Mechanism-Driven Monitors for Preemptive Detection of LLM Training Instability
Pith reviewed 2026-06-29 04:04 UTC · model grok-4.3
The pith
Monitors from attention and MoE functional roles detect LLM training instability thousands of steps before loss diverges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
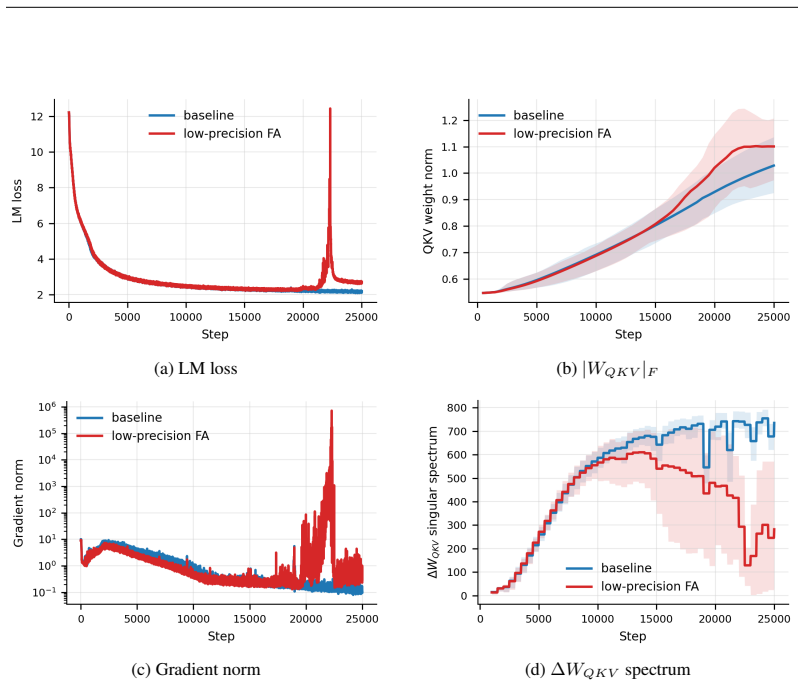
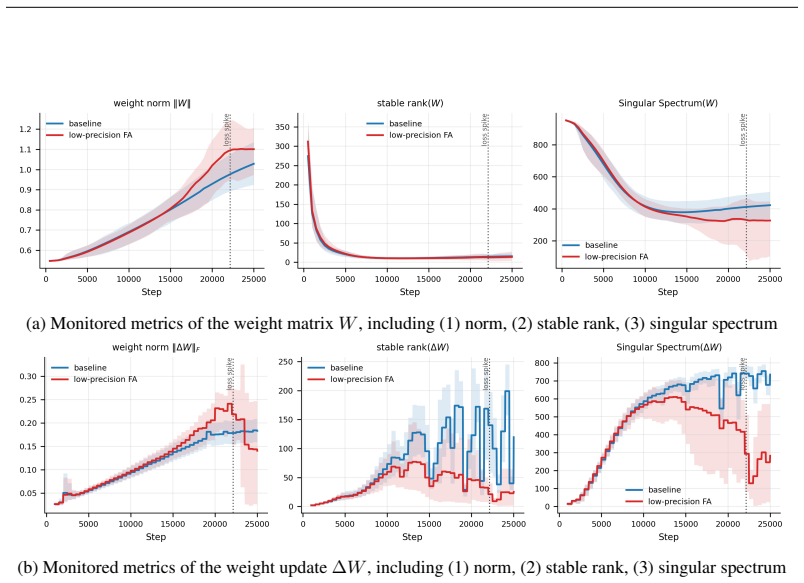
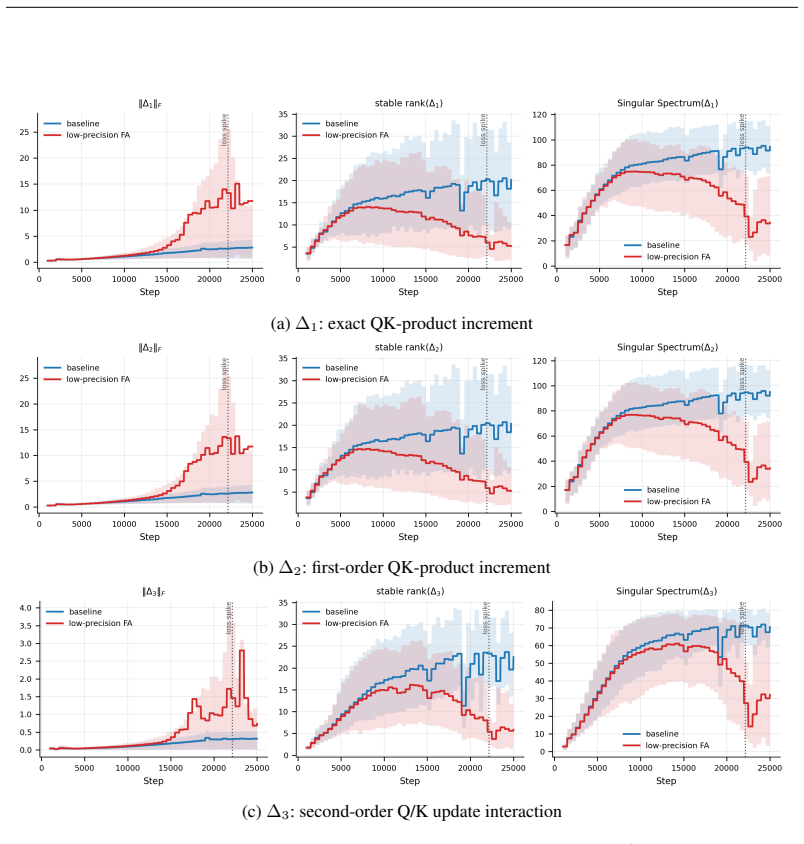
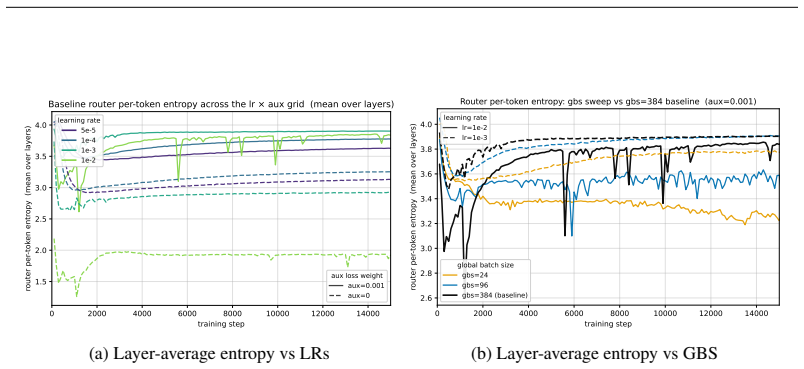
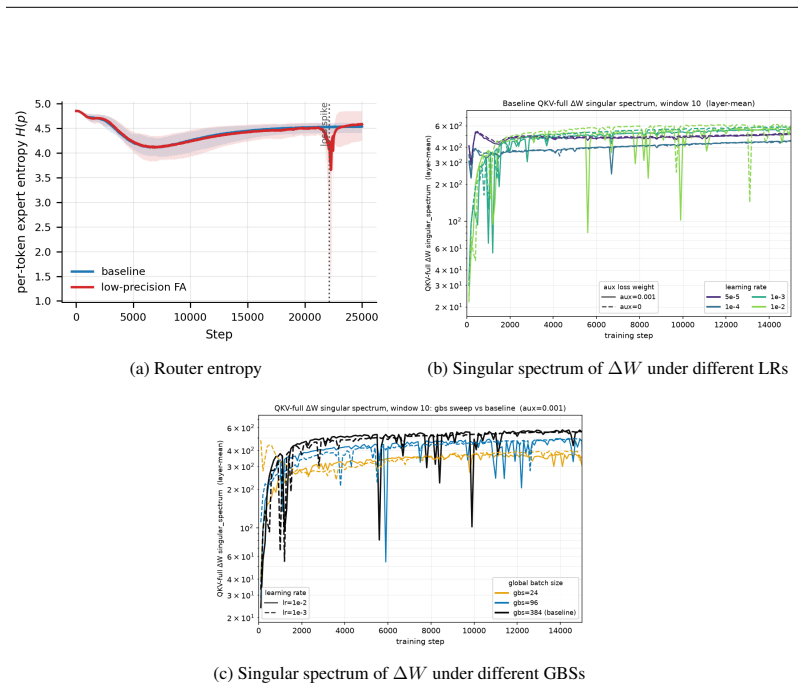
By deriving monitors from the functional role of each critical module and from the earliest computational sites where failures produce measurable signatures, the authors demonstrate that signals such as the spectral entropy of the QK bilinear decomposition in attention and role-based indicators for MoE routers provide distinct early warnings for different instability types, triggering thousands of steps before loss divergence in fault-injection experiments.
What carries the argument
Spectral entropy of the QK bilinear decomposition for attention and role-derived indicators for MoE routers, which capture abnormalities at the onset of faults.
If this is right
- Distinct signatures appear for low-precision attention faults, large learning-rate faults, and combined faults.
- These monitors trigger thousands of steps before loss divergence.
- Monitoring starts at the earliest computational sites where failures affect the modules.
- The approach applies to both attention and mixture-of-experts components.
Where Pith is reading between the lines
- Integrating these monitors could enable automatic training pauses or hyperparameter adjustments in real time.
- Similar mechanism-driven monitors might be developed for other components like layer norms or optimizers.
- The distinct signatures could help diagnose the specific cause of instability.
- Extending the method to full-scale production training runs would test its practicality at frontier scales.
Load-bearing premise
The assumption that monitors based on each module's functional role will produce measurable signatures precisely at the earliest sites of failure.
What would settle it
A training run where a numerical or hyperparameter fault causes instability but the proposed internal monitors remain normal until after loss divergence begins.
Figures
read the original abstract
Frontier large language model training consumes massive accelerator fleets and long wall-clock computation, making stability failures costly when they occur. After a numerical or a hyperparameter fault has already destabilized the training dynamics, it may continue for thousands of steps while loss and gradient norms still appear normal. We study mechanism-driven detection of training instability by deriving internal monitors from the functional role of each critical module and from the earliest computational sites where failures are expected to produce measurable signatures. For low-precision flash attention, we monitor the spectral entropy of a QK bilinear decomposition, whose first-order term becomes abnormal before the loss fully collapses. For MoE routers, we derive indicators from their role in expert selection. Our fault-injection experiments on low-precision attention, large learning-rate, and combined faults show that these signals provide distinct signatures for different failures, triggering thousands of steps before loss divergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mechanism-driven internal monitors, derived from the functional roles of critical LLM training modules (e.g., spectral entropy of the QK bilinear decomposition for low-precision flash attention and expert-selection indicators for MoE routers), can provide distinct signatures that detect instabilities thousands of steps before loss divergence. This is supported by fault-injection experiments on low-precision attention faults, large learning-rate faults, and combined faults.
Significance. If the central claim holds with rigorous controls, the work offers a practical advance for reducing wasted compute in frontier LLM training by enabling preemptive intervention. The mechanism-driven framing, if shown to yield interpretable and specific signals rather than generic statistics, strengthens the contribution over purely empirical monitoring approaches. The use of controlled fault injection is a methodological strength for isolating failure modes.
major comments (2)
- [Abstract] Abstract: the central claim that the monitors are derived from 'the earliest computational sites where failures are expected to produce measurable signatures' is load-bearing but unsupported, as the described experiments only establish that the signals precede loss divergence; no comparison to alternative internal statistics (from the same modules or others) is mentioned to verify earliness.
- [Abstract] Abstract: the experimental outcome is stated without derivation details, quantitative thresholds for 'abnormal', statistical tests, or baseline controls, so it is not possible to assess whether the data support the 'thousands of steps' advance-warning claim or the distinct-signature claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly quantified the advance warning (e.g., mean steps or range) and named the specific MoE indicators.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The comments correctly identify areas where the current presentation of claims requires additional support or clarification. We outline revisions below to strengthen the manuscript while preserving its core contribution on mechanism-driven monitors.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the monitors are derived from 'the earliest computational sites where failures are expected to produce measurable signatures' is load-bearing but unsupported, as the described experiments only establish that the signals precede loss divergence; no comparison to alternative internal statistics (from the same modules or others) is mentioned to verify earliness.
Authors: The derivation of the monitors begins from the functional roles of the modules (QK bilinear form in low-precision attention; expert selection logic in MoE routers) and the points at which numerical or routing faults first alter internal computations. The fault-injection results establish that the chosen signals diverge from their stable regimes thousands of steps before loss, but the manuscript does not present head-to-head comparisons against other candidate statistics computed from the same modules. We will add such comparisons (e.g., against raw attention entropy, router load variance, and gradient-norm variants) in a new subsection of the results and revise the abstract wording to distinguish theoretical motivation from empirical earliness evidence. revision: yes
-
Referee: [Abstract] Abstract: the experimental outcome is stated without derivation details, quantitative thresholds for 'abnormal', statistical tests, or baseline controls, so it is not possible to assess whether the data support the 'thousands of steps' advance-warning claim or the distinct-signature claim.
Authors: The abstract is intentionally concise. The full manuscript contains the module-level derivations, the precise definitions of the spectral-entropy and expert-selection indicators, the fault-injection protocol, and the step counts at which each monitor crosses its threshold. To make these elements evaluable from the abstract itself, we will insert a short quantitative clause reporting the median lead time, the threshold rule (e.g., >3σ deviation sustained for k steps), and mention of the control runs with no injected faults. A supplementary table summarizing statistical tests and baseline statistics will also be added to the main text. revision: yes
Circularity Check
No significant circularity; monitors derived from roles and validated independently
full rationale
The derivation starts from module functional roles (e.g., QK bilinear decomposition for attention, expert selection for MoE) and produces candidate monitors whose behavior is then checked via separate fault-injection experiments on low-precision attention, large LR, and combined faults. These experiments supply an external benchmark (pre-loss-divergence triggering) that is not constructed from the monitor definitions themselves. No equations, self-citations, fitted parameters, or uniqueness theorems appear in the supplied text that would reduce the claimed earliest-site property to a tautology or prior self-result. The argument therefore remains self-contained against the experimental outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-attention networks localize when qk- eigenspectrum concentrates
Han Bao, Ryuichiro Hataya, and Ryo Karakida. Self-attention networks localize when qk- eigenspectrum concentrates. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
2024
-
[2]
Srinadh Bhojanapalli, Chulhee Yun, Ankit Singh Rawat, Sashank J
URLhttps:// openreview.net/forum?id=aRZjRj41WQ. Srinadh Bhojanapalli, Chulhee Yun, Ankit Singh Rawat, Sashank J. Reddi, and Sanjiv Kumar. Low-rank bottleneck in multi-head attention models. InProceedings of the 37th Interna- tional Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, vol- ume 119 ofProceedings of Machine Learning Res...
2020
-
[4]
URLhttps://arxiv.org/abs/2603.15031. Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, and Wenfeng Liang. Conditional memory via scalable lookup: A new axis of sparsity for large language models. ArXiv preprint, abs/2601.07372,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
URLhttps://arxiv.org/abs/2601.07372. L´ena¨ıc Chizat, Edouard Oyallon, and Francis R. Bach. On lazy training in differen- tiable programming. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Flo- rence d’Alch ´e-Buc, Emily B. Fox, and Roman Garnett (eds.),Advances in Neural In- formation Processing Systems 32: Annual Conference on Neural Informati...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
12 Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al
URLhttps://proceedings.neurips.cc/paper/2019/hash/ ae614c557843b1df326cb29c57225459-Abstract.html. 12 Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways,
2019
-
[7]
Cohen, Simran Kaur, Yuanzhi Li, J
Jeremy M. Cohen, Simran Kaur, Yuanzhi Li, J. Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[8]
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme Ruiz, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Ga...
2023
-
[9]
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas
URL https://proceedings.mlr.press/v202/dehghani23a.html. Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, v...
2021
-
[10]
Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang
URLhttp://proceedings.mlr.press/v139/dong21a.html. Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. Maskllm: Learnable semi-structured sparsity for large language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, An- gela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang...
2024
-
[11]
Wenyi Fang, Hao Zhang, Ziyu Gong, Longbin Zeng, Xuhui Lu, Biao Liu, Xiaoyu Wu, Yang Zheng, Zheng Hu, and Xun Zhang
URLhttp://papers.nips.cc/paper_files/paper/2024/hash/ 0e9a05f5ce62284c91e4a33498899124-Abstract-Conference.html. Wenyi Fang, Hao Zhang, Ziyu Gong, Longbin Zeng, Xuhui Lu, Biao Liu, Xiaoyu Wu, Yang Zheng, Zheng Hu, and Xun Zhang. A survey of metrics to enhance training dependability in large lan- guage models. In2023 IEEE 34th International Symposium on So...
2024
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth Inter- national Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
2022
-
[13]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Cl ´ement Hongler, and Franck Gabriel. Neural tangent kernel: Convergence and generalization in neural networks. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicol `o Cesa-Bianchi, and Roman Garnett (eds.),Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2...
2018
-
[15]
URLhttps: //arxiv.org/abs/2601.16979. Kimi Team. Kimi k2: Open agentic intelligence,
-
[16]
Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl- Dickstein, and Jeffrey Pennington
Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl- Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelz- imer, Florence d’Alch ´e-Buc, Emily B. Fox, and Roman Garnett (eds.),Advances in Neu- ral Informat...
2019
-
[17]
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, et al
URLhttps://proceedings.neurips.cc/paper/2019/hash/ 0d1a9651497a38d8b1c3871c84528bd4-Abstract.html. Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, et al. Muon is scalable for LLM training,
2019
-
[18]
Dissecting query-key interac- tion in vision transformers
Xu Pan, Aaron Philip, Ziqian Xie, and Odelia Schwartz. Dissecting query-key interac- tion in vision transformers. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang (eds.),Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, Ne...
2024
-
[19]
Haiquan Qiu and Quanming Yao
URLhttp://papers.nips.cc/paper_files/paper/2024/hash/ 6216515a5e0b3257c49dcb1647e497d1-Abstract-Conference.html. Haiquan Qiu and Quanming Yao. Why low-precision transformer training fails: An analysis on flash attention,
2024
-
[20]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
2017
-
[21]
Liu, Lechao Xiao, Katie E
Mitchell Wortsman, Peter J. Liu, Lechao Xiao, Katie E. Everett, Alexander A. Alemi, Ben Adlam, John D. Co-Reyes, Izzeddin Gur, Abhishek Kumar, Roman Novak, Jeffrey Pennington, Jascha Sohl-Dickstein, Kelvin Xu, Jaehoon Lee, Justin Gilmer, and Simon Kornblith. Small-scale prox- ies for large-scale transformer training instabilities. InThe Twelfth Internatio...
2024
-
[23]
mHC: Manifold-Constrained Hyper-Connections
URLhttps: //arxiv.org/abs/2512.24880. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen3 technical report,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
doi: 10.1109/BigData50022.2020.9378171. David Yunis, Kumar Kshitij Patel, Samuel Wheeler, Pedro Savarese, Gal Vardi, Karen Livescu, Michael Maire, and Matthew R. Walter. Approaching deep learning through the spectral dynamics of weights,
-
[25]
GLM-130B: an open bilingual pre-trained model
Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. GLM-130B: an open bilingual pre-trained model. InThe Eleventh International Conference on Learning Representations, ICLR 2023...
2023
-
[26]
net/pdf?id=-Aw0rrrPUF
URLhttps://openreview. net/pdf?id=-Aw0rrrPUF. Shuangfei Zhai, Tatiana Likhomanenko, Etai Littwin, Dan Busbridge, Jason Ramapuram, Yizhe Zhang, Jiatao Gu, and Joshua M. Susskind. Stabilizing transformer training by preventing at- tention entropy collapse. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engel- hardt, Sivan Sabato, and Jonathan Sca...
2023
-
[27]
press/v202/zhai23a.html
URLhttps://proceedings.mlr. press/v202/zhai23a.html. Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory-efficient LLM training by gradient low-rank projection. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.