Data Augmentation: A Fourier Analysis Perspective
Pith reviewed 2026-06-26 00:12 UTC · model grok-4.3
The pith
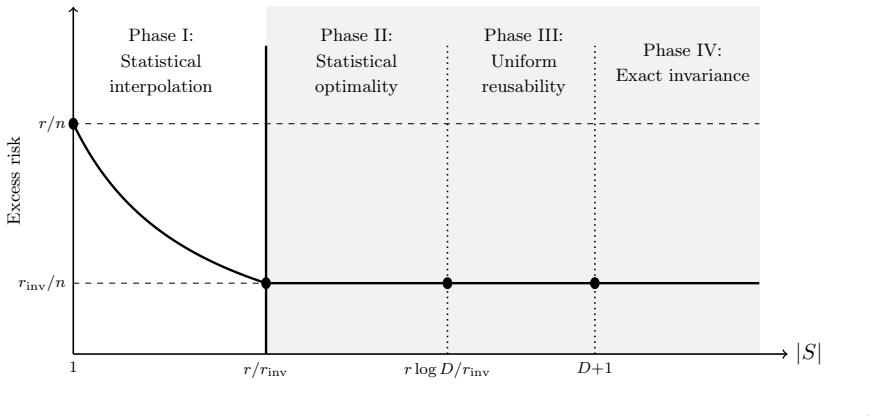
Partial data augmentation with randomly sampled group elements achieves the same minimax rates as full augmentation for a broad class of learning problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a general framework using Fourier analysis and the representation theory of finite groups to show that, for a broad class of classical learning problems, partial data augmentation based on a randomly sampled subset of group elements achieves the same minimax rates as full augmentation, up to an approximation error that vanishes as the subset size increases. We also prove that enforcing exact invariance via data augmentation requires averaging over the entire group and cannot be achieved by any strict subset when the hypothesis space is sufficiently expressive.
What carries the argument
Fourier analysis over the representation theory of finite groups, which decomposes the augmentation operator into irreducible components to bound the difference between partial random sampling and full group averaging.
If this is right
- Partial augmentation matches the optimal minimax rates of full augmentation up to vanishing error for many classical problems.
- The approximation gap shrinks as the random subset size increases.
- Exact invariance cannot be enforced by data augmentation over any proper subset of the group when the hypothesis space is expressive.
- Statistically optimal learning under group invariances is possible with computationally scalable partial methods.
Where Pith is reading between the lines
- Practitioners facing large symmetry groups can often use modest random subsets without sacrificing asymptotic rates.
- The same decomposition technique might be used to analyze other approximate symmetry methods such as penalty-based regularization.
- Finite-group results could serve as a stepping stone toward understanding partial augmentation for compact continuous groups via discretization.
Load-bearing premise
The symmetry group is finite so that its representation theory applies directly to the hypothesis space and loss functions of the learning problems.
What would settle it
An explicit finite-group example, such as the cyclic group of order four acting on binary classification, where the minimax excess risk for subset augmentation of size k stays bounded away from the full-group risk even as k grows to half the group order.
Figures
read the original abstract
Data augmentation is a simple and model-agnostic approach for exploiting known invariances in learning problems. Given a group acting on the input space, one augments the training set with transformed copies of each sample. Because it exploits symmetries without modifying the underlying learning algorithm, data augmentation can be applied broadly across learning methods. However, this universality comes at a computational cost: when the group is large, full group-sized augmentation quickly becomes computationally infeasible. This raises a fundamental question: Can partial data augmentation achieve the same statistical benefits as full augmentation in terms of generalization and sample complexity? We develop a general framework for investigating this question using Fourier analysis and the representation theory of finite groups. We show that, for a broad class of classical learning problems, partial data augmentation based on a randomly sampled subset of group elements achieves the same minimax rates as full augmentation, up to an approximation error that vanishes as the subset size increases. Our results provide a theoretical explanation for why partial augmentation can retain the statistical benefits of full augmentation despite enforcing symmetry only approximately, and shed light on a recently raised question in learning with symmetries: whether statistically optimal learning under general group invariances can be achieved using computationally scalable methods. Moreover, we prove a complementary impossibility result: enforcing exact invariance via data augmentation requires averaging over the entire group, and cannot be achieved by any strict subset when the hypothesis space is sufficiently expressive. Together, these results provide a unified perspective on full and partial data augmentation, as well as exact and approximate symmetry enforcement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a Fourier-analytic framework based on the representation theory of finite groups to study data augmentation. It claims that, for a broad class of classical learning problems, randomly sampling a subset of group elements for partial augmentation achieves the same minimax rates as full augmentation (up to an approximation error vanishing with subset size). A complementary impossibility result shows that exact invariance via augmentation requires averaging over the entire group when the hypothesis space is sufficiently expressive.
Significance. If the derivations hold, the results supply a theoretical basis for why partial augmentation retains statistical benefits while remaining computationally scalable, directly addressing questions about optimal learning under group invariances. The explicit use of representation theory to obtain rate equivalences is a methodological strength when the assumptions align with the problem class.
major comments (2)
- [§4, Theorem 4.3] §4, Theorem 4.3 (minimax rate equivalence): the argument that the excess risk decomposes into irreducible representations and that random subset averaging approximates the full group average in the relevant norm assumes the loss is linear or the hypothesis class is equivariant; for non-linear losses (e.g., logistic) or non-representation hypothesis classes the Fourier coefficients of the risk need not behave as stated, potentially introducing bias terms that alter the claimed minimax exponent.
- [§5, Corollary 5.2] §5, Corollary 5.2 (impossibility result): the claim that no strict subset suffices for exact invariance when the hypothesis space is 'sufficiently expressive' requires a precise characterization of expressivity; without an explicit condition linking expressivity to the dimension of the representation or the support of the Fourier transform, it is unclear whether the result applies beyond linear models.
minor comments (2)
- Notation for the random subset S and its size is introduced without a dedicated symbol table; consistent use of |S| versus m throughout would improve readability.
- The abstract states the results apply to 'a broad class of classical learning problems' but the precise list of problems (e.g., which losses and hypothesis classes) is only clarified in §3; an earlier enumeration would help.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which help improve the clarity and precision of our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§4, Theorem 4.3] §4, Theorem 4.3 (minimax rate equivalence): the argument that the excess risk decomposes into irreducible representations and that random subset averaging approximates the full group average in the relevant norm assumes the loss is linear or the hypothesis class is equivariant; for non-linear losses (e.g., logistic) or non-representation hypothesis classes the Fourier coefficients of the risk need not behave as stated, potentially introducing bias terms that alter the claimed minimax exponent.
Authors: We thank the referee for this observation. Our framework and Theorem 4.3 are developed for a class of learning problems where the excess risk admits a decomposition over irreducible representations, which is valid when the loss is linear in the predictions or when the hypothesis class is equivariant under the group action. This covers many classical problems, such as least-squares regression. For non-linear losses like the logistic loss, the risk function may not decompose in the same way, potentially leading to additional terms. We will revise Section 4 to explicitly state the assumptions on the loss function and hypothesis class required for the minimax rate equivalence, and add a remark that the results do not necessarily extend to arbitrary non-linear losses without further analysis. revision: yes
-
Referee: [§5, Corollary 5.2] §5, Corollary 5.2 (impossibility result): the claim that no strict subset suffices for exact invariance when the hypothesis space is 'sufficiently expressive' requires a precise characterization of expressivity; without an explicit condition linking expressivity to the dimension of the representation or the support of the Fourier transform, it is unclear whether the result applies beyond linear models.
Authors: We agree that the term 'sufficiently expressive' requires a more precise definition to clarify the scope of the impossibility result. In the paper, this refers to hypothesis spaces whose Fourier transforms have full support across all irreducible representations of the group. We will revise the statement of Corollary 5.2 and the surrounding discussion in Section 5 to include an explicit condition in terms of the dimension of the relevant representations or the support of the Fourier coefficients of the hypothesis class. This will make it clear that the result applies to hypothesis spaces that are rich enough to capture all group representations, which includes but is not limited to linear models. revision: yes
Circularity Check
No circularity; derivation applies standard Fourier analysis on finite groups
full rationale
The paper develops its framework by invoking the representation theory of finite groups and Fourier decomposition of functions on the group, which are external mathematical facts. The central claims equate minimax rates of partial and full augmentation via approximation of group averages in the Fourier basis and prove an impossibility result for exact invariance with proper subsets; neither step reduces to a fitted parameter, self-citation, or redefinition of the target quantity. The derivation remains self-contained against external benchmarks and does not rely on load-bearing self-citations or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Representation theory of finite groups applies to the learning problem and hypothesis space
- domain assumption The group acting on the input space is finite
Reference graph
Works this paper leans on
-
[1]
Equivariance with learned canonicalization functions , author=
-
[2]
A canonicalization perspective on invariant and equivariant learning , author=
-
[3]
Foundations and Trends
Artificial intelligence for science in quantum, atomistic, and continuum systems , author=. Foundations and Trends. 2025 , publisher=
2025
-
[4]
The exact sample complexity gain from invariances for kernel regression , author=
-
[5]
Generalization Bounds for Canonicalization: A Comparative Study with Group Averaging , author=
-
[6]
Sample Complexity Bounds for Estimating Probability Divergences under Invariances , author =
-
[7]
Frame averaging for invariant and equivariant network design , author=
-
[8]
A kernel theory of modern data augmentation , author=
-
[9]
arXiv preprint arXiv:2202.08871 , year=
Graph data augmentation for graph machine learning: A survey , author=. arXiv preprint arXiv:2202.08871 , year=
-
[10]
2018 international interdisciplinary PhD workshop (IIPhDW) , pages=
Data augmentation for improving deep learning in image classification problem , author=. 2018 international interdisciplinary PhD workshop (IIPhDW) , pages=. 2018 , organization=
2018
-
[11]
Array , volume=
Data augmentation: A comprehensive survey of modern approaches , author=. Array , volume=. 2022 , publisher=
2022
-
[12]
Journal of big data , volume=
A survey on image data augmentation for deep learning , author=. Journal of big data , volume=. 2019 , publisher=
2019
-
[13]
Learning with invariances in random features and kernel models , author=
-
[14]
Approximation-generalization trade-offs under (approximate) group equivariance , author=
-
[15]
Theory of Computing , volume =
Alon, Noga and Lovett, Shachar , title =. Theory of Computing , volume =. 2013 , pages =
2013
-
[16]
Random Structures & Algorithms , volume=
Random Cayley graphs and expanders , author=. Random Structures & Algorithms , volume=. 1994 , publisher=
1994
-
[17]
Data augmentation as feature manipulation , author=
-
[18]
Journal of Machine Learning Research , volume=
The good, the bad and the ugly sides of data augmentation: An implicit spectral regularization perspective , author=. Journal of Machine Learning Research , volume=
-
[19]
Journal of Machine Learning Research , volume=
A group-theoretic framework for data augmentation , author=. Journal of Machine Learning Research , volume=
-
[20]
Understanding the detrimental class-level effects of data augmentation , author=
-
[21]
Generalized equivalences between subsampling and ridge regularization , author=
-
[22]
Regularity in Canonicalized Models: A Theoretical Perspective , author=
-
[23]
International Journal of Computer Vision , pages=
A comprehensive survey of data augmentation in visual reinforcement learning , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[24]
Toward understanding generative data augmentation , author=
-
[25]
Adaptively Weighted Data Augmentation Consistency Regularization for Robust Optimization under Concept Shift , author =
-
[26]
Neurocomputing , volume=
A comprehensive survey for generative data augmentation , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[27]
Ai Open , volume=
Data augmentation approaches in natural language processing: A survey , author=. Ai Open , volume=. 2022 , publisher=
2022
-
[28]
Applied Soft Computing , volume=
Data augmentation techniques in natural language processing , author=. Applied Soft Computing , volume=. 2023 , publisher=
2023
-
[29]
Sample efficiency of data augmentation consistency regularization , author=
-
[30]
NeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations , year=
From Finite to Infinite Groups: A Polynomial-Time Algorithm for Learning with Exact Invariances , author=. NeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations , year=
2025
-
[31]
A Robust Kernel Statistical Test of Invariance: Detecting Subtle Asymmetries , author=
-
[32]
Learning with Exact Invariances in Polynomial Time , author=
-
[33]
Foundations of computational mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of computational mathematics , volume=. 2012 , publisher=
2012
-
[34]
Uniform expansion bounds for Cayley graphs of
Bourgain, Jean and Gamburd, Alex , journal=. Uniform expansion bounds for Cayley graphs of. 2008 , publisher=
2008
-
[35]
Nature communications , volume=
E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials , author=. Nature communications , volume=. 2022 , publisher=
2022
-
[36]
IEEE Signal Processing Magazine , volume=
Geometric deep learning: going beyond euclidean data , author=. IEEE Signal Processing Magazine , volume=. 2017 , publisher=
2017
-
[37]
Trends in Chemistry , volume=
Euclidean symmetry and equivariance in machine learning , author=. Trends in Chemistry , volume=. 2021 , publisher=
2021
-
[38]
Equivariant Frames and the Impossibility of Continuous Canonicalization , author=
-
[39]
Residual pathway priors for soft equivariance constraints , author=
-
[40]
Learning partial equivariances from data , author=
-
[41]
Relaxing equivariance constraints with non-stationary continuous filters , author=
-
[42]
Regularizing towards soft equivariance under mixed symmetries , author=
-
[43]
Approximate Equivariance in Reinforcement Learning , author =
-
[44]
Approximately equivariant networks for imperfectly symmetric dynamics , author=
-
[45]
Latent Space Symmetry Discovery , author=
-
[46]
Generative adversarial symmetry discovery , author=
-
[47]
Learning layer-wise equivariances automatically using gradients , author=
-
[48]
Discovering Group Structures via Unitary Representation Learning , author=
-
[49]
Physical Review D , volume=
Symmetry discovery with deep learning , author=. Physical Review D , volume=. 2022 , publisher=
2022
-
[50]
Symmetry discovery beyond affine transformations , author=
-
[51]
Lie algebra canonicalization: Equivariant neural operators under arbitrary lie groups , author=
-
[52]
Nature Reviews Physics , volume=
Advancing molecular simulation with equivariant interatomic potentials , author=. Nature Reviews Physics , volume=. 2023 , publisher=
2023
-
[53]
2013 , publisher=
Approximation theory and harmonic analysis on spheres and balls , author=. 2013 , publisher=
2013
-
[54]
arXiv preprint arXiv:2502.01886 , year=
Invariant kernels: Rank stabilization and generalization across dimensions , author=. arXiv preprint arXiv:2502.01886 , year=
-
[55]
AI Magazine , volume =
Weber, Melanie , title =. AI Magazine , volume =
-
[56]
International Conference on Learning Representations , volume=
On the hardness of learning under symmetries , author=. International Conference on Learning Representations , volume=
-
[57]
On Universality of Deep Equivariant Networks
On universality of deep equivariant networks , author=. arXiv preprint arXiv:2510.15814 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Achieving Approximate Symmetry Is Exponentially Easier than Exact Symmetry , author=
-
[59]
On the sample complexity of learning under geometric stability , author=
-
[60]
Adaptive Symmetry Discovery for Dynamical System Identification , author =
-
[61]
Automatic symmetry discovery with lie algebra convolutional network , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.