Guide Me Out: A Framework to Benchmark VLM Operators Communication in Crisis Scenarios
Pith reviewed 2026-06-27 16:47 UTC · model grok-4.3
The pith
Narrowcast communication from vision-language models reduces civilian failure rates compared to broadcast in simulated evacuations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
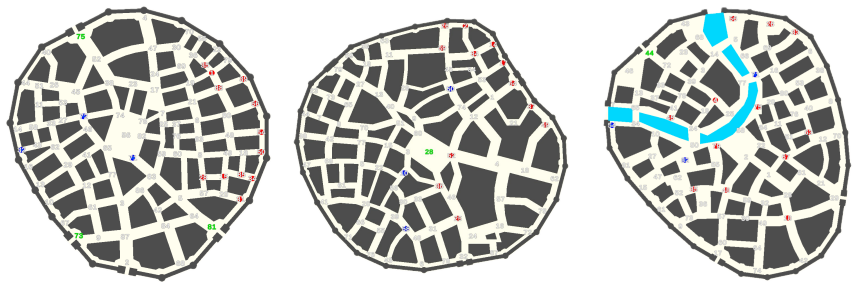
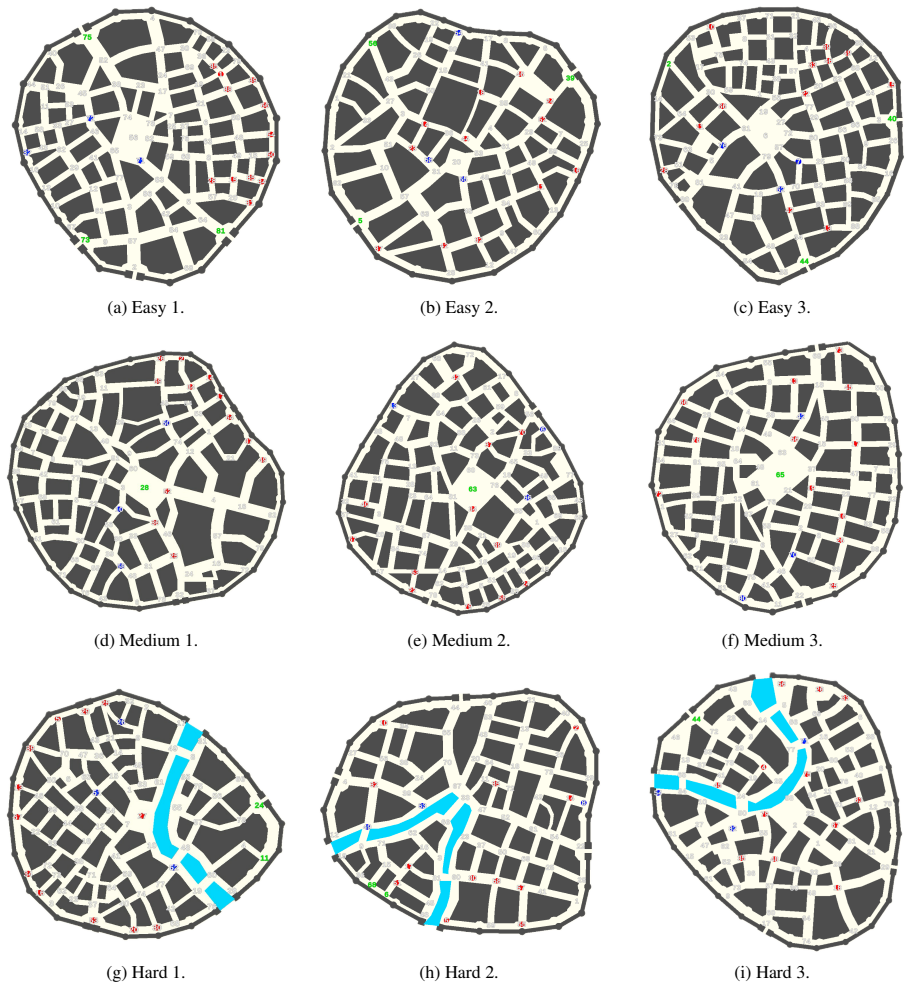
The authors introduce a simulation framework in which VLMs must produce natural-language guidance for civilian agents escaping nine maps that differ in structural complexity. Two message styles are compared—narrowcast, which addresses specific agents, versus broadcast, which addresses everyone—and two world representations—pure visual input versus visual input plus an adjacency graph—while threats are either static or moving. Narrowcast lowers civilian fail rates across all difficulty levels; visual input drives performance while the added graph is model-dependent and frequently harmful; moving threats increase fail rates in every condition because guidance must adapt continuously.
What carries the argument
The benchmarking framework that systematically varies communication strategy (narrowcast versus broadcast), environment representation (visual versus graph-augmented), and threat dynamics (static versus moving) across nine maps of increasing structural complexity.
If this is right
- Narrowcast messaging should be the default choice for VLM operators in evacuation tasks because it lowers failure rates at every tested difficulty.
- Visual input alone is the more reliable representation; adding an adjacency graph does not reliably improve and can degrade performance.
- Systems using VLMs for guidance must incorporate mechanisms for continuous re-planning when threats move.
- Benchmark outcomes can be used to decide which combination of strategy and representation to deploy for a given VLM.
- The framework provides a repeatable testbed for comparing future models on the same evacuation scenarios.
Where Pith is reading between the lines
- The same narrowcast advantage might appear in other spatially grounded tasks such as robot-assisted search and rescue.
- Real deployments would still need to handle noisy sensor data and uncertain civilian compliance, factors not yet tested here.
- Extending the maps to include multi-floor buildings or partial visibility could expose new failure modes for visual-only representations.
- The model-dependent harm from graphs suggests that future work should test graph construction methods tailored to each VLM rather than using a single fixed graph.
Load-bearing premise
The simulated maps, threat behaviors, and agent interactions capture the main difficulties that would appear in actual crisis evacuations.
What would settle it
A controlled physical evacuation exercise in which human participants receive either narrowcast or broadcast VLM-generated instructions and the difference in successful exits is measured directly.
Figures




read the original abstract
Effective crisis response requires spatially grounded communication that bridges linguistic guidance of civilians with the physical environment, accounting for structural bottlenecks, evolving threats, and agent-specific contexts. Yet, current NLP research in crisis communication remains mainly limited to static, text-only classification settings, overlooking the critical communicative role of AI operators in dynamic, embodied scenarios. We address this gap with a novel benchmarking framework for evaluating Vision-Language Models (VLMs) tasked with guiding civilian agents through simulated evacuations. We test two communication strategies (narrowcast vs. broadcast), two environment representations (visual vs. graph-based), and two threat behaviors (static vs. moving) across nine maps of varying structural complexity. Our results show that Narrowcast consistently reduces civilian Fail rates compared to Broadcast across all difficulty levels. Guidance quality depends heavily on how the VLM operator represents the world: the visual modality drives performance, while adding an adjacency graph is model-dependent and often harmful. Moving threats raise Fail rates across all conditions as communication must continuously adapt over time. Together, these findings show that deploying VLMs as AI operators in evacuation scenarios remains a non-trivial challenge, where the choice of communication strategy and input representation can directly determine the success or failure of the intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmarking framework for VLMs acting as operators to guide civilian agents through simulated evacuations. It compares narrowcast vs. broadcast communication strategies, visual vs. graph-based world representations, and static vs. moving threats across nine maps of varying structural complexity, reporting that narrowcast consistently lowers fail rates, visual modality drives performance (with graphs often harmful), and moving threats raise fail rates in all conditions.
Significance. If the simulation is representative, the work provides a novel empirical benchmark addressing the gap in dynamic, embodied crisis communication for VLMs, with direct measurements of strategy and modality effects. The purely empirical design with no fitted parameters is a strength, but the unvalidated mapping to real crises limits immediate applicability to deployment decisions.
major comments (2)
- [Abstract] Abstract and results: the claim of 'consistent directional trends' across difficulty levels provides no details on statistical tests, number of runs per condition, specific VLM models and versions, error bars, or data exclusion criteria, leaving the strength of evidence for the central claims (narrowcast superiority, visual dominance) difficult to evaluate.
- [Experiments] Simulation setup (Experiments section): the headline recommendation that these outcomes can inform VLM deployment decisions rests on the untested assumption that the nine hand-crafted maps, stylized threat dynamics, and agent rules capture representative real-world complexities such as structural bottlenecks and evolving threats; no calibration to documented evacuation data, expert realism review, or sensitivity analysis to omitted factors (panic, noise, partial observability) is described.
minor comments (2)
- [Methods] Specify the exact set of VLMs evaluated and any prompting or fine-tuning details in the methods to allow replication.
- [Evaluation Metrics] Clarify how 'Fail rates' are defined operationally and whether civilian agent behaviors are deterministic or stochastic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and scope.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the claim of 'consistent directional trends' across difficulty levels provides no details on statistical tests, number of runs per condition, specific VLM models and versions, error bars, or data exclusion criteria, leaving the strength of evidence for the central claims (narrowcast superiority, visual dominance) difficult to evaluate.
Authors: We agree that the abstract and results presentation would benefit from greater methodological transparency. The full manuscript describes experiments across nine maps with multiple conditions, but we will revise the abstract and Experiments section to explicitly report the number of runs per condition, the specific VLM models and versions tested, error bars or variance measures, any statistical tests supporting the directional trends, and data exclusion criteria where applicable. This will allow readers to better evaluate the evidence for narrowcast and visual representation effects. revision: yes
-
Referee: [Experiments] Simulation setup (Experiments section): the headline recommendation that these outcomes can inform VLM deployment decisions rests on the untested assumption that the nine hand-crafted maps, stylized threat dynamics, and agent rules capture representative real-world complexities such as structural bottlenecks and evolving threats; no calibration to documented evacuation data, expert realism review, or sensitivity analysis to omitted factors (panic, noise, partial observability) is described.
Authors: The work is framed as a controlled benchmarking framework to isolate effects of communication strategy and environment representation rather than a calibrated real-world model. We will revise the discussion and conclusion to more explicitly state the stylized nature of the maps and threat dynamics, note the absence of calibration to real evacuation data or expert review, and qualify any implications for deployment as requiring additional validation. This will prevent overgeneralization while retaining the benchmark's value for controlled comparisons. revision: yes
Circularity Check
Empirical benchmarking study with no derivations or self-referential reductions
full rationale
The paper describes a simulation-based benchmarking framework that directly measures outcomes (fail rates) under different communication strategies, modalities, and threat conditions across nine maps. No equations, fitted parameters, or derivation chains are present that could reduce results to inputs by construction. Claims rest on explicit simulation measurements rather than any self-definition, fitted-input prediction, or self-citation load-bearing step. The work is self-contained as an empirical evaluation; external validity concerns (simulation fidelity) fall outside circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simulated evacuation scenarios with the tested maps and threat models are representative of real-world crisis situations.
Reference graph
Works this paper leans on
-
[1]
Talk the Walk: Navigating New York City through Grounded Dialogue
Towards personalised public warnings: har- nessing technological advancements to promote bet- ter individual decision-making in the face of disasters. International Journal of Digital Earth, 10(12):1231– 1252. Pei Dang, Jun Zhu, Weilian Li, Yakun Xie, and Heng Zhang. 2025. Large-language-model-driven agents for fire evacuation simulation in a cellular aut...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
TagaVLM: Topology-Aware Global Action Reasoning for Vision-Language Navigation
Twitter as a lifeline: Human-annotated Twit- ter corpora for NLP of crisis-related messages. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC‘16), pages 1638–1643, Portorož, Slovenia. European Lan- guage Resources Association (ELRA). Jiaxing Liu, Zexi Zhang, Xiaoyan Li, Boyue Wang, Yongli Hu, and Baocai Yin. ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
In2024 IEEE Con- ference on Artificial Intelligence (CAI), pages 851– 859
Llm-assisted crisis management: Building advanced llm platforms for effective emergency re- sponse and public collaboration. In2024 IEEE Con- ference on Artificial Intelligence (CAI), pages 851– 859. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bern- stein. 2023. Generative agents: Interactive simul...
-
[4]
Crisissense-llm: Instruction fine-tuned large language model for multi-label social media text classification in disaster informatics.Preprint, arXiv:2406.15477. Gengze Zhou, Yicong Hong, and Qi Wu. 2024. Navgpt: Explicit reasoning in vision-and-language naviga- tion with large language models. InProceedings of the AAAI Conference on Artificial Intelligen...
-
[5]
command":
Recommended exit: 26 bottom edge.’→ {"command":"goto","target":"14"} C.3 Context across turns At every simulation turn, each agent is queried with the standard multi-turn chat format: a fixed system prompt followed by an alternating sequence of user and assistant messages, one pair per turn. In the image-enabled modalities (ImageandImage + Graph), the use...
-
[6]
Avoiding waypoints near threats
-
[7]
Moving toward the nearest safe exit
-
[8]
Only push through a risky path if there is no safer alternative
Weigh safety against progress: if a threat blocks the direct path, detour away from the exit to find a safer route. Only push through a risky path if there is no safer alternative. A longer safe path is better than a short dangerous one
-
[9]
response
Do not send the civilian back to the waypoint they just came from unless all other moves are unsafe Your response must: - Name the target waypoint clearly User Analyze the image and the positional data, and guide the civilian to safety. Current position: {currentWaypoint} Adjacent waypoints: {adjacentWaypoints} Safe waypoints: {safepoints} Threat position...
-
[10]
Warn about the nearest threats
-
[11]
Indicate the nearest safe zone(s)
-
[12]
C.6 BC Operator The broadcast operator addresses all civilians on the map with a single shared message at each turn
End with your suggested waypoint (e.g., ‘Move to X’) Respond with a short instruction (under 250 chars). C.6 BC Operator The broadcast operator addresses all civilians on the map with a single shared message at each turn. The message must describe the danger landscape and the recommended exit(s) in terms civilians can interpret from their own local view. ...
-
[13]
[<=4 threats: list individually | 5+ threats: group into DANGER ZONES, summarize clusters]
-
[14]
goto”. Always use “goto
Warn about exits near threats and RECOMMEND the SAFEST exit(s) and their location on the map (e.g., ‘top-left corner’, ‘along the bottom edge’) Respond with a short message (under 250 chars). C.7 Civilian A single civilian prompt is used in all condi- tions. The operator’s instruction is injected through {operatorMessage}, and few-shot examples cover both...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.