LARE: Low-Attention Region Encoding for Text-Image Retrieval
Pith reviewed 2026-06-26 21:23 UTC · model grok-4.3
The pith
A dual-encoding strategy that processes low-attention regions in parallel with full images produces more informative embeddings for text-image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
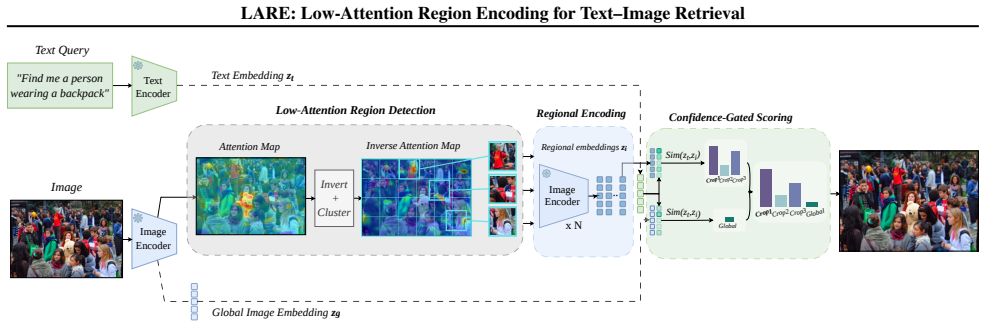
LARE adopts a dual-encoding strategy that encodes low-attention regions of an image and the full image in parallel, leading to more diverse and informative image embeddings that preserve subtle, non-dominant visual cues within the shared latent space and thereby improve retrieval performance on challenging crowded scenes.
What carries the argument
The dual-encoding strategy that encodes low-attention regions of an image and the full image in parallel.
If this is right
- Retrieval models gain access to visual cues from non-dominant regions that were previously neglected.
- Embeddings become more diverse because low-attention content is explicitly represented alongside the main image content.
- Performance gains appear on datasets that emphasize fine-grained descriptions of crowded scenes.
- Existing salience bias in visual encoders is shown to limit accuracy when low-attention regions carry matching information.
Where Pith is reading between the lines
- The same parallel encoding idea could be applied to video or 3D scenes where attention also concentrates on foreground motion.
- Downstream tasks such as visual question answering might benefit if the same low-attention features are made available to the language model.
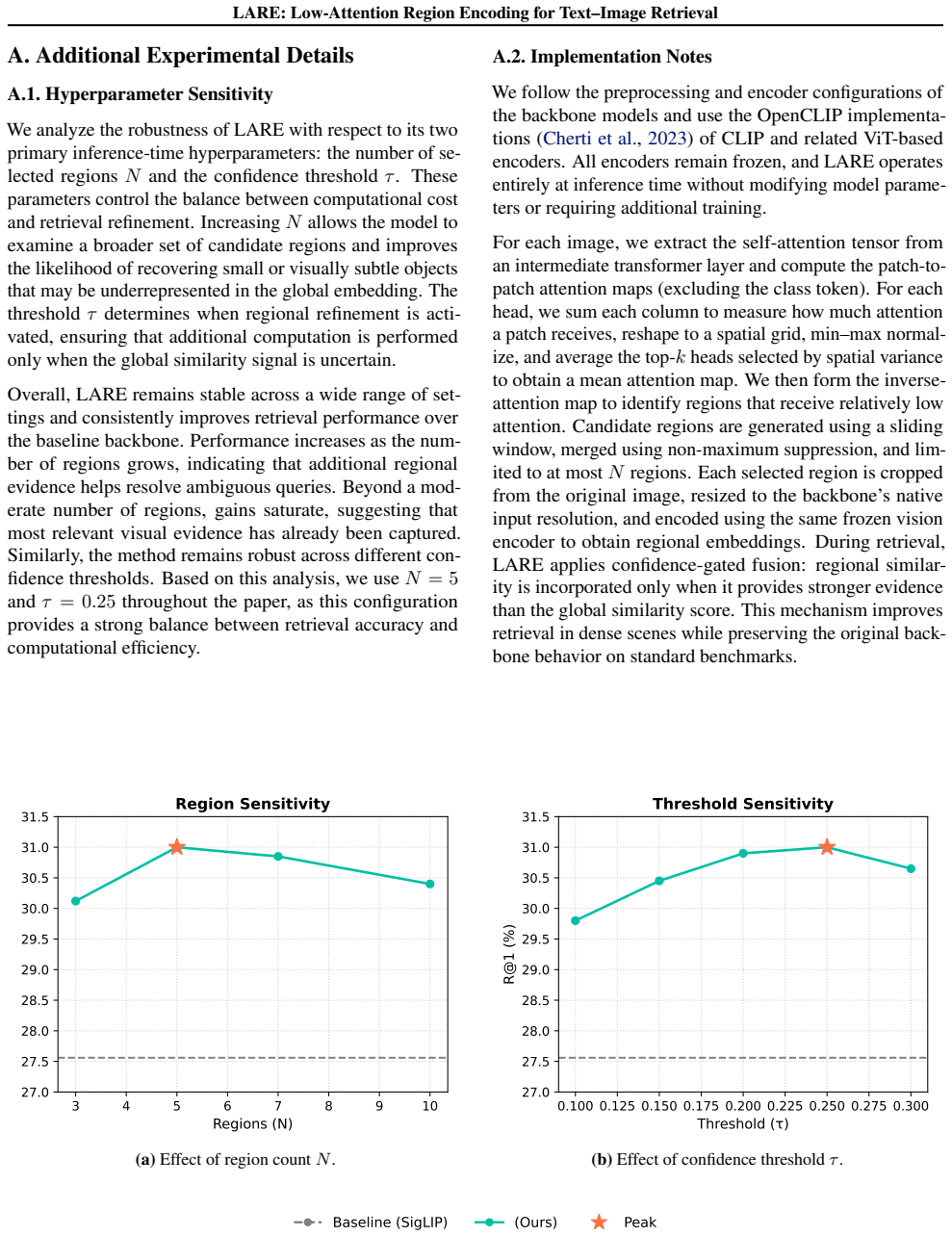
- A natural next measurement would be to quantify how much the added low-attention stream increases embedding dimensionality or training cost.
Load-bearing premise
Low-attention regions can be isolated and encoded separately in parallel with the full image without degrading the overall embedding quality or requiring extra implementation details.
What would settle it
Running the dual-encoding pipeline on Dense-Set and finding that retrieval metrics remain unchanged or decline relative to a standard single-encoder baseline would falsify the central claim.
Figures



read the original abstract
Image retrieval in crowded scenes is particularly challenging due to the salience bias of conventional visual encoders, which tend to focus on dominant objects while neglecting low-attention regions that are often crucial for fine-grained retrieval. We propose LARE (Low-Attention Region Encoding), a framework that explicitly models these overlooked regions. LARE adopts a dual-encoding strategy that encodes low-attention regions of an image and the full image in parallel, leading to more diverse and informative image embeddings. To evaluate image retrieval performance in challenging crowded scenes, we introduce Dense-Set, a challenging subset derived from COCO and Flickr30K. In this subset, images are re-captioned to provide richer descriptions of low-attention or previously overlooked regions. This dataset highlights the limitations of existing retrieval models and enables a more rigorous evaluation under densely crowded scene conditions. Experimental results demonstrate that the proposed framework improves retrieval performance by preserving subtle, non-dominant visual cues within the shared latent space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LARE, a dual-encoding framework that processes low-attention regions of an image in parallel with the full image to produce more diverse embeddings for text-image retrieval, addressing salience bias in crowded scenes. It also introduces the Dense-Set benchmark, a re-captioned subset of COCO and Flickr30K focused on overlooked regions, and claims that experimental results show improved retrieval performance by preserving subtle visual cues in the shared latent space.
Significance. If the empirical claims hold with proper validation, the dual-encoding approach could mitigate a known limitation of attention-based visual encoders in fine-grained retrieval tasks, and the Dense-Set benchmark would provide a useful testbed for dense-scene evaluation. However, the complete absence of any quantitative results, baselines, ablation studies, or implementation details in the manuscript prevents determining whether these contributions are significant.
major comments (1)
- [Abstract] Abstract: The central claim that 'Experimental results demonstrate that the proposed framework improves retrieval performance' is unsupported by any metrics, baselines, error bars, dataset statistics, or implementation specifics. This directly undermines verification of the empirical improvement asserted in the abstract and the reader's strongest claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for empirical support. We agree that the current manuscript version lacks the experimental results, baselines, and implementation details required to substantiate the abstract claim, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experimental results demonstrate that the proposed framework improves retrieval performance' is unsupported by any metrics, baselines, error bars, dataset statistics, or implementation specifics. This directly undermines verification of the empirical improvement asserted in the abstract and the reader's strongest claim.
Authors: We agree that the abstract's assertion requires concrete quantitative backing in the manuscript. The submitted version omitted the full experimental section (including results on Dense-Set, baseline comparisons, ablations, error bars, dataset statistics, and implementation details) due to an oversight during preparation. In the revised manuscript we will insert a complete Experiments section that reports retrieval metrics (e.g., R@1, R@5, R@10), comparisons against standard models, ablation studies on the dual-encoding components, statistical significance, and all implementation hyperparameters so that the abstract claim can be directly verified. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical framework (LARE dual-encoding) and a new benchmark (Dense-Set) whose performance claims rest on experimental results rather than any derivation chain. No equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claim is an observed improvement on a constructed test set, which is externally falsifiable and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Conventional visual encoders exhibit salience bias by focusing on dominant objects
- domain assumption Low-attention regions are often crucial for fine-grained retrieval
invented entities (1)
-
LARE dual-encoding strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[7]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[8]
FirstName LastName , title =
-
[9]
Advances in Neural Information Processing Systems , year=
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. Advances in Neural Information Processing Systems , year=
-
[10]
FirstName Alpher , title =
-
[11]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[12]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[13]
FirstName Alpher and FirstName Gamow , title =
-
[14]
International conference on machine learning , pages =
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author =. International conference on machine learning , pages =. 2022 , organization =
2022
-
[15]
Proceedings of the IEEE/CVF international conference on computer vision , pages =
Sigmoid loss for language image pre-training , author =. Proceedings of the IEEE/CVF international conference on computer vision , pages =
-
[16]
European Conference on Computer Vision , pages =
Crowd-sam: Sam as a smart annotator for object detection in crowded scenes , author =. European Conference on Computer Vision , pages =. 2024 , organization =
2024
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
On semantic similarity in video retrieval , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[18]
Neurocomputing , volume =
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning , author =. Neurocomputing , volume =. 2022 , publisher =
2022
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages =
Segment anything , author =. Proceedings of the IEEE/CVF international conference on computer vision , pages =
-
[20]
2024 , howpublished =
jina-clip-v2: Multilingual Multimodal Embeddings for Text and Images , author =. 2024 , howpublished =
2024
-
[21]
2024 , howpublished =
SAM 2: Segment Anything in Images and Videos , author =. 2024 , howpublished =
2024
-
[22]
Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig , title =
-
[23]
International conference on machine learning , pages =
Learning transferable visual models from natural language supervision , author =. International conference on machine learning , pages =. 2021 , organization =
2021
-
[24]
International conference on machine learning , pages =
Scaling up visual and vision-language representation learning with noisy text supervision , author =. International conference on machine learning , pages =. 2021 , organization =
2021
-
[25]
arXiv preprint arXiv:2111.07783 , year =
Filip: Fine-grained interactive language-image pre-training , author =. arXiv preprint arXiv:2111.07783 , year =
-
[26]
Advances in neural information processing systems , volume =
Pyramidclip: Hierarchical feature alignment for vision-language model pretraining , author =. Advances in neural information processing systems , volume =
-
[27]
Advances in neural information processing systems , volume =
Align before fuse: Vision and language representation learning with momentum distillation , author =. Advances in neural information processing systems , volume =
-
[28]
Advances in neural information processing systems , volume =
Attention is all you need , author =. Advances in neural information processing systems , volume =
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
X-pool: Cross-modal language-video attention for text-video retrieval , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[30]
2026 , howpublished =
Look Beyond Saliency: Low-Attention Guided Dual Encoding for Video Semantic Search , author =. 2026 , howpublished =
2026
-
[31]
Proceedings of the 30th ACM international conference on multimedia , pages =
X-clip: End-to-end multi-grained contrastive learning for video-text retrieval , author =. Proceedings of the 30th ACM international conference on multimedia , pages =
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Fine-grained image-text matching by cross-modal hard aligning network , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[33]
arXiv preprint arXiv:2104.08860 , year =
CLIP4Clip: An Empirical Study of CLIP for End-to-End Video Clip Retrieval , author =. arXiv preprint arXiv:2104.08860 , year =
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[35]
Proceedings of the 30th ACM International Conference on Multimedia (ACM MM) , year =
X-CLIP: End-to-End Multi-Grained Contrastive Learning for Video-Text Retrieval , author =. Proceedings of the 30th ACM International Conference on Multimedia (ACM MM) , year =
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
X-Pool: Cross-modal Language-Video Attention for Text-Video Retrieval , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Prompt switch: Efficient clip adaptation for text-video retrieval , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[38]
Belongie and James Hays and Pietro Perona and Deva Ramanan and Piotr Dollár and C
Tsung-Yi Lin and Michael Maire and Serge J. Belongie and James Hays and Pietro Perona and Deva Ramanan and Piotr Dollár and C. Lawrence Zitnick , title =. Proceedings of the 13th European Conference on Computer Vision (ECCV), Part V , pages =. 2014 , publisher =
2014
-
[39]
2025 , journal =
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features , author =. 2025 , journal =
2025
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
FLAIR: VLM with Fine-grained Language-informed Image Representations , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[41]
European Conference on Computer Vision , pages =
Dreamlip: Language-image pre-training with long captions , author =. European Conference on Computer Vision , pages =. 2024 , organization =
2024
-
[42]
Proceedings of the 22nd International Conference on Content-Based Multimedia Indexing (CBMI 2025) , year =
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval , author =. Proceedings of the 22nd International Conference on Content-Based Multimedia Indexing (CBMI 2025) , year =
2025
-
[43]
Proceedings of the 38th International Conference on Machine Learning , pages =
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , series =
2021
-
[44]
2023 , howpublished =
Sigmoid Loss for Language–Image Pre-training (SigLIP) , author =. 2023 , howpublished =
2023
-
[45]
European Conference on Computer Vision (ECCV) , year =
UNITER: UNiversal Image-TExt Representation Learning , author =. European Conference on Computer Vision (ECCV) , year =
-
[46]
arXiv preprint arXiv:2112.03521 , year =
Uniter-based situated coreference resolution with rich multimodal input , author =. arXiv preprint arXiv:2112.03521 , year =
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Reproducible scaling laws for contrastive language-image learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[48]
Proceedings of the 31st International Conference on Machine Learning (ICML) , year =
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition , author =. Proceedings of the 31st International Conference on Machine Learning (ICML) , year =
-
[49]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year =
CNN Features off-the-shelf: an Astounding Baseline for Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year =
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Large-scale Image Retrieval with Attentive Deep Local Features , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[51]
arXiv preprint arXiv:2104.14294 , year =
Emerging Properties in Self-Supervised Vision Transformers , author =. arXiv preprint arXiv:2104.14294 , year =
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
Proceedings of the IEEE international conference on computer vision , pages =
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models , author =. Proceedings of the IEEE international conference on computer vision , pages =
-
[54]
Technical Report, CNS-TR-2011-001, California Institute of Technology , year =
The Caltech-UCSD Birds-200-2011 Dataset , author =. Technical Report, CNS-TR-2011-001, California Institute of Technology , year =
2011
-
[55]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
Deep metric learning via lifted structured feature embedding , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Lvis: A dataset for large vocabulary instance segmentation , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[57]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[58]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =
Model Cards for Model Reporting , author =. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =
-
[59]
Proceedings of the British Machine Vision Conference (BMVC) , year=
Learning to ignore: Long-term tracker with inverse attention , author=. Proceedings of the British Machine Vision Conference (BMVC) , year=
-
[60]
arXiv preprint arXiv:2501.09333 , year=
Prompt-CAM: Making Vision Transformers Interpretable for Fine-Grained Analysis , author=. arXiv preprint arXiv:2501.09333 , year=
-
[61]
arXiv preprint arXiv:2509.04351 , year=
Global-to-Local or Local-to-Global? Enhancing Image Retrieval with Efficient Local Search and Effective Global Re-ranking , author=. arXiv preprint arXiv:2509.04351 , year=
-
[62]
arXiv preprint arXiv:2504.16691 , year=
Rethinking Vision Transformer for Large-Scale Fine-Grained Image Retrieval , author=. arXiv preprint arXiv:2504.16691 , year=
-
[63]
Transactions of the association for computational linguistics , volume=
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions , author=. Transactions of the association for computational linguistics , volume=. 2014 , publisher=
2014
-
[64]
arXiv preprint arXiv:2004.10934 , year=
YOLOv4: Optimal Speed and Accuracy of Object Detection , author=. arXiv preprint arXiv:2004.10934 , year=
Pith/arXiv arXiv 2004
-
[65]
arXiv preprint arXiv:2312.01597 , year=
SCLIP: Rethinking Self-Attention for Dense Vision-Language Inference , author=. arXiv preprint arXiv:2312.01597 , year=
-
[66]
ICCV , year=
VQA: Visual Question Answering , author=. ICCV , year=
-
[67]
CVPR , year=
Show and Tell: A Neural Image Caption Generator , author=. CVPR , year=
-
[68]
CVPR , year=
RegionCLIP: Region-based Language-Image Pretraining , author=. CVPR , year=
-
[69]
CVPR , year=
Grounded Language-Image Pre-training , author=. CVPR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.