Latent Actions from Factorized Transition Effects under Agent Ambiguity
Pith reviewed 2026-06-30 05:58 UTC · model grok-4.3
The pith
Decomposing visual transitions into sparse primitives yields reusable latent actions despite distractors and ambiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
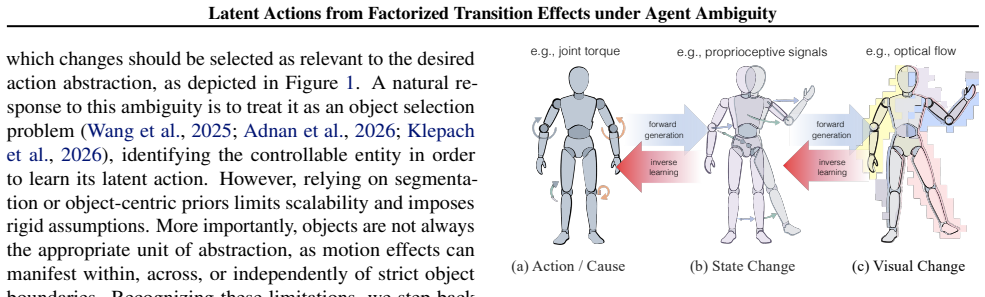
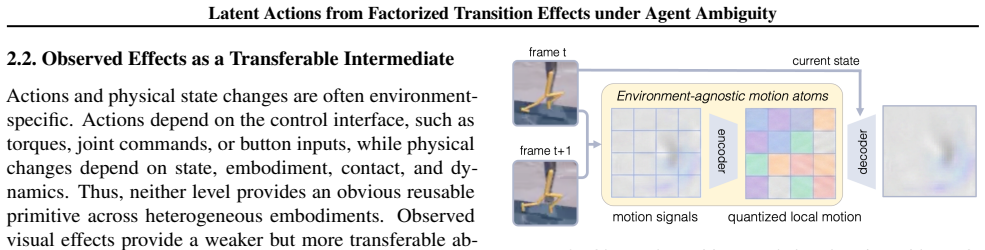
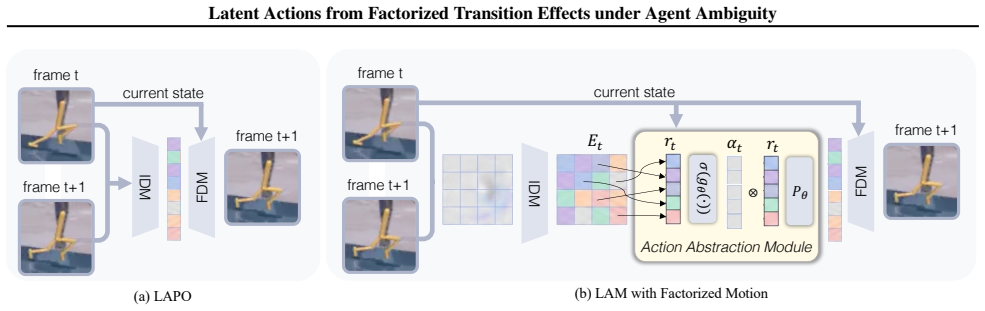
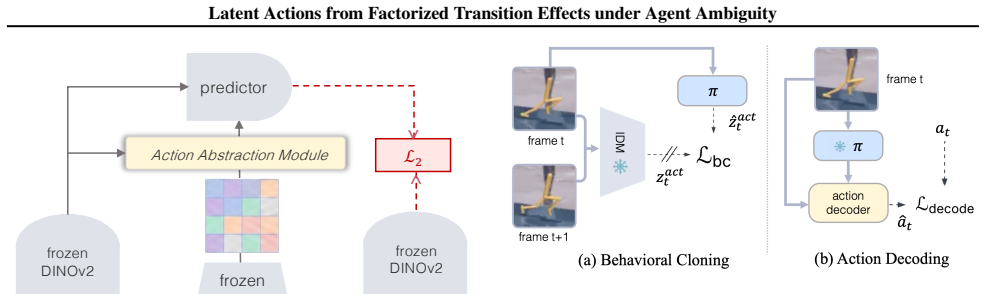
Observed Transition Factorization (OTF) decomposes each transition into a sparse set of observed transition primitives. Using these primitives as the transition interface, OTF-LAM abstracts motion primitives into action-like latents within the standard inverse-forward dynamics framework, and OTF-LAM-Dino predicts future states in a frozen DINOv2 representation space without a decoder. This structure turns the mixture of agent motion, distractors, and background changes into reusable transition effects from which action-like latents can be formed more robustly.
What carries the argument
Observed Transition Factorization (OTF), the decomposition of each visual transition into a sparse set of observed transition primitives that isolate action sources.
If this is right
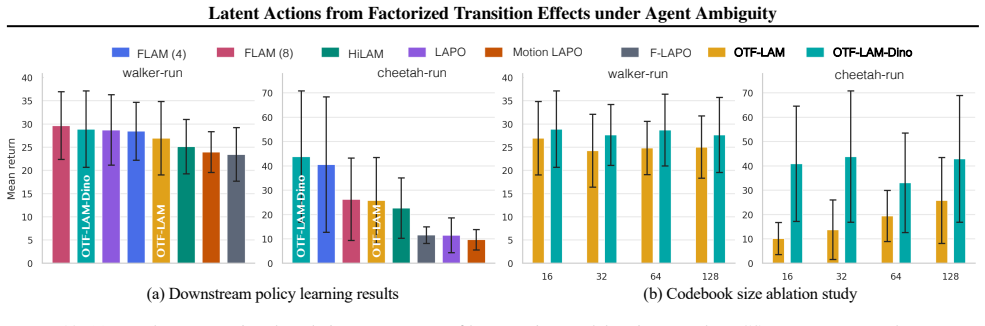
- OTF primitives transfer zeroshot across controlled carrier and morphology shifts.
- Downstream policy learning matches or outperforms baselines under complex transition ambiguity.
- The factorization supplies an intermediate representation that structures mixed visual effects into reusable transition effects.
- Action-like latents become more robust when formed from the factorized primitives rather than raw transitions.
Where Pith is reading between the lines
- The same primitives could be reused across entirely different robot embodiments if the sparsity pattern holds for the new morphology.
- Replacing the DINOv2 space with other frozen visual encoders might preserve the zero-shot transfer property.
- The method opens a path to learning from unlabeled video without explicit action labels even when the camera itself moves.
- Extending the factorization to handle temporal sequences longer than single transitions could improve long-horizon planning.
Load-bearing premise
Visual transition effects in multi-object scenes can be decomposed into a sparse set of observed transition primitives that isolate the underlying action source without supervision.
What would settle it
A controlled test scene where known agent actions are mixed with distractors, in which the extracted OTF primitives fail to separate agent-specific effects and the resulting policies underperform non-factorized baselines.
Figures



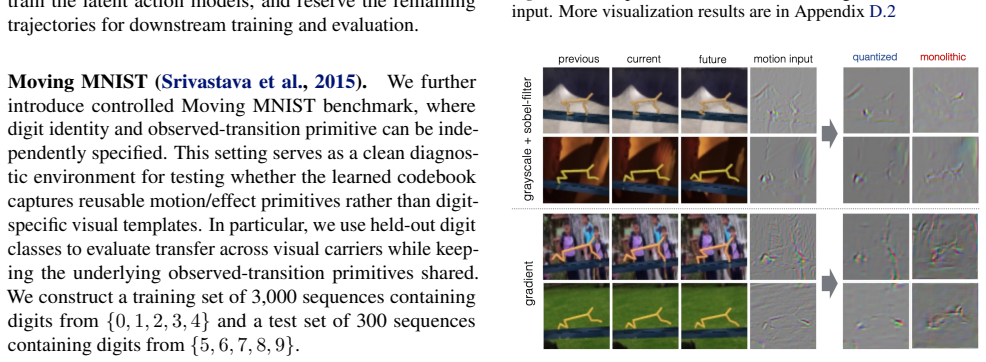

read the original abstract
Latent Action Models (LAMs) learn action-like proxies from observation transitions. However, in multi-object or distractor-rich scenes, these visual effects mix agent motion with distractors, camera dynamics, and background changes, making the underlying action source ambiguous without supervision. Structuring this mixture as reusable transition effects provides an intermediate representation from which action-like latents can be more robustly formed. We introduce Observed Transition Factorization (OTF), which decomposes each transition into a sparse set of observed transition primitives. Using these primitives as the transition interface, we propose OTF-LAM, which abstracts motion primitives into action-like latents within the standard inverse-forward dynamics framework, and OTF-LAM-Dino, a decoder-free variant that predicts future states in a frozen DINOv2 representation space. Empirically, OTF primitives transfer zeroshot across controlled carrier and morphology shifts, showing reusability. Furthermore, downstream policy learning results match or outperform baselines under complex transition ambiguity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Observed Transition Factorization (OTF) to decompose visual observation transitions into a sparse set of observed transition primitives without supervision in multi-object or distractor-rich scenes. These primitives serve as an interface for OTF-LAM, which learns action-like latents via the standard inverse-forward dynamics framework, and for the decoder-free OTF-LAM-Dino variant that operates in frozen DINOv2 space. The central claims are that the resulting primitives transfer zeroshot across controlled carrier and morphology shifts (demonstrating reusability) and that downstream policy learning matches or outperforms baselines under complex transition ambiguity.
Significance. If the empirical claims hold with rigorous validation, the work could meaningfully advance unsupervised learning of reusable latent actions in visually ambiguous settings, a persistent challenge in visual RL and robotics. The factorization into sparse primitives offers a structured intermediate representation that may reduce the impact of distractors, and the decoder-free DINOv2 variant is a practical design choice. No machine-checked proofs or parameter-free derivations are present.
major comments (2)
- [Abstract] Abstract: The abstract asserts empirical support for zeroshot transfer of OTF primitives and competitive downstream policy performance, but the manuscript supplies no experimental details, metrics, baselines, datasets, or implementation descriptions, preventing any evaluation of the support for these central claims.
- [Method] Method section (OTF definition): No derivation or analysis is provided showing why the sparsity constraint or factorization objective isolates the underlying agent action source from distractors, camera effects, or background changes rather than capturing spurious correlations; without this, the claimed reusability and policy gains do not necessarily follow from the stated mechanism.
Simulated Author's Rebuttal
We thank the referee for the detailed review. We address the two major comments point-by-point below, clarifying the role of the abstract and providing additional motivation for the OTF factorization while remaining faithful to the manuscript's content.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts empirical support for zeroshot transfer of OTF primitives and competitive downstream policy performance, but the manuscript supplies no experimental details, metrics, baselines, datasets, or implementation descriptions, preventing any evaluation of the support for these central claims.
Authors: Abstracts are concise summaries by design and do not contain experimental details; the manuscript's Experiments section provides full descriptions of the environments, datasets (including multi-object and distractor-rich scenes), metrics (zeroshot transfer success and policy returns), baselines (standard LAMs and variants), and implementation (training objectives, architectures for OTF-LAM and OTF-LAM-Dino). The abstract's claims are directly supported by those results. We can add a brief parenthetical reference to the experimental protocol if the editor prefers. revision: partial
-
Referee: [Method] Method section (OTF definition): No derivation or analysis is provided showing why the sparsity constraint or factorization objective isolates the underlying agent action source from distractors, camera effects, or background changes rather than capturing spurious correlations; without this, the claimed reusability and policy gains do not necessarily follow from the stated mechanism.
Authors: The OTF objective combines a reconstruction loss with an explicit sparsity penalty on the transition primitives, which is motivated by the assumption that agent-induced effects are sparse relative to background or distractor motion. This inductive bias is validated empirically through controlled carrier/morphology transfer experiments and qualitative factorization visualizations that separate agent motion from distractors. While a formal proof of isolation is absent, the design follows standard sparse coding principles used in disentanglement literature, and the downstream policy gains are measured directly against non-factorized baselines under identical ambiguity conditions. We can add a short paragraph in the Method section elaborating on these inductive biases. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes Observed Transition Factorization (OTF) as a novel unsupervised decomposition of visual transitions into sparse primitives, then integrates these primitives into the existing inverse-forward dynamics framework to form OTF-LAM and OTF-LAM-Dino. All performance claims (zeroshot transfer across carrier/morphology shifts and downstream policy results) are framed as empirical outcomes rather than closed-form derivations. No equations, self-citations, or fitted parameters are shown in the abstract or description that reduce the reusability or isolation claims to quantities defined by construction within the same work. The derivation chain remains self-contained against external benchmarks and does not exhibit self-definitional, fitted-input, or self-citation load-bearing patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Observed Transition Primitives
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 42nd International Conference on Machine Learning , year =
Latent Action Learning Requires Supervision in the Presence of Distractors , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[2]
2021 , eprint=
The Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels , author=. 2021 , eprint=
2021
-
[3]
ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling , year=
Hierarchical Latent Action Model , author=. ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling , year=
2026
-
[4]
2026 , eprint=
You Don't Need Strong Assumptions: Visual Representation Learning via Temporal Differences , author=. 2026 , eprint=
2026
-
[5]
2022 , url=
A Path Towards Autonomous Machine Intelligence Version 0.9.2, 2022-06-27 , author=. 2022 , url=
2022
-
[6]
International Conference on Learning Representations , year=
CLEVRER: Collision Events for Video Representation and Reasoning , author=. International Conference on Learning Representations , year=
-
[7]
The Fourteenth International Conference on Learning Representations , year=
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
Recurrent World Models Facilitate Policy Evolution , url =
Ha, David and Schmidhuber, J\". Recurrent World Models Facilitate Policy Evolution , url =. Advances in Neural Information Processing Systems , editor =
-
[9]
2026 , eprint=
Causal-JEPA: Learning World Models through Object-Level Latent Interventions , author=. 2026 , eprint=
2026
-
[10]
The Eleventh International Conference on Learning Representations , year=
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[11]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Locatello, Francesco and Weissenborn, Dirk and Unterthiner, Thomas and Mahendran, Aravindh and Heigold, Georg and Uszkoreit, Jakob and Dosovitskiy, Alexey and Kipf, Thomas , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[12]
The Twelfth International Conference on Learning Representations , year=
Learning to Act without Actions , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Latent Action Pretraining from Videos , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
2022 , eprint=
Unsupervised Image Representation Learning with Deep Latent Particles , author=. 2022 , eprint=
2022
-
[15]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[17]
2025 , url=
Gaoyue Zhou and Hengkai Pan and Yann LeCun and Lerrel Pinto , booktitle=. 2025 , url=
2025
-
[18]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[19]
2025 , eprint=
Autoregressive Video Autoencoder with Decoupled Temporal and Spatial Context , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
DeCo-VAE: Learning Compact Latents for Video Reconstruction via Decoupled Representation , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Hi-VAE: Efficient Video Autoencoding with Global and Detailed Motion , author=. 2025 , eprint=
2025
-
[22]
arXiv preprint arXiv:2310.01040 , year =
Segmenting the Motion Components of a Video: A Long-Term Unsupervised Model , author =. arXiv preprint arXiv:2310.01040 , year =
-
[23]
European Conference on Computer Vision , pages=
Un-EVIMO: Unsupervised event-based independent motion segmentation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[24]
Choudhury, Subhabrata and Karazija, Laurynas and Laina, Iro and Vedaldi, Andrea and Rupprecht, Christian , booktitle =
-
[25]
The Fourteenth International Conference on Learning Representations , year=
Articulation in Motion: Prior-free Part Mobility Analysis for Articulated Objects By Dynamic-Static Disentanglement , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
NeurIPS 2025 Workshop on Embodied World Models for Decision Making , year=
FLAM: Scaling Latent Action World Models with Factorization , author=. NeurIPS 2025 Workshop on Embodied World Models for Decision Making , year=
2025
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Object-centric latent action learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
2026 , eprint=
Segment to Focus: Guiding Latent Action Models in the Presence of Distractors , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
Learning Additively Compositional Latent Actions for Embodied AI , author=. 2026 , eprint=
2026
-
[30]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Generating holistic 3d human motion from speech , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
X-dancer: Expressive music to human dance video generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
European Conference on Computer Vision , pages=
Nymeria: A massive collection of multimodal egocentric daily motion in the wild , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[34]
Transactions on Machine Learning Research , issn=
Image Compression with Product Quantized Masked Image Modeling , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[35]
Proceedings of the 32nd International Conference on Machine Learning , year =
Unsupervised Learning of Video Representations Using LSTMs , author =. Proceedings of the 32nd International Conference on Machine Learning , year =
-
[36]
2026 , eprint=
Learning Latent Action World Models In The Wild , author=. 2026 , eprint=
2026
-
[37]
Nature , volume=
Mastering diverse control tasks through world models , author=. Nature , volume=. 2025 , publisher=
2025
-
[38]
2024 , url=
Nicklas Hansen and Hao Su and Xiaolong Wang , booktitle=. 2024 , url=
2024
-
[39]
Conference on Robot Learning (CoRL) , year=
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , author=. Conference on Robot Learning (CoRL) , year=
-
[40]
Proceedings of the Conference on Robot Learning , pages =
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning , author =. Proceedings of the Conference on Robot Learning , pages =. 2020 , editor =
2020
-
[41]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[42]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[43]
Journal of Machine Learning Research , year =
Laurens van der Maaten and Geoffrey Hinton , title =. Journal of Machine Learning Research , year =
-
[44]
Berthold K.P. Horn and Brian G. Schunck , abstract =. Determining optical flow , journal =. 1981 , issn =. doi:https://doi.org/10.1016/0004-3702(81)90024-2 , url =
-
[45]
and Kanade, Takeo , title =
Lucas, Bruce D. and Kanade, Takeo , title =. Proceedings of the 7th International Joint Conference on Artificial Intelligence - Volume 2 , pages =. 1981 , publisher =
1981
-
[46]
1990 , url=
An Isotropic 3×3 image gradient operator , author=. 1990 , url=
1990
-
[47]
ArXiv , year=
LAOF: Robust Latent Action Learning with Optical Flow Constraints , author=. ArXiv , year=
-
[48]
ArXiv , year=
Learning Latent Action World Models In The Wild , author=. ArXiv , year=
-
[49]
arXiv preprint arXiv:2101.02722 , year =
The Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels , author =. arXiv preprint arXiv:2101.02722 , year =
-
[50]
, booktitle =
Yi, Kexin and Gan, Chuang and Li, Yunzhu and Kohli, Pushmeet and Wu, Jiajun and Torralba, Antonio and Tenenbaum, Joshua B. , booktitle =. 2020 , url =
2020
-
[51]
International Conference on Learning Representations , year =
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling , author =. International Conference on Learning Representations , year =
-
[52]
Advances in Neural Information Processing Systems , volume =
Recurrent World Models Facilitate Policy Evolution , author =. Advances in Neural Information Processing Systems , volume =. 2018 , url =
2018
-
[53]
Nam, Heejeong and Le Lidec, Quentin and Maes, Lucas and LeCun, Yann and Balestriero, Randall , journal =. Causal-. 2026 , url =
2026
-
[54]
International Conference on Learning Representations , year =
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models , author =. International Conference on Learning Representations , year =
-
[55]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Locatello, Francesco and Weissenborn, Dirk and Unterthiner, Thomas and Mahendran, Aravindh and Heigold, Georg and Uszkoreit, Jakob and Dosovitskiy, Alexey and Kipf, Thomas , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , publisher =
2020
-
[56]
The Twelfth International Conference on Learning Representations , year =
Learning to Act without Actions , author =. The Twelfth International Conference on Learning Representations , year =
-
[57]
Latent Action Pretraining from Videos
Latent Action Pretraining from Videos , author =. arXiv preprint arXiv:2410.11758 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Proceedings of the 39th International Conference on Machine Learning , year =
Unsupervised Image Representation Learning with Deep Latent Particles , author =. Proceedings of the 39th International Conference on Machine Learning , year =
-
[59]
Proceedings of the IEEE , volume =
Toward causal representation learning , author =. Proceedings of the IEEE , volume =. 2021 , publisher =
2021
-
[60]
Nonlinear independent component analysis: Existence and uniqueness results , journal =
Hyv. Nonlinear independent component analysis: Existence and uniqueness results , journal =. 1999 , issn =. doi:https://doi.org/10.1016/S0893-6080(98)00140-3 , url =
-
[61]
arXiv preprint arXiv:2512.11293 , year =
Autoregressive Video Autoencoder with Decoupled Temporal and Spatial Context , author =. arXiv preprint arXiv:2512.11293 , year =
-
[62]
2025 , url =
Yin, Xiangchen and Yuan, Jiahui and Hu, Zhangchi and Sun, Wenzhang and Chen, Jie and Qiao, Xiaozhen and Li, Hao and Sun, Xiaoyan , journal =. 2025 , url =
2025
-
[63]
Liu, Huaize and Sun, Wenzhang and Zhang, Qiyuan and Di, Donglin and Gong, Biao and Li, Hao and Wei, Chen and Zou, Changqing , journal =. Hi-. 2025 , url =
2025
-
[64]
2024 , note =
Wang, Ziyun and Guo, Jinyuan and Daniilidis, Kostas , booktitle =. 2024 , note =
2024
-
[65]
British Machine Vision Conference , year =
Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion , author =. British Machine Vision Conference , year =
-
[66]
NeurIPS 2025 Workshop on Embodied World Models for Decision Making , year =
FLAM: Scaling Latent Action World Models with Factorization , author =. NeurIPS 2025 Workshop on Embodied World Models for Decision Making , year =
2025
-
[67]
International Conference on Learning Representations , year =
Object-Centric Latent Action Learning , author =. International Conference on Learning Representations , year =
-
[68]
Segment to Focus: Guiding Latent Action Models in the Presence of Distractors
Segment to Focus: Guiding Latent Action Models in the Presence of Distractors , author =. arXiv preprint arXiv:2602.02259 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Learning Additively Compositional Latent Actions for Embodied AI
Learning Additively Compositional Latent Actions for Embodied AI , author =. arXiv preprint arXiv:2604.03340 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Advances in Neural Information Processing Systems , volume =
Neural Discrete Representation Learning , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Generating Holistic 3D Human Motion from Speech , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[72]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
X-Dancer: Expressive Music to Human Dance Video Generation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[73]
arXiv preprint arXiv:2406.09905 , year =
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild , author =. arXiv preprint arXiv:2406.09905 , year =
-
[74]
arXiv preprint arXiv:2212.07372 , year =
Image Compression with Product Quantized Masked Image Modeling , author =. arXiv preprint arXiv:2212.07372 , year =
-
[75]
arXiv preprint arXiv:2601.05230 , year =
Learning Latent Action World Models In The Wild , author =. arXiv preprint arXiv:2601.05230 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.