Do Language Models Pass the Bechdel Test? Auditing Gender Biases in LLM-Generated Screenplays
Pith reviewed 2026-06-25 23:29 UTC · model grok-4.3
The pith
Human-written screenplays pass the Bechdel test more often than those generated by large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
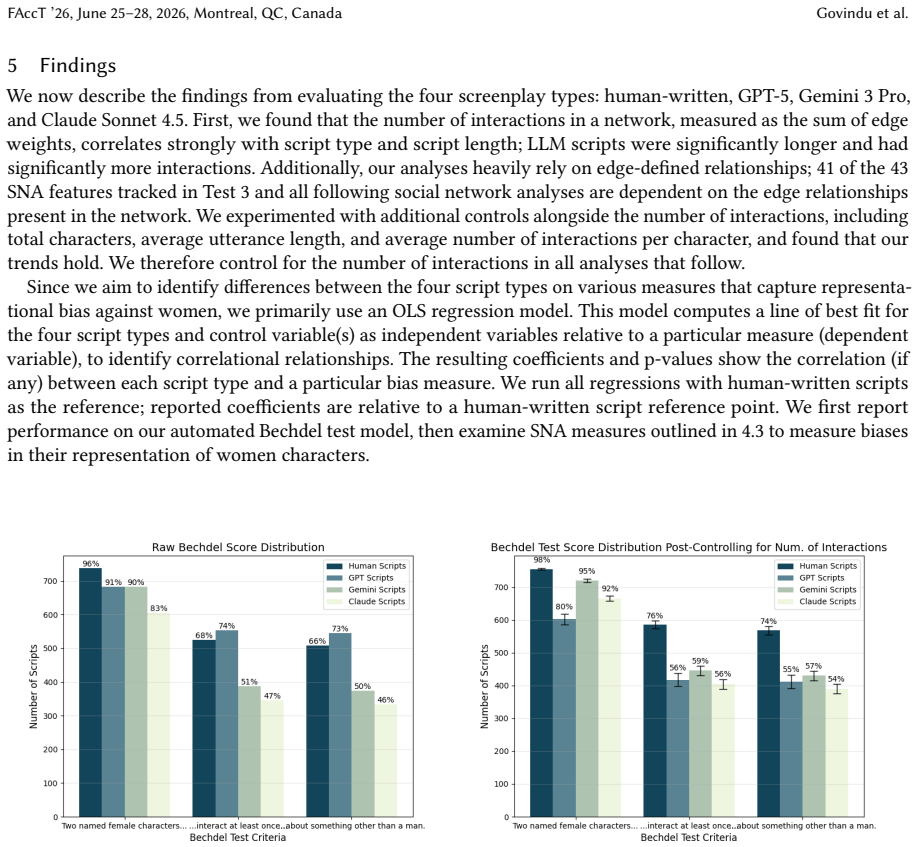
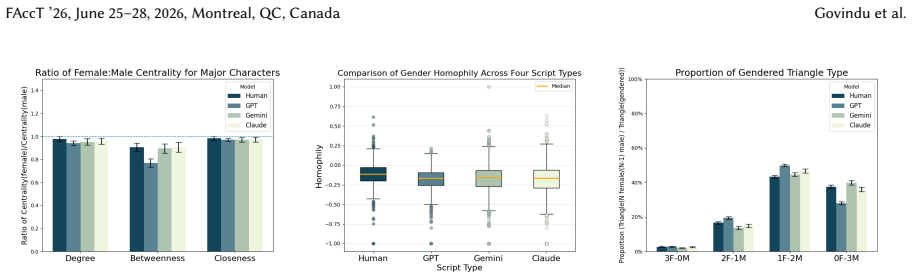
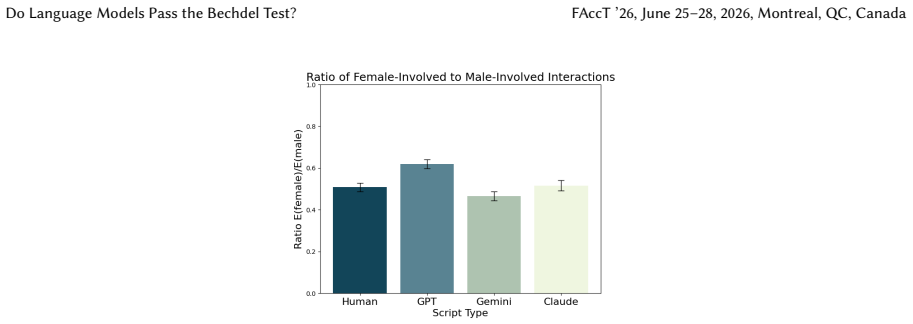
Screenplays generated by GPT-5, Gemini 3 Pro, and Claude Sonnet 4.5 are less likely to pass the Bechdel test than corresponding human-written screenplays, though measures of character centrality, homophily, and triadic relationships indicate that LLM scripts sometimes exhibit less representational bias, while every script type shows bias on most measures.
What carries the argument
An automated version of the Bechdel test applied to dialogue and character gender identification, supplemented by social network analysis of character interaction graphs.
If this is right
- LLMs may reduce the frequency of stories with strong female representation in generated media.
- Social network measures provide additional ways to quantify bias beyond the Bechdel test.
- Quantitative auditing tools are needed for AI-generated creative content.
Where Pith is reading between the lines
- If the automated test is reliable, then training data curation could reduce such biases in future models.
- Similar audits could be applied to other forms of LLM output like novels or news articles.
- Integration of bias-checking mechanisms directly into LLM prompting or fine-tuning might improve outputs.
Load-bearing premise
The automated Bechdel test and social network measures accurately capture representational bias without substantial errors from dialogue parsing, character gender identification, or prompt construction choices.
What would settle it
Finding that human raters disagree with the automated Bechdel test scores on a significant portion of the scripts, or that the gender identification step misclassifies characters frequently.
Figures
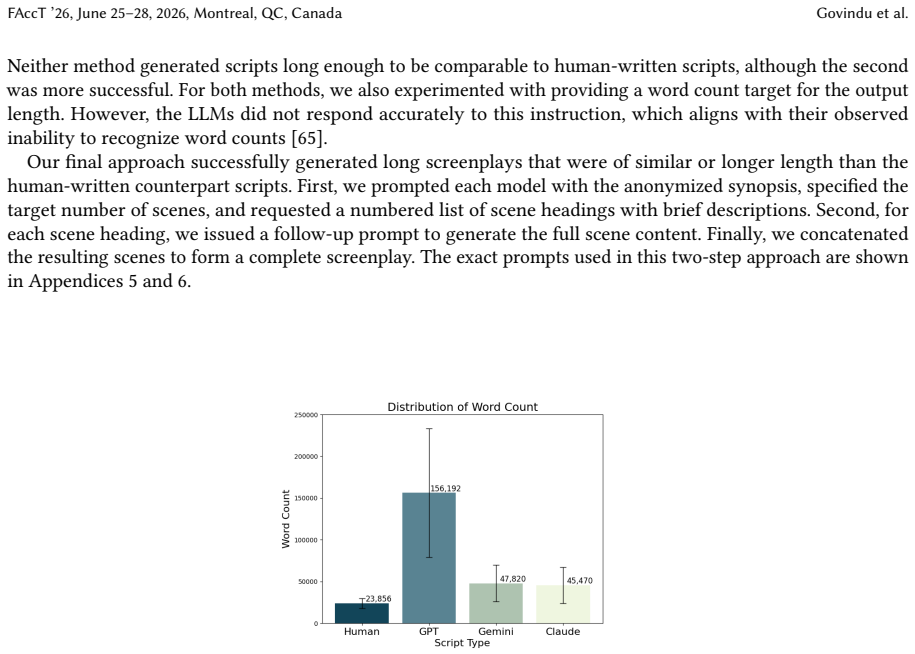


read the original abstract
As large language models (LLMs) are increasingly used in media production from journalistm to filmmaking, what impact do they have on the stories being told? Prior work has shown LLMs to perpetuate social biases, including those related to gender. We complement existing literature on gender bias in LLM outputs by auditing the network structure of LLM-generated movie screenplays through automating the Bechdel test, a popular measure of women's representation in literary and film works. We also introduce the use of social network analysis measures to further analyze representational bias in LLM-generated scripts. We evaluate screenplays generated by three state-of-the-art LLMs (GPT-5, Gemini 3 Pro, and Claude Sonnet 4.5) against 768 corresponding human-written screenplays, finding that human-written scripts are more likely to pass the Bechdel test. However, other network analyses, like centrality, homophily, and triadic relationships demonstrate that in some cases LLM-scripts have less bias, although all script types demonstrate some representational bias under most measures. We conclude by discussing the continued need for further quantitative assessments of media representations and AI-generated content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript automates the Bechdel test and applies social network analysis (centrality, homophily, triadic relationships) to compare screenplays generated by GPT-5, Gemini 3 Pro, and Claude Sonnet 4.5 against 768 matched human-written screenplays. It reports that human scripts pass the Bechdel test at higher rates, while LLM scripts sometimes exhibit lower bias on network measures, though all script types show representational bias on most metrics. The work positions this as a quantitative audit of gender bias in AI-generated media.
Significance. If the automated pipeline is reliable, the study supplies a replicable, quantitative framework for auditing narrative bias in LLM outputs that complements existing text-level bias analyses. The direct human baseline comparison and extension to screenplay network structure are strengths that could support future media-AI research.
major comments (3)
- [Methods] Methods section: The automated Bechdel pipeline (dialogue turn extraction, character name identification, binary gender assignment, and the three-condition check) reports no validation against human annotations—no precision/recall, inter-annotator agreement, or confusion matrix on the 768 screenplay pairs. This is load-bearing for the central claim because unquantified parser errors that differ by script source (e.g., LLM scripts having more ambiguous names or shorter turns) can produce the reported human-LLM difference as an artifact.
- [Results] Results section (Bechdel pass-rate comparison): The finding that human-written scripts are more likely to pass the Bechdel test rests entirely on the unvalidated pipeline; without error-rate bounds, it is impossible to determine whether the difference survives plausible levels of gender-inference or segmentation noise.
- [Results] Results section (social-network metrics): The same character-node errors propagate to centrality, homophily, and triadic-closure calculations; any claim that LLM scripts are “less biased” on these measures inherits the identical validation gap.
minor comments (2)
- [Abstract] Abstract: Typo 'journalistm' should read 'journalism'.
- [Methods] The manuscript should clarify the exact prompt templates and length/genre controls used when generating the LLM screenplays, as these choices can affect downstream network statistics.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. The concerns regarding validation of the automated Bechdel pipeline are well-taken and highlight a genuine limitation in the current version. We address each major comment point by point below and agree that revisions are needed to strengthen the work. We will incorporate the suggested validation and sensitivity analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: The automated Bechdel pipeline (dialogue turn extraction, character name identification, binary gender assignment, and the three-condition check) reports no validation against human annotations—no precision/recall, inter-annotator agreement, or confusion matrix on the 768 screenplay pairs. This is load-bearing for the central claim because unquantified parser errors that differ by script source (e.g., LLM scripts having more ambiguous names or shorter turns) can produce the reported human-LLM difference as an artifact.
Authors: We acknowledge that the manuscript does not include a quantitative validation of the automated pipeline against human annotations, which is a substantive gap. To address this, we will add a dedicated validation subsection in Methods. We will manually annotate a stratified random sample of 100 screenplays (50 human-written, 50 LLM-generated) with two independent annotators, reporting precision, recall, and F1 for each pipeline stage (dialogue extraction, character identification, gender assignment, and Bechdel condition checks), along with inter-annotator agreement via Cohen's kappa. We will also compare error rates between human and LLM sources to test for differential bias in parsing. revision: yes
-
Referee: [Results] Results section (Bechdel pass-rate comparison): The finding that human-written scripts are more likely to pass the Bechdel test rests entirely on the unvalidated pipeline; without error-rate bounds, it is impossible to determine whether the difference survives plausible levels of gender-inference or segmentation noise.
Authors: We agree that the Bechdel pass-rate results cannot be fully interpreted without error bounds. In the revision, after adding the validation metrics, we will include a sensitivity analysis in Results. This will simulate plausible error rates (e.g., 5%, 10%, and 15% misclassification in gender or segmentation) drawn from the validation study and recompute pass rates under these perturbations. We will report whether the human-LLM gap remains statistically significant across these scenarios and qualify the main finding accordingly if it does not. revision: yes
-
Referee: [Results] Results section (social-network metrics): The same character-node errors propagate to centrality, homophily, and triadic-closure calculations; any claim that LLM scripts are “less biased” on these measures inherits the identical validation gap.
Authors: We concur that character identification and gender assignment errors would affect all downstream network metrics. The same validation study will quantify accuracy for the character nodes and gender labels used in network construction. We will then propagate these error estimates to provide confidence intervals or robustness checks for centrality, homophily, and triadic closure results. Our original text already described the network findings as mixed rather than claiming LLM superiority; we will further emphasize this qualification and note the validation dependency in the revised Results and Discussion sections. revision: yes
Circularity Check
No circularity: purely empirical comparison to external human baseline
full rationale
The paper conducts a direct empirical audit by generating screenplays from three LLMs and comparing them to 768 human-written scripts using an automated Bechdel test plus social-network metrics. No equations, parameter fits, derivations, or predictions appear. The central claim (human scripts pass Bechdel at higher rates) is a straightforward measurement against an external corpus; it does not reduce to any self-defined quantity, fitted input renamed as prediction, or self-citation chain. All load-bearing steps are external data comparisons, so the analysis is self-contained with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abubakar Abid, Maheen Farooqi, and James Zou. 2021. Persistent Anti-Muslim Bias in Large Language Models. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’21). Association for Computing Machinery, New York, NY, USA, 298–306. doi:10.1145/3461702.3462624
-
[2]
Apoorv Agarwal, Sriramkumar Balasubramanian, Jiehan Zheng, and Sarthak Dash. 2014. Parsing Screenplays for Extracting Social Networks from Movies. InProceedings of the 3rd Workshop on Computational Linguistics for Literature (CLFL), Anna Feldman, Anna Kazantseva, and Stan Szpakowicz (Eds.). Association for Computational Linguistics, Gothenburg, Sweden, 50...
-
[3]
Apoorv Agarwal, Jiehan Zheng, Shruti Kamath, Sriramkumar Balasubramanian, and Shirin Ann Dey. 2015. Key Female Characters in Film Have More to Talk About Besides Men: Automating the Bechdel Test. InProceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Rada Mihalcea, ...
-
[4]
Evan Bailyn. 2025. Top Generative AI Chatbots by Market Share – December 2025. https://firstpagesage.com/reports/top-generative-ai- chatbots/ Section: SEO Blog
2025
-
[5]
David Bamman, Rachael Samberg, Richard Jean So, and Naitian Zhou. 2024. Measuring diversity in Hollywood through the large-scale computational analysis of film.Proceedings of the National Academy of Sciences121, 46 (Nov. 2024), e2409770121. doi:10.1073/pnas. 2409770121 Publisher: Proceedings of the National Academy of Sciences
-
[6]
Solon Barocas, Kate Crawford, Aaron Shapiro, and Hanna Wallach. 2017. The problem with bias: From allocative to representational harms in machine learning. InSIGCIS conference paper
2017
-
[7]
1985.Dykes to Watch Out For
Alison Bechdel. 1985.Dykes to Watch Out For. Firebrand Books. https://dykestowatchoutfor.com/
1985
-
[8]
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020. Language (Technology) is Power: A Critical Survey of “Bias” in NLP. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 5454...
-
[9]
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. InAdvances in Neural Information Processing Systems, Vol. 29. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2016/hash/a486cd07e4ac3d270571622f4f316ec5-Abstract.html
2016
-
[10]
Labor Issues Are Queer Issues
Joel Kim Booster. 2023. GLAAD Media Awards 2023: Fire Island’s Joel Kim Stands Strong With WGA In Acceptance Speech: “Labor Issues Are Queer Issues”. https://glaad.org/glaad-media-awards-2023-fire-islands-joel-kim-stands-strong-wga-acceptance-speech- labor-issues/
2023
-
[11]
Boyle and L
D. Boyle and L. Tandan. 2008. Slumdog Millionaire
2008
-
[12]
Semantics derived automatically from language corpora contain human-like biases
Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases.Science356, 6334 (April 2017), 183–186. doi:10.1126/science.aal4230
-
[13]
Serina Chang, Alicja Chaszczewicz, Emma Wang, Maya Josifovska, Emma Pierson, and Jure Leskovec. 2025. LLMs Generate Structurally Realistic Social Networks but Overestimate Political Homophily.Proceedings of the International AAAI Conference on Web and Social Media19 (June 2025), 341–371. doi:10.1609/icwsm.v19i1.35820
-
[14]
Kate Crawford. 2017. The Trouble with Bias. InKeynote at NeurIPS
2017
-
[15]
Hannah Cyberey, Yangfeng Ji, and David Evans. 2025. Unsupervised Concept Vector Extraction for Bias Control in LLMs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 28333...
-
[16]
Nurcan Durak, Ali Pinar, Tamara G. Kolda, and C. Seshadhri. 2012. Degree relations of triangles in real-world networks and graph models. InProceedings of the 21st ACM international conference on Information and knowledge management (CIKM ’12). Association for Computing Machinery, New York, NY, USA, 1712–1716. doi:10.1145/2396761.2398503
-
[17]
David Garcia, Ingmar Weber, and Venkata Garimella. 2014. Gender Asymmetries in Reality and Fiction: The Bechdel Test of Social Media.Proceedings of the International AAAI Conference on Web and Social Media8, 1 (May 2014), 131–140. doi:10.1609/icwsm.v8i1.14522
-
[18]
Vagrant Gautam, Arjun Subramonian, Anne Lauscher, and Os Keyes. 2024. Stop! In the Name of Flaws: Disentangling Personal Names and Sociodemographic Attributes in NLP. InProceedings of the 5th Workshop on Gender Bias in Natural Language Processing (GeBNLP), Agnieszka Faleńska, Christine Basta, Marta Costa-jussà, Seraphina Goldfarb-Tarrant, and Debora Nozza...
-
[19]
Philip John Gorinski and Mirella Lapata. 2015. Movie Script Summarization as Graph-based Scene Extraction. InProceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Rada Mihalcea, Joyce Chai, and Anoop Sarkar (Eds.). Association for Computational Linguistics, Denver, C...
-
[20]
Mark S Granovetter. 1973. The strength of weak ties.American journal of sociology78, 6 (1973), 1360–1380
1973
-
[21]
Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, and Sharese King. 2024. AI generates covertly racist decisions about people based on their dialect.Nature633, 8028 (Sept. 2024), 147–154. doi:10.1038/s41586-024-07856-5 Publisher: Nature Publishing Group
-
[22]
Hayate Iso, Pouya Pezeshkpour, Nikita Bhutani, and Estevam Hruschka. 2025. Evaluating Bias in LLMs for Job-Resume Matching: Gender, Race, and Education. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track), Weizhu Chen, Yi Yang, ...
-
[23]
Dima Kagan, Thomas Chesney, and Michael Fire. 2020. Using data science to understand the film industry’s gender gap.Palgrave Communications6, 1 (May 2020), 92. doi:10.1057/s41599-020-0436-1 Publisher: Palgrave
-
[24]
D. Kellner. 1995.Media Culture: Cultural Studies, Identity and Politics Between the Modern and the Postmodern. Routledge. https: //books.google.com/books?id=GjbdsiZ0q10C
1995
-
[25]
Molly Kinder. 2024. Hollywood writers went on strike to protect their livelihoods from generative AI. Their remarkable victory matters for all workers. https://www.brookings.edu/articles/hollywood-writers-went-on-strike-to-protect-their-livelihoods-from-generative- ai-their-remarkable-victory-matters-for-all-workers/
2024
-
[26]
Dreyer, Aleksandar Shtedritski, and Yuki M
Hannah Rose Kirk, Yennie Jun, Haider Iqbal, Elias Benussi, Filippo Volpin, Frederic A. Dreyer, Aleksandar Shtedritski, and Yuki M. Asano. 2021. Bias out-of-the-box: an empirical analysis of intersectional occupational biases in popular generative language models. In Proceedings of the 35th International Conference on Neural Information Processing Systems ...
2021
-
[27]
Arjun M. Kumar, Jasmine Y. Q. Goh, Tiffany H. H. Tan, and Cynthia S. Q. Siew. 2022. Gender Stereotypes in Hollywood Movies and Their Evolution over Time: Insights from Network Analysis.Big Data and Cognitive Computing6, 2 (June 2022), 50. doi:10.3390/bdcc6020050 Publisher: Multidisciplinary Digital Publishing Institute
-
[28]
Anja Lambrecht and Catherine Tucker. 2019. Algorithmic bias? An empirical study of apparent gender-based discrimination in the display of STEM career ads.Management science65, 7 (2019), 2966–2981
2019
-
[29]
David Laniado, Yana Volkovich, Karolin Kappler, and Andreas Kaltenbrunner. 2016. Gender homophily in online dyadic and triadic relationships.EPJ Data Science5, 1 (May 2016), 19. doi:10.1140/epjds/s13688-016-0080-6 Do Language Models Pass the Bechdel Test? FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[30]
Peter A. Leavitt, Rebecca Covarrubias, Yvonne A. Perez, and Stephanie A. Fryberg. 2015. “Frozen in Time”: The Impact of Native American Media Representations on Identity and Self-Understanding.Journal of Social Issues71, 1 (2015), 39–53. doi:10.1111/josi.12095 _eprint: https://spssi.onlinelibrary.wiley.com/doi/pdf/10.1111/josi.12095
-
[31]
Benjamin Lee. 2024. Lionsgate partners with AI firm to train generative model on film and TV library.The Guardian(Sept. 2024). https://www.theguardian.com/film/2024/sep/18/lionsgate-ai
2024
-
[32]
Eric Justin Liu, Wonyoung So, Peko Hosoi, and Catherine D’Ignazio. 2024. Racial Steering by Large Language Models: A Prospective Audit of GPT-4 on Housing Recommendations. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO ’24). Association for Computing Machinery, New York, NY, USA, 1–13. doi:1...
-
[33]
Li Lucy and David Bamman. 2021. Gender and Representation Bias in GPT-3 Generated Stories. InProceedings of the Third Workshop on Narrative Understanding, Nader Akoury, Faeze Brahman, Snigdha Chaturvedi, Elizabeth Clark, Mohit Iyyer, and Lara J. Martin (Eds.). Association for Computational Linguistics, Virtual, 48–55. doi:10.18653/v1/2021.nuse-1.5
-
[34]
Jinna Lv, Bin Wu, Lili Zhou, and Han Wang. 2018. StoryRoleNet: Social Network Construction of Role Relationship in Video.IEEE Access6 (2018), 25958–25969. doi:10.1109/ACCESS.2018.2832087
-
[35]
Crawford, Sanjana Gautam, Sorelle A
Yaaseen Mahomed, Charlie M. Crawford, Sanjana Gautam, Sorelle A. Friedler, and Danaë Metaxa. 2024. Auditing GPT’s Content Moderation Guardrails: Can ChatGPT Write Your Favorite TV Show?. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). Association for Computing Machinery, New York, NY, USA, 660–686. doi:1...
-
[36]
Janice McCabe, Emily Fairchild, Liz Grauerholz, Bernice A. Pescosolido, and Daniel Tope. 2011. Gender in the Twentieth-Century Children’s Books: Patterns of Disparity in Titles and Central Characters.Gender and Society25, 2 (2011), 197–226. http://www.jstor. org/stable/23044136
arXiv 2011
-
[37]
Miller McPherson, Lynn Smith-Lovin, and James M. Cook. 2001. Birds of a Feather: Homophily in Social Networks.Annual Review of Sociology27 (2001), 415–444. http://www.jstor.org/stable/2678628
arXiv 2001
-
[38]
Danaë Metaxa, Joon Sung Park, James A. Landay, and Jeff Hancock. 2019. Search Media and Elections: A Longitudinal Investigation of Political Search Results.Proc. ACM Hum.-Comput. Interact.3, CSCW (Nov. 2019), 129:1–129:17. doi:10.1145/3359231
-
[39]
Robertson, Karrie Karahalios, Christo Wilson, Jeff Hancock, and Christian Sandvig
Danaë Metaxa, Joon Sung Park, Ronald E. Robertson, Karrie Karahalios, Christo Wilson, Jeff Hancock, and Christian Sandvig. 2021. Auditing Algorithms: Understanding Algorithmic Systems from the Outside In.Foundations and Trends®in Human–Computer Interaction 14, 4 (2021), 272–344. doi:10.1561/1100000083
-
[40]
M. E. J. Newman. 2003. Mixing patterns in networks.Physical Review E67, 2 (Feb. 2003), 026126. doi:10.1103/PhysRevE.67.026126
-
[41]
Marios Papachristou and Yuan Yuan. 2025. Network formation and dynamics among multi-LLMs.PNAS Nexus4, 12 (Dec. 2025), pgaf317. doi:10.1093/pnasnexus/pgaf317
-
[42]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–22. doi:10.1145/35861...
-
[43]
Seung-Bo Park, Yoo-Won Kim, Mohammed Nazim Uddin, and Geun-Sik Jo. 2009. Character-Net: Character Network Analysis from Video. In2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Vol. 1. 305–308. doi:10.1109/WI-IAT.2009.54
-
[44]
Seung-Bo Park, Kyeong-Jin Oh, and Geun-Sik Jo. 2012. Social network analysis in a movie using character-net.Multimedia Tools Appl. 59, 2 (2012), 601–627. doi:10.1007/s11042-011-0725-1
-
[45]
Crawford, Danaé Metaxa, and Sorelle A
Grace Proebsting, Oghenefejiro Isaacs Anigboro, Charlie M. Crawford, Danaé Metaxa, and Sorelle A. Friedler. 2025. Identity-related Speech Suppression in Generative AI Content Moderation. InProceedings of the 5th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO ’25). Association for Computing Machinery, New York, NY, U...
-
[46]
Robertson, Shan Jiang, Kenneth Joseph, Lisa Friedland, David Lazer, and Christo Wilson
Ronald E. Robertson, Shan Jiang, Kenneth Joseph, Lisa Friedland, David Lazer, and Christo Wilson. 2018. Auditing Partisan Audience Bias within Google Search.Proceedings of the ACM on Human-Computer Interaction2, CSCW (Nov. 2018), 1–22. doi:10.1145/3274417
-
[47]
Muniba Saleem and Srividya Ramasubramanian. 2019. Muslim Americans’ Responses to Social Identity Threats: Effects of Media Representations and Experiences of Discrimination.Media Psychology22, 3 (2019), 373–393. doi:10.1080/15213269.2017.1302345 _eprint: https://doi.org/10.1080/15213269.2017.1302345
-
[48]
Maarten Sap, Marcella Cindy Prasettio, Ari Holtzman, Hannah Rashkin, and Yejin Choi. 2017. Connotation Frames of Power and Agency in Modern Films. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Martha Palmer, Rebecca Hwa, and Sebastian Riedel (Eds.). Association for Computational Linguistics, Copenhagen, Denmark,...
-
[49]
Akrati Saxena, George Fletcher, and Mykola Pechenizkiy. 2024. FairSNA: Algorithmic Fairness in Social Network Analysis.Comput. Surveys(April 2024). doi:10.1145/3653711 Publisher: ACMPUB27New York, NY
-
[50]
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. The Woman Worked as a Babysitter: On Biases in Language Generation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguist...
-
[51]
Zara Siddique, Liam Turner, and Luis Espinosa-Anke. 2024. Who is better at math, Jenny or Jingzhen? Uncovering Stereotypes in Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al- Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, ...
-
[52]
Dr Stacy L Smith, Dr Katherine Pieper, and Sam Wheeler. 2023. Inequality in 1,600 popular films: Examining Portrayals of Gender, Race/Ethnicity, LGBTQ+ & Disability from 2007 to 2022. (Aug. 2023). https://assets.uscannenberg.org/docs/aii-inequality-in-1600- popular-films-20230811.pdf
2023
-
[53]
Jessica Toonkel. 2025. Exclusive | OpenAI Backs AI-Made Animated Feature Film. https://www.wsj.com/tech/ai/openai-backs-ai-made- animated-feature-film-389f70b0
2025
-
[54]
Ownership, Not Just Happy Talk
Emily Tseng, Meg Young, Marianne Aubin Le Quéré, Aimee Rinehart, and Harini Suresh. 2025. "Ownership, Not Just Happy Talk": Co-Designing a Participatory Large Language Model for Journalism. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 3119–3130. ...
-
[55]
Riva Tukachinsky, Dana Mastro, and Moran Yarchi. 2015. Documenting Portrayals of Race/Ethnicity on Primetime Television over a 20-Year Span and Their Association with National-Level Racial/Ethnic Attitudes.Communication Faculty Articles and Research(Jan. 2015). doi:10.1111/josi.12094
-
[56]
Johan Ugander, Brian Karrer, Lars Backstrom, and Cameron A. Marlow. 2011. The Anatomy of the Facebook Social Graph. (2011)
2011
-
[57]
Johann Valentowitsch. 2023. Hollywood caught in two worlds? The impact of the Bechdel test on the international box office performance of cinematic films.Marketing Letters34, 2 (2023), 293–308. doi:10.1007/s11002-022-09652-5
-
[58]
Ian Van Buskirk, Aaron Clauset, and Daniel B Larremore. 2023. An Open-Source Cultural Consensus Approach to Name-Based Gender Classification. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 17. 866–877. https://github.com/ ianvanbuskirk/nbgc
2023
-
[59]
Kelly is a Warm Person, Joseph is a Role Model
Yixin Wan, George Pu, Jiao Sun, Aparna Garimella, Kai-Wei Chang, and Nanyun Peng. 2023. “Kelly is a Warm Person, Joseph is a Role Model”: Gender Biases in LLM-Generated Reference Letters. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Sin...
-
[60]
Angelina Wang, Jamie Morgenstern, and John P. Dickerson. 2025. Large language models that replace human participants can harmfully misportray and flatten identity groups.Nature Machine Intelligence7, 3 (March 2025), 400–411. doi:10.1038/s42256-025-00986-z Publisher: Nature Publishing Group
-
[61]
Stephanie Wang, Shengchun Huang, Alvin Zhou, and Danaë Metaxa. 2024. Lower Quantity, Higher Quality: Auditing News Content and User Perceptions on Twitter/X Algorithmic versus Chronological Timelines.Proc. ACM Hum.-Comput. Interact.8, CSCW2 (Nov. 2024), 507:1–507:25. doi:10.1145/3687046
-
[62]
1994.Social Network Analysis: Methods and Applications
Stanley Wasserman and Katherine Faust. 1994.Social Network Analysis: Methods and Applications. Cambridge University Press
1994
-
[63]
Chung-Yi Weng, Wei-Ta Chu, and Ja-Ling Wu. 2007. RoleNet: treat a movie as a small society. InProceedings of the international workshop on Workshop on multimedia information retrieval (MIR ’07). Association for Computing Machinery, New York, NY, USA, 51–60. doi:10.1145/1290082.1290092
-
[64]
Kyra Wilson and Aylin Caliskan. 2024. Gender, Race, and Intersectional Bias in Resume Screening via Language Model Retrieval. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society7, 1 (Oct. 2024), 1578–1590. doi:10.1609/aies.v7i1.31748
-
[65]
Nan Xu and Xuezhe Ma. 2025. LLM The Genius Paradox: A Linguistic and Math Expert’s Struggle with Simple Word-based Counting Problems. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds...
-
[66]
Yulin Yu, Yucong Hao, and Paramveer Dhillon. 2022. Unpacking Gender Stereotypes in Film Dialogue. InSocial Informatics, Frank Hopfgartner, Kokil Jaidka, Philipp Mayr, Joemon Jose, and Jan Breitsohl (Eds.). Springer International Publishing, Cham, 398–405. doi:10.1007/978-3-031-19097-1_26 A Screenplay generation prompts Two prompts used to generate screenp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.