Automated IEP Generation from Traditional Chinese Parent-Teacher Interviews via Corpus-Grounded Feature Diffusion
Pith reviewed 2026-06-27 16:49 UTC · model grok-4.3
The pith
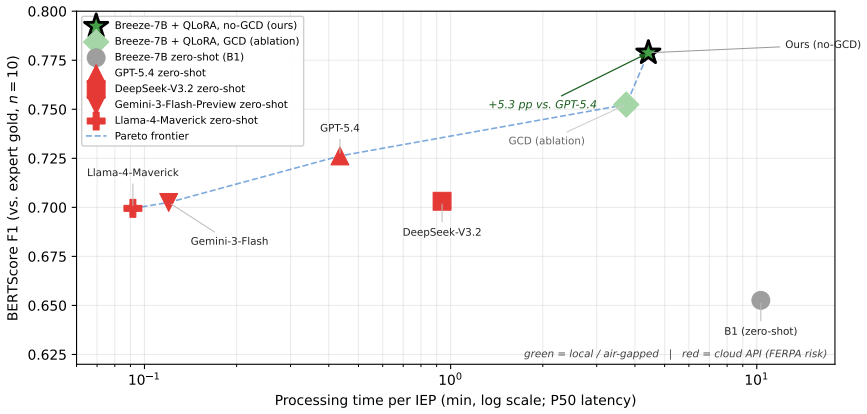
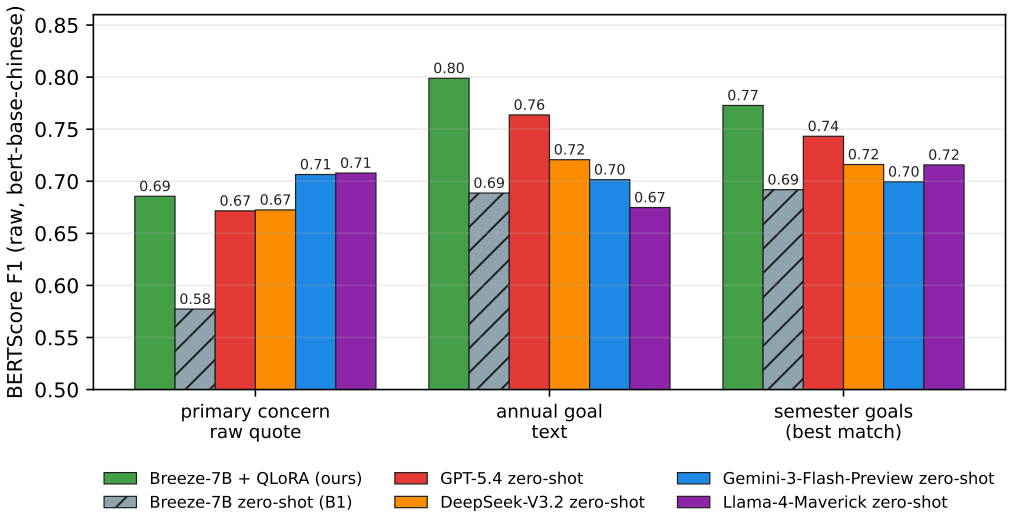
Corpus-grounded feature diffusion from 25 seed transcripts fine-tunes a 7B local model to generate Traditional Chinese IEPs at BERTScore F1 0.779, beating zero-shot larger models on a 10-sample hold-out.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
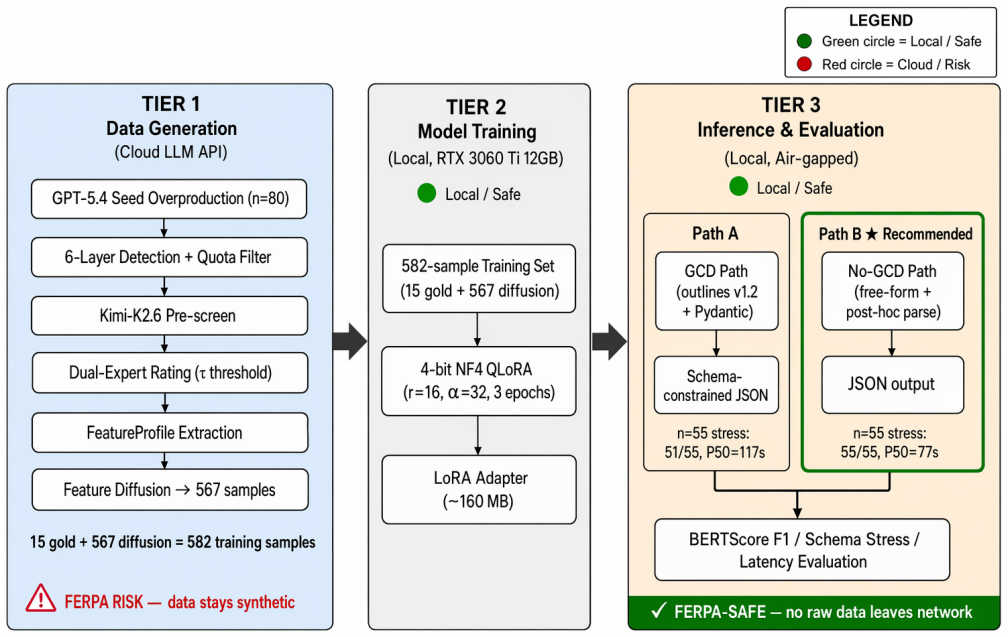
A 582-sample training set produced by Corpus-Grounded Feature Diffusion from 25 high-score seeds enables QLoRA fine-tuning of Breeze-7B such that the resulting model, when run without Grammar-Constrained Decoding, attains 0.779 BERTScore F1 on a 10-sample formal hold-out while achieving 100 percent schema pass rate at 34 percent lower median latency than the GCD path and outperforming the listed zero-shot baselines under fully local, air-gapped inference.
What carries the argument
Corpus-Grounded Feature Diffusion (CGFD), which extracts a FeatureProfile of sentence length, structure, and quantification templates from the 25 seeds and injects it into LLM prompts with Verbalized-Sampling diversity control to generate the 567 diffusion samples.
If this is right
- Skipping Grammar-Constrained Decoding improves both reliability and speed under Traditional Chinese token budgets.
- The resulting local model exceeds the listed larger zero-shot models on the n=10 hold-out while preserving privacy.
- The pipeline supplies a concrete low-resource route to schema-constrained document generation in data-scarce languages.
- Ablation on the 55-sample schema stress set confirms that GCD harms performance in this setting.
Where Pith is reading between the lines
- Similar diffusion pipelines could be tested on other low-resource document-generation tasks that require hierarchical output schemas.
- The finding that GCD hurts performance under certain token regimes may generalize to other East-Asian languages with comparable script constraints.
- The 25-seed starting point suggests that expert curation of a small high-quality core may be more critical than volume for domain adaptation in regulated fields.
Load-bearing premise
The 25 dual-expert high-score seed transcripts are representative of the domain and sufficient to produce diffusion samples whose FeatureProfiles capture the linguistic properties needed for effective fine-tuning.
What would settle it
Evaluating the fine-tuned model on an expanded hold-out set of 50 or more unseen parent-teacher interview transcripts would show whether the 0.779 BERTScore and 100 percent schema rate persist or degrade.
Figures
read the original abstract
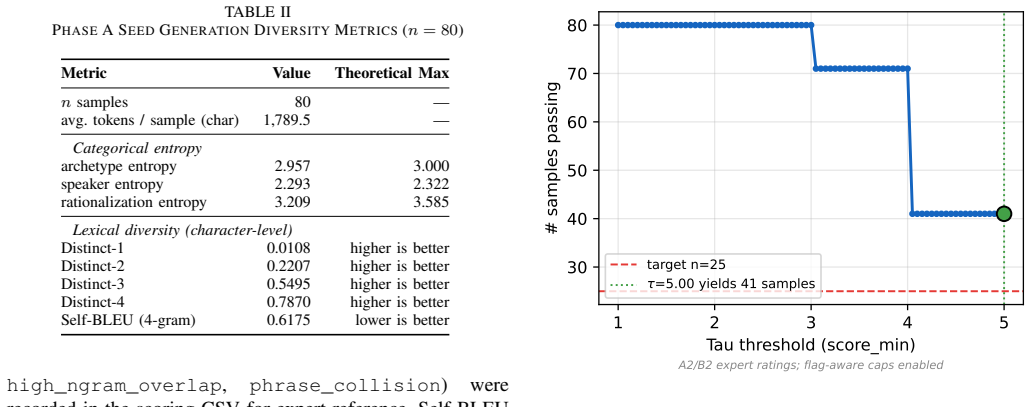
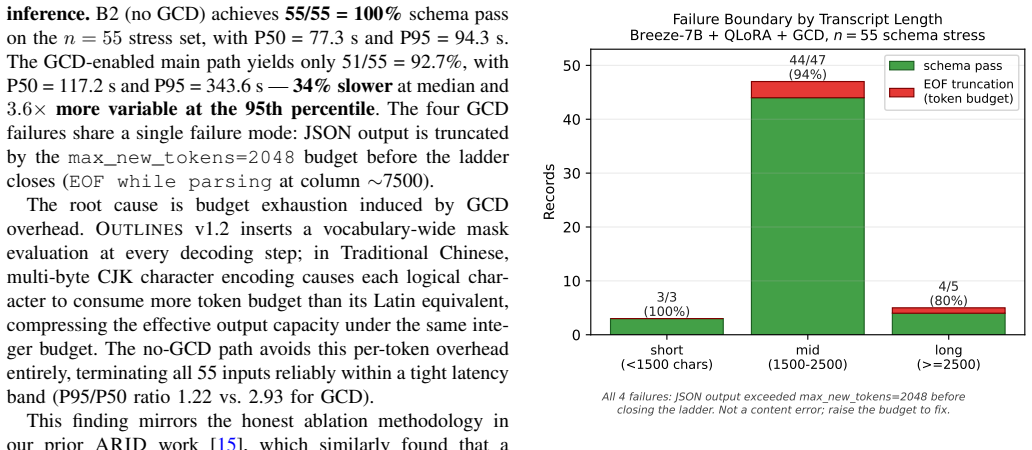
Writing Individualized Education Programs (IEPs) is a high-labor, knowledge-intensive document burden; English-language research has demonstrated that generative AI can significantly reduce drafting time, yet automated IEP generation in Traditional Chinese remains virtually unexplored due to domain data scarcity, strict privacy regulations, and the absence of local evaluation benchmarks. We propose a low-resource fine-tuning pipeline centered on Corpus-Grounded Feature Diffusion (CGFD): (1) 25 dual-expert high-score seed transcripts are selected via a tau threshold with flag-aware score caps; (2) a FeatureProfile (sentence length, structure, quantification templates) is extracted from seeds and injected into LLM prompts alongside Verbalized-Sampling-style diversity control to drive diffusion; (3) 15 expert gold seeds are used as diffusion anchors, targeting 585 samples; 567 valid diffusion samples are obtained, yielding a 582-sample training set used to fine-tune Breeze-7B with QLoRA; (4) schema-constrained inference via Grammar-Constrained Decoding (GCD) enforces a hierarchical SMART Goal Ladder schema at inference time. Ablation results on a 55-sample schema stress set reveal an unexpected finding: GCD is counterproductive under Traditional Chinese token budgets -- the no-GCD path achieves 100% schema pass rate at 34% lower median latency, outperforming GCD on both reliability and speed. On the n=10 formal hold-out, the no-GCD inference path achieves BERTScore F1 = 0.779, exceeding GPT-5.4 (0.726), DeepSeek-V3.2 (0.703), Gemini-3-Flash-Preview (0.703), and Llama-4-Maverick (0.700) zero-shot baselines while maintaining fully local, air-gapped inference. This system addresses a gap in Traditional Chinese special-education NLP and offers a scalable, privacy-preserving local inference solution under an industrial engineering paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a Corpus-Grounded Feature Diffusion (CGFD) pipeline that addresses data scarcity for Traditional Chinese IEP generation: 25 dual-expert high-score seed transcripts are selected via a tau threshold with flag-aware caps; FeatureProfiles (sentence length, structure, quantification templates) are extracted and injected into LLM prompts with Verbalized-Sampling diversity control to diffuse 567 valid samples from 15 gold anchors; these yield a 582-sample training set for QLoRA fine-tuning of Breeze-7B; schema-constrained inference is tested with and without Grammar-Constrained Decoding (GCD). Ablations on a 55-sample schema stress set show no-GCD achieves 100% schema pass rate at 34% lower median latency. On an n=10 formal hold-out, the no-GCD path reports BERTScore F1 = 0.779, exceeding zero-shot GPT-5.4 (0.726), DeepSeek-V3.2 (0.703), Gemini-3-Flash-Preview (0.703), and Llama-4-Maverick (0.700) while remaining fully local.
Significance. If the empirical results hold under more robust evaluation, the work provides a concrete, privacy-preserving local solution for a high-labor domain with no prior Traditional Chinese benchmarks, demonstrating that corpus-grounded diffusion plus lightweight fine-tuning can outperform much larger zero-shot models on this task. The ablation finding that GCD is counterproductive under Traditional Chinese token budgets is a useful engineering insight. The approach is grounded in real expert seeds and reports concrete hold-out metrics plus an ablation, which strengthens its practical contribution.
major comments (2)
- [Abstract] Abstract (n=10 formal hold-out paragraph): The headline claim that the no-GCD path exceeds the listed zero-shot baselines rests on a single point estimate (BERTScore F1 = 0.779) from only 10 samples, reported without variance, confidence intervals, per-sample scores, or any statistical test (e.g., paired t-test or bootstrap) against the baselines. With n=10 the observed 0.053 margin over GPT-5.4 is consistent with sampling variability or hold-out selection effects and therefore does not yet support the conclusion of reliable superiority.
- [Abstract] Abstract (steps 1-3): The construction of the 567 valid diffusion samples from 25 tau-thresholded seeds and 15 gold anchors is load-bearing for the fine-tuning data quality, yet the manuscript supplies no inter-rater reliability figures for the dual-expert scoring, the exact tau value, or the precise criteria used to declare a diffused sample 'valid'. These details are required to assess whether the FeatureProfiles truly capture the domain properties needed for the reported performance.
minor comments (1)
- [Abstract] Abstract: The sentence 'targeting 585 samples; 567 valid diffusion samples are obtained, yielding a 582-sample training set' leaves the arithmetic and filtering steps implicit; an explicit accounting of how the final training-set size is obtained would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive review and for recognizing the practical value of the CGFD pipeline for Traditional Chinese IEP generation. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (n=10 formal hold-out paragraph): The headline claim that the no-GCD path exceeds the listed zero-shot baselines rests on a single point estimate (BERTScore F1 = 0.779) from only 10 samples, reported without variance, confidence intervals, per-sample scores, or any statistical test (e.g., paired t-test or bootstrap) against the baselines. With n=10 the observed 0.053 margin over GPT-5.4 is consistent with sampling variability or hold-out selection effects and therefore does not yet support the conclusion of reliable superiority.
Authors: We agree that n=10 is small and that the reported point estimate alone does not support strong claims of superiority. The manuscript currently provides only the aggregate BERTScore F1. In revision we will add a table of per-sample scores, explicitly discuss the small-sample limitation in both the abstract and results, and qualify the comparison as preliminary rather than statistically demonstrated. With this sample size, formal confidence intervals or paired tests are unlikely to be informative, so we will not add them. revision: partial
-
Referee: [Abstract] Abstract (steps 1-3): The construction of the 567 valid diffusion samples from 25 tau-thresholded seeds and 15 gold anchors is load-bearing for the fine-tuning data quality, yet the manuscript supplies no inter-rater reliability figures for the dual-expert scoring, the exact tau value, or the precise criteria used to declare a diffused sample 'valid'. These details are required to assess whether the FeatureProfiles truly capture the domain properties needed for the reported performance.
Authors: We will revise the methods section to report the exact tau threshold, the flag-aware capping rules, and the concrete validity criteria applied to diffused samples (schema compliance plus expert review). The dual-expert scoring reached consensus through discussion; formal inter-rater reliability statistics were not computed, and we will add a clarifying note to that effect rather than retroactively claiming such metrics. revision: yes
Circularity Check
No circularity; central result is independent empirical comparison on held-out data
full rationale
The paper's derivation consists of selecting 25 seed transcripts, extracting FeatureProfiles to guide LLM-based diffusion for synthetic sample creation, fine-tuning Breeze-7B on the resulting 582-sample set, and reporting BERTScore F1 on a separate n=10 formal hold-out against external zero-shot baselines. No equation, parameter fit, or self-citation reduces the final reported metric to a quantity defined by the authors' own inputs or prior work. The evaluation is performed on held-out data using an external metric (BERTScore) and compared to independent models, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- tau threshold
- target diffusion sample count
axioms (2)
- domain assumption FeatureProfile (sentence length, structure, quantification templates) extracted from the 25 seeds is sufficient to drive high-quality diffusion when injected into prompts.
- domain assumption The 15 expert gold seeds serve as reliable diffusion anchors that keep generated samples within the target domain.
Reference graph
Works this paper leans on
-
[1]
Automated compliance and communica- tion system for IEP management,
iTherapy / NCSER SBIR, “Automated compliance and communica- tion system for IEP management,” IES/SBIR Award. https://ies.ed.gov/ use-work/awards/, 2025
2025
-
[2]
Enhancing individualized education program goal development for preschoolers with autism: A randomized controlled trial of generative AI,
S. Rakap and S. Balikci, “Enhancing individualized education program goal development for preschoolers with autism: A randomized controlled trial of generative AI,”Journal of Special Education Technology, 2024
2024
-
[3]
From personalized to pro- grammed: The use of generative AI to develop IEPs for students with disabilities,
Center for Democracy and Technology, “From personalized to pro- grammed: The use of generative AI to develop IEPs for students with disabilities,” https://cdt.org/insights/from-personalized-to-programmed-. .., 2025
2025
-
[4]
Generating authentic grounded synthetic maintenance work orders,
C. Lau, B. Feng, M. Hodkiewiczet al., “Generating authentic grounded synthetic maintenance work orders,” inIEEE Xplore Digital Library, 2025. [Online]. Available: https://ieeexplore.ieee.org/ iel8/6287639/10820123/11124200.pdf
2025
-
[5]
Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity,
S. Zhanget al., “Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity,” inOpenReview Preprint / arXiv 2510.01171, 2025
arXiv 2025
-
[6]
Beyond the surface: Measuring self-preference in LLM judgments,
Z. Chenet al., “Beyond the surface: Measuring self-preference in LLM judgments,” inProc. EMNLP, 2025. [Online]. Available: https://aclanthology.org/2025.emnlp-main.86.pdf
2025
-
[7]
Self-preference bias in LLM-as-a-judge,
K. Wataokaet al., “Self-preference bias in LLM-as-a-judge,” arXiv preprint arXiv:2410.21819, 2024. [Online]. Available: https: //arxiv.org/abs/2410.21819
Pith/arXiv arXiv 2024
-
[8]
Self- instruct: Aligning language models with self-generated instructions,
Y . Wang, S. Mishra, D. Khashabi, Q. V . Leet al., “Self- instruct: Aligning language models with self-generated instructions,” arXiv preprint arXiv:2212.10560, 2022. [Online]. Available: https: //arxiv.org/abs/2212.10560
Pith/arXiv arXiv 2022
-
[9]
Stanford Alpaca: An instruction- following LLaMA model,
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford Alpaca: An instruction- following LLaMA model,” https://github.com/tatsu-lab/stanford alpaca, 2023
2023
-
[10]
WizardLM: Empowering large pre-trained language models to follow complex instructions,
C. Xu, Q. Sun, K. Zhenget al., “WizardLM: Empowering large pre-trained language models to follow complex instructions,” arXiv preprint arXiv:2304.12244, 2023. [Online]. Available: https: //arxiv.org/abs/2304.12244
Pith/arXiv arXiv 2023
-
[11]
Automatic instruction evolving for large language models,
W. Zenget al., “Automatic instruction evolving for large language models,”arXiv preprint arXiv:2406.00770, 2024. [Online]. Available: https://arxiv.org/abs/2406.00770
arXiv 2024
-
[12]
MaintIE: A fine-grained annotation schema for maintenance text,
T. Bikaun, M. Hodkiewiczet al., “MaintIE: A fine-grained annotation schema for maintenance text,” Open dataset, 2024
2024
-
[13]
SQaLe: A large text-to-SQL corpus grounded in real schemas,
P. Wolffet al., “SQaLe: A large text-to-SQL corpus grounded in real schemas,”arXiv preprint arXiv:2602.22223, 2025
arXiv 2025
-
[14]
SPICE: Self-play in corpus environments improves reasoning,
X. Liuet al., “SPICE: Self-play in corpus environments improves reasoning,” 2025, arXiv preprint
2025
-
[15]
ARID: A deployable edge AI system for structured information extraction from industrial maintenance work orders,
K. Chen and C.-E. Ou, “ARID: A deployable edge AI system for structured information extraction from industrial maintenance work orders,” inProc. IEEE Int. Conf. Industrial Electronics Society (IECON), 2026, submitted, under review
2026
-
[16]
Quantifying and mitigating self-preference bias of LLM judges,
Y . Zhanget al., “Quantifying and mitigating self-preference bias of LLM judges,”arXiv preprint arXiv:2604.22891, 2026
Pith/arXiv arXiv 2026
-
[17]
INSTAJUDGE: Aligning judgment bias of LLM-as-judge with humans in industry applications,
J. Jang and F. Silavong, “INSTAJUDGE: Aligning judgment bias of LLM-as-judge with humans in industry applications,” inProc. EMNLP Industry Track, 2025. [Online]. Available: https://aclanthology.org/2025. emnlp-industry.82.pdf
2025
-
[18]
Grammar-constrained decoding for structured NLP tasks without finetuning,
S. Genget al., “Grammar-constrained decoding for structured NLP tasks without finetuning,” inProc. EMNLP, 2023. [Online]. Available: https://arxiv.org/abs/2305.13971
arXiv 2023
-
[19]
Grammar-constrained decoding for structured information extraction with fine-tuned generative models applied to clinical trial abstracts,
S. Geng, D. Tamet al., “Grammar-constrained decoding for structured information extraction with fine-tuned generative models applied to clinical trial abstracts,”Frontiers in Artificial Intelligence, 2024
2024
-
[20]
Flexible and efficient grammar-constrained decoding,
Y . Wanget al., “Flexible and efficient grammar-constrained decoding,” inProc. ICML, 2025, integrated in XGrammar
2025
-
[21]
Awesome-LLM-constrained-decoding,
S. Geng, “Awesome-LLM-constrained-decoding,” https://github.com/ Saibo-creator/Awesome-LLM-Constrained-Decoding, 2024
2024
-
[22]
Generative AI and IEP goal development: Impli- cations for special education teacher preparation,
D. Waterfieldet al., “Generative AI and IEP goal development: Impli- cations for special education teacher preparation,” CIDDL Policy Brief, 2025
2025
-
[23]
Improving reading comprehension in Taiwanese students: A study on a Chinese dialogue-based intelligent tutoring system,
Y .-H. Liao, S.-Y . Wu, and P.-C. Shih, “Improving reading comprehension in Taiwanese students: A study on a Chinese dialogue-based intelligent tutoring system,”Interactive Learning Environments, 2025
2025
-
[24]
C.-J. Hu, T.-Y . Shen, L. Walliset al., “Breeze-7B technical report,”arXiv preprint arXiv:2403.02712, 2024. [Online]. Available: https://arxiv.org/abs/2403.02712
arXiv 2024
-
[25]
P.-K. Hsuet al., “The Breeze-2 herd of models: Traditional Chinese LLMs based on LLaMA with vision-aware and function-calling capa- bilities,”arXiv preprint arXiv:2501.13921, 2025
arXiv 2025
-
[26]
Limits ofn-gram style control for LLMs via logit-space injection,
K. Chen and C.-E. Ou, “Limits ofn-gram style control for LLMs via logit-space injection,”arXiv preprint arXiv:2601.16224, 2026
arXiv 2026
-
[27]
Epistemic diversity and knowledge collapse in large language models,
J. Wrightet al., “Epistemic diversity and knowledge collapse in large language models,”arXiv preprint arXiv:2510.04226, 2026
arXiv 2026
-
[28]
M. James, “Counting on consensus: Selecting the right inter-annotator agreement metric for NLP annotation and evaluation,”arXiv preprint arXiv:2603.06865, 2026
arXiv 2026
-
[29]
LEAP: Common-law annotations for investigating the stability of dialog system output annotations,
S. Liet al., “LEAP: Common-law annotations for investigating the stability of dialog system output annotations,” inFindings of ACL, 2023. [Online]. Available: https://aclanthology.org/2023.findings-acl.780.pdf
2023
-
[30]
Toward reliable annotation in low-resource NLP: A mixture of agents framework and multi-LLM benchmarking,
K. Chen and C.-E. Ou, “Toward reliable annotation in low-resource NLP: A mixture of agents framework and multi-LLM benchmarking,” 2026, preprint
2026
-
[31]
Asking a language model for diverse responses,
S. Troshinet al., “Asking a language model for diverse responses,” inProc. ACL UncertaintyNLP Workshop, 2025. [Online]. Available: https://aclanthology.org/2025.uncertainlp-main.8.pdf
2025
-
[32]
BERTScore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “BERTScore: Evaluating text generation with BERT,” inInternational Conference on Learning Representations (ICLR), 2020. [Online]. Available: https://arxiv.org/abs/1904.09675
Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.