Offline Reinforcement Learning for Rotation Profile Control in Tokamaks
Pith reviewed 2026-06-30 23:44 UTC · model grok-4.3
The pith
Offline reinforcement learning trained only on past DIII-D shots can control the full plasma rotation profile in real time on the tokamak.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We investigate the use of offline RL and offline model-based RL algorithms for rotation profile control, training them solely on historical data from the DIII-D tokamak. Our final method uses probabilistic models of plasma dynamics to generate rollouts for RL training. We deploy this policy on the DIII-D Tokamak and observe promising real-world results.
What carries the argument
Probabilistic models of plasma dynamics that generate rollouts for training offline RL policies solely from historical DIII-D shots.
If this is right
- Multi-input multi-output rotation-profile control becomes feasible without an accurate first-principles simulator.
- Data collected from past shots can be reused to train policies that are then run in closed loop on the device.
- The same offline-model-based workflow may extend to other high-dimensional tokamak control tasks once sufficient historical coverage exists.
- Real-time deployment reveals concrete challenges in safety, actuator limits, and data coverage that must be addressed for reliable operation.
Where Pith is reading between the lines
- If the approach scales, offline RL could serve as a general template for learning control laws on other fusion devices where simulators lag behind experimental data.
- Iterative data collection—running the policy, logging new trajectories, and retraining—could steadily enlarge the covered state space.
- The method implicitly assumes that the probabilistic model captures enough of the dynamics to avoid harmful extrapolation; violations would appear as unsafe actions on the device.
Load-bearing premise
Historical DIII-D shots contain sufficient coverage of the relevant state-action space and plasma conditions so that a policy learned from them will generalize safely and effectively when executed in real time on the live device.
What would settle it
Execution of the learned policy on a new set of DIII-D discharges that produces large deviations from target rotation profiles or triggers instabilities would falsify the claim of effective real-world control.
Figures
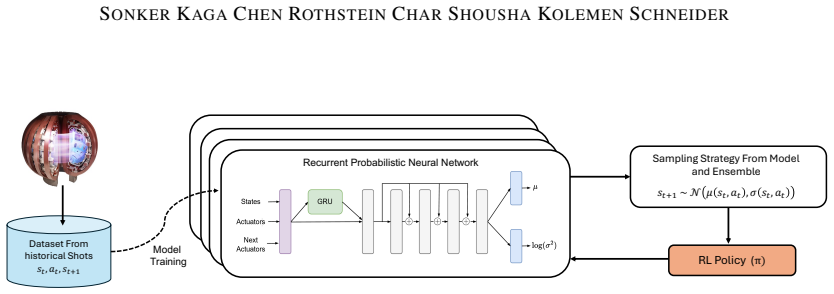





read the original abstract
Tokamaks remain leading candidates for achieving practical fusion energy, yet many important control problems inside these devices are still difficult or unsolved. One such challenge is controlling the plasma rotation profile, which strongly influences stability, confinement, and transport. While the average rotation can be controlled, controlling the full profile is challenging due to high dimensionality, response to multiple actuators and dependence on plasma condition. Learning-based control methods, such as reinforcement learning (RL), provide a potential solution to this challenging problem with ability to model complex interactions leading to effective multi-input multi-output control. However, learning such policies is challenging due to the lack of accurate simulators that can model the rotation profile dynamics. In this work, we investigate the use of offline RL and offline model-based RL algorithms for rotation profile control, training them solely on historical data from the DIII-D tokamak. Our final method uses probabilistic models of plasma dynamics to generate rollouts for RL training. We deploy this policy on the DIII-D Tokamak and observe promising real-world results. We conclude by highlighting key challenges and insights from training and deploying an RL policy on a complex physical device while using only limited past data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates offline RL and offline model-based RL for plasma rotation profile control in tokamaks. Policies are trained exclusively on historical DIII-D data; probabilistic models of plasma dynamics are used to generate rollouts during training. The central claim is that the resulting policy was deployed on the DIII-D tokamak and produced promising real-world results, with the work concluding by discussing challenges of real-world RL deployment from limited offline data.
Significance. Demonstrating safe, effective real-world deployment of an offline RL policy for a high-dimensional, safety-critical control task in a fusion device would be a notable contribution, as it addresses the absence of accurate simulators and shows practical generalization from historical data. The work also surfaces concrete deployment challenges that are valuable for the community. However, the absence of quantitative metrics, baselines, coverage analysis, or safety validation in support of the deployment claim substantially limits the assessed significance at present.
major comments (2)
- [Abstract] Abstract: The claim that 'we deploy this policy on the DIII-D Tokamak and observe promising real-world results' is presented without any quantitative performance metrics, comparison to existing controllers or baselines, safety-constraint satisfaction rates, or validation details. This evidence is load-bearing for the paper's primary contribution and must be supplied to substantiate the generalization from offline data to live execution.
- [Deployment / Results] Deployment / Results section: No analysis is provided of state-action space coverage in the historical DIII-D dataset, out-of-distribution detection during rollouts or execution, or mechanisms to prevent unsafe extrapolation. The skeptic concern that historical shots may not cover the relevant plasma conditions therefore remains unaddressed, directly affecting the reliability of the reported real-time deployment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of substantiating the real-world deployment claim, which we address point by point below. We will revise the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'we deploy this policy on the DIII-D Tokamak and observe promising real-world results' is presented without any quantitative performance metrics, comparison to existing controllers or baselines, safety-constraint satisfaction rates, or validation details. This evidence is load-bearing for the paper's primary contribution and must be supplied to substantiate the generalization from offline data to live execution.
Authors: We agree that the abstract claim would be strengthened by additional detail. The deployment section of the manuscript describes the real-time execution on DIII-D and characterizes the outcomes as promising based on the observed alignment of the rotation profile with targets during the limited experimental shots. However, the study was exploratory with a small number of deployments, and no formal quantitative metrics (e.g., integrated error or direct controller comparisons) were recorded due to operational constraints. We will revise the abstract to more precisely describe the results as 'we deploy this policy on the DIII-D Tokamak under supervised conditions and observe profile evolution consistent with the learned behavior' and include any available time-series plots from the deployment in the revised manuscript. revision: partial
-
Referee: [Deployment / Results] Deployment / Results section: No analysis is provided of state-action space coverage in the historical DIII-D dataset, out-of-distribution detection during rollouts or execution, or mechanisms to prevent unsafe extrapolation. The skeptic concern that historical shots may not cover the relevant plasma conditions therefore remains unaddressed, directly affecting the reliability of the reported real-time deployment.
Authors: The referee correctly notes the absence of explicit coverage analysis. The training dataset consists of all qualifying historical DIII-D discharges containing rotation profile measurements, and deployment occurred on plasmas with parameters within the observed historical ranges. No dedicated out-of-distribution detection module was implemented; instead, the existing tokamak safety systems and operator oversight served as safeguards against unsafe actions. We will add a new subsection in the revised manuscript that summarizes key statistics of the historical dataset (e.g., ranges of plasma current, density, and actuator commands) and explicitly describes the operational safeguards used during real-time execution. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper trains offline RL and model-based RL policies solely on historical DIII-D data, uses probabilistic models for rollouts during training, and reports real-world deployment results. No equations, parameter fits, or self-citations are described that would make any reported result equivalent to its inputs by construction. The central claims rest on external historical data and physical deployment, with no self-definitional, fitted-input-renamed-as-prediction, or uniqueness-via-self-citation patterns present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1109/ICRA.2017.7989202. Niannian Wu, Zongyu Yang, Rongpeng Li, Ning Wei, Yihang Chen, Qianyun Dong, Jiyuan Li, Guohui Zheng, Xinwen Gong, Feng Gao, et al. High-fidelity data-driven dynamics model for reinforcement learning-based control in hl-3 tokamak.Communications Physics, 8(1):393, 2025. 15 SONKERKAGACHENROTHSTEINCHARSHOUSHAKOLEMENSCHNEIDER Ti...
-
[2]
RPNN Training 6.1.1
Appendix 6.1. RPNN Training 6.1.1. STATE ANDACTUATORSPACE- The dynamics model (an ensemble of RPNN networks) models the transitions on a larger state and action space, in comparison to the policy. This is shown in table 2. Variables marked under Actuators and States are used in dynamics modeling. Only a subset of the states is provided as observations to ...
-
[3]
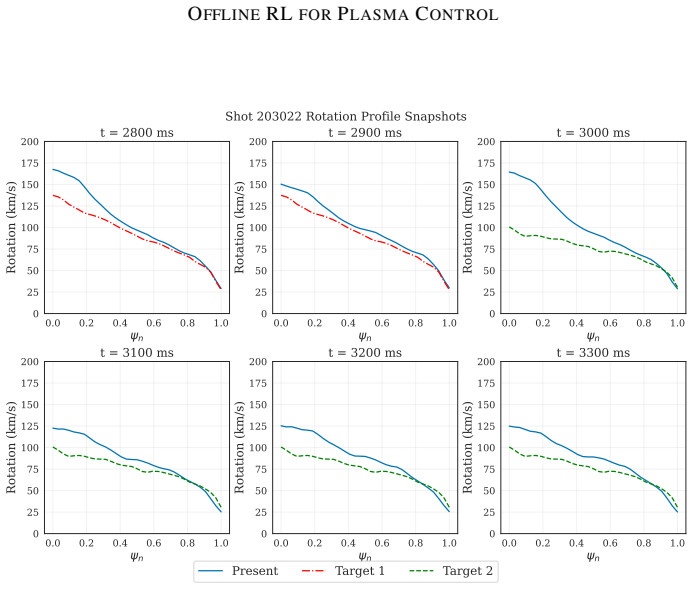
Fig.??shows the profile variation when the first target change occurs
Profile Views In this section, we present full rotation profile views across time. Fig.??shows the profile variation when the first target change occurs. This target change corresponds to a decrease in profile at t = 3s. Fig.??shows the profile changes that occur during the second target change at t = 4.5 s. At this point, more variations occur in the pla...
-
[4]
These plots show the actual amount of gas flowing into the plasma, corresponding well to the gas valve voltage, which the policy controls
Gas Flow In this section, plots showing the gas flow rate into the plasma are shown in Fig.??. These plots show the actual amount of gas flowing into the plasma, corresponding well to the gas valve voltage, which the policy controls. 19 SONKERKAGACHENROTHSTEINCHARSHOUSHAKOLEMENSCHNEIDER 0.0 0.5 1.0 n 0 50 100 150 200Rotation (km/s) t = 4400 ms 0.0 0.5 1.0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.