LUCID: Learning Unified Control for Image Deflaring and Exposure Mastery in Nighttime Photography
Pith reviewed 2026-06-27 22:42 UTC · model grok-4.3
The pith
LUCID unifies flare removal and exposure adjustment in nighttime photos through four-mode training and classifier-free guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
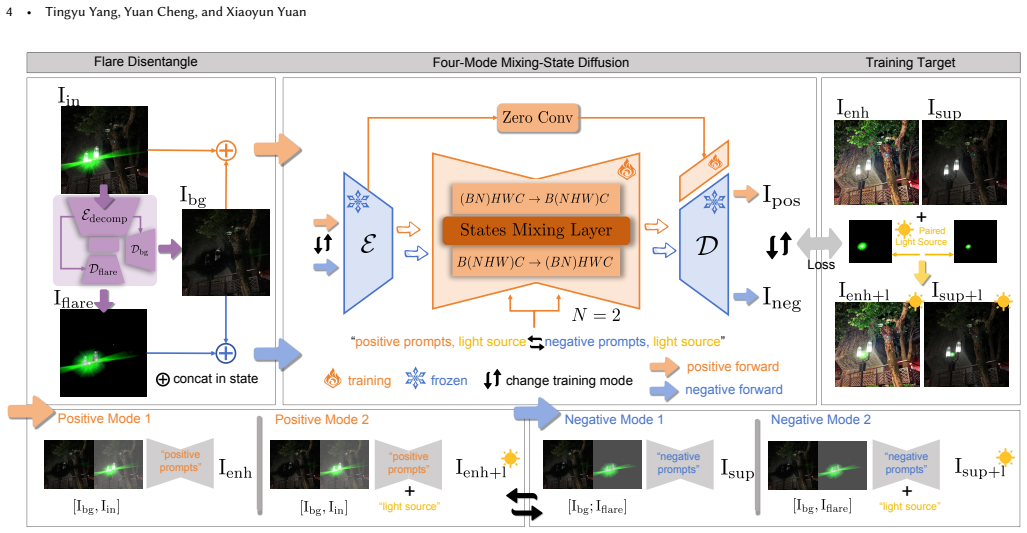
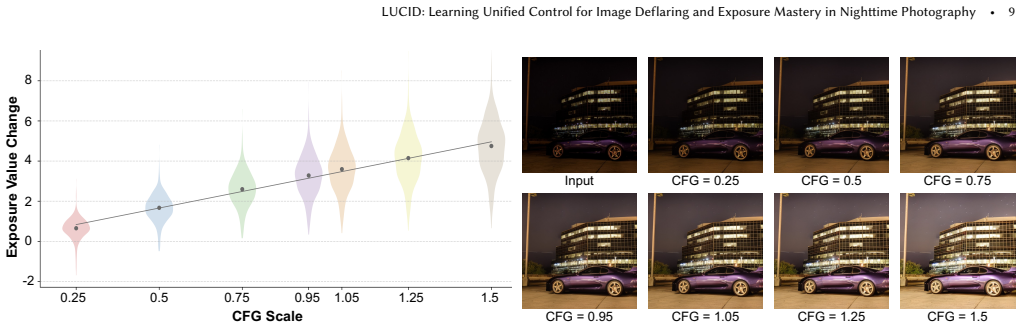
LUCID decomposes nighttime restoration into a flare disentanglement module that lifts optical artifacts to supply structural guidance and a diffusion-driven module that applies generative priors to reconstruct clean well-exposed imagery. It adds explicit controllability through a novel four-mode training strategy that supports selective steering of light sources, flare and ghosting artifacts, and high dynamic range reconstruction via continuous exposure control through classifier-free guidance.
What carries the argument
The four-mode training strategy that enables selective control via classifier-free guidance over the flare disentanglement module and diffusion-driven reconstruction.
Load-bearing premise
Nighttime degradations from flares and photon noise are entangled in a way that allows one model trained in four modes to provide reliable selective control without new artifacts or loss of scene structure.
What would settle it
Running the model on a real nighttime scene with bright light sources produces either visible residual flares or distorted scene details when compared to a clean reference capture.
Figures








read the original abstract
Photography is the art of painting with light, yet nighttime scenes are shaped by competing degradations: intense flares obscure scene structure, while photon-limited regions collapse into noise. Conventional approaches address these factors in isolation, overlooking the fact that these degradations are fundamentally entangled. To bridge this gap, we introduce LUCID, a unified framework that reframes nighttime restoration as a continuous and controllable process rather than a fixed correction. We decompose nighttime restoration into two cooperative components: a flare disentanglement module that lifts the 'curtain' of optical artifacts to provide reliable structural guidance, and a diffusion-driven module that leverages generative priors to reconstruct clean and well-exposed imagery. Crucially, LUCID introduces explicit controllability through a novel four-mode training strategy, enabling users to steer the restoration process via classifier-free guidance (CFG) and allowing selective control over light sources and their associated flare and ghosting artifacts, while also supporting high dynamic range (HDR) reconstruction through continuous exposure control. Extensive experiments demonstrate that LUCID consistently outperforms state-of-the-art methods across diverse real-world nighttime scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LUCID, a unified framework for nighttime image restoration that decomposes the task into a flare disentanglement module and a diffusion-driven reconstruction module. It proposes a four-mode training strategy to enable controllable restoration via classifier-free guidance, supporting selective control over flares/ghosting and continuous exposure for HDR output, and claims consistent outperformance over state-of-the-art methods on diverse real-world nighttime scenes.
Significance. If the central claims hold with supporting evidence, the work could represent a meaningful advance in controllable low-light restoration by treating entangled degradations in a single framework rather than isolated corrections, with potential utility in computational photography pipelines.
major comments (2)
- [Abstract] Abstract: The claim that 'LUCID consistently outperforms state-of-the-art methods across diverse real-world nighttime scenarios' is presented without any quantitative results, comparison tables, ablation studies, or experimental details, making it impossible to evaluate whether the four-mode strategy or CFG-based control delivers the stated gains.
- [Abstract] Abstract: No description, equations, or implementation details are supplied for the flare disentanglement module, the diffusion-driven module, the four-mode training strategy, or the classifier-free guidance mechanism, all of which are load-bearing for the controllability and unified-restoration claims.
Simulated Author's Rebuttal
We thank the referee for their feedback on the abstract. The comments highlight the need for clarity on what belongs in an abstract versus the full manuscript. We address each point below and note that the full paper contains the requested details, tables, and equations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'LUCID consistently outperforms state-of-the-art methods across diverse real-world nighttime scenarios' is presented without any quantitative results, comparison tables, ablation studies, or experimental details, making it impossible to evaluate whether the four-mode strategy or CFG-based control delivers the stated gains.
Authors: Abstracts are concise summaries and conventionally omit tables or full quantitative results to remain within length limits. The manuscript provides these in Section 4 (Experiments), including comparison tables against state-of-the-art methods on real-world nighttime datasets, ablation studies on the four-mode strategy, and quantitative metrics demonstrating the gains from CFG-based control. The abstract claim is supported by those results. revision: no
-
Referee: [Abstract] Abstract: No description, equations, or implementation details are supplied for the flare disentanglement module, the diffusion-driven module, the four-mode training strategy, or the classifier-free guidance mechanism, all of which are load-bearing for the controllability and unified-restoration claims.
Authors: The abstract is a high-level overview. Full technical descriptions, network architectures, loss functions, equations for the flare disentanglement module (Section 3.1), diffusion-driven module (Section 3.2), four-mode training strategy (Section 3.3), and classifier-free guidance mechanism are provided in the main body of the manuscript with accompanying figures and pseudocode. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and available description contain no equations, derivations, or load-bearing self-citations. Claims rest on empirical outperformance and a proposed four-mode training strategy for controllability, with no visible reduction of any prediction or uniqueness result to fitted inputs or prior self-work by construction. Without concrete technical sections or equations supplied for inspection, the derivation chain cannot be shown to collapse internally; the work is treated as self-contained method description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2022 , organization=
Unsupervised night image enhancement: When layer decomposition meets light-effects suppression , author=. 2022 , organization=
2022
-
[2]
Nighttime Visibility Enhancement by Increasing the Dynamic Range and Suppression of Light Effects , author=
-
[3]
From Generation to Suppression: Towards Effective Irregular Glow Removal for Nighttime Visibility Enhancement , author=
-
[4]
Flare7K: A Phenomenological Nighttime Flare Removal Dataset , author=
-
[5]
Improving Lens Flare Removal with General Purpose Pipeline and Multiple Light Sources Recovery , author=
-
[6]
MFDNet: Multi-Frequency Deflare Network for Efficient Nighttime Flare Removal , author=
-
[7]
Difflare: Removing Image Lens Flare with Latent Diffusion Model , author=
-
[8]
2010 , publisher=
Thin-film optical filters , author=. 2010 , publisher=
2010
-
[9]
Cockpit Displays X , volume=
Liquid-filled camera for the measurement of high-contrast images , author=. Cockpit Displays X , volume=. 2003 , organization=
2003
-
[10]
Kindling the Darkness: a Practical Low-light Image Enhancer , author=
-
[11]
Guo, Chunle and Li, Chongyi and Guo, Jichang and Loy, Chen Change and Hou, Junhui and Kwong, Sam and Cong, Runmin , title =
-
[12]
Benchmarking Low-Light Image Enhancement and Beyond , author=
-
[13]
Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model , author=
-
[14]
Deep Retinex Decomposition for Low-Light Enhancement , author=
-
[15]
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement , author=
-
[16]
and Garcia, Alvaro and Conde, Marcos V
Feijoo, Daniel and Benito, Juan C. and Garcia, Alvaro and Conde, Marcos V. , title =
-
[17]
Reti-Diff: Illumination Degradation Image Restoration with Retinex-based Latent Diffusion Model , author=
-
[18]
Journal of the Optical Society of America , volume=
Lightness and retinex theory , author=. Journal of the Optical Society of America , volume=. 1971 , doi=
1971
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
Xinqi Lin and Jingwen He and Ziyan Chen and Zhaoyang Lyu and Bo Dai and Fanghua Yu and Wanli Ouyang and Yu Qiao and Chao Dong , year=
-
[21]
Yu, Fanghua and Gu, Jinjin and Li, Zheyuan and Hu, Jinfan and Kong, Xiangtao and Wang, Xintao and He, Jingwen and Qiao, Yu and Dong, Chao , title =
-
[22]
Wu, Rongyuan and Yang, Tao and Sun, Lingchen and Zhang, Zhengqiang and Li, Shuai and Zhang, Lei , booktitle=CVPR, year=
-
[23]
One-Step Effective Diffusion Network for Real-World Image Super-Resolution , author=
-
[24]
arxiv , year =
Aiping Zhang and Zongsheng Yue and Renjing Pei and Wenqi Ren and Xiaochun Cao , title =. arxiv , year =
-
[25]
ArXiv , year =
Classifier-Free Diffusion Guidance , author =. ArXiv , year =
-
[26]
GaSLight: Gaussian Splats for Spatially-Varying Lighting in HDR , author=
-
[27]
Intrinsic Single-Image HDR Reconstruction , booktitle=ECCV, year=
Sebastian Dille and Chris Careaga and Ya. Intrinsic Single-Image HDR Reconstruction , booktitle=ECCV, year=
-
[28]
LEDiff: Latent Exposure Diffusion for HDR Generation , author =
-
[29]
Degradation-Modeled Multipath Diffusion for Tunable Metalens Photography , author=
-
[30]
Shi, Yichun and Wang, Peng and Ye, Jianglong and Mai, Long and Li, Kejie and Yang, Xiao , title =. arXiv:2308.16512 , year =
-
[31]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author =
-
[32]
arXiv preprint arXiv:2311.17042 , year=
Adversarial Diffusion Distillation , author=. arXiv preprint arXiv:2311.17042 , year=
-
[33]
IEEE Transactions on Image Processing , volume=
No-reference image quality assessment in the spatial domain , author=. IEEE Transactions on Image Processing , volume=
-
[34]
Journal of Visual Communication and Image Representation , volume=
R2rnet: Low-light image enhancement via real-low to real-normal network , author=. Journal of Visual Communication and Image Representation , volume=
-
[35]
Aakerberg, Andreas and Moeslund, Thomas B and Nasrollahi, Kamal , booktitle=NIPS, year=
-
[36]
IEEE Transactions on Image Processing , volume=
Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images , author=. IEEE Transactions on Image Processing , volume=
-
[37]
Learning to See in the Dark , author=
-
[38]
Computer Vision and Image Understanding , volume =
Getting to Know Low-light Images with The Exclusively Dark Dataset , author =. Computer Vision and Image Understanding , volume =. 2019 , doi =
2019
-
[39]
SI-HDR - dataset for comparison of single-image high dynamic range reconstruction methods , url=
Hanji, Param and Mantiuk, Rafal and Eilertsen, Gabriel and Hajisharif, Saghi and Unger, Jonas , year=. SI-HDR - dataset for comparison of single-image high dynamic range reconstruction methods , url=. doi:10.17863/CAM.87333 , publisher=
-
[40]
MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment , author=
-
[41]
Wang, Jianyi and Chan, Kelvin CK and Loy, Chen Change , title =
-
[42]
Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective , author=
-
[43]
MUSIQ: Multi-scale Image Quality Transformer , author=
-
[44]
Proceedings of the ACM SIGGRAPH Conference , year =
Param Hanji and Rafal Mantiuk and Gabriel Eilertsen and Saghi Hajisharif and Jonas Unger , title =. Proceedings of the ACM SIGGRAPH Conference , year =
-
[45]
NIMA: Neural Image Assessment , year=
Talebi, Hossein and Milanfar, Peyman , journal=. NIMA: Neural Image Assessment , year=. doi:10.1109/TIP.2018.2831899 , pages=
-
[46]
Removing diffraction image artifacts in under-display camera via dynamic skip connection network , author=
-
[47]
Under-display camera image restoration with scattering effect , author=
-
[48]
UDC-VIT: A Real-World Video Dataset for Under-Display Cameras , author=
-
[49]
Nighttime smartphone reflective flare removal using optical center symmetry prior , author=
-
[50]
AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion , author=
-
[51]
Controlling Vision-Language Models for Multi-Task Image Restoration , author=
-
[52]
UniCoRN: Latent Diffusion-based Unified Controllable Image Restoration Network across Multiple Degradations , author=
-
[53]
Neural Networks , year =
Jiahuan Ren and Zhao Zhang and Suiyi Zhao and Jicong Fan and Zhongqiu Zhao and Yang Zhao and Richang Hong and Meng Wang , title =. Neural Networks , year =
-
[54]
Tan , title =
Yeying Jin and Beibei Lin and Wending Yan and Yuan Yuan and Wei Ye and Robby T. Tan , title =
-
[55]
Bernabel and Sos S
Sherwin A. Bernabel and Sos S. Agaian , title =
-
[56]
Journal of King Saud University Computer and Information Sciences , year =
Yiqiang Zhou and Xindan Gao and Jifeng Guo and Guang Li and Lu Wang and Jing Liu , title =. Journal of King Saud University Computer and Information Sciences , year =
-
[57]
Simoncelli , title =
Keyan Ding and Kede Ma and Shiqi Wang and Eero P. Simoncelli , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[58]
Bovik , title =
Anish Mittal and Rajiv Soundararajan and Alan C. Bovik , title =. IEEE Signal Processing Letters , volume =
-
[59]
Venkatanath and D
N. Venkatanath and D. M. Praneeth and M. S. C. Murthy and S. S. Channappayya and A. C. Bovik , title =. 2015 Twenty First National Conference on Communications (NCC) , year =
2015
-
[60]
2021 , publisher =
How to Train Neural Networks for Flare Removal , author =. 2021 , publisher =
2021
-
[61]
2023 , publisher =
Semi-Supervised Learning for Low-Light Image Restoration Through Quality Assisted Pseudo-Labeling , author =. 2023 , publisher =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.