GROVE: Grounded Pedestrian Simulation via Natural Language for Interactive Social Robot Navigation
Pith reviewed 2026-06-25 21:20 UTC · model grok-4.3
The pith
GROVE turns natural language prompts into customizable, multi-scale pedestrian simulations for testing social robot navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
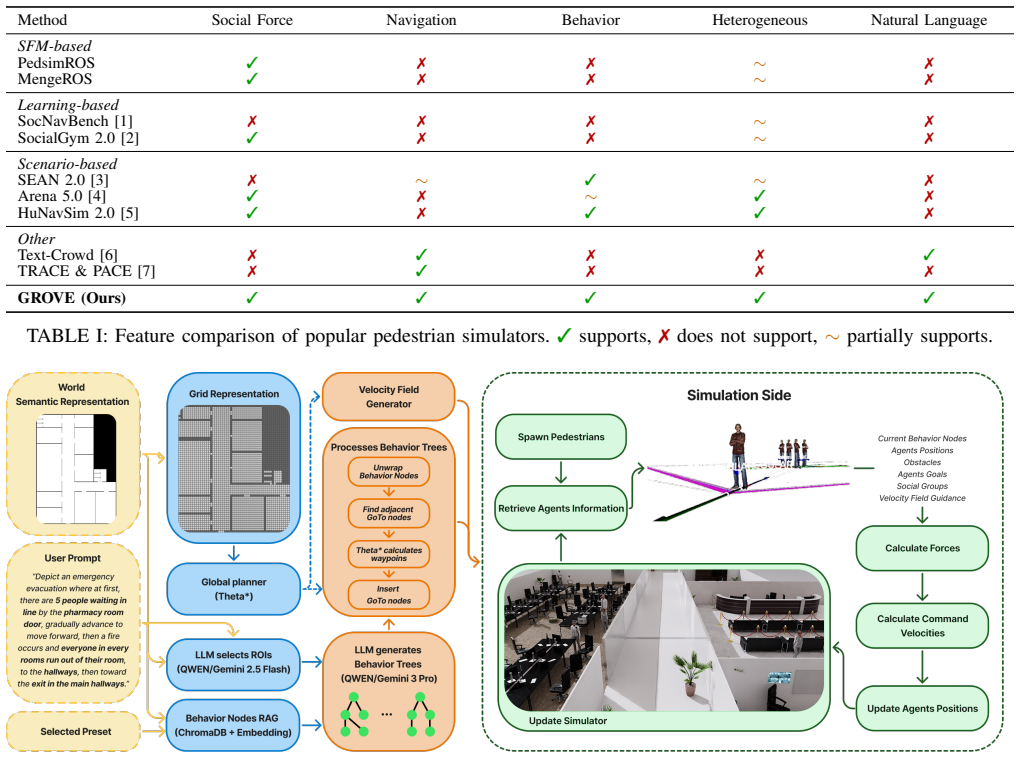
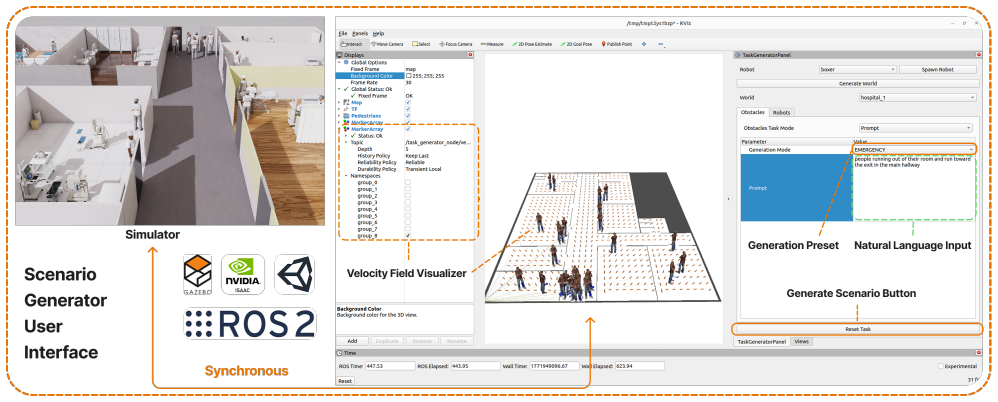
GROVE is a text-to-scenario system whose central mechanism is prompt-driven dynamic selection among state-of-the-art components for each temporal scale of pedestrian activity, yielding simulations that are directly embedded in Isaac Sim, Gazebo, and RViz and that exhibit greater behavioral diversity than prior fixed pedestrian engines.
What carries the argument
A prompt-conditioned multi-module pipeline that assigns and parameterizes separate state-of-the-art simulators for long-horizon human behavior, medium-horizon navigation, and short-horizon robot-social interactions.
If this is right
- Robot navigation algorithms can be trained or evaluated against a wider range of prompt-specified social situations without new data collection.
- The same text interface supports rapid iteration between emergency, queuing, and everyday crowd configurations.
- Direct integration into common simulators removes an extra translation step when moving policies from simulation to hardware.
Where Pith is reading between the lines
- The framework could serve as a test-bed generator for reinforcement-learning policies that must handle open-ended social contexts.
- Extending the prompt interface to accept live corrections during a simulation run would allow on-the-fly scenario adaptation.
- If the modular selection logic generalizes, similar text-driven orchestration might apply to other multi-agent simulation domains such as traffic or warehouse logistics.
Load-bearing premise
That a user's natural language description can reliably guide the selection and tuning of existing simulation techniques so that the combined output remains both realistic and internally consistent over long, medium, and short time horizons.
What would settle it
A side-by-side human rating study in which observers judge the behavioral realism and social appropriateness of crowds generated by GROVE versus manually authored baselines in the same three environments; consistent preference for the manual baselines would undermine the claim.
Figures

read the original abstract
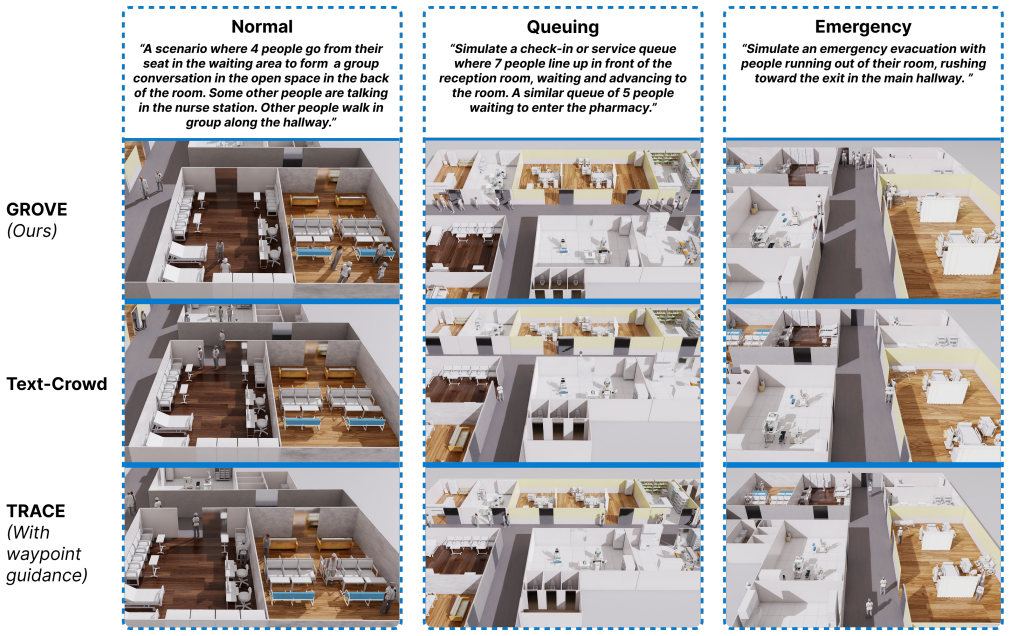
Pedestrian simulation is a critical component for training and deploying social robot navigation approaches, yet it remains a largely rigid system that repeatedly requires manual data generation to define even simple scenarios. We propose GROVE, a text-to-scenario pedestrian simulation framework that combines state-of-the-art approaches to produce realistic, socially challenging scenarios for social robot navigation. Our framework allows users to customize one of several common presets (emergency, queuing, normal) or even enter a fully independent prompt to generate a highly customizable pedestrian simulation. Multiple modules separately ensure the realism and soundness of long-horizon human behavior, medium-horizon pedestrian navigation, and short-horizon robot/social interactions. Each module is tuned by the prompt in a way that reflects the user intent across all aspects of pedestrian simulation. By dynamically selecting one of several state-of-the-art (SotA) approaches in our modules based on the scenario, we capture many situational nuances of pedestrian behavior in order to narrow the simulation-to-real (sim2real) gap. The human simulation is directly integrated into Isaac Sim, Gazebo, and RViz simulators for robot deployment in highly social environments. We validate our approach through qualitative comparison against existing pedestrian simulation baselines across scenarios of varying complexity in residential, hospital, and office environments. The result is a high-fidelity pedestrian simulation that challenges social robot navigation with complex, diverse, realistic human behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GROVE, a text-to-scenario pedestrian simulation framework that uses natural language prompts or presets (e.g., emergency, queuing) to dynamically select and tune multiple state-of-the-art modules handling long-horizon human behavior, medium-horizon navigation, and short-horizon interactions. The system integrates into Isaac Sim, Gazebo, and RViz, and is validated through qualitative comparisons against baselines in residential, hospital, and office settings, claiming to produce realistic, socially challenging scenarios that narrow the sim2real gap.
Significance. If substantiated, the framework would enable flexible, prompt-driven generation of diverse pedestrian scenarios for social robot navigation research, reducing manual data collection and providing more challenging test environments than rigid existing simulators.
major comments (3)
- [Abstract] Abstract: The central claim that the framework 'narrows the simulation-to-real (sim2real) gap' and produces 'high-fidelity' simulations rests on 'qualitative comparison against existing pedestrian simulation baselines', yet no quantitative metrics, error statistics, or details on how realism is measured (e.g., trajectory distributions, collision rates, or social compliance scores) are supplied. This leaves the soundness of the composite system unverified.
- [Framework description] Framework description (modules section): The assertion that 'Multiple modules separately ensure the realism and soundness' via 'dynamically selecting one of several state-of-the-art (SotA) approaches in our modules based on the scenario' and prompt-based tuning is load-bearing for the claim of realistic multi-horizon behavior, but the manuscript provides no description of the selection logic, consistency constraints across horizons, or how conflicts between modules are resolved.
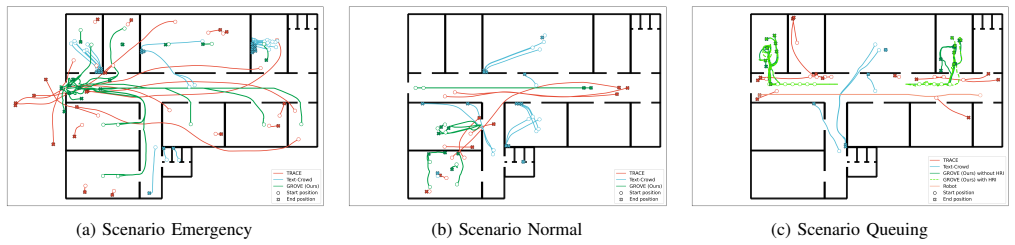
- [Validation] Validation section: The qualitative comparisons in residential, hospital, and office environments are presented without any reported mechanism for cross-horizon consistency or statistical matching to real pedestrian data, undermining the claim that the system 'challenges social robot navigation with complex, diverse, realistic human behaviors'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the paper and indicate revisions where appropriate to improve clarity without altering the core contribution of the GROVE framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'narrows the simulation-to-real (sim2real) gap' and produces 'high-fidelity' simulations rests on 'qualitative comparison against existing pedestrian simulation baselines', yet no quantitative metrics, error statistics, or details on how realism is measured (e.g., trajectory distributions, collision rates, or social compliance scores) are supplied. This leaves the soundness of the composite system unverified.
Authors: The manuscript positions GROVE as a flexible integration framework rather than a new pedestrian model with novel quantitative benchmarks. Realism claims are grounded in qualitative visual comparisons demonstrating more natural multi-horizon behaviors than rigid baselines, as is standard for simulation tool papers. We will revise the abstract to qualify the sim2real claim as 'qualitatively demonstrated through diverse scenario generation' and add a brief note on evaluation approach in the validation section. No new quantitative metrics will be introduced as they fall outside the paper's scope. revision: partial
-
Referee: [Framework description] Framework description (modules section): The assertion that 'Multiple modules separately ensure the realism and soundness' via 'dynamically selecting one of several state-of-the-art (SotA) approaches in our modules based on the scenario' and prompt-based tuning is load-bearing for the claim of realistic multi-horizon behavior, but the manuscript provides no description of the selection logic, consistency constraints across horizons, or how conflicts between modules are resolved.
Authors: The paper describes prompt-driven tuning and scenario-based selection at the architectural level, with each horizon module operating independently yet aligned via shared user intent. Detailed selection logic (e.g., prompt parsing rules) and explicit conflict resolution (e.g., priority hierarchies) are not elaborated beyond the high-level description. We will add a dedicated paragraph in the framework section outlining the selection process and consistency mechanisms via shared scenario state. revision: yes
-
Referee: [Validation] Validation section: The qualitative comparisons in residential, hospital, and office environments are presented without any reported mechanism for cross-horizon consistency or statistical matching to real pedestrian data, undermining the claim that the system 'challenges social robot navigation with complex, diverse, realistic human behaviors'.
Authors: Cross-horizon consistency is implicitly maintained through the unified prompt that tunes all modules simultaneously, as described in the framework. The validation focuses on qualitative demonstration of challenging scenarios rather than statistical matching to real-world datasets. We will revise the validation section to explicitly state the consistency mechanism and acknowledge the absence of statistical matching as a limitation of the current evaluation. revision: yes
Circularity Check
No circularity: descriptive system framework without derivations or fitted predictions
full rationale
The paper describes a modular text-to-scenario framework that dynamically selects and tunes existing SotA components for pedestrian simulation based on user prompts or presets. No equations, first-principles derivations, parameter fitting, or 'predictions' appear in the provided text. Claims rest on system composition and qualitative comparisons rather than any reduction of outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the abstract or description. The work is self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Soc- NavBench: A grounded simulation testing framework for evaluating social navigation,
A. Biswas, A. Wang, G. Silvera, A. Steinfeld, and H. Admoni, “Soc- NavBench: A grounded simulation testing framework for evaluating social navigation,”ACM Transactions on Human-Robot Interaction, vol. 11, no. 3, pp. 26:1–26:24, 2022
2022
-
[2]
SOCIALGYM 2.0: Simulator for multi-robot learning and navigation in shared human spaces,
J. Holtz and J. Biswas, “SOCIALGYM 2.0: Simulator for multi-robot learning and navigation in shared human spaces,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024, pp. 23 778–23 780
2024
-
[3]
SEAN 2.0: Formalizing and generating social situations for robot navigation,
N. Tsoi, A. Xiang, P. Yu, S. S. Sohn, G. Schwartz, S. Ramesh, M. Hussein, A. W. Gupta, M. Kapadia, and M. Vázquez, “SEAN 2.0: Formalizing and generating social situations for robot navigation,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 11 047– 11 054, 2022
2022
-
[4]
Demonstrating Arena 5.0: A Photorealistic ROS2 Simulation Framework for Developing and Benchmarking Social Navigation,
L. Kästner, V . Shcherbyna, H. Soh, G. N. H. Truong, D. D. Anh, T. M. Kien, T. Seeger, A. Martban, V . T. Lam, N. Q. Hung, P. T. H. Tung, T. D. An, E. Wiese, and M. H.-K. Schreff, “Demonstrating Arena 5.0: A Photorealistic ROS2 Simulation Framework for Developing and Benchmarking Social Navigation,” inProceedings of Robotics: Science and Systems, LosAngel...
2025
-
[5]
HuNavSim 2.0: An extended ROS 2 human navigation simulator,
I. Escudero, N. Pérez-Higueras, F. Caballero, and L. Merino, “HuNavSim 2.0: An extended ROS 2 human navigation simulator,”
-
[6]
Available: https://arxiv.org/abs/2507.17317
[Online]. Available: https://arxiv.org/abs/2507.17317
-
[7]
Text-guided synthesis of crowd animation,
X. Ji, Z. Pan, X. Gao, and J. Pan, “Text-guided synthesis of crowd animation,” inACM SIGGRAPH 2024 Conference Papers, 2024
2024
-
[8]
Trace and pace: Controllable pedestrian animation via guided trajectory diffusion,
D. Rempe, Z. Luo, X. B. Peng, Y . Yuan, K. Kitani, K. Kreis, S. Fidler, and O. Litany, “Trace and pace: Controllable pedestrian animation via guided trajectory diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 13 756–13 766
2023
-
[9]
Human motion trajectory prediction: A survey,
A. Rudenko, L. Palmieri, M. Herman, K. M. Kitani, D. M. Gavrila, and K. O. Arras, “Human motion trajectory prediction: A survey,” The International Journal of Robotics Research, vol. 39, no. 8, pp. 895–935, 2020
2020
-
[10]
Evaluation of socially-aware robot navigation,
C. Mavrogiannis, F. Baldini, A. Wang, D. Zhao, P. Trautman, A. Ste- infeld, and J. Oh, “Evaluation of socially-aware robot navigation,” Frontiers in Robotics and AI, vol. 8, 2021
2021
-
[11]
Social force models for pedestrian traffic – state of the art,
X. Chen, M. Treiber, V . Kanagaraj, and H. Li, “Social force models for pedestrian traffic – state of the art,”Transport Reviews, vol. 38, no. 5, pp. 625–653, 2018
2018
-
[12]
Social force model for pedestrian dynam- ics,
D. Helbing and P. Molnár, “Social force model for pedestrian dynam- ics,”Physical Review E, vol. 51, no. 5, pp. 4282–4286, 1995
1995
-
[13]
The walking behaviour of pedestrian social groups and its impact on crowd dynamics,
M. Moussaïd, N. Perozo, S. Garnier, D. Helbing, and G. Theraulaz, “The walking behaviour of pedestrian social groups and its impact on crowd dynamics,”PloS one, vol. 5, no. 4, p. e10047, 2010
2010
-
[14]
Social physics informed diffusion model for crowd simulation,
H. Chen, J. Ding, Y . Li, Y . Wang, and X.-P. Zhang, “Social physics informed diffusion model for crowd simulation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 1, 2024, pp. 474–482
2024
-
[15]
Sim-to-real transfer in deep reinforcement learning for robotics: A survey,
W. Zhao, J. P. Queralta, and T. Westerlund, “Sim-to-real transfer in deep reinforcement learning for robotics: A survey,” inIEEE Symposium Series on Computational Intelligence (SSCI), 2020, pp. 737–744
2020
-
[16]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen,et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[17]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[18]
Pedes- trian intention and trajectory prediction in unstructured traffic using idd-ped,
R. Bokkasam, S. Gangisetty, A. A. Hafez, and C. Jawahar, “Pedes- trian intention and trajectory prediction in unstructured traffic using idd-ped,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 763–770
2025
-
[19]
Learning better representa- tions for crowded pedestrians in offboard lidar-camera 3d tracking-by- detection,
S. Li, P. Li, Q. Lian, P. Yun, and X. Chen, “Learning better representa- tions for crowded pedestrians in offboard lidar-camera 3d tracking-by- detection,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 2740–2747
2025
-
[20]
Physgcn-dl: Physics-informed graph convolutional networks with diversity-aware loss optimization for multimodal pedestrian trajectory prediction,
Z. Jiang, R. Liu, Y . Zhou, H. Lu, B. Yang, D. Lin, and W. Zhang, “Physgcn-dl: Physics-informed graph convolutional networks with diversity-aware loss optimization for multimodal pedestrian trajectory prediction,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 38–45
2025
-
[21]
Visual-linguistic reasoning for pedes- trian trajectory prediction,
D. Shenkut and B. V . Kumar, “Visual-linguistic reasoning for pedes- trian trajectory prediction,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 771–778
2025
-
[22]
Learning crowd behavior from real data: A residual network method for crowd simulation,
Z. Yao, G. Zhang, D. Lu, and H. Liu, “Learning crowd behavior from real data: A residual network method for crowd simulation,” Neurocomputing, vol. 404, pp. 173–185, 2020
2020
-
[23]
Learning to generate diverse pedestrian movements from web videos with noisy labels,
Z. Liu, J. Lin, W. Wu, and B. Zhou, “Learning to generate diverse pedestrian movements from web videos with noisy labels,” inThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[24]
Continuous locomotive crowd behavior generation,
I. Bae, J. Lee, and H.-G. Jeon, “Continuous locomotive crowd behavior generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 416–22 431
2025
-
[25]
Efficient crowd simulation in complex environment using deep reinforcement learning,
Y . Li, Y . Chen, J. Liu, and T. Huang, “Efficient crowd simulation in complex environment using deep reinforcement learning,”Scientific Reports, vol. 15, no. 1, p. 5403, 2025
2025
-
[26]
Learning to simulate crowd trajectories with graph networks,
H. Shi, Q. Yao, and Y . Li, “Learning to simulate crowd trajectories with graph networks,” inProceedings of the ACM Web Conference 2023, 2023, pp. 4200–4209
2023
-
[27]
GenSim: Generating robotic simulation tasks via large language models,
L. Wang, Y . Ling, Z. Yuan, M. Shridhar, C. Bao, Y . Qin, B. Wang, H. Xu, and X. Wang, “GenSim: Generating robotic simulation tasks via large language models,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[28]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[29]
Theta*: Any-angle path planning on grids,
K. Daniel, A. Nash, S. Koenig, and A. Felner, “Theta*: Any-angle path planning on grids,”Journal of Artificial Intelligence Research, vol. 39, pp. 533–579, 2010
2010
-
[30]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[31]
Sceneeval: Evaluating semantic coherence in text-conditioned 3d indoor scene synthesis,
H. I. I. Tam, H. I. D. Pun, A. T. Wang, A. X. Chang, and M. Savva, “Sceneeval: Evaluating semantic coherence in text-conditioned 3d indoor scene synthesis,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2026, pp. 7355–7365
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.