GRAR: Glass-induced Reflection Artifact Removal in LiDAR Point Clouds
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
A two-stage framework detects glass regions with a vision foundation model and removes reflection artifacts using a physics-driven geometric descriptor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
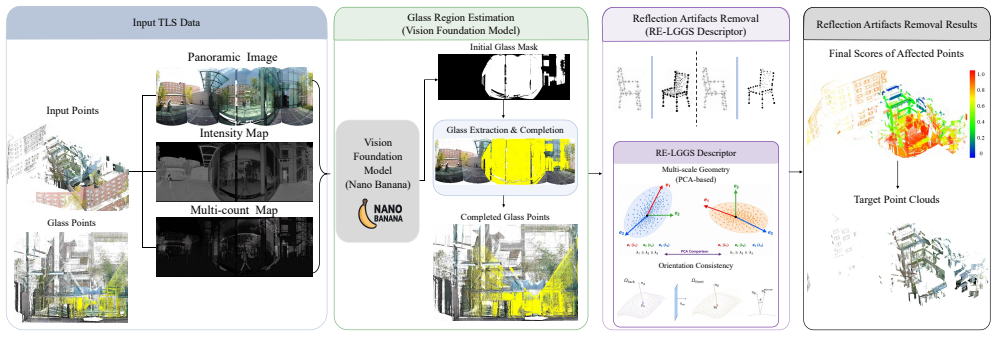
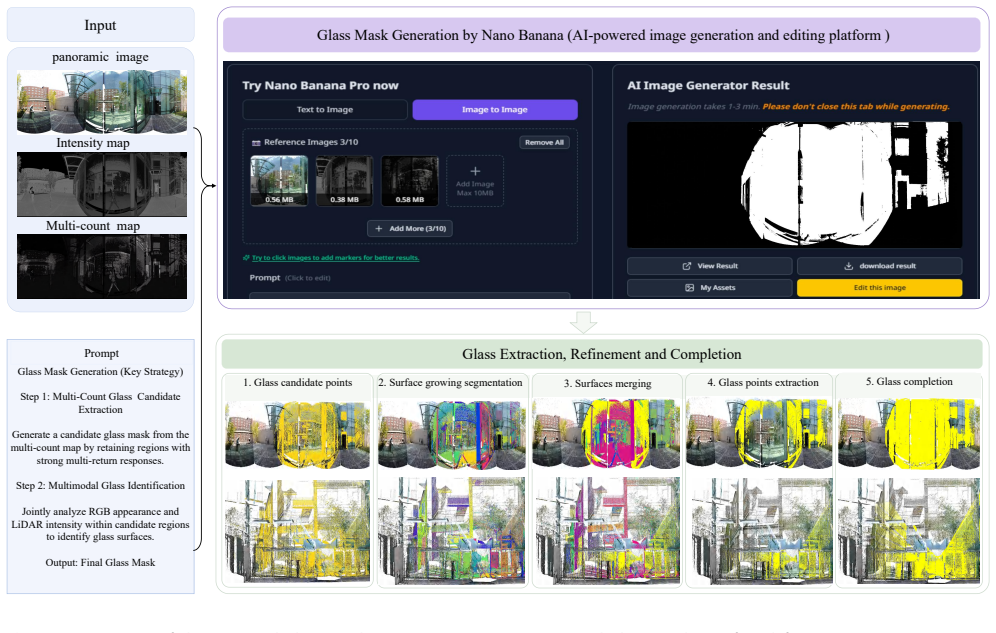
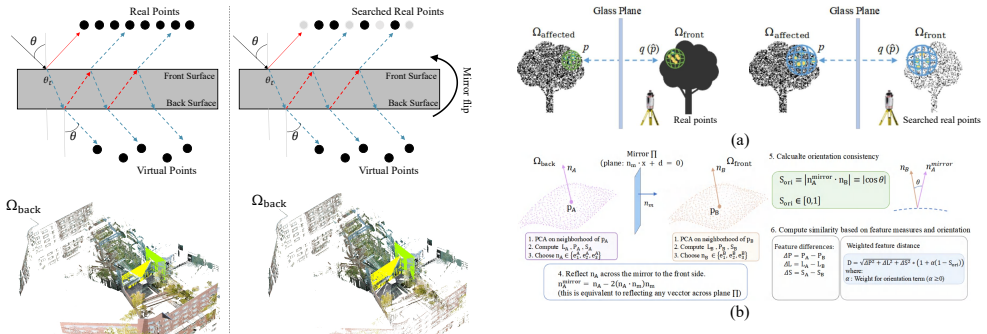
The central claim is that a unified two-stage framework removes glass-induced reflection artifacts from TLS point clouds: the first stage uses a multi-modal vision foundation model to produce initial glass masks refined by geometric cues and completed for no-return regions; the second stage introduces the Reflection-aware Local-Global Geometric Similarity (RE-LGGS) descriptor grounded in laser reflection geometry that jointly encodes multi-scale structures and orientation consistency via PCA-based representations, leading to consistent outperformance over state-of-the-art methods on multiple public TLS datasets.
What carries the argument
The Reflection-aware Local-Global Geometric Similarity (RE-LGGS) descriptor, which encodes multi-scale geometric structures and orientation consistency using PCA-based local shape representations based on actual laser reflection geometry.
If this is right
- Higher-precision glass region detection directly improves the identification and removal of spurious reflection points.
- The physics-based RE-LGGS descriptor provides robustness to imperfect observations that break ideal symmetry assumptions.
- Glass completion recovers missing scene parts that would otherwise be lost to transparent surfaces.
- Consistent gains across multiple public TLS datasets indicate the approach generalizes within urban scanning settings.
Where Pith is reading between the lines
- Cleaned point clouds from this method could improve reliability of 3D models used in autonomous vehicle mapping through glass-heavy environments.
- The two-stage separation of detection and geometric cleaning might transfer to removing similar reflection artifacts in mobile or aerial LiDAR systems.
- Replacing the foundation model component with domain-specific glass detectors could test whether the geometric stage alone suffices for certain datasets.
Load-bearing premise
The multi-modal vision foundation model produces initial glass masks accurate enough that geometric refinement and completion can support effective downstream artifact removal.
What would settle it
Applying the full pipeline to a held-out TLS dataset where the vision model yields glass masks with large errors and finding no measurable improvement in artifact removal over existing methods would disprove the central claim.
Figures









read the original abstract
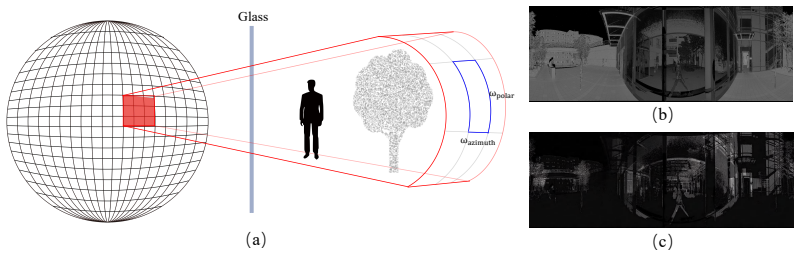
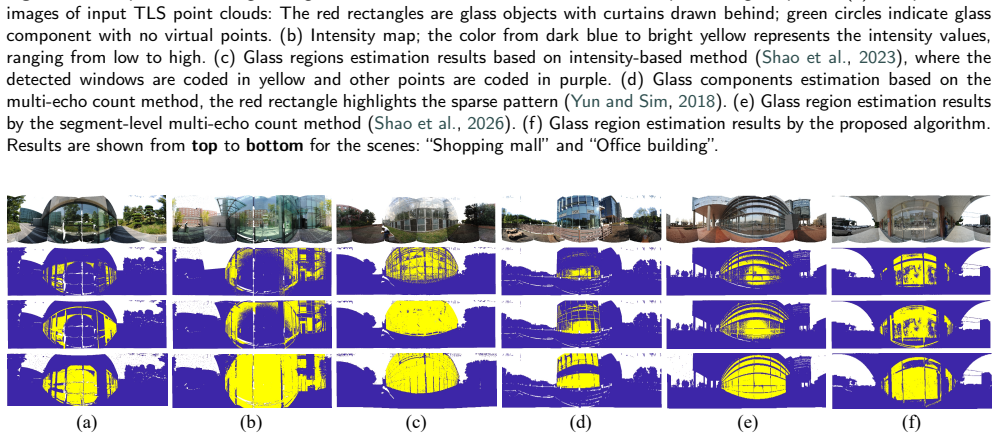
Terrestrial Laser Scanning (TLS) point clouds captured in urban environments frequently suffer from glass-induced reflection artifacts, severely degrading downstream applications. Existing reflection artifact removal methods generally rely on ideal reflection symmetry assumptions, yet their performance is limited by inaccurate glass estimation and insufficient geometric representations. To address these issues, we propose a novel unified framework aimed at robust reflection artifact removal: In the first stage, we leverage a multi-modal vision foundation model to produce initial glass masks, which are then refined using geometric cues to achieve high-precision glass regions, followed by glass completion to recover missing regions caused by no-return measurements on transparent surfaces; In the second stage, we propose a physics-driven descriptor, termed Reflection-aware Local-Global Geometric Similarity (RE-LGGS), which is grounded in actual laser reflection geometry and jointly encodes multi-scale geometric structures and orientation consistency using PCA-based local shape representations, thereby significantly improving robustness against imperfect observations. Extensive experiments on multiple public TLS datasets demonstrate that our framework consistently outperforms state-of-the-art methods in reflection artifacts removal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GRAR, a two-stage framework for removing glass-induced reflection artifacts from TLS point clouds. Stage 1 uses a multi-modal vision foundation model to generate initial glass masks, which are refined via geometric cues and completed to handle no-return regions on transparent surfaces. Stage 2 introduces the RE-LGGS descriptor, a physics-driven measure grounded in laser reflection geometry that jointly encodes multi-scale structures and orientation consistency via PCA-based local shape representations. The paper claims that extensive experiments on multiple public TLS datasets demonstrate consistent outperformance over state-of-the-art reflection artifact removal methods.
Significance. If the quantitative claims hold, the work could improve reliability of TLS data in urban scenes for downstream tasks such as 3D reconstruction and semantic segmentation. The explicit grounding of the similarity measure in reflection physics and the two-stage separation of mask generation from geometric removal are potentially useful design choices.
major comments (3)
- [Abstract] Abstract: the central claim that the framework 'consistently outperforms state-of-the-art methods' is unsupported by any quantitative metrics, error bars, dataset statistics, or ablation results, rendering the headline result impossible to evaluate from the provided text.
- [Abstract] Abstract (first-stage description): the entire pipeline is load-bearing on the assumption that the multi-modal vision foundation model supplies initial glass masks accurate enough for geometric refinement to succeed; no mask-quality metric (IoU, precision-recall on glass regions) or domain-shift analysis is referenced, leaving this prerequisite unanchored.
- [Abstract] Abstract (second-stage description): the RE-LGGS descriptor is asserted to be 'grounded in actual laser reflection geometry,' yet the abstract supplies neither the explicit geometric derivation nor any equation showing how the PCA-based local shape representations enforce orientation consistency under imperfect observations.
minor comments (1)
- [Abstract] The acronym RE-LGGS is introduced without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We agree that the abstract can be made more self-contained and will revise it accordingly while preserving its concise nature. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework 'consistently outperforms state-of-the-art methods' is unsupported by any quantitative metrics, error bars, dataset statistics, or ablation results, rendering the headline result impossible to evaluate from the provided text.
Authors: The abstract serves as a high-level summary; the full manuscript contains the supporting quantitative results, metrics, error bars, dataset statistics, and ablations on multiple public TLS datasets. To strengthen the abstract, we will incorporate key performance highlights and dataset details in the revision. revision: yes
-
Referee: [Abstract] Abstract (first-stage description): the entire pipeline is load-bearing on the assumption that the multi-modal vision foundation model supplies initial glass masks accurate enough for geometric refinement to succeed; no mask-quality metric (IoU, precision-recall on glass regions) or domain-shift analysis is referenced, leaving this prerequisite unanchored.
Authors: We agree the abstract does not reference mask-quality metrics. The manuscript evaluates the initial glass mask generation, geometric refinement, and completion stages using metrics such as IoU and precision-recall. We will revise the abstract to reference these metrics and note the evaluation of the first stage. revision: yes
-
Referee: [Abstract] Abstract (second-stage description): the RE-LGGS descriptor is asserted to be 'grounded in actual laser reflection geometry,' yet the abstract supplies neither the explicit geometric derivation nor any equation showing how the PCA-based local shape representations enforce orientation consistency under imperfect observations.
Authors: The abstract summarizes the descriptor; the full manuscript provides the physics-based derivation and the equations detailing how the PCA-based local shape representations capture orientation consistency. We will update the abstract to include a concise reference to the geometric grounding and the relevant equation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and method description introduce a two-stage pipeline that invokes an external multi-modal vision foundation model for initial masks, followed by geometric refinement and a new RE-LGGS descriptor grounded in laser reflection geometry. No equations, fitted parameters, or self-citations are quoted that reduce any claimed prediction or result to a definition or input by construction. The central claim of outperformance rests on experimental results rather than tautological steps, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RE-LGGS descriptor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ying and P
S. Ying and P. Van Oosterom and H. Fan , title =. J. Geovis. Spat. Anal. , volume =. 2023 , doi =
2023
-
[2]
Snavely and S
N. Snavely and S. M. Seitz and R. Szeliski , title =. ACM Trans. Graph. , volume =. 2006 , doi =
2006
-
[3]
Furukawa and J
Y. Furukawa and J. Ponce , title =. IEEE Trans. Pattern Anal. Mach. Intell. , volume =
-
[4]
Kerbl and G
B. Kerbl and G. Kopanas and T. Leimk. 3D Gaussian Splatting for Real-Time Radiance Field Rendering , journal =. 2023 , doi =
2023
-
[5]
T. S. Fong and W. Y. Yan , title =. Autom. Constr. , volume =. 2025 , doi =
2025
-
[6]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2020 , publisher=
2020
-
[7]
Xiong and Y
B. Xiong and Y. Jin and F. Li and Y. Chen and Y. Zou and Z. Zhou , title =. Autom. Constr. , volume =. 2023 , doi =
2023
-
[8]
Robust Multiview Point Cloud Registration Using Algebraic Connectivity and Spatial Compatibility , year=
Fang, Li and Li, Tianyu and Zhou, Shudong and Lin, Yanghong , journal=. Robust Multiview Point Cloud Registration Using Algebraic Connectivity and Spatial Compatibility , year=
-
[9]
Ambrosino and A
A. Ambrosino and A. Di Benedetto and M. Fiani , title =. Remote Sens. , volume =. 2024 , doi =
2024
-
[10]
Lao , title =
Y. Lao , title =. 2019 , address =
2019
-
[11]
Srinivasan, Matthew Tancik, Jonathan T
Mildenhall, Ben and Srinivasan, Pratul P. and Tancik, Matthew and Barron, Jonathan T. and Ramamoorthi, Ravi and Ng, Ren , title =. 2021 , issue_date =. doi:10.1145/3503250 , journal =
-
[12]
WHU-Urban3D: An urban scene LiDAR point cloud dataset for semantic instance segmentation , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.isprsjprs.2024.02.007 , author =
-
[13]
2026 , title =
Geist, Louis and Landrieu, Loic and Robert, Damien , journal =. 2026 , title =
2026
-
[14]
Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
Wang, Peng and Liu, Lingjie and Liu, Yuan and Theobalt, Christian and Komura, Taku and Wang, Wenping , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[15]
and Frahm, Jan-Michael , booktitle=
Schönberger, Johannes L. and Frahm, Jan-Michael , booktitle=. Structure-from-Motion Revisited , year=
-
[16]
Gonizzi Barsanti and M
S. Gonizzi Barsanti and M. R. Marini and S. G. Malatesta and A. Rossi , title =. Remote Sens. , volume =. 2024 , doi =
2024
-
[17]
Zheng and B
Z. Zheng and B. Zha and Y. Zhou and J. Huang and Y. Xuchen and H. Zhang , title =. Remote Sens. , volume =. 2022 , doi =
2022
-
[18]
Wang and Y
L. Wang and Y. Chen and H. Xu , title =. Remote Sens. , volume =. 2024 , doi =
2024
-
[19]
J. -S. Yun and J. -Y. Sim , title =. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , pages =. 2018 , address =
2018
-
[20]
J. -S. Yun and J. -Y. Sim , title =. IEEE Trans. Pattern Anal. Mach. Intell. , volume =. 2021 , doi =
2021
-
[21]
J. -S. Yun and J. -Y. Sim , title =. Proc. IEEE Int. Conf. Image Process. (ICIP) , pages =. 2019 , address =
2019
-
[22]
Shao and K
W. Shao and K. Kakizaki and S. Araki and T. Mukai , title =. Proc. IEEE Annu. Comput. Softw. Appl. Conf. (COMPSAC) , pages =. 2023 , address =
2023
-
[23]
Lee and K
O. Lee and K. Joo and J. -Y. Sim , title =. IEEE Robot. Autom. Lett. , volume =. 2023 , doi =
2023
-
[24]
Fang and T
L. Fang and T. Li and Y. Lin and S. Zhou and W. Yao , title =. ISPRS J. Photogramm. Remote Sens. , volume =. 2025 , doi =
2025
-
[25]
Shao and Y
W. Shao and Y. Zhang and Y. Xue and T. Ji and Y. Lao , title =. Remote Sens. , volume =. 2026 , doi =
2026
-
[26]
2025 , note =
Nano Banana (Gemini 2.5 Flash Image) , howpublished =. 2025 , note =
2025
-
[27]
R. B. Rusu and N. Blodow and M. Beetz , title =. Proc. IEEE Int. Conf. Robot. Autom. (ICRA) , pages =. 2009 , address =
2009
-
[28]
Advances in Civil Engineering , volume =
Hosamo, Haidar Hosamo and Hosamo, Mohsen Hosamo , title =. Advances in Civil Engineering , volume =. doi:https://doi.org/10.1155/2022/2194949 , year =
-
[29]
Liu and P
C. Liu and P. Zhang and X. Xu , title =. J. Infrastruct. Intell. Resil. , volume =. 2023 , doi =
2023
-
[30]
Gao and J
R. Gao and J. Park and X. Hu and S. Yang and K. Cho , title =. Remote Sens. , volume =. 2021 , doi =
2021
-
[31]
Gao and M
R. Gao and M. Li and S. -J. Yang and K. Cho , title =. Remote Sens. , volume =. 2022 , doi =
2022
-
[32]
Koch and S
R. Koch and S. May and P. Koch and M. K. Detection of Specular Reflections in Range Measurements for Faultless Robotic SLAM , booktitle =. 2016 , address =
2016
-
[33]
Koch and S
R. Koch and S. May and P. Murmann and A. N. Identification of Transparent and Specular Reflective Material in Laser Scans to Discriminate Affected Measurements for Faultless Robotic SLAM , journal =. 2017 , doi =
2017
-
[34]
Koch and S
R. Koch and S. May and A. N. Detection and Purging of Specular Reflective and Transparent Object Influences in 3D Range Measurements , booktitle =. 2017 , address =
2017
-
[35]
Zhao and Z
X. Zhao and Z. Yang and S. Schwertfeger , title =. Proc. IEEE Int. Symp. Safety, Secur. Rescue Robot. (SSRR) , pages =. 2020 , address =
2020
-
[36]
Li and X
Y. Li and X. Zhao and S. Schwertfeger , title =. Sensors , volume =. 2024 , doi =
2024
-
[37]
A Review of LIDAR Radiometric Processing: From Ad Hoc Intensity Correction to Rigorous Radiometric Calibration , journal =. 2015 , issn =. doi:https://doi.org/10.3390/s151128099 , author =
-
[38]
Vosselman , title =
G. Vosselman , title =. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. , year =
-
[39]
Vosselman and B
G. Vosselman and B. G. H. Gorte and G. Sithole and T. Rabbani , title =. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. , pages =. 2004 , volume =
2004
-
[40]
Mei and X
H. Mei and X. Yang and Y. Wang and Y. Liu and S. He and Q. Zhang and X. Wei and R. W. Lau , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , address =
-
[41]
He and X
H. He and X. Li and G. Cheng and J. Shi and Y. Tong and G. Meng and V. Prinet and L. Weng , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[42]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,
Ke Fan and Changan Wang and Yabiao Wang and Chengjie Wang and Ran Yi and Lizhuang Ma , title =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,. 2023 , doi =
2023
-
[43]
Qi and X
F. Qi and X. Tan and Z. Zhang and M. Chen and Y. Xie and L. Ma , title =. IEEE Transactions on Industrial Informatics , volume =
-
[44]
Lin and Z
J. Lin and Z. He and R. W. Lau , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[45]
Liu and Y
F. Liu and Y. Liu and J. Lin and K. Xu and R. W. Lau , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[46]
Lin and Y.-H
J. Lin and Y.-H. Yeung and R. Lau , title =. Advances in Neural Information Processing Systems , volume =
-
[47]
and Shi, Boxin , journal=
Hong, Yuchen and Zheng, Qian and Zhao, Lingran and Jiang, Xudong and Kot, Alex C. and Shi, Boxin , journal=. PAR2Net: End-to-End Panoramic Image Reflection Removal , year=
-
[48]
MLLM - Tool : A Multimodal Large Language Model for Tool Agent Learning
Tan, Tianlong and Chen, Bin and Cao, Hongliang and Yan, Chenggang and Ma, Yike and Dai, Feng , booktitle =. 2025 , volume =. doi:10.1109/WACV61041.2025.00852 , url =
-
[49]
Zhang, Jiaming and Yang, Kailun and Shi, Hao and Reiß, Simon and Peng, Kunyu and Ma, Chaoxiang and Fu, Haodong and Torr, Philip H. S. and Wang, Kaiwei and Stiefelhagen, Rainer , journal=. Behind Every Domain There is a Shift: Adapting Distortion-Aware Vision Transformers for Panoramic Semantic Segmentation , year=
-
[50]
Pairwise coarse registration of point clouds in urban scenes using voxel-based 4-planes congruent sets , year=
Xu, Yusheng and Boerner, Richard and Yao, Wei and Hoegner, Ludwig and Stilla, Uwe , journal=. Pairwise coarse registration of point clouds in urban scenes using voxel-based 4-planes congruent sets , year=
-
[51]
Landrieu and G
L. Landrieu and G. Obozinski , title =. SIAM J. Imaging Sci. , volume =. 2017 , month =
2017
-
[52]
2014 , note =
RIEGL VZ-400 3D Terrestrial Laser Scanner , howpublished =. 2014 , note =
2014
-
[53]
2024 , note =
RIEGL VZ-2000i Long Range 3D Laser Scanning System , howpublished =. 2024 , note =
2024
-
[54]
Householder, Alston S. , title =. 1958 , issue_date =. doi:10.1145/320941.320947 , journal =
-
[55]
Thomas and C
H. Thomas and C. R. Qi and J. -E. Deschaud and B. Marcotegui and F. Goulette and L. Guibas , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =. 2019 , address =
2019
-
[56]
Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.isprsjprs.2020.03.013 , url =
-
[57]
2025 , eprint=
Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets , author=. 2025 , eprint=
2025
-
[58]
High-Resolution Image Synthesis with Latent Diffusion Models , year=
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Björn , booktitle=. High-Resolution Image Synthesis with Latent Diffusion Models , year=
-
[59]
2025 , eprint=
Pico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing , author=. 2025 , eprint=
2025
-
[60]
How Multimodal
Zhuoran Yu and Yong Jae Lee , booktitle=. How Multimodal. 2025 , url=
2025
-
[61]
and Landrieu, L
Guinard, S. and Landrieu, L. , TITLE =. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences , VOLUME =. 2017 , PAGES =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.