SPOQ: Specialist Orchestrated Queuing for Multi-Agent Software Engineering
Pith reviewed 2026-06-28 09:37 UTC · model grok-4.3
The pith
SPOQ's wave dispatch, dual validation, and human integration let multi-agent systems approach critical-path speeds with 99.75 percent test pass rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
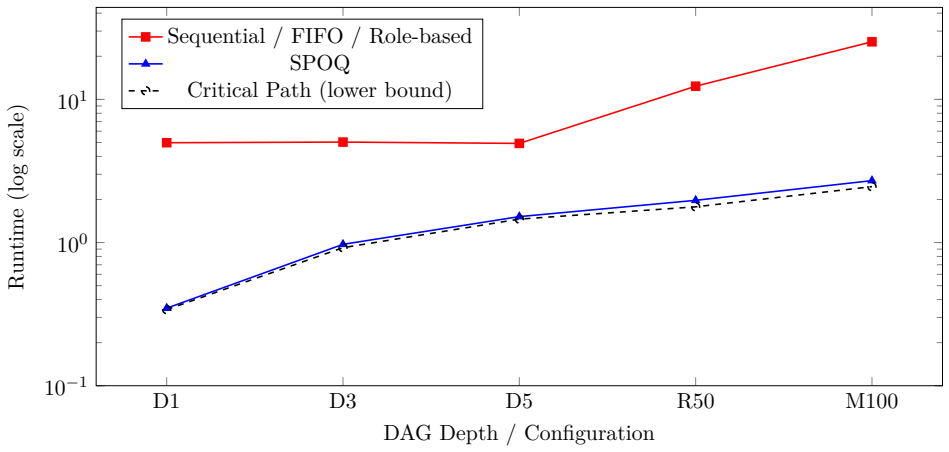
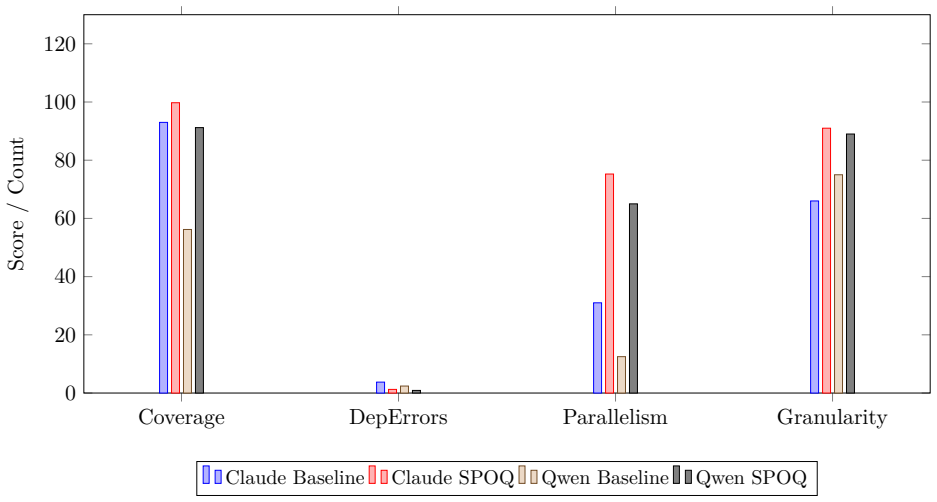
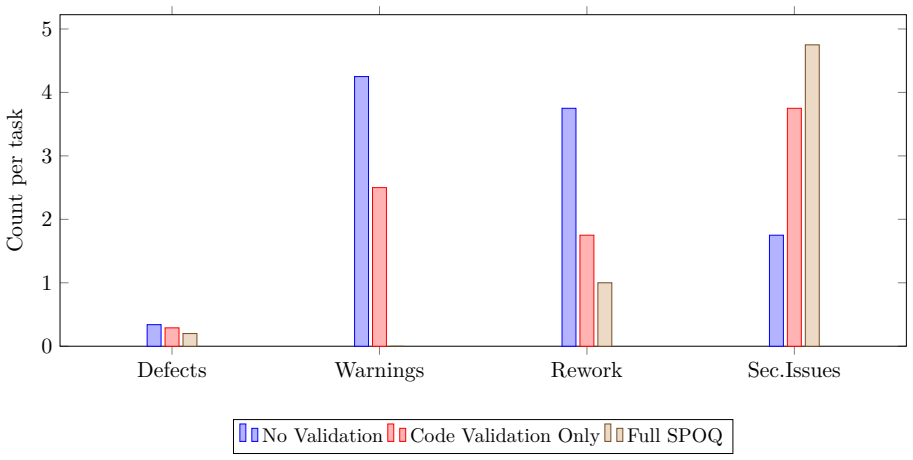
SPOQ uses wave-based topological dispatch from dependency graphs, dual validation gates before and after execution, and Human-as-an-Agent integration inside a three-tier hierarchy of Opus workers, Sonnet reviewers, and Haiku investigators. This combination yields execution ratios of 1.03-1.11 to the critical-path lower bound, eliminates cyclic plans, raises parallelism from 31 to 75.25, reduces defects to 0.20 per task, and achieves 99.75 percent test pass rates, with further defect cuts to 0.03 under human review. The gains replicate on a locally hosted open-weights model and hold across a longitudinal study of 1,822 tasks.
What carries the argument
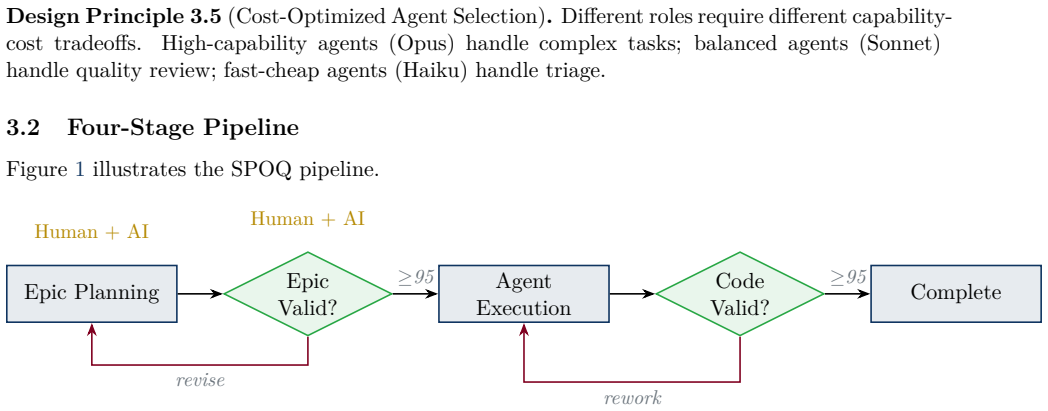
Wave-based topological dispatch that computes parallel execution waves from task dependency graphs, together with dual validation gates and Human-as-an-Agent integration.
Load-bearing premise
The reported speed and quality gains are produced by the wave dispatch, dual validation, and human integration rather than by unstated choices in task selection, model prompting, or evaluation criteria.
What would settle it
Run the identical set of tasks once with full SPOQ and once with the wave dispatch replaced by standard sequential or random scheduling, then check whether the 1.03-1.11 ratio to critical path and the parallelism increase both disappear.
Figures

read the original abstract
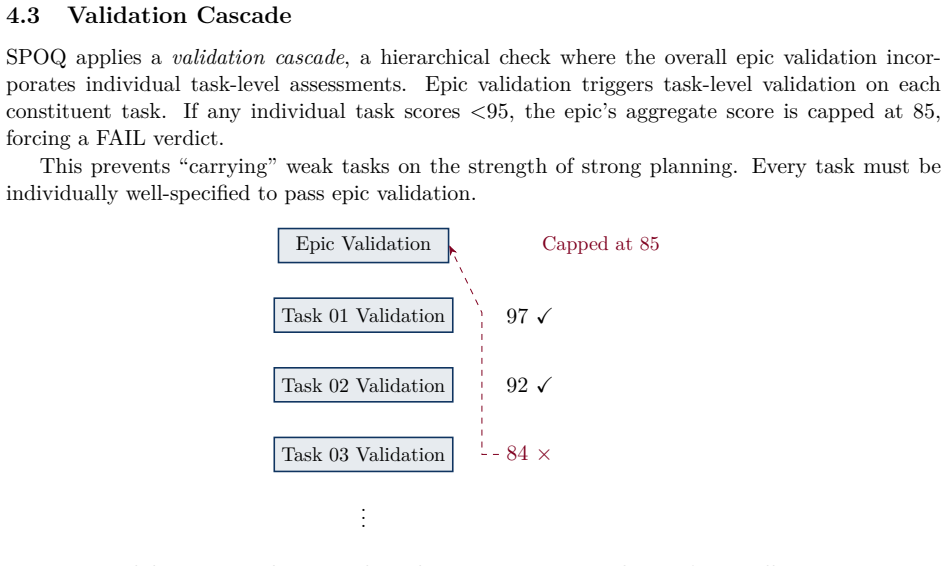
Multi-agent AI systems show promise for automating software engineering tasks, yet existing approaches suffer from coordination overhead, quality control gaps, and limited human oversight. We introduce SPOQ (Specialist Orchestrated Queuing), a methodology combining three innovations: (1) wave-based topological dispatch that computes parallel execution waves from task dependency graphs; (2) dual validation gates applying quality metrics before execution (planning validation) and after (code validation) to reduce rework cycles; and (3) Human-as-an-Agent (HaaA) integration, where a human specialist participates in decomposition and can be consulted during execution. SPOQ uses a three-tier agent hierarchy (Opus workers, Sonnet reviewers, Haiku investigators) to optimize cost-quality tradeoffs. We evaluate SPOQ through four experiments. Experiment 1: wave dispatch approaches the critical-path lower bound (ratio 1.03--1.11, speedup up to 14.3x); on a 2-slot local backend it delivers a stable 1.4x speedup. Experiment 2: SPOQ improves planning coverage from 93.0 to 99.75, eliminates cyclic plans, and lifts parallelism from 31.0 to 75.25. Experiment 3: dual validation reduces defects from 0.34 to 0.20 per task and lifts test pass rate from 91.25% to 99.75%. Experiment 4: human review reduces residual defects from 0.47 to 0.03 per task. Results are replicated on a locally hosted open-weights model (Qwen3.6-35B-A3B), verifying gains are attributable to orchestration rather than any specific model. A longitudinal study across 17 repositories, 8,589 commits, 1,822 tasks, and 13,866 tests (99.87% pass rate) provides ecological validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPOQ, a multi-agent orchestration methodology for software engineering tasks that combines three innovations: wave-based topological dispatch from task dependency graphs, dual validation gates (planning and code), and Human-as-an-Agent (HaaA) integration. It employs a three-tier agent hierarchy (Opus workers, Sonnet reviewers, Haiku investigators) and reports four experiments plus a longitudinal study: wave dispatch reaches 1.03-1.11× the critical-path lower bound (up to 14.3× speedup, 1.4× on 2-slot backend); planning coverage improves to 99.75% with higher parallelism; dual validation reduces defects from 0.34 to 0.20 per task and raises test pass rate from 91.25% to 99.75%; human review further cuts defects to 0.03; a study across 17 repositories, 1,822 tasks, and 13,866 tests achieves 99.87% pass rate. Gains are replicated on Qwen3.6-35B-A3B and attributed to the orchestration rather than model choice.
Significance. If the reported gains can be isolated to the three innovations via transparent controls, the work would provide a practical contribution to multi-agent SE by showing how topological dispatching, staged validation, and selective human involvement can reduce coordination overhead and defects while approaching theoretical speed limits. The replication on an open-weights model and the ecological validation over 8,589 commits are strengths that support generalizability claims.
major comments (2)
- [Abstract / Experiments] Abstract / Experiments 1-4: The central claim that speedups, defect reductions (0.34→0.20 then 0.47→0.03), and pass-rate lifts (91.25%→99.75%, 99.87%) are attributable to wave dispatch, dual validation, and HaaA rather than task selection, prompting, or scoring choices requires explicit baseline definitions and controls; the manuscript supplies no description of the exact baseline agent configurations, dependency-graph construction procedure, or whether repositories were chosen before or after observing outcomes.
- [Experiment 3] Experiment 3: The defect and pass-rate improvements are presented as direct effects of dual validation, yet without reported variance, error bars, or pre-specified success criteria for defect counting and test-pass definitions, it is unclear whether the deltas (0.34 to 0.20; 91.25% to 99.75%) can be isolated from evaluation choices.
minor comments (2)
- [Longitudinal study] The extremely high pass rates (99.75%, 99.87%) would be more convincing with accompanying confidence intervals or per-repository breakdowns to address possible measurement sensitivity.
- [Experiment 1] Clarify the precise definition of 'critical-path lower bound' and how parallelism is measured (e.g., average waves or task concurrency) in Experiment 1 and 2.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript accordingly to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract / Experiments 1-4: The central claim that speedups, defect reductions (0.34→0.20 then 0.47→0.03), and pass-rate lifts (91.25%→99.75%, 99.87%) are attributable to wave dispatch, dual validation, and HaaA rather than task selection, prompting, or scoring choices requires explicit baseline definitions and controls; the manuscript supplies no description of the exact baseline agent configurations, dependency-graph construction procedure, or whether repositories were chosen before or after observing outcomes.
Authors: We agree that the manuscript requires more explicit documentation to support attribution of gains to the three innovations. The revised version will add a dedicated 'Baseline and Control Configurations' subsection describing the exact agent hierarchies, prompting templates, and scoring functions used in all control conditions. The dependency-graph construction procedure (including the topological sort and wave partitioning algorithm) will be specified in full with pseudocode. Repository selection occurred prior to any outcome observation according to fixed criteria (public repositories with ≥500 commits, existing test suites, and language diversity); this protocol and the list of selection criteria will be stated explicitly in a new 'Ecological Validation Setup' paragraph. These changes will allow readers to evaluate the isolation of effects from wave dispatch, dual validation, and HaaA. revision: yes
-
Referee: [Experiment 3] Experiment 3: The defect and pass-rate improvements are presented as direct effects of dual validation, yet without reported variance, error bars, or pre-specified success criteria for defect counting and test-pass definitions, it is unclear whether the deltas (0.34 to 0.20; 91.25% to 99.75%) can be isolated from evaluation choices.
Authors: We accept that the current presentation of Experiment 3 lacks sufficient statistical detail. The revision will introduce a 'Evaluation Metrics and Protocol' section that pre-specifies defect counting (two independent annotators, Cohen's kappa reported) and test-pass criteria (all tests in the suite must pass). We will also add error bars to the relevant figures. Because the original runs were single-trial due to compute limits, we will perform five additional seeded replications of the dual-validation conditions and report means plus standard deviations; if resource constraints prevent full replication, we will note this limitation and provide the protocol for future verification. revision: partial
Circularity Check
No circularity: results are empirical measurements on external tasks
full rationale
The paper introduces a methodology (wave dispatch, dual validation, HaaA) and reports performance numbers from four experiments plus a longitudinal study across external repositories. No equations, fitted parameters, or derivation steps are present that would reduce any reported ratio, speedup, defect count, or pass rate to a quantity defined by the method itself. The abstract and experiments frame outcomes as direct measurements (e.g., critical-path ratio 1.03-1.11, defect reduction 0.34 to 0.20) on task sets drawn from 17 repositories, with replication on Qwen3.6-35B-A3B. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the central claims. The derivation chain is therefore self-contained as an empirical evaluation rather than a closed mathematical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ChatDev: Communicative Agents for Software Development
ChatDev: Communicative Agents for Software Development , author=. arXiv preprint arXiv:2307.07924 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2312.17025 , year=
Experiential Co-Learning of Software-Developing Agents , author=. arXiv preprint arXiv:2312.17025 , year=
-
[3]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. arXiv preprint arXiv:2308.00352 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.19118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT , author=. arXiv preprint arXiv:2302.11382 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. arXiv preprint arXiv:2308.08155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Journal of Artificial Intelligence Research , volume=
SHOP2: An HTN Planning System , author=. Journal of Artificial Intelligence Research , volume=
-
[10]
Acta Informatica , volume=
Optimal Scheduling for Two-Processor Systems , author=. Acta Informatica , volume=. 1972 , publisher=
1972
-
[11]
Proceedings of the Eastern Joint Computer Conference , pages=
Critical-Path Planning and Scheduling , author=. Proceedings of the Eastern Joint Computer Conference , pages=
-
[12]
2003 , publisher=
Agile Software Development: Principles, Patterns, and Practices , author=. 2003 , publisher=
2003
-
[13]
Agile Alliance , year=
Manifesto for Agile Software Development , author=. Agile Alliance , year=
-
[14]
2017 , publisher=
Clean Architecture: A Craftsman's Guide to Software Structure and Design , author=. 2017 , publisher=
2017
-
[15]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Anthropic Technical Documentation , year=
The Claude Model Family , author=. Anthropic Technical Documentation , year=
-
[17]
Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems , pages=
Guidelines for Human-AI Interaction , author=. Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems , pages=
2019
-
[18]
A Survey on Large Language Model based Autonomous Agents
A Survey on Large Language Model based Autonomous Agents , author=. arXiv preprint arXiv:2308.11432 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2023 , note=
Auto-GPT: An Autonomous GPT-4 Experiment , author=. 2023 , note=
2023
-
[20]
2023 , note=
BabyAGI: AI-powered Task Management System , author=. 2023 , note=
2023
-
[21]
2024 , note=
Devin: The First AI Software Engineer , author=. 2024 , note=
2024
-
[22]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. arXiv preprint arXiv:2407.16741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2024 , note=
Aider: AI Pair Programming in Your Terminal , author=. 2024 , note=
2024
-
[24]
2023 , note=
GPT-Engineer: Specify What You Want It to Build, the AI Asks for Clarification, and Then Builds It , author=. 2023 , note=
2023
-
[25]
2024 , howpublished=
Moura, Jo\. 2024 , howpublished=
2024
-
[26]
2024 , howpublished=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.