Agent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads
Pith reviewed 2026-06-28 01:07 UTC · model grok-4.3
The pith
A phase-aware profiling of ten agent memory systems shows design choices shift costs between write and read paths, producing ten system recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
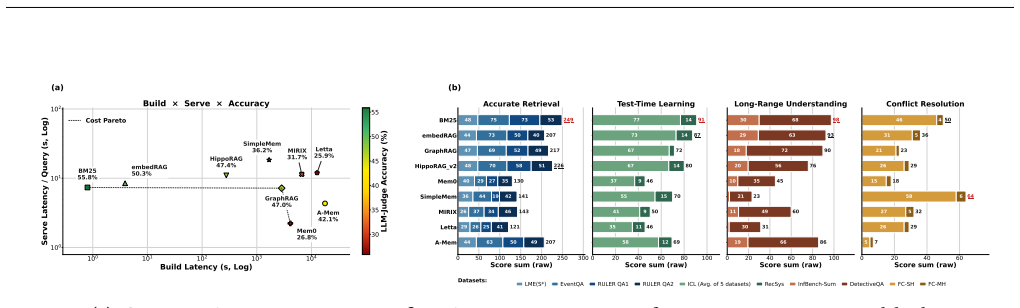
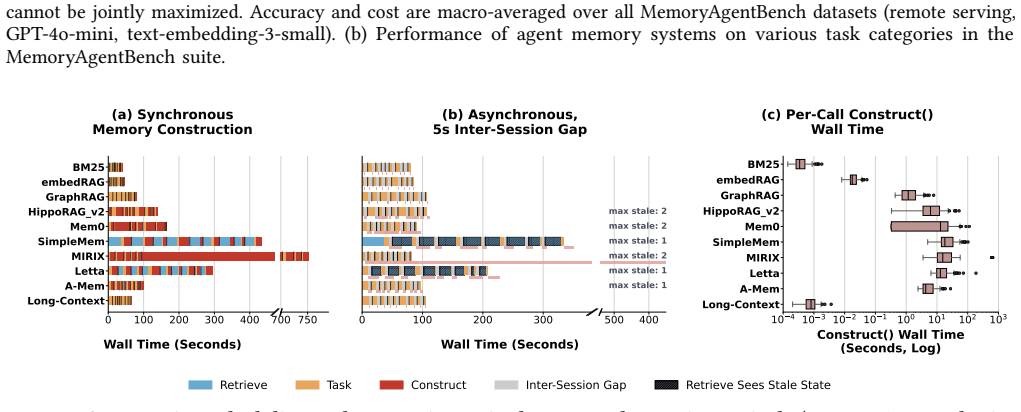
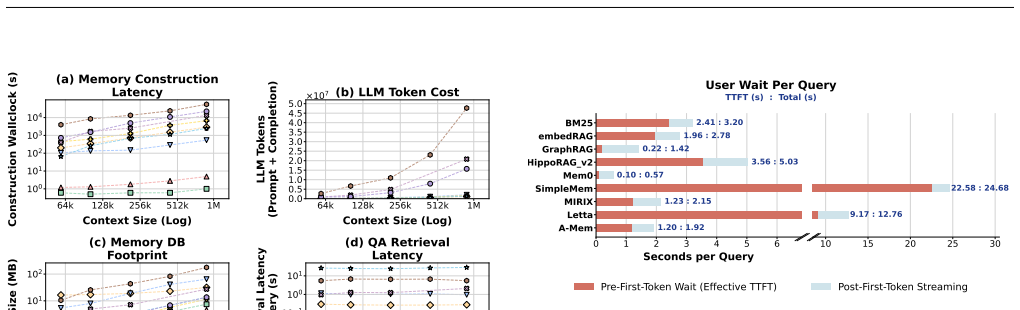
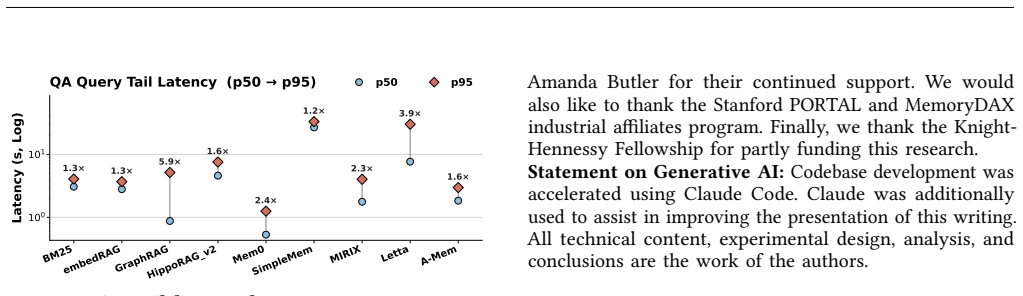
By classifying agent memory systems along four axes and applying a phase-aware profiling harness that isolates costs in construction, retrieval, and generation, the study of ten representative systems on two benchmarks demonstrates that design choices systematically shift cost between the write and read paths, from which ten concrete system recommendations follow.
What carries the argument
A system-oriented taxonomy along four axes combined with a phase-aware profiling harness that attributes cost to construction, retrieval, and generation phases.
If this is right
- Construction scheduling can be adjusted to lower total system cost.
- Capability floors set minimum performance requirements for deployed memory.
- Higher query volumes amortize fixed construction costs across more operations.
- Freshness-latency tradeoffs must be explicitly managed in system design.
- Fleet-scale management becomes necessary once many agents share memory resources.
Where Pith is reading between the lines
- The four-axis taxonomy could be used to classify new memory systems as they appear without re-running the full profiling harness.
- The observed write-read cost shifts may guide hardware or storage-layer choices for hosting long-running agents.
- Recommendations on amortization imply that low-volume agent workloads may require different designs than high-volume ones.
- Extending the profiling harness to measure end-to-end task success rather than isolated phase costs could connect system metrics to agent capability.
Load-bearing premise
The ten chosen systems and two benchmark suites are sufficient to expose the dominant cost tradeoffs across the wider space of agent memory designs.
What would settle it
Profiling a substantially larger collection of systems or additional benchmarks and finding cost-shift patterns that diverge from those observed in the original ten systems would falsify the claimed generality of the characterization.
Figures


read the original abstract
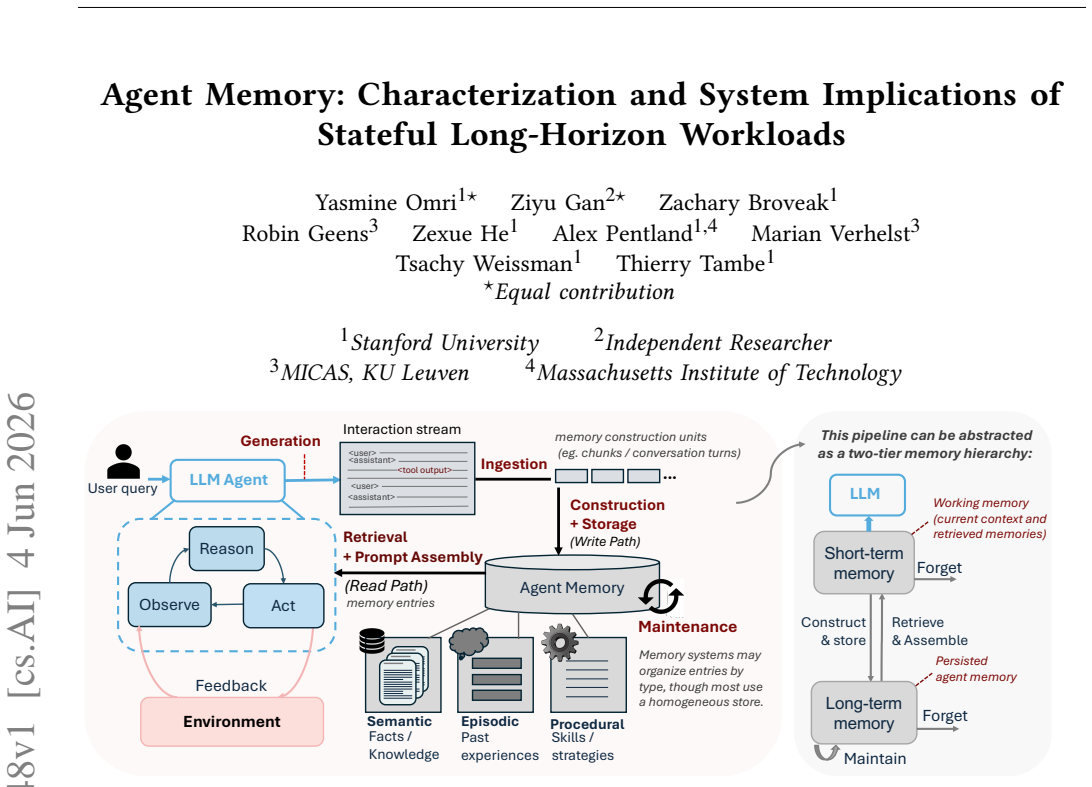
LLM agents are increasingly deployed on long-horizon tasks requiring sustained reasoning over extended interaction histories. Realizing this at scale requires agents to persistently store, retrieve, and update their own memory across sessions. A rich ecosystem of agent memory systems has emerged spanning flat retrieval, LLM-mediated extraction, consolidating fact stores, and agentic control flows. Yet, their system-level behavior remains uncharacterized. We present the first systems characterization of agent memory. First, we introduce a system-oriented taxonomy classifying agent memory systems along four axes. Second, we build a phase-aware profiling harness attributing cost to construction, retrieval, and generation. Third, we characterize ten representative systems across two benchmark suites, uncovering how design choices shift cost across the write and read paths. Finally, we derive 10 system recommendations covering construction scheduling, capability floors, amortization via query volume, freshness-latency tradeoffs, and fleet-scale management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systems characterization of agent memory for LLM agents on long-horizon tasks. It introduces a four-axis taxonomy for classifying agent memory systems, develops a phase-aware profiling harness to attribute costs to construction, retrieval, and generation phases, empirically evaluates ten representative systems across two benchmark suites to reveal cost shifts between write and read paths, and derives ten system recommendations regarding construction scheduling, capability floors, amortization, freshness-latency tradeoffs, and fleet-scale management.
Significance. If the empirical findings hold, the work provides timely and actionable insights into an emerging area of LLM agent infrastructure where persistent memory is required for sustained reasoning. The phase-aware cost attribution and derivation of concrete recommendations represent strengths that could directly influence system design choices. The empirical measurement study approach is appropriate for the claims made.
major comments (2)
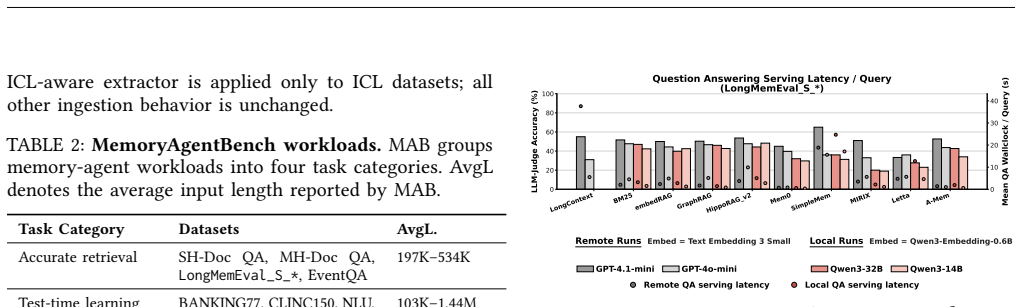
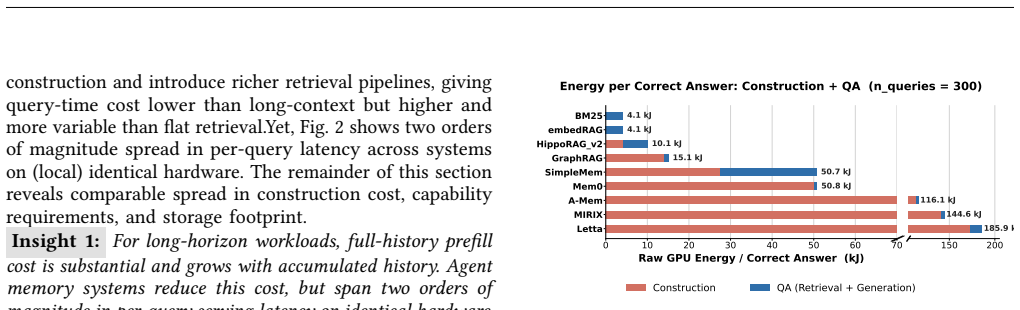
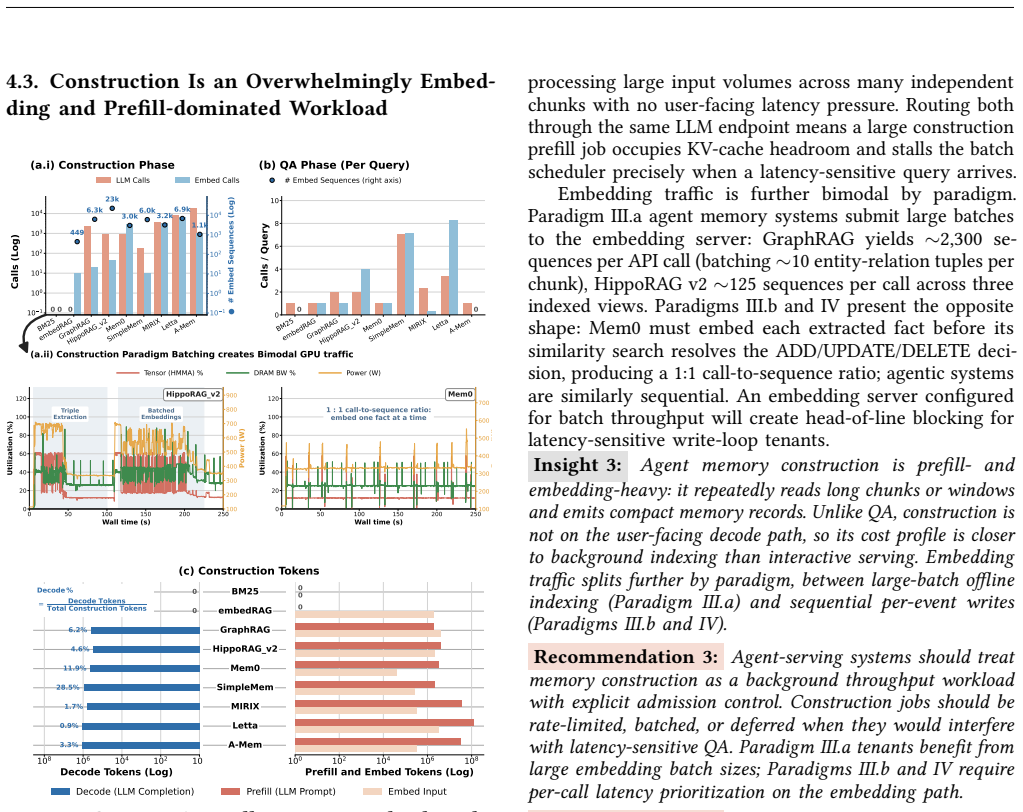
- [Section 5] Section 5 (Characterization of ten systems): The selection of the ten representative systems is presented without an explicit coverage analysis or justification relative to the four-axis taxonomy from Section 3. If the chosen systems do not adequately sample quadrants involving high-frequency updates or agentic control flows, the observed cost shifts across write/read paths and the generalization to ten system recommendations cannot be treated as dominant for the broader design space.
- [Section 5.2] Section 5.2 (Benchmark suites): The two benchmark suites are used to drive the characterization, but the manuscript provides no discussion of how these suites were selected or their coverage of long-horizon task distributions relative to other potential workloads. This is load-bearing for claims about general system implications and cost tradeoffs.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly name the two benchmark suites and the four taxonomy axes to improve readability for readers unfamiliar with the agent memory ecosystem.
- Figure captions and axis labels in the cost attribution plots should include units and error bar definitions for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate explicit justifications as outlined.
read point-by-point responses
-
Referee: [Section 5] Section 5 (Characterization of ten systems): The selection of the ten representative systems is presented without an explicit coverage analysis or justification relative to the four-axis taxonomy from Section 3. If the chosen systems do not adequately sample quadrants involving high-frequency updates or agentic control flows, the observed cost shifts across write/read paths and the generalization to ten system recommendations cannot be treated as dominant for the broader design space.
Authors: We agree that an explicit coverage analysis was not provided in Section 5. The ten systems were selected to span the design space outlined in the four-axis taxonomy of Section 3, but we will add a dedicated table and accompanying text in the revision that maps each system to the axes. This will explicitly demonstrate coverage, including of high-frequency update and agentic control flow quadrants, thereby supporting the generalizability of the cost-shift observations and recommendations. revision: yes
-
Referee: [Section 5.2] Section 5.2 (Benchmark suites): The two benchmark suites are used to drive the characterization, but the manuscript provides no discussion of how these suites were selected or their coverage of long-horizon task distributions relative to other potential workloads. This is load-bearing for claims about general system implications and cost tradeoffs.
Authors: We acknowledge that Section 5.2 lacks explicit discussion of benchmark selection and coverage. The suites were chosen for their established use in long-horizon agent tasks with varying interaction lengths and complexities. In revision we will expand the section with a rationale for their selection, summary statistics on task distributions (e.g., horizon lengths), and comparison to other potential workloads to clarify the scope of the reported system implications. revision: yes
Circularity Check
Empirical measurement study with no self-referential derivations or fitted predictions
full rationale
The paper introduces a taxonomy, builds a profiling harness, measures ten systems on two benchmarks, and derives recommendations from those measurements. No equations, parameter fits presented as predictions, or self-citations are used to justify central claims. The work is self-contained as an empirical characterization; representativeness of the sample is a validity concern but does not create circularity by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Flash endurance is priced via shadow price η making placement cost-optimal for any sign of value-write correlation χ, with χ positive only in recurrent long-horizon manipulation and the budget binding only on low-endu...
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory,
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, ” 2025. [Online]. Available: https://arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[2]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization,
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From Local to Global: A Graph RAG Approach to Query-Focused Summarization, ” 2025. [Online]. Available: https://arxiv.org/abs/2404.16130
Pith/arXiv arXiv 2025
-
[3]
From RAG to memory: non-parametric continual learning for large language models,
B. J. Gutiérrez, Y. Shu, W. Qi, S. Zhou, and Y. Su, “From RAG to memory: non-parametric continual learning for large language models, ” inProceedings of the 42nd International Conference on Machine Learning, ser. ICML’25. JMLR.org, 2025
2025
-
[4]
MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks,
Z. He, Y. Wang, C. Zhi, Y. Hu, T.-P. Chen, L. Yin, Z. Chen, T. A. Wu, S. Ouyang, Z. Wang, J. Pei, J. McAuley, Y. Choi, and A. Pentland, “MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks, ” 2026. [Online]. Available: https://arxiv.org/abs/2602.16313
arXiv 2026
-
[5]
RULER: What’s the Real Context Size of Your Long-Context Language Models?
C.-P. Hsieh, S. Sun, S. Kriman, S. Acharya, D. Rekesh, F. Jia, Y. Zhang, and B. Ginsburg, “RULER: What’s the Real Context Size of Your Long-Context Language Models?” 2024. [Online]. Available: https://arxiv.org/abs/2404.06654
Pith/arXiv arXiv 2024
-
[6]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions,
Y. Hu, Y. Wang, and J. McAuley, “Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions, ” 2026. [Online]. Available: https://arxiv.org/abs/2507.05257
Pith/arXiv arXiv 2026
-
[7]
Billion-Scale Similarity Search with GPUs ,
J. Johnson, M. Douze, and H. Jegou, “ Billion-Scale Similarity Search with GPUs , ”IEEE Transactions on Big Data, vol. 7, no. 03, pp. 535–547, Jul. 2021. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TBDATA.2019.2921572
-
[8]
Dense Passage Retrieval for Open-Domain Question Answering,
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense Passage Retrieval for Open-Domain Question Answering, ” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y. He, and Y. Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 676...
2020
-
[9]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient Memory Management for Large Language Model Serving with PagedAttention, ” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Available...
-
[10]
Stateful Agents: The Missing Link in LLM Intelligence,
Letta, “Stateful Agents: The Missing Link in LLM Intelligence, ” Febru- ary 2025. [Online]. Available: https://www.letta.com/blog/stateful- agents
2025
-
[11]
Retrieval-Augmented Generation forKknowledge-Intensive NLP Tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-Augmented Generation forKknowledge-Intensive NLP Tasks, ” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY, USA: Curran Associates Inc., 2020
2020
-
[12]
SimpleMem: Efficient Lifelong Memory for LLM Agents,
J. Liu, Y. Su, P. Xia, S. Han, Z. Zheng, C. Xie, M. Ding, and H. Yao, “SimpleMem: Efficient Lifelong Memory for LLM Agents, ” 2026. [Online]. Available: https://arxiv.org/abs/2601.02553 11
Pith/arXiv arXiv 2026
-
[13]
Lost in the Middle: How Language Models Use Long Contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the Middle: How Language Models Use Long Contexts, ” vol. 12. Cambridge, MA: MIT Press, 2024, pp. 157–173. [Online]. Available: https://aclanthology.org/2024.tacl-1.9/
2024
-
[14]
Evaluating Very Long-Term Conversational Memory of LLM Agents,
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y. Fang, “Evaluating Very Long-Term Conversational Memory of LLM Agents, ” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V. Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguisti...
2024
-
[15]
FP8 Formats for Deep Learning,
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu, N. Mellempudi, S. Oberman, M. Shoeybi, M. Siu, and H. Wu, “FP8 Formats for Deep Learning, ” 2022. [Online]. Available: https://arxiv.org/abs/2209.05433
Pith/arXiv arXiv 2022
-
[16]
MemGPT: Towards LLMs as Operating Systems,
C. Packer, S. Wooders, K. Lin, V. Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “MemGPT: Towards LLMs as Operating Systems, ” 2024. [Online]. Available: https://arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[17]
Generative Agents: Interactive Simulacra of Human Behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative Agents: Interactive Simulacra of Human Behavior, ” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, ser. UIST ’23. New York, NY, USA: Association for Computing Machinery, 2023. [Online]. Available: https://doi.org/10.1145/35...
-
[18]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory,
P. Rasmussen, P. Paliychuk, T. Beauvais, J. Ryan, and D. Chalef, “Zep: A Temporal Knowledge Graph Architecture for Agent Memory, ”
-
[19]
Available: https://arxiv.org/abs/2501.13956
[Online]. Available: https://arxiv.org/abs/2501.13956
-
[20]
The Probabilistic Relevance Framework: BM25 and Beyond,
S. Robertson and H. Zaragoza, “The Probabilistic Relevance Framework: BM25 and Beyond, ”Found. Trends Inf. Retr., vol. 3, no. 4, p. 333–389, Apr. 2009. [Online]. Available: https://doi.org/10.1561/1500000019
-
[21]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory,
T. Wei, N. Sachdeva, B. Coleman, Z. He, Y. Bei, X. Ning, M. Ai, Y. Li, J. He, E. H. Chi, C. Wang, S. Chen, F. Pereira, W.-C. Kang, and D. Z. Cheng, “Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory, ” 2026. [Online]. Available: https://arxiv.org/abs/2511.20857
Pith/arXiv arXiv 2026
-
[22]
Intelligence per watt: Measuring intelligence efficiency of local ai,
J. Saad-Falcon, A. Narayan, H. O. Akengin, J. W. Griffin, H. Shandilya, A. G. Lafuente, M. Goel, R. Joseph, S. Natarajan, E. K. Guha, S. Zhu, B. Athiwaratkun, J. Hennessy, A. Mirhoseini, and C. Ré, “Intelligence per watt: Measuring intelligence efficiency of local ai, ”
-
[23]
Available: https://arxiv.org/abs/2511.07885
[Online]. Available: https://arxiv.org/abs/2511.07885
-
[24]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval,
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning, “RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval, ” 2024. [Online]. Available: https://arxiv.org/abs/2401.18059
Pith/arXiv arXiv 2024
-
[25]
Reflexion: Language Agents with Verbal Reinforcement Learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language Agents with Verbal Reinforcement Learning, ” in Proceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY, USA: Curran Associates Inc., 2023
2023
-
[26]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Teamet al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, ” 2024. [Online]. Available: https://arxiv.org/abs/2403.05530
Pith/arXiv arXiv 2024
-
[27]
vLLM quantization documentation: FP8,
vLLM Project, “vLLM quantization documentation: FP8, ” 2025, online: https://docs.vllm.ai/en/latest/features/quantization/fp8.html
2025
-
[28]
A Survey on Large Language Model Based Autonomous Agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin, W. X. Zhao, Z. Wei, and J. Wen, “A Survey on Large Language Model Based Autonomous Agents, ” Front. Comput. Sci., vol. 18, no. 6, Mar. 2024. [Online]. Available: https://doi.org/10.1007/s11704-024-40231-1
-
[29]
MIRIX: Multi-Agent Memory System for LLM-Based Agents,
Y. Wang and X. Chen, “MIRIX: Multi-Agent Memory System for LLM-Based Agents, ” 2025. [Online]. Available: https://arxiv.org/abs/2507.07957
Pith/arXiv arXiv 2025
-
[30]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory,
D. Wu, H. Wang, W. Yu, Y. Zhang, K.-W. Chang, and D. Yu, “LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ” 2024. [Online]. Available: https://arxiv.org/abs/2410.10813
Pith/arXiv arXiv 2024
-
[31]
A-MEM: Agentic Memory for LLM Agents,
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y. Zhang, “A-MEM: Agentic Memory for LLM Agents, ” 2025. [Online]. Available: https://arxiv.org/abs/2502.12110 12
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.