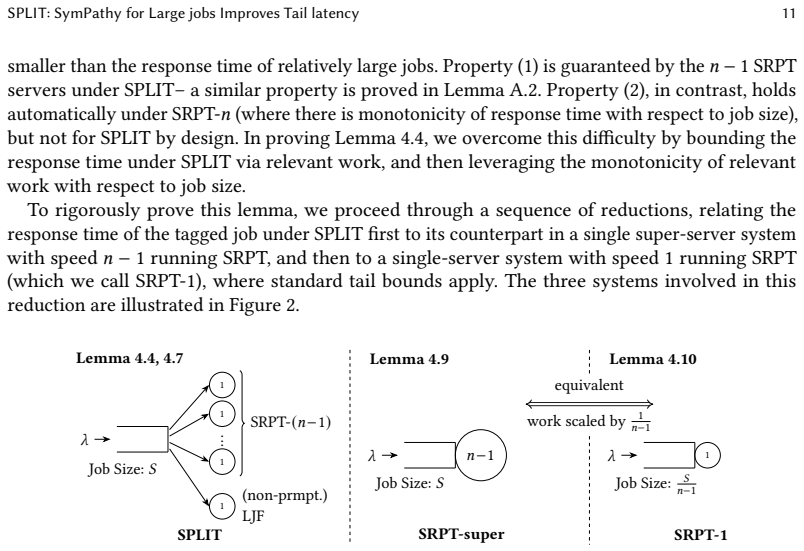
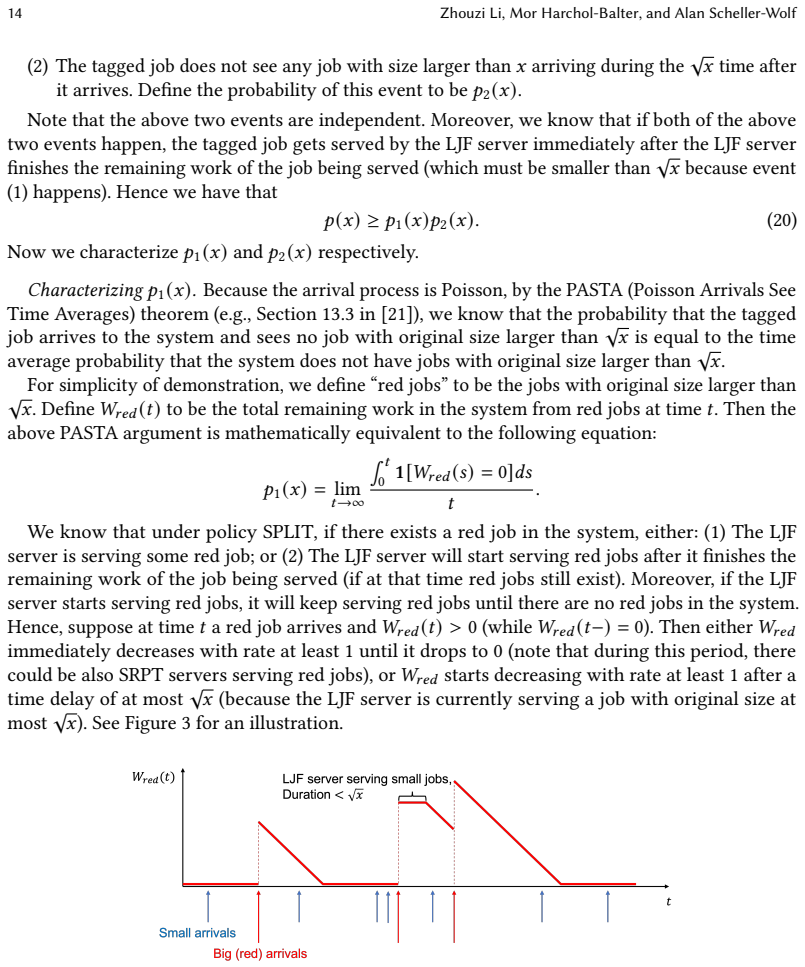
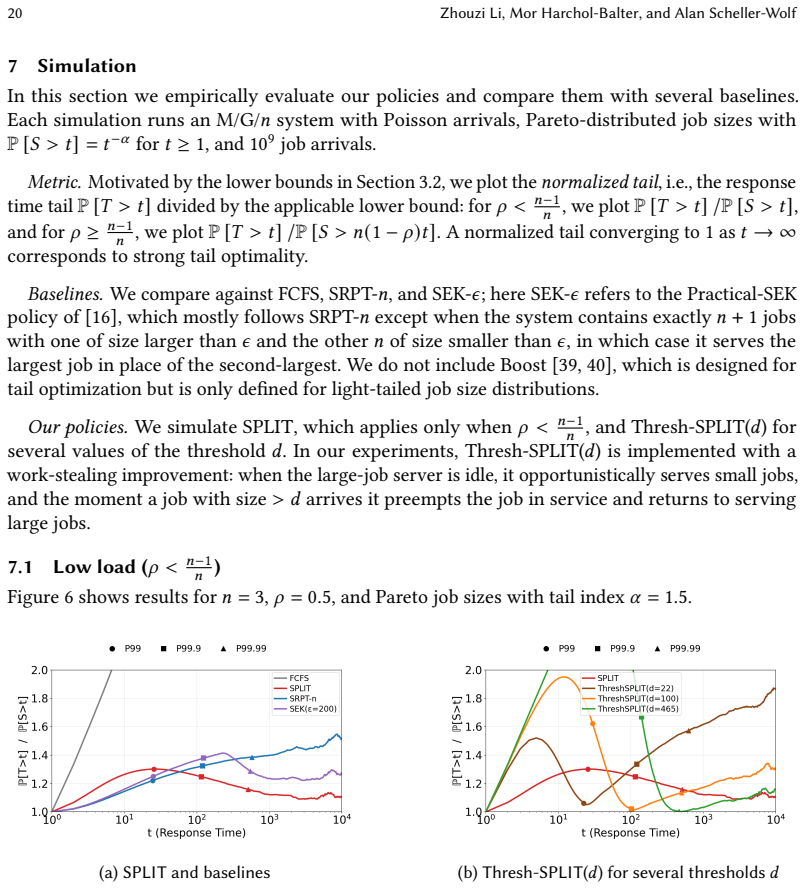
SPLIT: SymPathy for Large jobs Improves Tail latency
Pith reviewed 2026-06-30 21:07 UTC · model grok-4.3
The pith
In multi-server queues with heavy-tailed jobs, giving large jobs a small amount of priority is essential for strong tail optimality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
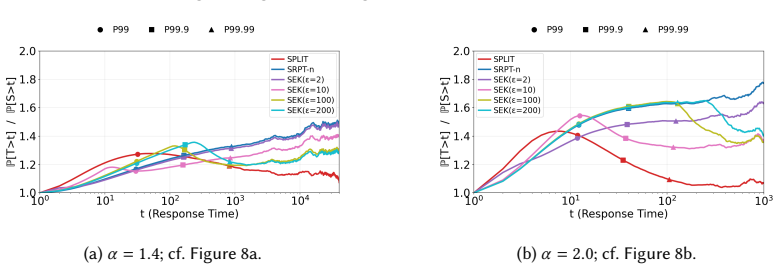
The central claim is that the multi-server case is intrinsically different from the single-server case: giving a small amount of sympathy to large jobs is essential for strong tail optimality. The paper establishes the first strongly tail-optimal (or arbitrarily close to strongly tail-optimal) scheduling policies for the M/G/n queue with heavy-tailed job sizes, both with and without knowledge of job sizes, across the full stability region.
What carries the argument
The SPLIT scheduling policy, which incorporates a small amount of sympathy for large jobs by occasionally allowing them service priority to achieve the optimal tail decay rate.
If this is right
- Strong tail optimality is achievable for multi-server systems throughout the stability region.
- The optimal policy must differ from single-server SRPT by incorporating sympathy for large jobs.
- The result holds both when job sizes are known in advance and when they are unknown.
- Policies that give no sympathy to large jobs fail to be strongly tail optimal in the multi-server case.
Where Pith is reading between the lines
- Cluster schedulers may need to add limited protection for long jobs to control tail latency even when most jobs are short.
- The same sympathy principle could apply to other multi-resource systems where job size variation affects shared queues.
- Exact tuning of the sympathy parameter might be tested by varying the tail index of the job-size distribution in simulation.
Load-bearing premise
The M/G/n multi-server queue model with regularly varying heavy-tailed job sizes accurately captures the asymptotic tail behavior of modern computing workloads.
What would settle it
Measure the empirical response-time tail exponent in a physical multi-server testbed under regularly varying job sizes and check whether SPLIT achieves the predicted optimal decay rate while a strict short-job priority policy does not.
Figures


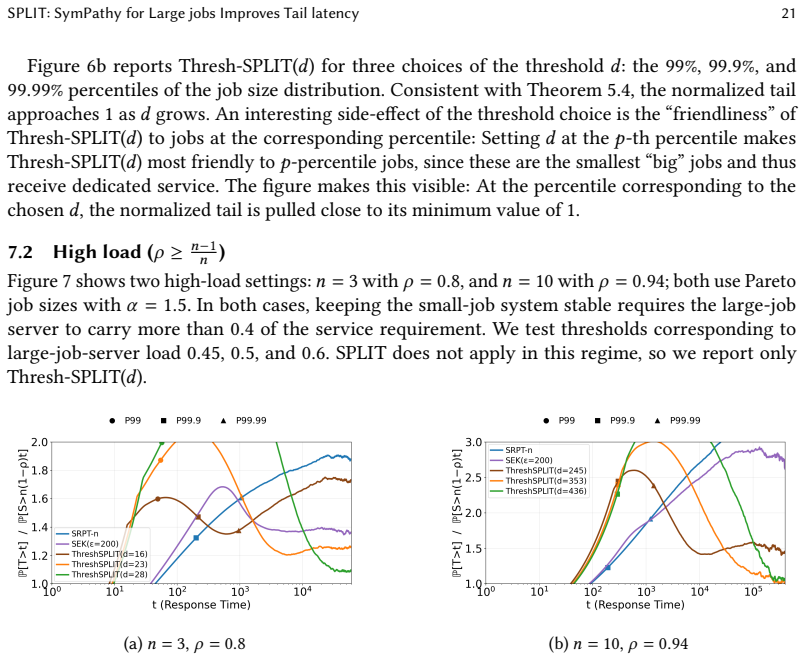
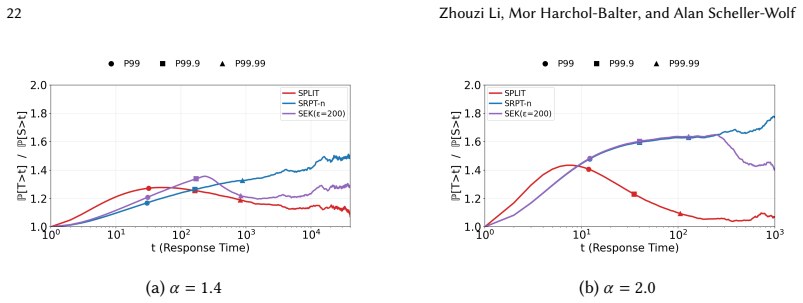
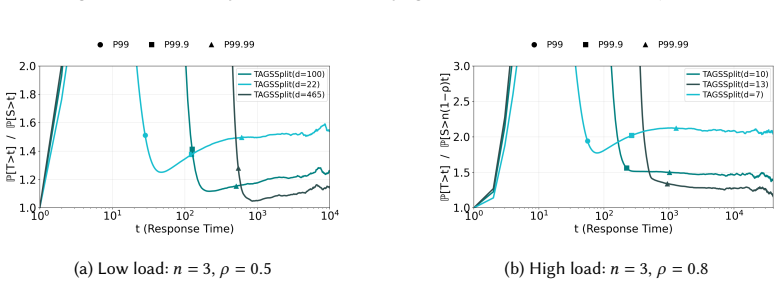
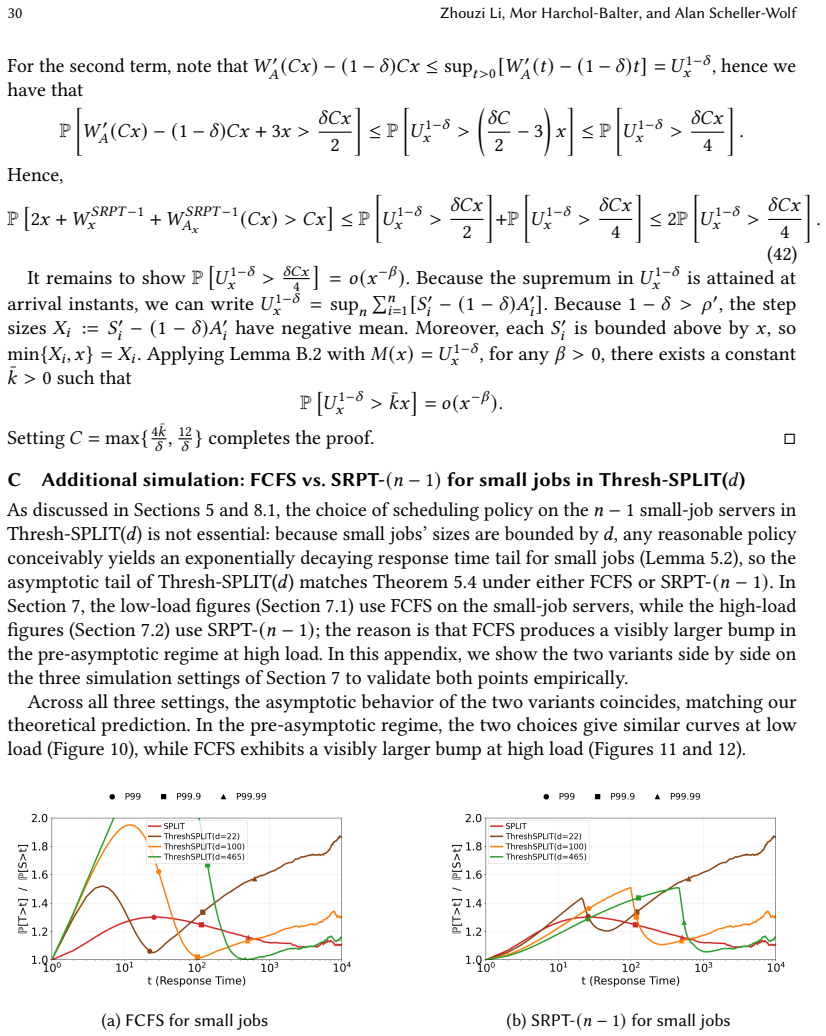
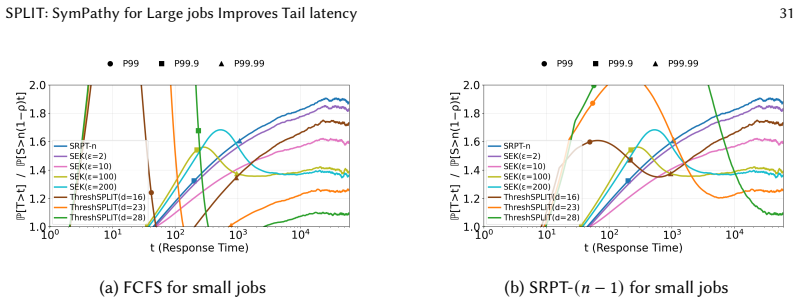
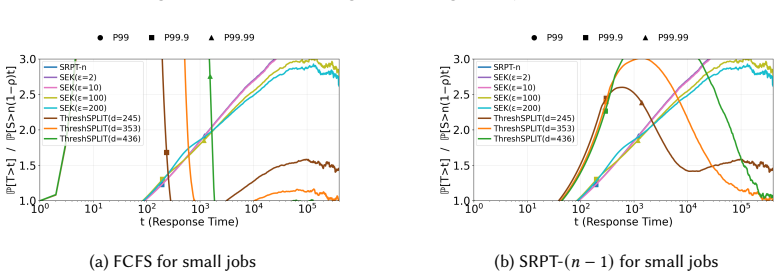
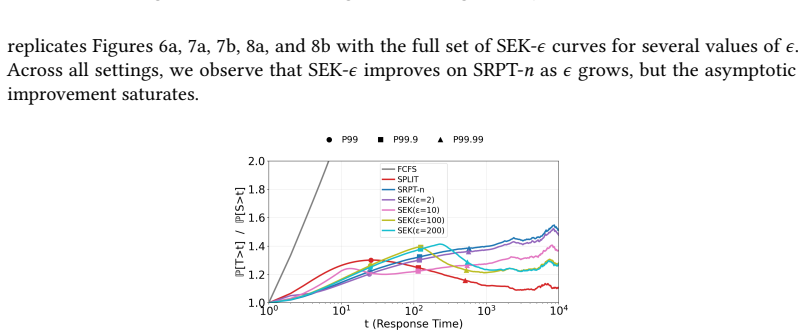
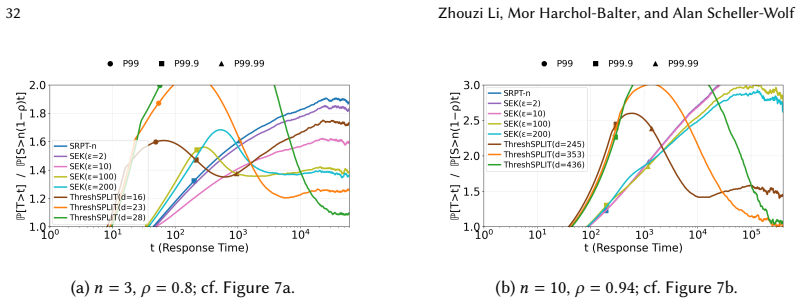
read the original abstract
We study the asymptotic response time tail in the M/G/n multi-server queue with heavy-tailed (regularly varying) job sizes, a setting representative of modern computing workloads. For single-server systems, tail optimization is well understood: under heavy-tailed job sizes, policies such as SRPT that strictly prioritize short jobs are strongly tail optimal, and giving any priority to large jobs is harmful. For multi-server systems, the question has been almost entirely open. This paper gives the first strongly tail-optimal scheduling policies for the M/G/n queue with heavy-tailed job sizes. Our central finding is that the multi-server case is intrinsically different from the single-server case: giving a small amount of ``sympathy'' to large jobs is essential for strong tail optimality. We establish strong (or arbitrarily close to strong) tail optimality across the full stability region, both with and without knowledge of job sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to provide the first strongly tail-optimal scheduling policies for the M/G/n multi-server queue with regularly varying (heavy-tailed) job sizes. The central finding is that the multi-server case differs intrinsically from the single-server case: a small amount of sympathy to large jobs is essential for strong tail optimality. The results are asserted to hold across the full stability region both with and without job-size information.
Significance. If the derivations and optimality proofs hold, this would be a significant contribution to scheduling theory for multi-server systems under heavy-tailed workloads, resolving an open question and establishing a key distinction from single-server behavior.
major comments (1)
- [Abstract] Abstract: the claim that the paper gives the first strongly tail-optimal policies and establishes this across the full stability region is stated without any derivations, proofs, or evidence; the full paper is required to check whether the math supports the stated optimality.
Simulated Author's Rebuttal
We thank the referee for their review. The major comment concerns the abstract's claims; we address it point by point below. The full manuscript contains the supporting analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the paper gives the first strongly tail-optimal policies and establishes this across the full stability region is stated without any derivations, proofs, or evidence; the full paper is required to check whether the math supports the stated optimality.
Authors: The abstract summarizes the paper's main results at a high level, as is standard. The full manuscript provides the derivations and proofs: Section 3 defines the SPLIT policies and establishes their tail behavior via sample-path analysis; Section 4 proves strong tail optimality (or arbitrary closeness) for the M/G/n queue with regularly varying job sizes across the entire stability region, both with and without job-size information; Section 5 contains the technical lemmas on residual service times and workload bounds. These sections directly support the abstract claims. We are happy to add explicit forward references from the abstract to these sections if the referee finds that helpful. revision: partial
Circularity Check
No significant circularity; derivation is self-contained theoretical analysis
full rationale
The paper advances a new theoretical result on tail-optimal scheduling for M/G/n queues under regularly varying job sizes. The central claim—that a small amount of sympathy to large jobs is required for strong tail optimality, unlike the single-server case—is presented as a first-principles asymptotic derivation across the stability region, both with and without job-size information. No equations or steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The analysis does not rename known empirical patterns or smuggle ansatzes via prior work. This is the expected outcome for a pure queueing-theory paper whose results are externally falsifiable via simulation or proof verification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption M/G/n multi-server queue with regularly varying job sizes
Forward citations
Cited by 1 Pith paper
-
Beyond Prediction: Tail-Aware Scheduling for LLM Inference
Presents a distribution-aware scheduling framework for LLM inference that reduces P99 TTLT by 35-50% and TTFT by 34-47% versus SRPT with perfect length knowledge using statistical signals instead of predictions.
Reference graph
Works this paper leans on
-
[1]
Samuli Aalto, Urtzi Ayesta, and Rhonda Righter. 2009. On the Gittins Index in the M/G/1 Queue.Queueing Systems63 (2009), 437–458
2009
-
[2]
Choudhury, and Ward Whitt
Joseph Abate, Gagan L. Choudhury, and Ward Whitt. 1995. Exponential Approximations for Tail Probabilities in Queues, I: Waiting Times.Operations Research43, 5 (1995), 885–901
1995
-
[3]
Venkat Anantharam. 1988. How large delays build up in a GI/G/1 queue.Queueing Systems5, 4 (1988), 345–368
1988
-
[4]
Eitan Bachmat, Josu Doncel, and Hagit Sarfati. 2019. Performance and Stability Analysis of the Task Assignment Based on Guessing Size Routing Policy. In2019 IEEE 27th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS). IEEE, 1–13
2019
-
[5]
Eitan Bachmat, Josu Doncel, and Hagit Sarfati. 2020. Analysis of the Task Assignment based on Guessing Size policy. Performance Evaluation142 (2020), 102122
2020
-
[6]
Jose Blanchet and Karthyek Murthy. 2016. Tail Asymptotics for Delay in a Half-Loaded GI/GI/2 Queue with Heavy- Tailed Job Sizes.Queueing Systems81, 4 (2016), 301–340
2016
-
[7]
Boxma, Rudesindo Núñez-Queija, and Bert Zwart
Sem Borst, Onno J. Boxma, Rudesindo Núñez-Queija, and Bert Zwart. 2003. The Impact of the Service Discipline on Delay Asymptotics.Performance Evaluation54 (2003), 175–206
2003
-
[8]
Sem Borst, Rudesindo Núñez-Queija, and Bert Zwart. 2006. Sojourn time asymptotics in processor-sharing queues. Queueing Systems53, 1 (2006), 31–51
2006
-
[9]
Boxma, Qing Deng, and Bert Zwart
Onno J. Boxma, Qing Deng, and Bert Zwart. 2002. Waiting-Time Asymptotics for the M/G/2 Queue with Heterogeneous Servers.Queueing Systems40 (2002), 5–31
2002
-
[10]
Boxma and Denis Denisov
Onno J. Boxma and Denis Denisov. 2011. Sojourn Time Tails in the Single Server Queue with Heavy-Tailed Service Times.Queueing Systems69 (2011), 101–119
2011
-
[11]
Boxma and Bert Zwart
Onno J. Boxma and Bert Zwart. 2007. Tails in scheduling.ACM SIGMETRICS Performance Evaluation Review34, 4 (2007), 13–20
2007
-
[12]
Nils Charlet and Benny Van Houdt. 2024. Tail Optimality and Performance Analysis of the Nudge-M Scheduling Algorithm.arXiv preprint arXiv:2403.06588(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Crovella and Azer Bestavros
Mark E. Crovella and Azer Bestavros. 1997. Self-similarity in World Wide Web traffic: evidence and possible causes. IEEE/ACM Transactions on Networking5, 6 (1997), 835–846
1997
-
[14]
Serguei Foss and Dmitry Korshunov. 2006. Heavy tails in multi-server queue.Queueing Systems52, 1 (2006), 31–48
2006
-
[15]
Serguei Foss and Dmitry Korshunov. 2012. On Large Delays in Multi-Server Queues with Heavy Tails.Mathematics of Operations Research37, 2 (2012), 201–218
2012
- [16]
-
[17]
Isaac Grosof, Ziv Scully, and Mor Harchol-Balter. 2018. SRPT for multiserver systems.Performance Evaluation127-128 (2018), 154–175. doi:10.1016/j.peva.2018.10.001
-
[18]
Isaac Grosof, Kunhe Yang, Ziv Scully, and Mor Harchol-Balter. 2021. Nudge: Stochastically Improving upon FCFS. Proceedings of the ACM on Measurement and Analysis of Computing Systems5, 2 (2021), 1–29
2021
-
[19]
Fabrice Guillemin, Philippe Robert, and Bert Zwart. 2004. Tail asymptotics for processor-sharing queues.Advances in Applied Probability36, 2 (2004), 525–543
2004
-
[20]
Mor Harchol-Balter. 2002. Task Assignment with Unknown Duration.J. ACM49, 2 (2002), 260–288
2002
-
[21]
2013.Performance modeling and design of computer systems: queueing theory in action
Mor Harchol-Balter. 2013.Performance modeling and design of computer systems: queueing theory in action. Cambridge University Press
2013
-
[22]
Mor Harchol-Balter and Allen B. Downey. 1997. Exploiting process lifetime distributions for dynamic load balancing. ACM Transactions on Computer Systems15, 3 (1997), 253–285
1997
-
[23]
Amit Harlev, George Yu, and Ziv Scully. 2025. A Gittins Policy for Optimizing Tail Latency.Proceedings of the ACM on Measurement and Analysis of Computing Systems9, 2 (2025), 1–40
2025
-
[24]
Robert M Loynes. 1962. The stability of a queue with non-independent inter-arrival and service times. InMathematical proceedings of the cambridge philosophical society, Vol. 58. Cambridge University Press, 497–520
1962
-
[25]
Michel Mandjes and Bert Zwart. 2006. Large Deviations of Sojourn Times in Processor Sharing Queues.Queueing Systems52 (2006), 237–250
2006
-
[26]
2022.The Fundamentals of Heavy Tails: Properties, Emergence, and Estimation
Jayakrishnan Nair, Adam Wierman, and Bert Zwart. 2022.The Fundamentals of Heavy Tails: Properties, Emergence, and Estimation. Cambridge University Press
2022
-
[27]
Rudesindo Núñez-Queija. 2002. Queues with Equally Heavy Sojourn Time and Service Requirement Distributions. Annals of Operations Research113 (2002), 101–117. , Vol. 1, No. 1, Article . Publication date: May 2026. 26 Zhouzi Li, Mor Harchol-Balter, and Alan Scheller-Wolf
2002
-
[28]
Misja Nuyens, Adam Wierman, and Bert Zwart. 2008. Preventing large sojourn times using SMART scheduling. Operations Research56, 1 (2008), 88–101
2008
-
[29]
Misja Nuyens and Bert Zwart. 2006. A Large-Deviations Analysis of the GI/GI/1 SRPT Queue.Queueing Systems54 (2006), 85–97
2006
-
[30]
Sidney Resnick and Gennady Samorodnitsky. 1999. Activity periods of an infinite server queue and performance of certain heavy tailed fluid queues.Queueing Systems33, 1 (1999), 43–71
1999
-
[31]
John S Sadowsky and Wojciech Szpankowski. 1989. On the Analysis of the Tail Queue Length and Waiting Time Distributions of a GI/GI/c Queue. (1989)
1989
-
[32]
Linus Schrage. 1968. A Proof of the Optimality of the Shortest Remaining Processing Time Discipline.Operations Research16, 3 (1968), 687–690
1968
-
[33]
Ziv Scully, Isaac Grosof, and Mor Harchol-Balter. 2020. Optimal Multiserver Scheduling with Unknown Job Sizes in Heavy Traffic.Performance Evaluation145 (2020), 102150
2020
-
[34]
Ziv Scully and Mor Harchol-Balter. 2021. The Gittins Policy in the M/G/1 Queue. In19th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt). IEEE, 248–255
2021
-
[35]
Muhammad Tirmazi, Adam Barker, Nan Deng, Md E Haque, Zhijing He Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. 2020. Borg: the next generation. InProceedings of the Fifteenth European Conference on Computer Systems. 1–14
2020
-
[36]
Benny Van Houdt. 2022. On the Stochastic and Asymptotic Improvement of First-Come First-Served and Nudge Scheduling.Proceedings of the ACM on Measurement and Analysis of Computing Systems6, 3 (2022), 1–22
2022
-
[37]
Adam Wierman, Mor Harchol-Balter, and Takayuki Osogami. 2005. Nearly insensitive bounds on SMART scheduling. ACM SIGMETRICS Performance Evaluation Review33, 1 (2005), 205–216
2005
-
[38]
Adam Wierman and Bert Zwart. 2012. Is tail-optimal scheduling possible?Operations research60, 5 (2012), 1249–1257
2012
-
[39]
George Yu, Amit Harlev, Reevu Adakroy, and Ziv Scully. 2025. A Tale of Two Traffics: Optimizing Tail Latency in the Light-Tailed M/G/k.Proceedings of the ACM on Measurement and Analysis of Computing Systems9, 3 (2025), 1–40
2025
-
[40]
George Yu and Ziv Scully. 2024. Strongly tail-optimal scheduling in the light-tailed M/G/1.Proceedings of the ACM on Measurement and Analysis of Computing Systems8, 2 (2024), 1–33
2024
-
[41]
𝑥 busy period
Bert Zwart and Onno J. Boxma. 2000. Sojourn Time Asymptotics in the M/G/1 Processor Sharing Queue.Queueing Systems35 (2000), 141–166. A SRPT-𝑛is weakly tail optimal In this section, we prove that SRPT-𝑛 is weakly tail optimal. The proof of the main lemma (Lemma A.2) is very similar to the proof in Section 4.3. The proof of the main theorem (Theorem A.1) f...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.