Findings of the Counter Turing Test: AI-Generated Image Detection
Pith reviewed 2026-05-22 09:59 UTC · model grok-4.3
The pith
AI-generated images can be detected with high accuracy but identifying the exact generative model remains difficult.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Participants achieved F1-scores above 0.83 for classifying images as real or AI-generated using strategies such as convolutional neural networks, vision transformers, frequency-based analysis, contrastive learning, and multimodal techniques. In contrast, the highest F1-score for identifying which particular generative model produced a given image reached only 0.4986. The evaluation relied on a dataset combining real images with 50,000 synthetic images produced by multiple generative models.
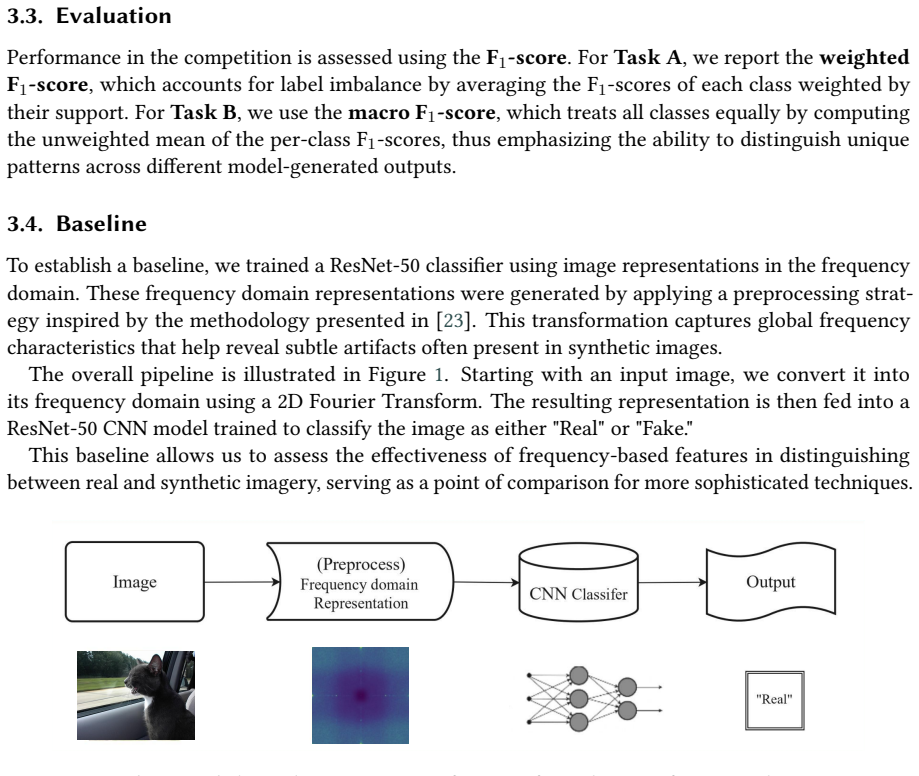
What carries the argument
A dual-task benchmark requiring first binary classification of images as real or synthetic and second attribution of synthetic images to their source generative model.
Load-bearing premise
The collected set of synthetic images from several current generative models paired with real images captures the range of visual properties that detectors will encounter in everyday use.
What would settle it
Testing the top binary and model-identification systems on images produced by generative models absent from the original dataset and measuring whether F1 scores fall below 0.7 would determine whether the reported performance generalizes.
Figures

read the original abstract
The rapid advancements in generative AI technologies, such as Stable Diffusion, DALL-E, and Midjourney, have significantly transformed the creation of synthetic visual content. While these models enable innovation across industries, they also pose serious challenges, including misinformation, disinformation, and biased content generation. The increasing realism of AI-generated images makes their detection a pressing concern for researchers, policymakers, and industry stakeholders. In this paper, we present the findings of the Defactify 4.0 workshop, which introduced the Counter Turing Test (CT2) for AI-Generated Image Detection. The competition consisted of two key tasks: (1) binary classification of images as either AI-generated or real and (2) identification of the specific generative model responsible for an AI-generated image. To support both tasks, we employed the MS COCOAI dataset, a benchmark of 96000 real and synthetic images generated by five state-of-the-art models alongside real images from MS COCO. Participants employed diverse detection strategies, including convolutional neural networks (CNNs), Vision Transformers (ViTs), frequency-based analysis, contrastive learning, and multimodal techniques. The results demonstrated that while AI-generated images can be detected with high accuracy (F1-score > 0.83), identifying the exact model used remains significantly more challenging (highest F1-score: 0.4986). These findings highlight the need for improved model fingerprinting, adversarial robustness, and real-time detection mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the findings of the Defactify 4.0 workshop's Counter Turing Test (CT2) competition on AI-generated image detection. It introduces the MS COCOAI dataset (50,000 synthetic images from multiple generative models paired with real MS COCO images) and describes participant submissions using CNNs, ViTs, frequency analysis, contrastive learning, and multimodal methods. The central empirical results are F1 > 0.83 on binary AI-vs-real classification and a best F1 of 0.4986 on identifying the specific generative model.
Significance. If the benchmark proves robust, the results establish that binary detection is practically feasible with existing architectures while model attribution remains substantially harder, providing a concrete empirical baseline that can guide future work on fingerprinting and adversarial robustness.
major comments (1)
- [§3] §3 (MS COCOAI dataset construction): The dataset is described only at a high level (50k synthetic images from 'multiple generative models' plus MS COCO reals). No information is given on exact model versions, generation hyperparameters, prompt sampling, resizing/upsampling kernels, or compression steps. This detail is load-bearing for the headline claim of F1 > 0.83, because without it the performance cannot be distinguished from exploitation of dataset-specific artifacts (fixed kernels, prompt biases, or train-test leakage) as noted in the stress-test concern.
minor comments (2)
- [Abstract] Abstract: The statement 'F1-score > 0.83' should specify whether this is the single best submission, the mean across teams, or a threshold; the same clarification is needed for the model-identification F1 of 0.4986.
- [Results] Results section: Add per-team breakdowns, number of submissions, and any statistical significance or variance measures for the reported F1 scores to allow readers to assess stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript describing the findings of the Defactify 4.0 Counter Turing Test competition. We address the single major comment below and will incorporate the requested details to strengthen the paper's reproducibility and address concerns about potential dataset artifacts.
read point-by-point responses
-
Referee: [§3] §3 (MS COCOAI dataset construction): The dataset is described only at a high level (50k synthetic images from 'multiple generative models' plus MS COCO reals). No information is given on exact model versions, generation hyperparameters, prompt sampling, resizing/upsampling kernels, or compression steps. This detail is load-bearing for the headline claim of F1 > 0.83, because without it the performance cannot be distinguished from exploitation of dataset-specific artifacts (fixed kernels, prompt biases, or train-test leakage) as noted in the stress-test concern.
Authors: We agree that the current high-level description of the MS COCOAI dataset in Section 3 is insufficient for full reproducibility and does not adequately address potential concerns about dataset-specific artifacts. In the revised manuscript we will expand Section 3 with a dedicated subsection that specifies the exact generative models and versions employed, the generation hyperparameters, the prompt sampling procedure (including how MS COCO captions were selected and diversified), and all post-processing steps such as resizing kernels, upsampling methods, and compression. We will also add a brief discussion of steps taken during dataset construction to mitigate common artifacts, such as prompt diversity and standardized pipelines. These additions will allow readers to better evaluate the robustness of the reported F1 scores (>0.83 for binary detection) and will clarify that the competition dataset was designed as a standardized benchmark rather than an artifact-prone test set. revision: yes
Circularity Check
No circularity: purely empirical competition report with no derivation chain
full rationale
The paper is a report on competition results for binary AI-vs-real classification and model identification using the MS COCOAI dataset. It contains no equations, mathematical derivations, fitted parameters, or self-citation chains that reduce any claimed performance metric to the input data by construction. All reported F1 scores are direct empirical outcomes from participant submissions evaluated on the held-out test split; the analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine-learning assumptions of i.i.d. data and representative sampling hold for the MS COCOAI dataset
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Participants employed diverse detection strategies, including convolutional neural networks (CNNs), Vision Transformers (ViTs), frequency-based analysis, contrastive learning, and multimodal techniques. The results demonstrated that while AI-generated images can be detected with high accuracy (F1-score > 0.83)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.