive framework for Any-to-Image generation. By discretizing various visual conditions through a shared visual tokenizer and text prompts with a text tokenizer, the model supports a broad spectrum of conditional inputs within a single model, including text-to-image generation, segmentation-to-image, depth-to-image, image editing, frame prediction, and text-to-video generation. Disentangled Causal Attention separates the full-sequence causal mask into condition causal attention and content causal attention, serving as a training-time regularizer without affecting standard next-token prediction during inference.
What carries the argument
Disentangled Causal Attention (DCA), which separates the causal mask into condition and content parts to prevent leakage while acting only as a training regularizer.
If this is right
- One model architecture performs text-to-image, spatial-signal-to-image, and visual-context tasks without retraining or separate heads.
- Disentangled Causal Attention keeps inference unchanged while regularizing training against condition leakage.
- The design extends naturally to frame prediction for video and to image editing from visual context.
- Competitive or leading results appear across text-to-image and video benchmarks under the unified setup.
Where Pith is reading between the lines
- The uniform tokenization could allow a single generation pass to accept mixed conditions, such as text plus depth, without extra engineering.
- If the tokenizer generalizes, the same approach might apply to additional modalities like sketches or 3D projections in future extensions.
- Simpler deployment pipelines become possible when one checkpoint replaces several task-specific generators.
Load-bearing premise
A shared visual tokenizer can discretize diverse condition types such as depth maps and segmentation while retaining enough detail for accurate image synthesis.
What would settle it
Generate an image from a provided depth map condition and check whether the output depth structure matches the input map within a small error margin; systematic mismatch would show the tokenizer or attention failed to preserve the signal.
Figures



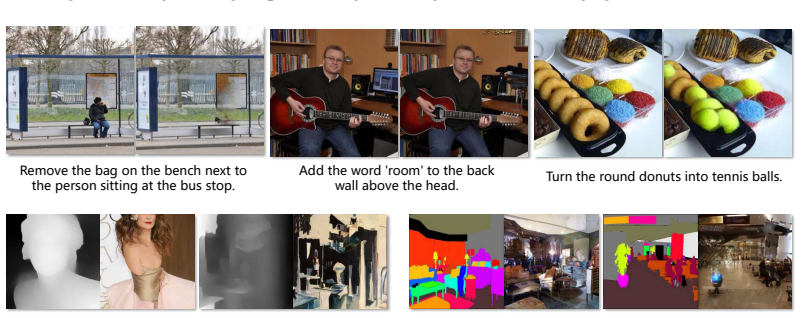
read the original abstract
Autoregressive (AR) models have demonstrated strong potential in visual generation, offering superior performance with simple architectures and optimization objectives. However, existing methods are typically limited to single-modality conditions, e.g., text, restricting their applicability in real-world scenarios that demand image synthesis from diverse controls. In this work, we present OmniGen-AR, a unified autoregressive framework for Any-to-Image generation. By discretizing various visual conditions through a shared visual tokenizer and text prompts with a text tokenizer, OmniGen-AR supports a broad spectrum of conditional inputs within a single model, including text (text-to-image generation), spatial signals (segmentation-to-image and depth-to-image), and visual context (image editing, frame prediction, and text-to-video generation). To mitigate the risk of information leakage from condition tokens to content tokens, we introduce Disentangled Causal Attention (DCA), which separates the full-sequence causal mask into condition causal attention and content causal attention. It serves as a training-time regularizer without affecting the standard next-token prediction during inference. With this design, OmniGen-AR achieves new state-of-the-art or at least competitive results across a range of benchmark, e.g., 0.63 on GenEval and 80.02 on VBench, demonstrating its effectiveness in flexible and high-fidelity visual generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OmniGen-AR, a unified autoregressive framework for any-to-image generation. It discretizes diverse visual conditions (depth, segmentation, video frames) via a shared visual tokenizer and text via a text tokenizer, enabling a single model to handle text-to-image, segmentation-to-image, depth-to-image, image editing, frame prediction, and text-to-video. Disentangled Causal Attention (DCA) is introduced to separate condition and content causal masks during training as a regularizer that leaves standard inference unchanged. The work claims new state-of-the-art or competitive results on benchmarks including 0.63 on GenEval and 80.02 on VBench.
Significance. If the experimental claims hold after proper validation, the approach would offer a meaningful unification of conditional visual generation tasks under a single autoregressive architecture, reducing the need for modality-specific models while maintaining high fidelity.
major comments (2)
- Abstract: the benchmark scores (0.63 on GenEval, 80.02 on VBench) are asserted without any description of experimental protocol, baselines, training details, or implementation of the shared visual tokenizer and DCA, rendering the performance claims unverifiable from the supplied text.
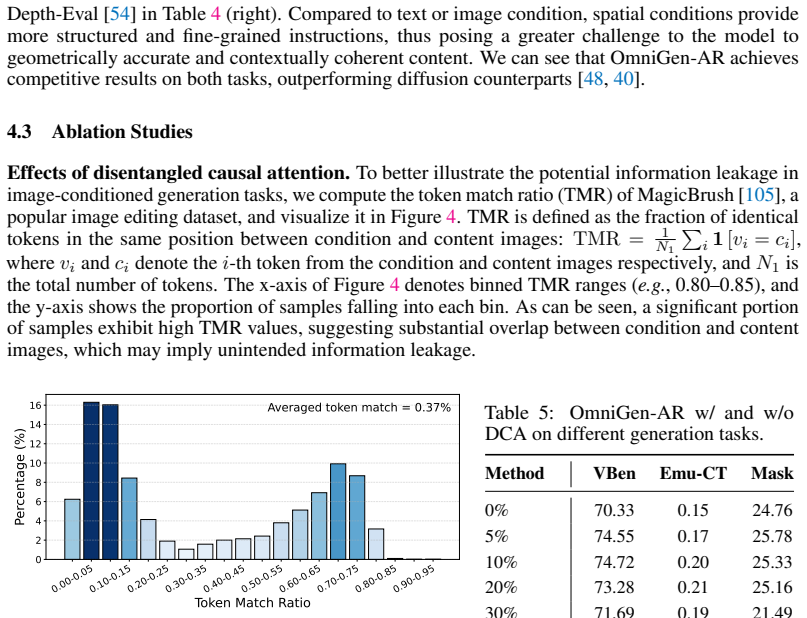
- Method section (DCA and shared tokenizer): the central claims rest on the assumptions that a single visual tokenizer losslessly discretizes depth maps, segmentation masks, and video frames into a shared codebook and that DCA prevents leakage without side-effects, yet no per-modality reconstruction metrics, codebook analysis, or ablation comparing DCA to standard causal attention are reported.
minor comments (1)
- Notation for the condition causal attention mask versus content causal attention mask should be defined explicitly with an equation or diagram to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and outline concrete revisions to improve clarity and completeness of the experimental claims.
read point-by-point responses
-
Referee: Abstract: the benchmark scores (0.63 on GenEval, 80.02 on VBench) are asserted without any description of experimental protocol, baselines, training details, or implementation of the shared visual tokenizer and DCA, rendering the performance claims unverifiable from the supplied text.
Authors: We agree that the abstract, as currently written, is too terse to allow verification of the reported numbers. The full manuscript contains the experimental protocol, baselines, and implementation details in Sections 4 and 5, but these are not referenced or summarized in the abstract. In the revised version we will add one concise sentence to the abstract that states the training data scale, the primary baselines, and that all results use the shared tokenizer and DCA described in Section 3. revision: yes
-
Referee: Method section (DCA and shared tokenizer): the central claims rest on the assumptions that a single visual tokenizer losslessly discretizes depth maps, segmentation masks, and video frames into a shared codebook and that DCA prevents leakage without side-effects, yet no per-modality reconstruction metrics, codebook analysis, or ablation comparing DCA to standard causal attention are reported.
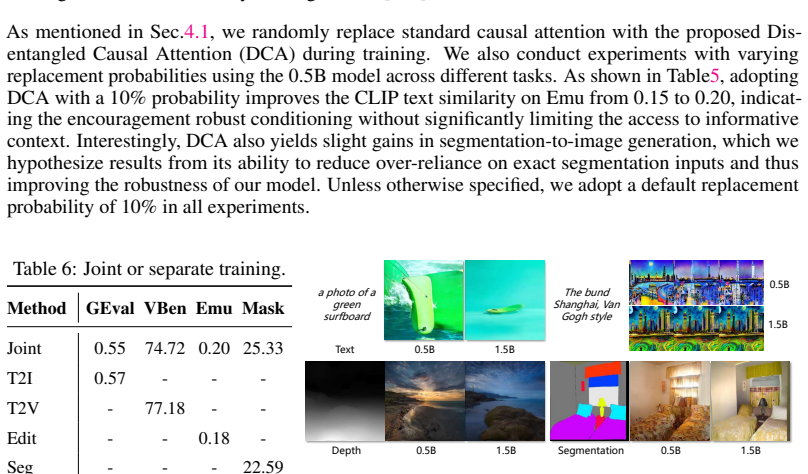
Authors: The manuscript describes the shared visual tokenizer (Section 3.2) and DCA (Section 3.3) but does not include the requested quantitative validation. We will add a new subsection (or appendix) containing: (i) per-modality reconstruction metrics (PSNR/SSIM/FID) for depth, segmentation, and video frames, (ii) codebook utilization statistics, and (iii) an ablation table comparing DCA against standard causal attention on GenEval and a subset of VBench tasks. These additions will directly test the lossless-discretization and no-leakage assumptions. revision: yes
Circularity Check
No circularity; claims rest on external benchmark scores
full rationale
The paper presents architectural choices (shared visual tokenizer, DCA) whose value is asserted via empirical results on independent benchmarks (GenEval 0.63, VBench 80.02). No equations, self-definitions, or fitted parameters are shown reducing to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Autoregressive next-token prediction remains effective when inputs from multiple modalities are discretized into a shared token space.
- ad hoc to paper Separating condition causal attention from content causal attention during training prevents leakage while leaving standard inference unchanged.
invented entities (2)
-
Disentangled Causal Attention (DCA)
no independent evidence
-
Shared visual tokenizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Pith/arXiv arXiv 2024
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[4]
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network.arXiv preprint arXiv:2504.13181, 2025
Pith/arXiv arXiv 2025
-
[5]
Brooks, A
T. Brooks, A. Holynski, and A. A. Efros. Instructpix2pix: Learning to follow image editing instructions. InCVPR, 2023
2023
-
[6]
J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier, and A. Zisserman. A short note about kinetics-600.arXiv preprint arXiv:1808.01340, 2018
Pith/arXiv arXiv 2018
-
[7]
Changpinyo, P
S. Changpinyo, P. Sharma, N. Ding, and R. Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InCVPR, 2021
2021
-
[8]
H. Chen, Y . Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y . Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, 2024
2024
-
[9]
J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y . Wu, Z. Wang, J. Kwok, P. Luo, H. Lu, et al. Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
Pith/arXiv arXiv 2023
-
[10]
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever. Generative pretraining from pixels. InICML, 2020
2020
-
[11]
T.-S. Chen, A. Siarohin, W. Menapace, E. Deyneka, H.-w. Chao, B. E. Jeon, Y . Fang, H.-Y . Lee, J. Ren, M.-H. Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InCVPR, 2024
2024
-
[12]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024
2024
-
[13]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis. InNeurIPS, 2021
2021
-
[14]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In ICLR, 2024
2024
-
[15]
Esser, R
P. Esser, R. Rombach, and B. Ommer. Taming transformers for high-resolution image synthesis. InCVPR, 2021
2021
-
[16]
N. et. al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[17]
Z. Fu, W. Lam, A. M.-C. So, and B. Shi. A theoretical analysis of the repetition problem in text generation. InAAAI, 2021
2021
-
[18]
S. Ge, T. Hayes, H. Yang, X. Yin, G. Pang, D. Jacobs, J.-B. Huang, and D. Parikh. Long video generation with time-agnostic vqgan and time-sensitive transformer. InECCV, 2022
2022
-
[19]
Y . Ge, S. Zhao, C. Li, Y . Ge, and Y . Shan. Seed-data-edit technical report: A hybrid dataset for instructional image editing.arXiv preprint arXiv:2405.04007, 2024. 10
arXiv 2024
-
[20]
Ghosh, H
D. Ghosh, H. Hajishirzi, and L. Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment. InNeurIPS, 2024
2024
-
[21]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets. InNeurIPS, 2014
2014
-
[22]
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
Pith/arXiv arXiv 2023
-
[23]
J. Han, J. Liu, Y . Jiang, B. Yan, Y . Zhang, Z. Yuan, B. Peng, and X. Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. InCVPR, 2025
2025
-
[24]
T. Henighan, J. Kaplan, M. Katz, M. Chen, C. Hesse, J. Jackson, H. Jun, T. B. Brown, P. Dhariwal, S. Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701, 2020
Pith/arXiv arXiv 2010
-
[25]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[26]
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[27]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
Pith/arXiv arXiv 2022
-
[28]
open-sora-pexels-45k
hpcai tech. open-sora-pexels-45k. https://huggingface.co/datasets/hpcai-tech/ open-sora-pexels-45k, 2025
2025
-
[29]
Huang, Y
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
2024
-
[30]
X. Ju, Y . Gao, Z. Zhang, Z. Yuan, X. Wang, A. Zeng, Y . Xiong, Q. Xu, and Y . Shan. Miradata: A large-scale video dataset with long durations and structured captions. InNeurIPS, 2024
2024
-
[31]
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[32]
D. P. Kingma, M. Welling, et al. Auto-encoding variational bayes, 2013
2013
-
[33]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InICCV, 2023
2023
-
[34]
Kondratyuk, L
D. Kondratyuk, L. Yu, X. Gu, J. Lezama, J. Huang, G. Schindler, R. Hornung, V . Birodkar, J. Yan, M.-C. Chiu, et al. Videopoet: A large language model for zero-shot video generation. InICML, 2024
2024
-
[35]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[36]
Kuznetsova, H
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.IJCV, 2020
2020
-
[37]
H. Li, T. Lan, Z. Fu, D. Cai, L. Liu, N. Collier, T. Watanabe, and Y . Su. Repetition in repetition out: Towards understanding neural text degeneration from the data perspective. InNeurIPS, 2023
2023
-
[38]
J. Li, D. Li, C. Xiong, and S. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML, 2022
2022
-
[39]
T. Li, Y . Tian, H. Li, M. Deng, and K. He. Autoregressive image generation without vector quantization. InNeurIPS, 2024. 11
2024
-
[40]
Y . Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y . J. Lee. Gligen: Open-set grounded text-to-image generation. InCVPR, 2023
2023
-
[41]
Z. Li, T. Cheng, S. Chen, P. Sun, H. Shen, L. Ran, X. Chen, W. Liu, and X. Wang. Controlar: Controllable image generation with autoregressive models. InICLR, 2025
2025
-
[42]
B. Lin, Y . Ge, X. Cheng, Z. Li, B. Zhu, S. Wang, X. He, Y . Ye, S. Yuan, L. Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024
Pith/arXiv arXiv 2024
-
[43]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. InCVPR, 2024
2024
-
[44]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InNeuIPS, 2023
2023
-
[45]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[46]
Megalith-huggingface
madebyollin. Megalith-huggingface. https://huggingface.co/datasets/ madebyollin/megalith-10m, 2024
2024
-
[47]
Mokady, A
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, and D. Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023
2023
-
[48]
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InAAAI, 2024
2024
-
[49]
J. Mu, N. Vasconcelos, and X. Wang. Editar: Unified conditional generation with autoregres- sive models. InCVPR, 2025
2025
-
[50]
K. Nan, R. Xie, P. Zhou, T. Fan, Z. Yang, Z. Chen, X. Li, J. Yang, and Y . Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371, 2024
Pith/arXiv arXiv 2024
-
[51]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InCVPR, 2023
2023
-
[52]
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rom- bach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[53]
synthetic-dataset-1m-dalle3-high-quality- captions
ProGamerGov. synthetic-dataset-1m-dalle3-high-quality- captions. https://huggingface.co/datasets/ProGamerGov/ synthetic-dataset-1m-dalle3-high-quality-captions, 2022
2022
-
[54]
C. Qin, S. Zhang, N. Yu, Y . Feng, X. Yang, Y . Zhou, H. Wang, J. C. Niebles, C. Xiong, S. Savarese, et al. Unicontrol: A unified diffusion model for controllable visual generation in the wild.arXiv preprint arXiv:2305.11147, 2023
arXiv 2023
-
[55]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InICML, 2021
2021
-
[56]
Radford, K
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, et al. Improving language understanding by generative pre-training.OpenAI Blog, 2018
2018
-
[57]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners.OpenAI Blog, 2019
2019
-
[58]
R. Rakhimov, D. V olkhonskiy, A. Artemov, D. Zorin, and E. Burnaev. Latent video transformer. arXiv preprint arXiv:2006.10704, 2020
arXiv 2006
-
[59]
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022. 12
Pith/arXiv arXiv 2022
-
[60]
Ramesh, M
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. InICML, 2021
2021
-
[61]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[62]
Sharma, N
P. Sharma, N. Ding, S. Goodman, and R. Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InACL, 2018
2018
-
[63]
Sheynin, A
S. Sheynin, A. Polyak, U. Singer, Y . Kirstain, A. Zohar, O. Ashual, D. Parikh, and Y . Taigman. Emu edit: Precise image editing via recognition and generation tasks. InCVPR, 2024
2024
-
[64]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InICLR, 2021
2021
-
[65]
K. Sun, J. Pan, Y . Ge, H. Li, H. Duan, X. Wu, R. Zhang, A. Zhou, Z. Qin, Y . Wang, et al. Journeydb: A benchmark for generative image understanding. InNeurIPS, 2023
2023
-
[66]
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
Pith/arXiv arXiv 2024
-
[67]
C. Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Pith/arXiv arXiv 2024
-
[68]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[69]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.arXiv preprint arXiv:2404.02905, 2024
arXiv 2024
-
[70]
R. Tian, Q. Dai, J. Bao, K. Qiu, Y . Yang, C. Luo, Z. Wu, and Y .-G. Jiang. Reducio! generating 1k video within 16 seconds using extremely compressed motion latents. InICCV, 2025
2025
-
[71]
R. Tian, M. Gao, M. Xu, J. Hu, J. Lu, Z. Wu, Y . Yang, and A. Dehghan. Unigen: Enhanced training & test-time strategies for unified multimodal understanding and generation. In NeurIPS, 2025
2025
-
[72]
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[73]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InCVPR, 2023
2023
-
[74]
van den Oord and N
A. van den Oord and N. Kalchbrenner. Pixel rnn. InICML, 2016
2016
-
[75]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017
2017
-
[76]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
- [77]
-
[78]
A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[79]
H. Wang, S. Suri, Y . Ren, H. Chen, and A. Shrivastava. Larp: Tokenizing videos with a learned autoregressive generative prior. InICLR, 2025
2025
-
[80]
J. Wang, D. Chen, Z. Wu, C. Luo, L. Zhou, Y . Zhao, Y . Xie, C. Liu, Y .-G. Jiang, and L. Yuan. Omnivl: One foundation model for image-language and video-language tasks. InNeurIPS, 2022. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.