Bridging Semantics and Kinematics: A Modular Framework for Zero-Shot Robotic Manipulation
Pith reviewed 2026-06-26 08:27 UTC · model grok-4.3
The pith
A three-stage modular system turns natural language into robot actions by anchoring visuals with FastSAM and routing semantics through an LLM to generate collision-free trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
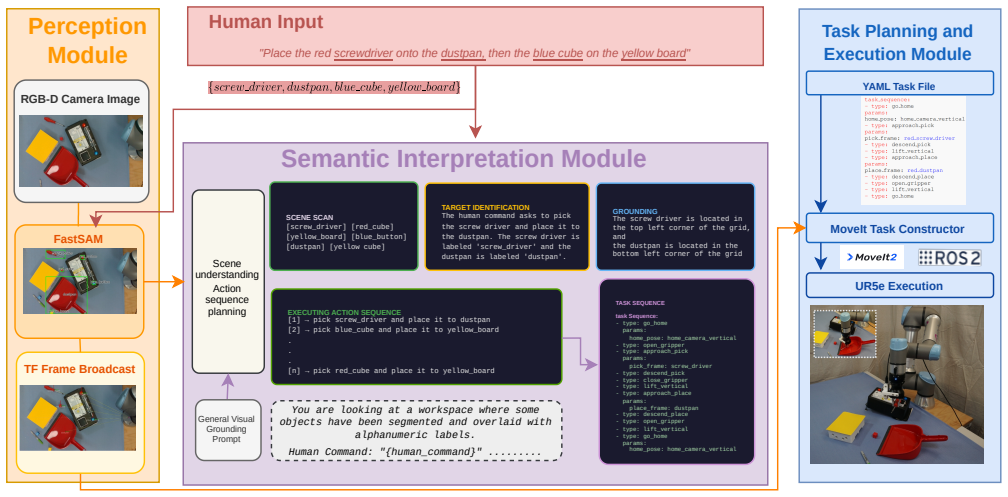
By combining FastSAM and Set-of-Mark prompting to generate grounded visual anchors, routing semantics through an LLM acting purely as a semantic router, and dynamically parsing the resulting configurations via a Task Orchestrator into MoveIt Task Constructor for collision-free paths, the framework executes complex physical actions from unconstrained language directives in semi-structured environments.
What carries the argument
The three-stage architecture of perception with FastSAM and Set-of-Mark prompting, LLM semantic router, and Task Orchestrator parsing to MoveIt Task Constructor.
If this is right
- Robots can complete unconstrained sequential manipulation tasks from language input alone.
- Dense relational spatial reasoning tasks become executable without pre-programmed coordinates.
- New tasks can be added by changing only the language directives rather than retraining models.
- Configurations remain reconfigurable and verifiable before physical execution.
Where Pith is reading between the lines
- The modular separation could let teams replace the vision component with newer models to raise success rates in varied lighting or clutter.
- The same routing approach might transfer to non-robotic domains that need language-to-action mapping, such as automated assembly instructions.
- Scaling the orchestrator to multi-robot coordination would test whether the semantic layer remains stable when multiple agents share the same scene anchors.
Load-bearing premise
The combination of FastSAM with Set-of-Mark prompting and the LLM semantic router produces configurations that contain few enough spatial ambiguities or hallucinations for the Task Orchestrator to generate reliable executable trajectories.
What would settle it
A sequence of trials in which the LLM misidentifies object relations in a crowded scene, leading to trajectories that collide or grasp the wrong object at rates well above the reported 38 percent failure.
Figures

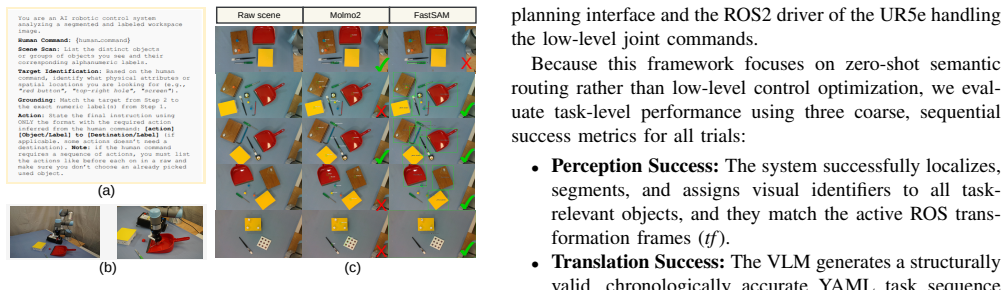

read the original abstract
This paper presents a modular training-free framework for zero-shot, language-guided robotic manipulation in semi-structured environments. The architecture bridges the gap between high-level reasoning and low-level kinematics by decomposing the vision-action pipeline into three stages: visual perception, semantic interpretation, and task execution. To overcome the spatial ambiguity and semantic hallucinations inherent in standard Vision-Language Models (VLMs), the perception module employs FastSAM and Set-of-Mark (SoM) prompting to dynamically generate grounded, alphanumeric visual anchors. The same foundation model then operates purely as a Large Language Model (LLM) to act as a semantic router, translating unconstrained human directives into verifiable, reconfigurable configurations. Finally, these configurations are dynamically parsed by a Task Orchestrator into MoveIt Task Constructor (MTC) to generate collision-free trajectories. The framework is evaluated across two zero-shot experimental setups: unconstrained open-world sequential manipulation and dense relational spatial reasoning, achieving a 62% end-to-end task success rate across both scenarios, demonstrating its capacity to reliably execute complex physical actions without domain-specific training or manual coordinate programming.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a modular, training-free framework for zero-shot robotic manipulation guided by natural language in semi-structured environments. It decomposes the pipeline into three stages: (1) visual perception using FastSAM combined with Set-of-Mark prompting to create grounded visual anchors, (2) semantic interpretation where an LLM acts as a semantic router to convert human directives into verifiable configurations, and (3) task execution via a Task Orchestrator that parses these into MoveIt Task Constructor for collision-free trajectories. The framework is tested in two zero-shot scenarios—unconstrained open-world sequential manipulation and dense relational spatial reasoning—reporting an overall 62% success rate.
Significance. If substantiated by detailed experimental evidence, the framework's ability to achieve zero-shot performance by bridging semantic reasoning with kinematic execution without any domain-specific training or manual coordinate specification would represent a meaningful advance in practical robotic manipulation systems. The use of existing foundation models in a modular architecture avoids the data and compute costs of end-to-end training and could facilitate more flexible deployment in real-world settings. However, the current presentation does not provide enough information to confirm this potential.
major comments (1)
- [Abstract] Abstract: The central claim of a 62% end-to-end task success rate across the two experimental setups is not supported by any reported trial counts, baseline comparisons, statistical analysis, or discussion of failure modes and environmental variations, rendering it impossible to evaluate whether the results validate the framework's reliability.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater transparency in the abstract regarding the experimental validation. We address the single major comment below and will revise the manuscript to improve clarity and support for the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a 62% end-to-end task success rate across the two experimental setups is not supported by any reported trial counts, baseline comparisons, statistical analysis, or discussion of failure modes and environmental variations, rendering it impossible to evaluate whether the results validate the framework's reliability.
Authors: We agree that the abstract, as currently written, does not provide sufficient supporting details on the experimental protocol. The full manuscript describes the two zero-shot scenarios (unconstrained open-world sequential manipulation and dense relational spatial reasoning) in Section 4, but does not explicitly state trial counts, include baseline comparisons, or analyze failure modes and environmental factors in the abstract itself. To address this, we will revise the abstract to summarize the evaluation methodology, note the total number of trials conducted across scenarios, and briefly reference the observed success rate breakdown. We will also expand the experiments section to include statistical context, failure mode discussion, and environmental variations if these details can be extracted from our logs without new experiments. revision: yes
Circularity Check
No significant circularity; engineering framework with experimental evaluation only
full rationale
The paper describes a modular three-stage robotic manipulation pipeline (perception with FastSAM/SoM, LLM semantic router, Task Orchestrator to MTC) evaluated on two zero-shot tasks with a reported 62% success rate. No mathematical derivations, fitted parameters, predictions, uniqueness theorems, or self-citations appear in the provided abstract or description. The central claim reduces to empirical performance of an applied system rather than any closed derivation chain, making the work self-contained against external benchmarks with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal fusion and vision-language models: A survey for robot vision,
X. Han, S. Chen, Z. Fu, Z. Feng, L. Fan, D. An, C. Wang, L. Guo, W. Meng, X. Zhanget al., “Multimodal fusion and vision-language models: A survey for robot vision,”Information Fusion, p. 103652, 2025
2025
-
[2]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779– 788
2016
-
[3]
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,”arXiv preprint arXiv:2306.12156, 2023
arXiv 2023
-
[4]
Masked-attention mask transformer for universal image segmenta- tion,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmenta- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–1299
2022
-
[5]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean conference on computer vision. Springer, 2024, pp. 38–55
2024
-
[6]
Simple open-vocabulary object detection,
M. Minderer, A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Mahendran, A. Arnab, M. Dehghani, Z. Shenet al., “Simple open-vocabulary object detection,” inEuropean conference on computer vision. Springer, 2022, pp. 728–755
2022
-
[7]
Grounded language-image pre-training,
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwanget al., “Grounded language-image pre-training,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 965–10 975
2022
-
[8]
Large language and vision-language models for robot: safety challenges, mitigation strategies and future directions,
X. Hu and Z. Xu, “Large language and vision-language models for robot: safety challenges, mitigation strategies and future directions,” Industrial Robot: the international journal of robotics research and application, 2025
2025
-
[9]
Physically grounded vision-language models for robotic manipulation,
J. Gao, B. Sarkar, F. Xia, T. Xiao, J. Wu, B. Ichter, A. Majumdar, and D. Sadigh, “Physically grounded vision-language models for robotic manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12 462–12 469
2024
-
[10]
Vision language action models in robotic manipulation: A systematic review,
M. U. Din, W. Akram, L. S. Saoud, J. Rosell, and I. Hussain, “Vision language action models in robotic manipulation: A systematic review,” URL https://arxiv. org/abs/2507.10672, 2025
arXiv 2025
-
[11]
Vision- language-action models for robotics: A review towards real-world applications,
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu, “Vision- language-action models for robotics: A review towards real-world applications,”IEEE Access, 2025
2025
-
[12]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[13]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J. Alayrac, M. Arenas, A. Balakrishna, N. Batchelor, A. Bewley, J. Binghamet al., “Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer,”arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[14]
Z. Zhou, Y . Zhu, J. Wen, C. Shen, and Y . Xu, “Chatvla-2: Vision- language-action model with open-world embodied reasoning from pretrained knowledge,”arXiv preprint arXiv:2505.21906, 2025
arXiv 2025
-
[15]
Openvla: An open vision-language-action model,
O. Team, “Openvla: An open vision-language-action model,”arXiv preprint, 2024
2024
-
[16]
Do as i can, not as i say: Grounding language in robotic affordances,
A. et al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[17]
Pddl—the planning domain definition language,
C. Aeronautiques, A. Howe, C. Knoblock, I. D. McDermott, A. Ram, M. Veloso, D. Weld, D. W. Sri, A. Barrett, D. Christiansonet al., “Pddl—the planning domain definition language,”Technical Report, Tech. Rep., 1998
1998
-
[18]
Fast planning through planning graph analysis,
A. L. Blum and M. L. Furst, “Fast planning through planning graph analysis,”Artificial intelligence, vol. 90, no. 1-2, pp. 281–300, 1997
1997
-
[19]
The ff planning system: Fast plan generation through heuristic search,
J. Hoffmann and B. Nebel, “The ff planning system: Fast plan generation through heuristic search,”Journal of Artificial Intelligence Research, vol. 14, pp. 253–302, 2001
2001
-
[20]
Autotamp: Autoregressive task and motion planning with llms as translators and checkers,
Y . Chen, J. Arkin, C. Dawson, Y . Zhang, N. Roy, and C. Fan, “Autotamp: Autoregressive task and motion planning with llms as translators and checkers,” in2024 IEEE International conference on robotics and automation (ICRA). IEEE, 2024, pp. 6695–6702
2024
-
[21]
Integrating action knowledge and llms for task planning and situation handling in open worlds,
Y . Ding, X. Zhang, S. Amiri, N. Cao, H. Yang, A. Kaminski, C. Esselink, and S. Zhang, “Integrating action knowledge and llms for task planning and situation handling in open worlds,”Autonomous Robots, vol. 47, no. 8, pp. 981–997, 2023
2023
-
[22]
Progprompt: Generating situ- ated robot task plans using large language models,
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situ- ated robot task plans using large language models,”arXiv preprint arXiv:2209.11302, 2022
Pith/arXiv arXiv 2022
-
[23]
Llmˆ 3: Large language model-based task and motion planning with motion failure reasoning,
S. Wang, M. Han, Z. Jiao, Z. Zhang, Y . N. Wu, S.-C. Zhu, and H. Liu, “Llmˆ 3: Large language model-based task and motion planning with motion failure reasoning,” in2024 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2024, pp. 12 086– 12 092
2024
-
[24]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” inInternational conference on machine learning. PMLR, 2022, pp. 9118–9147
2022
-
[25]
Onto-llm-tamp: Knowledge-oriented task and motion planning using large language models,
M. U. Din, J. Rosell, W. Akram, I. Zaplana, M. A. Roa, and I. Hussain, “Onto-llm-tamp: Knowledge-oriented task and motion planning using large language models,”Robotics and Autonomous Systems, p. 105404, 2026
2026
-
[26]
Interactive task planning with language models,
B. Li, P. Wu, P. Abbeel, and J. Malik, “Interactive task planning with language models,”arXiv preprint arXiv:2310.10645, 2023
arXiv 2023
-
[27]
A survey of robotic language grounding: Tradeoffs between symbols and embeddings,
V . Cohen, J. X. Liu, R. Mooney, S. Tellex, and D. Watkins, “A survey of robotic language grounding: Tradeoffs between symbols and embeddings,”arXiv preprint arXiv:2405.13245, 2024
arXiv 2024
-
[28]
Kinodynamic task and motion plan- ning using vlm-guided and interleaved sampling,
M. Kwon and Y . J. Kim, “Kinodynamic task and motion plan- ning using vlm-guided and interleaved sampling,”arXiv preprint arXiv:2510.26139, 2025
arXiv 2025
-
[29]
Moveit! task constructor for task-level motion planning,
M. G ¨orner, R. Haschke, H. Ritter, and J. Zhang, “Moveit! task constructor for task-level motion planning,” in2019 International conference on robotics and automation (ICRA). IEEE, 2019, pp. 190–196
2019
-
[30]
Spatialrgpt: Grounded spatial reasoning in vision-language models,
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu, “Spatialrgpt: Grounded spatial reasoning in vision-language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 135 062–135 093, 2024
2024
-
[31]
Gemini 3 pro: the frontier of vision ai,
Google DeepMind, “Gemini 3 pro: the frontier of vision ai,” 2025. [Online]. Available: https://blog.google/innovation-and-ai/technology/ developers-tools/gemini-3-pro-vision/
2025
-
[32]
Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v,
J. Yang, H. Zhang, F. Li, X. Zou, C. Li, and J. Gao, “Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v,”arXiv preprint arXiv:2310.11441, 2023
Pith/arXiv arXiv 2023
-
[33]
Molmo2: Open weights and data for vision-language models with video understanding and grounding,
C. Clark, J. Zhang, Z. Ma, J. S. Park, M. Salehi, R. Tripathi, S. Lee, Z. Ren, C. D. Kim, Y . Yanget al., “Molmo2: Open weights and data for vision-language models with video understanding and grounding,” arXiv preprint arXiv:2601.10611, 2026
Pith/arXiv arXiv 2026
-
[34]
Grounding large language models for robot task planning using closed-loop state feedback,
V . Bhat, A. U. Kaypak, P. Krishnamurthy, R. Karri, and F. Khor- rami, “Grounding large language models for robot task planning using closed-loop state feedback,”Advanced Robotics Research, p. e202500072, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.