Self-Paced Curriculum Reinforcement Learning for Autonomous Superbike Racing in Simulation
Pith reviewed 2026-06-27 16:21 UTC · model grok-4.3
The pith
Integrating self-paced curriculum learning with SAC trains autonomous superbike agents more efficiently than SAC alone in a physics simulator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
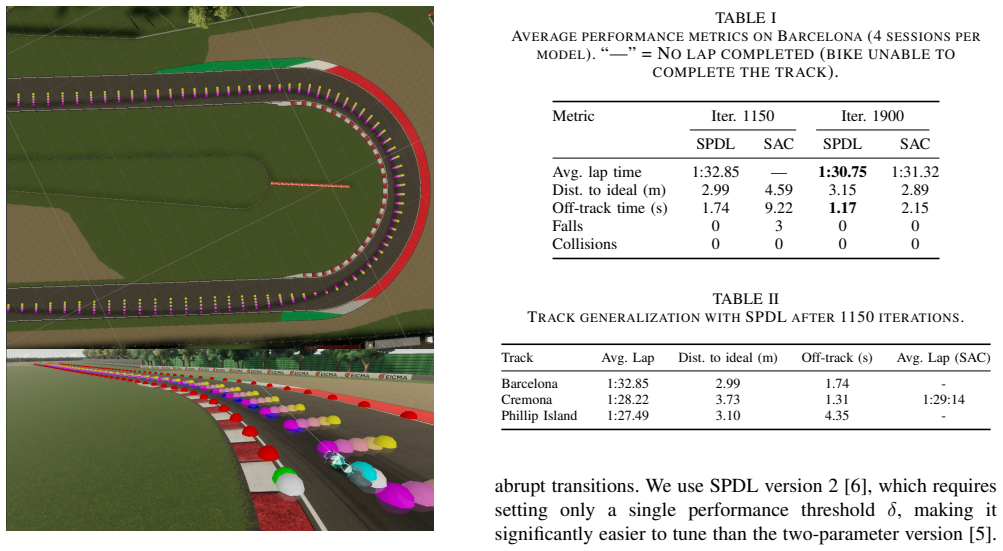
The authors argue that SPDL combined with SAC produces agents that reach higher training efficiency, lower lap times, and greater driving stability than plain SAC, and that these gains appear consistently across several tracks and motorbike models inside the VRider SBK simulator.
What carries the argument
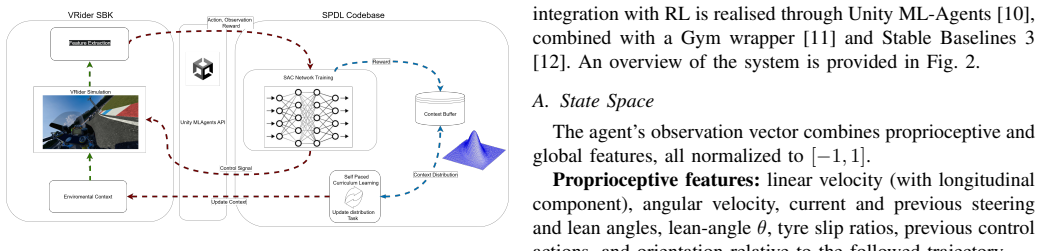
Self-Paced curriculum Deep reinforcement Learning (SPDL) integrated with Soft Actor-Critic, which automatically generates a sequence of progressively harder racing tasks from the agent's measured performance.
If this is right
- The same SPDL-SAC combination works without any hand-designed sequence of tasks.
- State features that track lean-angle history plus rewards that penalize instability are sufficient to manage two-wheeled dynamics.
- Performance advantages hold when the same method is tested on multiple tracks and multiple motorbike models.
- The resulting agents provide an initial quantitative baseline that later work can compare against.
Where Pith is reading between the lines
- If the simulator-to-reality gap can be closed, the learned policies supply candidate control laws for physical superbikes.
- The automatic curriculum construction may transfer to other vehicles whose stability depends on continuous lean or tilt control.
- Adding visual or tire-force observations to the existing proprioceptive state could further reduce falls during high-speed cornering.
Load-bearing premise
The VRider SBK Unity simulator supplies a physics model accurate enough that policies successful inside it will reflect real superbike balance and lean behavior.
What would settle it
Running identical training runs in a higher-fidelity or real-world superbike platform and finding that SPDL no longer improves lap time or stability over SAC would falsify the central performance claim.
Figures


read the original abstract
Autonomous Racing has seen remarkable progress through deep Reinforcement Learning (RL), primarily for four-wheeled vehicles. However, motorbikes introduce substantially greater complexity due to the need to manage balance and lean angle, in addition to more reactive steering and throttle control, and a smaller weight. In this work, we present a framework for training an autonomous agent to race a superbike in VRider SBK, a physics-accurate Unity-based motorbike simulator. Our approach integrates Soft Actor-Critic (SAC) with Self-Paced curriculum Deep reinforcement Learning (SPDL), which dynamically generates progressively more challenging tasks based on the agent's performance, without requiring manual curriculum design. The agent's state space comprises proprioceptive features extended with lean-angle history, along with global track features via course points. The reward signal is shaped to encourage progress along the track while penalizing instability-inducing behaviors specific to two-wheeled dynamics. Preliminary experimental results demonstrate that SPDL outperforms SAC alone in training efficiency, lap time, and driving stability across multiple tracks and motorbike models, establishing a first baseline for RL-based autonomous motorbike racing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a framework for autonomous superbike racing in the VRider SBK Unity simulator that combines Soft Actor-Critic (SAC) with Self-Paced curriculum Deep reinforcement Learning (SPDL). The state includes proprioceptive features augmented by lean-angle history plus global track course points; the reward encourages forward progress while penalizing two-wheeled instability. The central claim is that SPDL yields better training efficiency, lap times, and stability than plain SAC across multiple tracks and motorbike models, thereby establishing a first baseline for RL-based motorbike racing.
Significance. If the reported performance gains are reproducible and the simulator dynamics are shown to be faithful to real superbikes, the work would supply a useful initial benchmark in an underexplored domain. The self-paced curriculum mechanism, which generates tasks automatically from agent performance, is a practical contribution that avoids hand-crafted curricula. The explicit inclusion of lean-angle history in the observation is a domain-appropriate design choice.
major comments (2)
- [Abstract] Abstract: the assertion that the VRider SBK simulator is 'physics-accurate' is load-bearing for the claim that the SPDL-vs-SAC comparison establishes a meaningful baseline, yet the manuscript supplies no quantitative validation (e.g., lean-angle time-series correlation, steering-response matching, or comparison against real telemetry).
- [Abstract] Abstract: the central empirical claim that 'SPDL outperforms SAC alone in training efficiency, lap time, and driving stability' is stated without any numerical metrics, error bars, statistical tests, ablation tables, or learning-curve figures, rendering the strength of the evidence impossible to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below and will revise the manuscript to strengthen the presentation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the VRider SBK simulator is 'physics-accurate' is load-bearing for the claim that the SPDL-vs-SAC comparison establishes a meaningful baseline, yet the manuscript supplies no quantitative validation (e.g., lean-angle time-series correlation, steering-response matching, or comparison against real telemetry).
Authors: We agree that the unqualified term 'physics-accurate' is not supported by quantitative evidence in the manuscript. The work is intended as a simulation baseline rather than a claim of real-world transfer. In the revised manuscript we will replace the phrase with 'Unity-based motorbike simulator incorporating two-wheeled dynamics' and add a short paragraph in Section 3 describing the simulator's modeling assumptions and known limitations. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim that 'SPDL outperforms SAC alone in training efficiency, lap time, and driving stability' is stated without any numerical metrics, error bars, statistical tests, ablation tables, or learning-curve figures, rendering the strength of the evidence impossible to assess.
Authors: The abstract follows the conventional practice of summarizing results at a high level while deferring quantitative details to the body of the paper. However, we accept that the current wording makes the strength of the evidence difficult to judge from the abstract alone. We will revise the abstract to include concise numerical highlights (e.g., relative lap-time reduction and training-step savings) together with explicit references to the learning-curve figures and statistical tables already present in Section 5. revision: yes
Circularity Check
No circularity: purely empirical RL comparison with no derivation chain
full rationale
The paper reports experimental results from training SAC and SPDL agents in the VRider SBK simulator and compares their training efficiency, lap times, and stability. No equations, first-principles derivations, or predictions are presented that could reduce to fitted parameters or self-referential definitions. The core claim rests on direct simulation runs rather than any analytical chain. Self-citations, if present for the SPDL method, are not load-bearing for the reported performance deltas, which are measured independently. This matches the default case of an empirical paper whose results are falsifiable outside any internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The reward signal shaped to encourage track progress while penalizing instability-inducing behaviors is appropriate for two-wheeled dynamics.
Reference graph
Works this paper leans on
-
[1]
Super- human performance in gran turismo sport using deep reinforcement learning,
F. Fuchs, Y . Song, E. Kaufmann, D. Scaramuzza, and P. D ¨urr, “Super- human performance in gran turismo sport using deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4257–4264, 2021
2021
-
[2]
Outracing champion gran turismo drivers with deep reinforcement learning,
P. R. Wurman, S. Barrett, K. Kawamoto, J. MacGlashan, K. Subrama- nian, T. J. Walsh, R. Capobianco, A. Devlic, F. Eckert, and F. Fuchs, “Outracing champion gran turismo drivers with deep reinforcement learning,”Nature, vol. 602, no. 7896, pp. 223–228, 2022
2022
-
[3]
A super-human vision-based reinforcement learning agent for autonomous racing in gran turismo,
M. Vasco, T. Seno, K. Kawamoto, K. Subramanian, P. R. Wurman, and P. Stone, “A super-human vision-based reinforcement learning agent for autonomous racing in gran turismo,” inProceedings of the 2024 Reinforcement Learning Conference (RLC), 2024
2024
-
[4]
A champion-level vision-based reinforcement learning agent for competitive racing in gran turismo 7,
H. Lee, T. Seno, J. J. Tai, K. Subramanian, K. Kawamoto, P. Stone, and P. R. Wurman, “A champion-level vision-based reinforcement learning agent for competitive racing in gran turismo 7,”IEEE Robotics and Automation Letters (RA-L), 2025
2025
-
[5]
Self-paced deep reinforcement learning,
P. Klink, C. D’Eramo, J. R. Peters, and J. Pajarinen, “Self-paced deep reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 9216–9227, 2020
2020
-
[6]
A probabilistic interpretation of self-paced learning with applications to reinforcement learning,
P. Klink, H. Abdulsamad, B. Belousov, C. D’Eramo, J. Peters, and J. Pajarinen, “A probabilistic interpretation of self-paced learning with applications to reinforcement learning,”Journal of Machine Learning Research, vol. 22, no. 182, pp. 1–52, 2021
2021
-
[7]
Curriculum reinforcement learning via constrained optimal transport,
P. Klink, H. Yang, C. D’Eramo, J. Peters, and J. Pajarinen, “Curriculum reinforcement learning via constrained optimal transport,” inProceed- ings of the International Conference on Machine Learning (ICML). PMLR, 2022, pp. 11 341–11 358
2022
-
[8]
Au- tonomous overtaking in gran turismo sport using curriculum rein- forcement learning,
Y . Song, H. Lin, E. Kaufmann, P. D ¨urr, and D. Scaramuzza, “Au- tonomous overtaking in gran turismo sport using curriculum rein- forcement learning,” inProceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 9403–9409
2021
-
[9]
Out-of-distribution generalization with a sparc: Racing 100 unseen vehicles with a single policy,
B. Grooten, P. MacAlpine, K. Subramanian, P. Stone, and P. R. Wurman, “Out-of-distribution generalization with a sparc: Racing 100 unseen vehicles with a single policy,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[10]
Unity: A general platform for intelligent agents,
A. Juliani, V .-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y . Gao, H. Henry, M. Mattar, and D. Lange, “Unity: A general platform for intelligent agents,”arXiv preprint arXiv:1809.02627, 2020. [Online]. Available: https://arxiv.org/pdf/1809.02627.pdf
-
[11]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.