APEX4: Efficient Pure W4A4 LLM Inference via Intra-SM Compute Rebalancing
Pith reviewed 2026-06-27 17:46 UTC · model grok-4.3
The pith
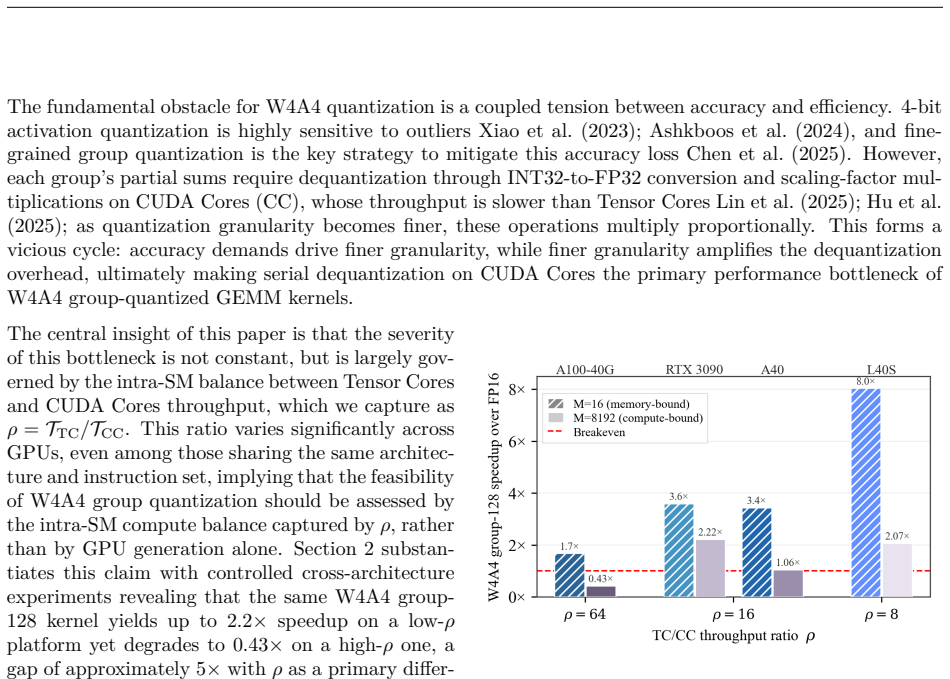
Pure W4A4 inference for LLMs succeeds when the Tensor Core to CUDA Core throughput ratio stays at or below 16, through ρ-aware kernel granularity adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
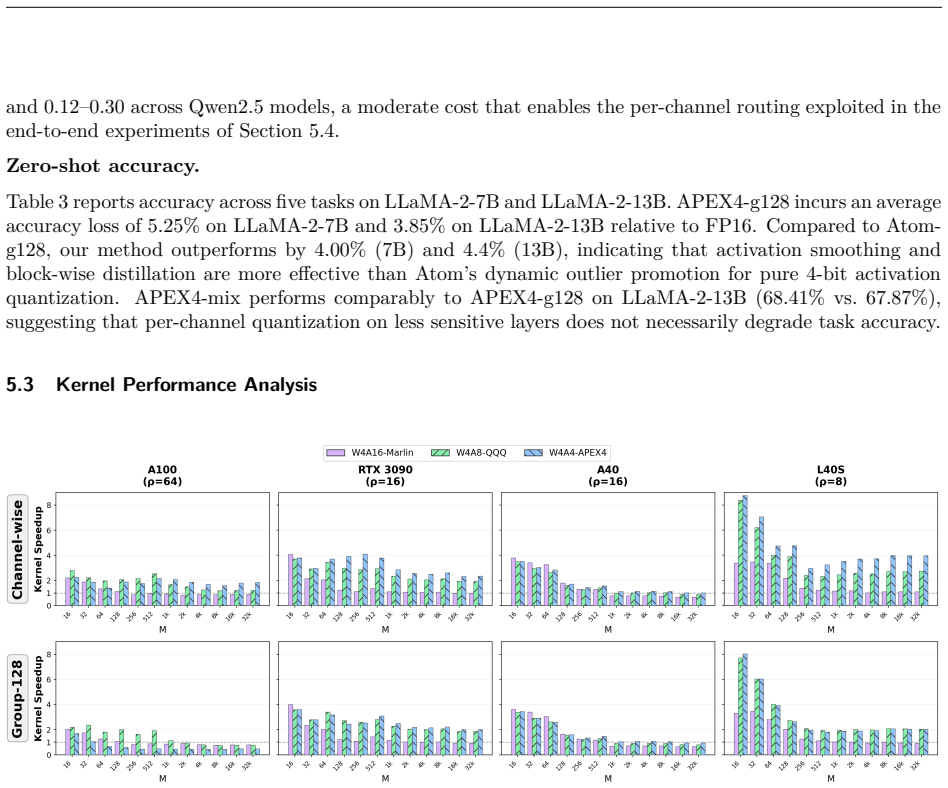
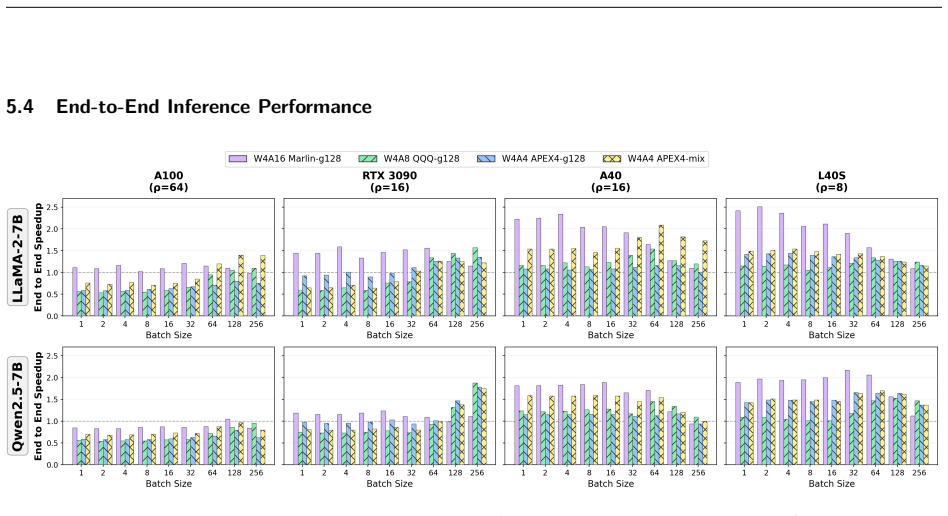
APEX4 co-designs pure INT4 GEMM kernels with ρ-aware granularity adaptation to mitigate the CUDA Cores dequantization bottleneck, achieving perplexity within 0.63 of FP16 on LLaMA-2-70B, 4.0–4.4% higher zero-shot accuracy than W4Ax Atom-g128, and end-to-end speedups of 1.66× on L40S (ρ=8), 1.78× on RTX 3090 (ρ=16), 2.09× on A40 (ρ=16), and 1.20–1.40× on A100 (ρ=64) via mixed-granularity mode.
What carries the argument
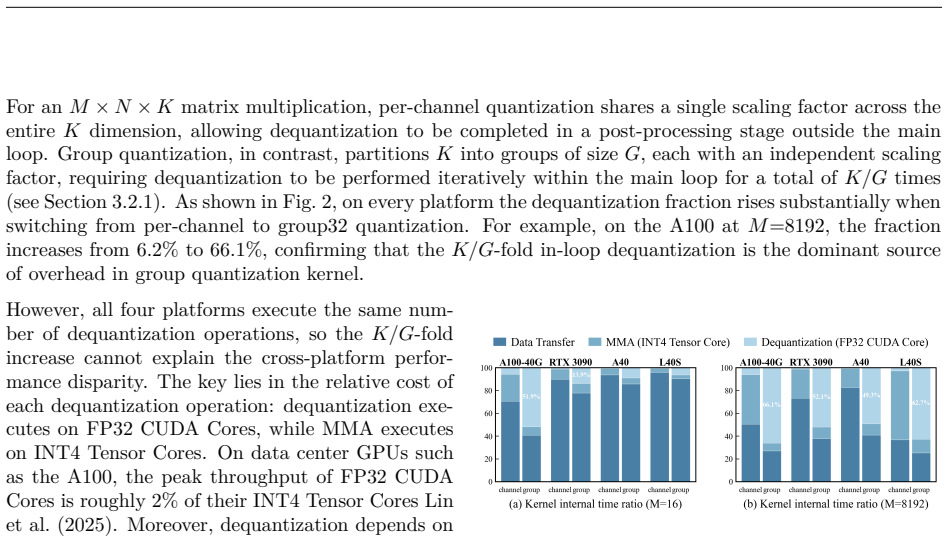
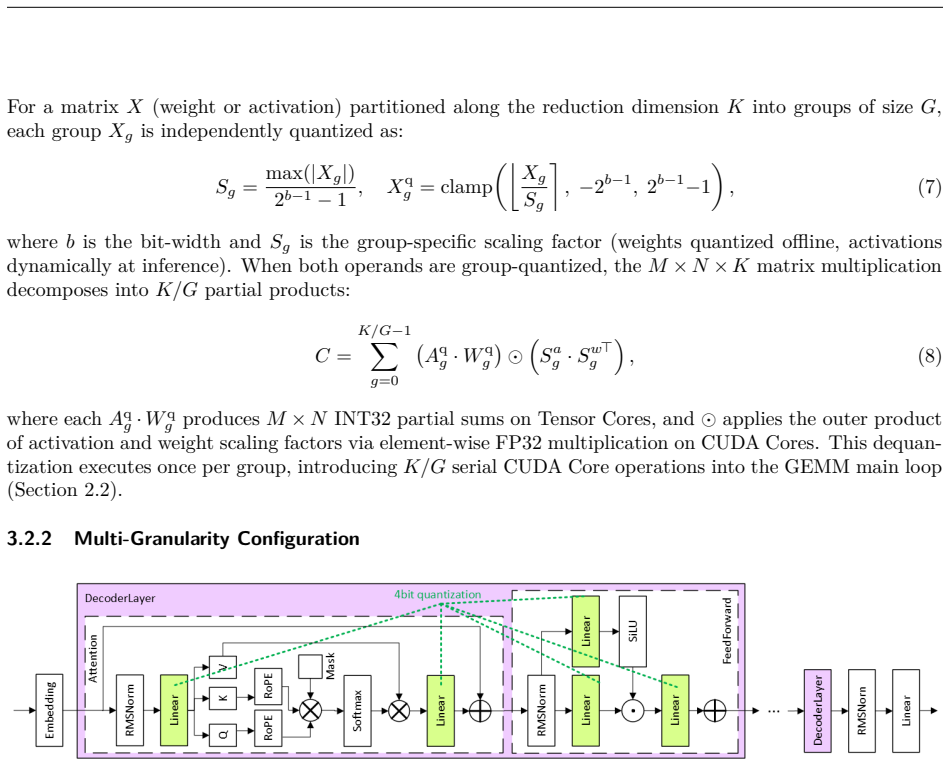
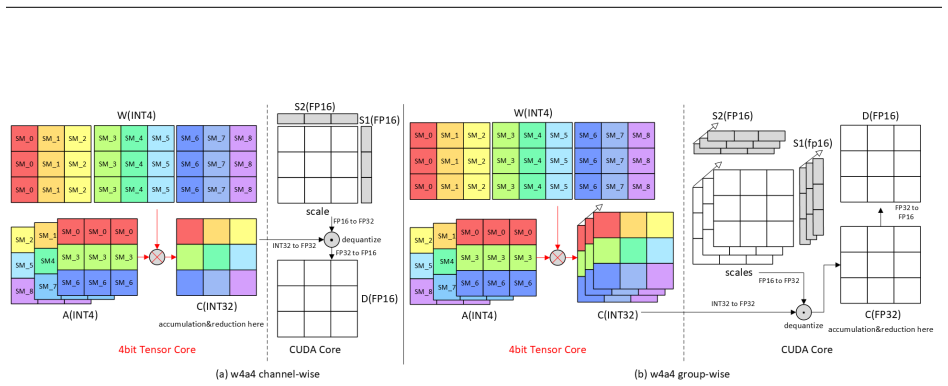
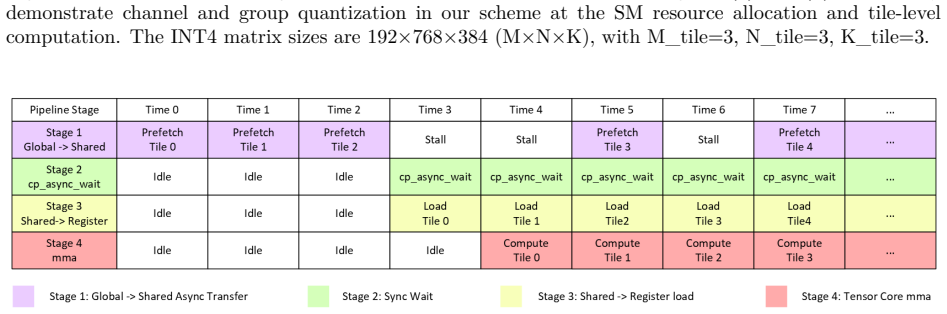
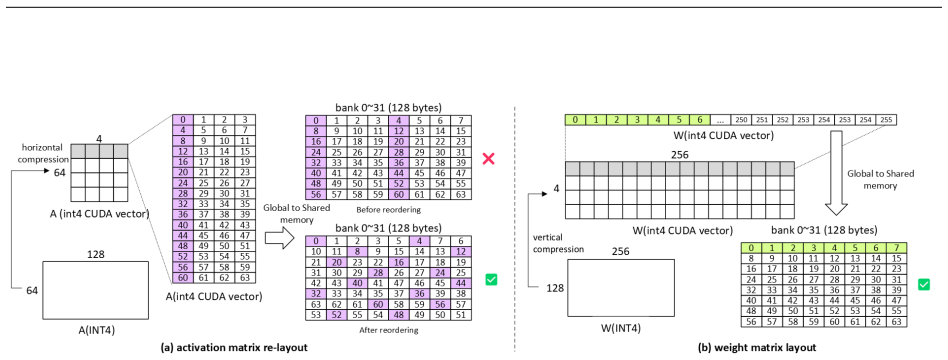
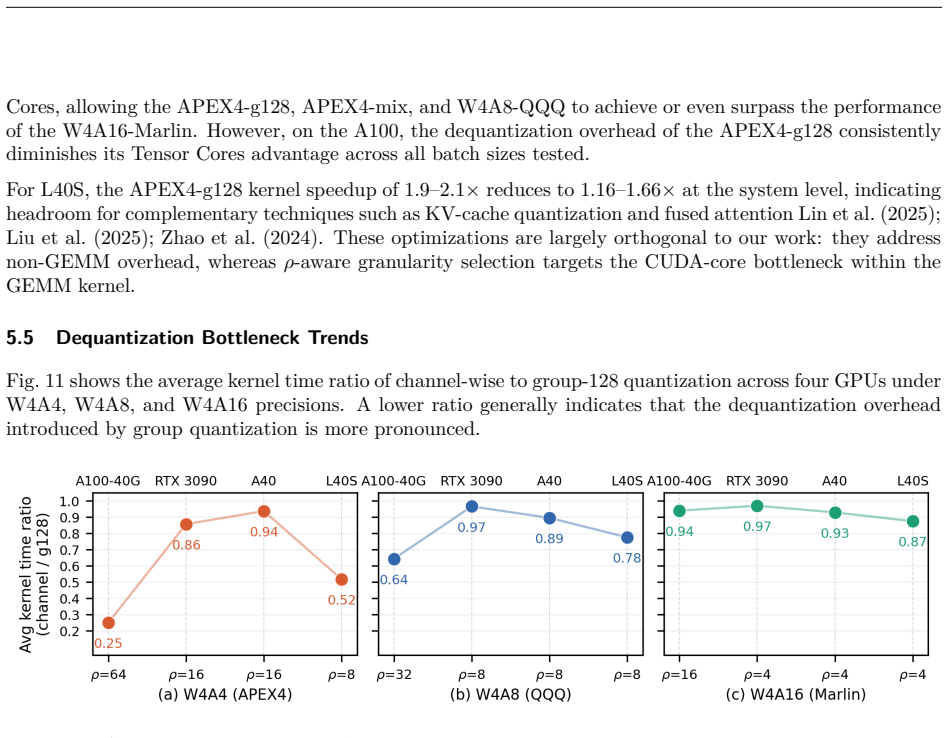
ρ-aware granularity adaptation inside pure INT4 GEMM kernels, which selects group size according to the measured Tensor Core to CUDA Core throughput ratio to keep dequantization from dominating execution time.
If this is right
- On GPUs with ρ≤16, unmodified vLLM can replace its current kernels with APEX4 and obtain 1.78–2.09× end-to-end latency reduction.
- High-ρ platforms such as A100 require the mixed-granularity fallback to retain any speedup over FP16.
- The same ρ-guided adaptation principle can be applied to other low-precision GEMM kernels that mix Tensor Core and CUDA Core work.
- Accuracy results remain within 0.63 perplexity of FP16 when the adapted kernels are used end-to-end on LLaMA-2-70B.
Where Pith is reading between the lines
- GPU vendors could expose ρ as a queryable device property so that runtime systems automatically select the right granularity at load time.
- The same intra-SM balancing technique may apply to future mixed-precision formats that also split work between Tensor Cores and CUDA Cores.
- If newer architectures increase ρ further, pure low-bit inference may need dedicated dequantization hardware rather than software kernels.
Load-bearing premise
The dequantization overhead on CUDA cores is the main limiter of W4A4 performance and is controlled by the single hardware ratio ρ.
What would settle it
Run the W4A4-g128 kernel on a GPU with ρ=16 and measure whether it still underperforms a mixed-precision baseline in a compute-bound matrix multiply.
Figures

read the original abstract
W4A4 quantization promises full utilization of INT4 Tensor Cores, yet group dequantization overhead on CUDA Cores has driven existing systems to mixed-precision fallbacks. We present the first systematic study of how intra-SM compute balance governs this bottleneck. Through controlled benchmarks across four GPUs from Ampere and Ada architectures, we identify the Tensor Cores to CUDA Cores throughput ratio ($\rho$) as the primary hardware indicator: the W4A4-g128 kernel yields $2.0$--$2.5\times$ speedup on RTX~3090 ($\rho=16$) yet degrades to $0.43$--$0.47\times$ on A100 ($\rho=64$) in compute-bond scenarios, establishing W4A4 viability as platform-dependent rather than universally infeasible. Guided by this finding, we build \textbf{APEX4}, which co-designs pure INT4 GEMM kernels with $\rho$-aware granularity adaptation to mitigate the CUDA Cores dequantization bottleneck. APEX4 achieves perplexity within 0.63 of FP16 on LLaMA-2-70B and outperforms W4Ax Atom-g128 by 4.0\%--4.4\% in zero-shot accuracy. Deployed as a drop-in replacement in unmodified vLLM, it delivers up to $1.66\times$ end-to-end speedup on L40S ($\rho=8$), and $1.78\times$ on RTX~3090 ($\rho=16$), $2.09\times$ on A40 ($\rho=16$), while recovering A100 ($\rho=64$) to $1.20$--$1.40\times$ via the mixed-granularity mode. Our code is available at https://github.com/APEX4-W4A4/APEX4-W4A4.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents APEX4, a co-designed system for pure W4A4 LLM inference that uses ρ-aware granularity adaptation (where ρ is the Tensor Cores to CUDA Cores throughput ratio) in INT4 GEMM kernels. It reports a systematic study across four GPUs showing that fixed g128 kernels yield 2.0–2.5× speedup at ρ=16 but only 0.43–0.47× at ρ=64 in compute-bound cases; APEX4 mitigates this via mixed-granularity mode on high-ρ platforms. End-to-end claims include perplexity within 0.63 of FP16 on LLaMA-2-70B, 4.0–4.4% zero-shot accuracy gains over W4Ax Atom-g128, and speedups of 1.66–2.09× on low-ρ GPUs plus 1.20–1.40× recovery on A100 (ρ=64) as a drop-in replacement in unmodified vLLM.
Significance. If the accuracy claims hold under the mixed-granularity configurations required for high-ρ GPUs, the work supplies the first explicit hardware-indicator analysis (ρ) for W4A4 viability and a practical kernel-level solution that avoids mixed-precision fallbacks while delivering measurable end-to-end gains; the controlled multi-GPU benchmarks and vLLM integration are concrete strengths.
major comments (2)
- [Abstract] Abstract: the reported perplexity (within 0.63 of FP16 on LLaMA-2-70B) and zero-shot accuracy gains (4.0–4.4% over W4Ax Atom-g128) are not disaggregated by granularity mode. Because the A100 (ρ=64) recovery explicitly relies on the mixed-granularity mode while the g128 mode is stated to degrade on that platform, it is impossible to verify whether the accuracy numbers apply to the configurations actually used for the 1.20–1.40× claim; this directly affects the platform-dependent viability argument.
- [Abstract] Abstract and § on kernel design: the primary hardware indicator ρ is measured on target GPUs and used to motivate the mixed-granularity adaptation, yet no quantitative breakdown is given of how group-size variation or tile-level dequantization patterns in the mixed mode affect the reported accuracy metrics versus the uniform g128 baseline.
minor comments (2)
- Notation for ρ and the four GPUs (A40, RTX 3090, L40S, A100) should be introduced with explicit throughput ratios in a single table for reproducibility.
- [Abstract] The abstract states "pure INT4 GEMM kernels" but the mixed-granularity mode description implies per-tile or per-layer variation; a brief clarification of what remains strictly INT4 would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and kernel design sections. The comments correctly identify that accuracy metrics are not disaggregated by granularity mode and that the impact of mixed-granularity on accuracy is not quantified. We will revise the manuscript to address both points by adding the requested breakdowns and platform-specific accuracy tables.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported perplexity (within 0.63 of FP16 on LLaMA-2-70B) and zero-shot accuracy gains (4.0–4.4% over W4Ax Atom-g128) are not disaggregated by granularity mode. Because the A100 (ρ=64) recovery explicitly relies on the mixed-granularity mode while the g128 mode is stated to degrade on that platform, it is impossible to verify whether the accuracy numbers apply to the configurations actually used for the 1.20–1.40× claim; this directly affects the platform-dependent viability argument.
Authors: We agree that the abstract presents aggregate accuracy figures without explicit per-mode disaggregation, which obscures whether the reported perplexity and zero-shot gains apply to the mixed-granularity configuration used on A100. The underlying experiments used the ρ-aware mode for high-ρ platforms and g128 for low-ρ platforms; the accuracy bounds hold under those configurations. We will revise the abstract to state the mode used per platform and add a new table in the evaluation section that reports perplexity and zero-shot accuracy separately for uniform g128 and mixed-granularity modes on each GPU. revision: yes
-
Referee: [Abstract] Abstract and § on kernel design: the primary hardware indicator ρ is measured on target GPUs and used to motivate the mixed-granularity adaptation, yet no quantitative breakdown is given of how group-size variation or tile-level dequantization patterns in the mixed mode affect the reported accuracy metrics versus the uniform g128 baseline.
Authors: The manuscript indeed lacks a quantitative comparison of accuracy under group-size variation and tile-level dequantization in mixed mode versus the g128 baseline. This omission weakens the claim that mixed granularity preserves accuracy. We will add a dedicated subsection (or appendix) with controlled experiments on LLaMA-2-7B/13B/70B that measure perplexity and zero-shot accuracy deltas when switching from uniform g128 to the mixed-granularity patterns employed on high-ρ GPUs. If any degradation appears, it will be reported explicitly. revision: yes
Circularity Check
No circularity; empirical results from direct GPU benchmarks and end-to-end measurements
full rationale
The paper's central claims rest on controlled benchmarks across four GPUs to identify ρ as the key hardware indicator and on direct perplexity/accuracy/speedup measurements in unmodified vLLM. No equations reduce predictions to fitted inputs by construction, no self-citations are load-bearing for the viability or performance results, and the design choices are guided by measured platform differences rather than ansatzes or uniqueness theorems imported from prior author work. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- granularity mode (g128 vs mixed)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.