TAVR-VLM: Risk-Conditioned Causal Grounding for Hallucination-Resistant Report Generation
Pith reviewed 2026-06-26 05:04 UTC · model grok-4.3
The pith
Risk-conditioned causal grounding enables hallucination-resistant TAVR report generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
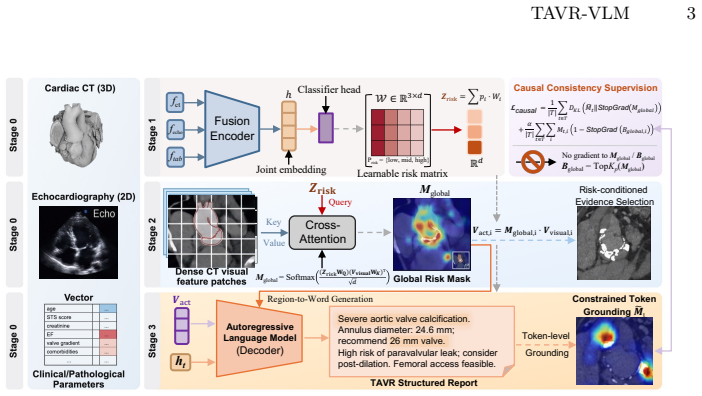
TAVR-VLM instantiates a model-internal Risk to Region to Word structural grounding pathway using Risk-Conditioned Causal Grounding Attention. The mechanism compresses multimodal inputs into a causal risk bottleneck that purifies dense visual features into a global risk mask. During generation, a support-projected causal consistency objective constrains token-level grounding within the risk-defined support mask, leading to reduced diagnostic hallucinations on the M3TAVR cohort.
What carries the argument
Risk-Conditioned Causal Grounding Attention (R-CGA), which compresses multimodal inputs into a causal risk bottleneck and constrains token generation within the risk-defined support mask.
If this is right
- Anatomically grounded reports are produced by linking risk to specific regions and words.
- Token generation is restricted to anatomically supported content.
- Multimodal reasoning for TAVR planning gains improved evidence basis.
- Interpretability of the AI outputs increases for clinical use.
Where Pith is reading between the lines
- This causal structure could generalize to other high-stakes medical report tasks like radiology.
- The risk mask could serve as a visual explanation tool for clinicians reviewing the reports.
- Applying the method to video or 3D imaging data might extend the grounding to dynamic procedures.
- Comparing performance on datasets from different hospitals would test robustness to distribution shifts.
Load-bearing premise
That constraining generation within the risk-defined support mask will eliminate hallucinations without creating new dataset-specific errors or missing important details.
What would settle it
Checking whether generated reports correctly reference anatomical regions visible in the input images on a new set of TAVR cases that previously triggered hallucinations in other models.
Figures
read the original abstract
Transcatheter Aortic Valve Replacement (TAVR) planning requires meticulous multimodal reasoning. However, adapting Multimodal Large Language Models (MLLMs) to this high-stakes domain is severely impeded by diagnostic hallucinations, where generated text lacks anatomical grounding. To address this, TAVR-VLM is introduced: a novel framework featuring Risk-Conditioned Causal Grounding Attention (R-CGA) that instantiates a model-internal ``Risk $\rightarrow$ Region $\rightarrow$ Word'' structural grounding pathway. R-CGA compresses multimodal inputs into a causal risk bottleneck, purifying dense visual features into a global risk mask. During autoregressive generation, a support-projected causal consistency objective constrains token-level grounding within the risk-defined support mask. Evaluated on $\text{M}^3\text{TAVR}$, a comprehensive 1,482-patient cohort, TAVR-VLM establishes a new state-of-the-art. It achieves an AUROC of 0.896, boosts CIDEr to 0.936, and drastically reduces the hallucination rate to 8.1\%, thereby improving interpretability for evidence-based surgical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TAVR-VLM, a multimodal LLM framework for TAVR planning report generation that uses a novel Risk-Conditioned Causal Grounding Attention (R-CGA) mechanism to instantiate a 'Risk → Region → Word' structural pathway. R-CGA compresses multimodal inputs into a causal risk bottleneck to produce a global risk mask and applies a support-projected causal consistency objective to constrain autoregressive token generation within the mask. On the M³TAVR cohort of 1,482 patients, the model is reported to achieve AUROC 0.896, CIDEr 0.936, and an 8.1% hallucination rate, establishing a new state-of-the-art for hallucination-resistant, anatomically grounded reports.
Significance. If substantiated with internal evidence, the work could meaningfully advance reliable multimodal reasoning in high-stakes surgical AI by addressing diagnostic hallucinations through an explicit causal grounding pathway. The risk-bottleneck formulation offers a potentially generalizable direction for improving interpretability in medical MLLMs.
major comments (2)
- [Abstract] Abstract: The central SOTA claim rests on the reported metrics (AUROC 0.896, CIDEr 0.936, hallucination rate 8.1%) yet no baseline values, ablation results, or statistical tests are referenced, preventing assessment of whether R-CGA is responsible for the gains.
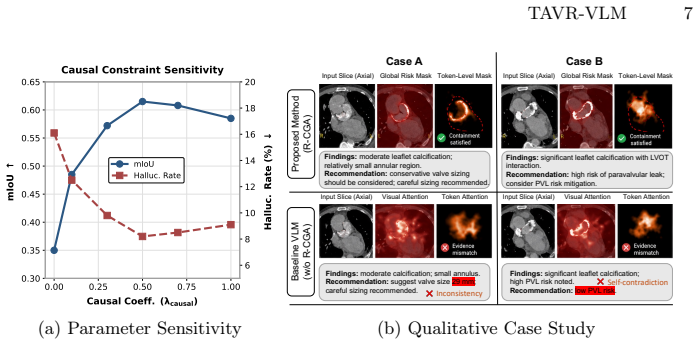
- [R-CGA mechanism] R-CGA description: No ablations, risk-mask visualizations, or failure-case analyses are supplied to show that the causal risk bottleneck and support mask produce anatomically grounded outputs without new artifacts or dataset-specific biases, which is load-bearing for the hallucination-resistance claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects for strengthening the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central SOTA claim rests on the reported metrics (AUROC 0.896, CIDEr 0.936, hallucination rate 8.1%) yet no baseline values, ablation results, or statistical tests are referenced, preventing assessment of whether R-CGA is responsible for the gains.
Authors: The abstract is intentionally concise to summarize the core contribution and primary outcomes. The full manuscript contains detailed baseline comparisons, ablation studies, and statistical significance tests in the Experiments section that attribute performance gains to R-CGA. To improve accessibility of this evidence, we will revise the abstract to include a brief reference to the key improvements over baselines and the supporting analyses. revision: yes
-
Referee: [R-CGA mechanism] R-CGA description: No ablations, risk-mask visualizations, or failure-case analyses are supplied to show that the causal risk bottleneck and support mask produce anatomically grounded outputs without new artifacts or dataset-specific biases, which is load-bearing for the hallucination-resistance claim.
Authors: We agree that direct empirical support for the causal risk bottleneck is important for the hallucination-resistance claim. The manuscript provides a detailed mechanistic description in Section 3. To strengthen validation, we will add component ablations, risk-mask visualizations, and failure-case analyses in the revised manuscript and supplementary material to demonstrate anatomical grounding and address potential artifacts or biases. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a new architectural mechanism (R-CGA) and report standard evaluation metrics (AUROC, CIDEr, hallucination rate) on an external cohort (M^3TAVR). No equations, fitting procedures, or derivation steps are shown that reduce predictions or results to inputs by construction. No self-citations, ansatzes, or uniqueness claims appear in the text. The central claim rests on empirical performance of the described pathway rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal large language models can be adapted to specialized medical domains through targeted grounding mechanisms.
invented entities (1)
-
Risk-Conditioned Causal Grounding Attention (R-CGA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceed- ings of the AAAI Conference on Artificial Intelligence (2021)
Arik, S.Ö., Pfister, T.: Tabnet: Attentive interpretable tabular learning. Proceed- ings of the AAAI Conference on Artificial Intelligence (2021). https://doi.org/10. 1609/aaai.v35i8.16826
2021
-
[2]
Xgboost: A scalable tree boosting system,
Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016). https://doi.org/10.1145/2939672.2939785
-
[3]
In: Proceedings of the 2020 Conference on Empir- ical Methods in Natural Language Processing (EMNLP)
Chen, Z., Song, Y., Chang, T.H., Wan, X.: Generating radiology reports via memory-driven transformer. In: Proceedings of the 2020 Conference on Empir- ical Methods in Natural Language Processing (EMNLP). pp. 1439–1449. Asso- ciation for Computational Linguistics (2020). https://doi.org/10.18653/v1/2020. emnlp-main.112
-
[4]
Token-wise curriculum learning for neural machine translation
Gheini, M., Ren, X., May, J.: Cross-attention is all you need: Adapting pretrained Transformers for machine translation. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 1754–1765. Associa- tion for Computational Linguistics (Nov 2021). https://doi.org/10.18653/v1/2021. emnlp-main.132
-
[5]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., Liu, T.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst.43(2) (Jan 2025). https://doi.org/10.1145/3703155
-
[6]
Johnson, A.E.W., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data (2019). https: //doi.org/10.1038/s41597-019-0322-0
-
[7]
New England Journal of Medicine (2010)
Leon, M.B., Smith, C.R., Mack, M., Miller, D.C., Moses, J.W., Svensson, L.G., et al.: Transcatheter aortic-valve implantation for aortic stenosis in patients who cannot undergo surgery. New England Journal of Medicine (2010). https://doi. org/10.1056/NEJMoa1008232
-
[8]
In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023), https://openreview
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: LLaVA-med: Training a large language-and-vision assistant for biomedicine in one day. In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023), https://openreview. net/forum?id=GSuP99u2kR
2023
-
[9]
Lilly, S.M., Deshmukh, A.J., Epstein, A.E., Ricciardi, M.J., Shreenivas, S., Ve- lagapudi, P., et al.: 2020 ACC expert consensus decision pathway on man- agement of conduction disturbances in patients undergoing transcatheter aor- 10 Z. Lu et al. tic valve replacement. Journal of the American College of Cardiology (2020). https://doi.org/10.1016/j.jacc.20...
-
[10]
In: Workshop on Text Summarization Branches Out (WAS 2004) (2004)
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Workshop on Text Summarization Branches Out (WAS 2004) (2004)
2004
-
[11]
https://doi.org/10.1609/aaai.v40i46
Lu, Z., Li, Y., Tang, F., Jiang, Z., Li, C., Zhou, M., Li, T., Su, J.: Deepgb-tb: A risk-balanced cross-attention gradient-boosted convolutional network for rapid, interpretabletuberculosisscreening.ProceedingsoftheAAAIConferenceonArtifi- cial Intelligence40(46), 38989–38997 (2026). https://doi.org/10.1609/aaai.v40i46. 41245
-
[12]
Gaussian Process Tilted Nonparametric Density Estimation Using
Lu, Z., Su, J.: Hierrisk: A hierarchical framework for suicide risk prediction on social media. In: 2025 IEEE International Conference on Big Data (BigData). pp. 8169–8174 (2025). https://doi.org/10.1109/BigData66926.2025.11402629
-
[13]
Lu, Z., Su, J.: Dialectic-med: Mitigating diagnostic hallucinations via counterfac- tual adversarial multi-agent debate (2026), https://arxiv.org/abs/2604.11258
Pith/arXiv arXiv 2026
-
[14]
Lu, Z., Xu, S., Li, Y., Su, J., Tang, T.: Causal-sam-llm: Large language models as causal reasoners for robust medical segmentation. In: ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 6246–6250 (2026). https://doi.org/10.1109/ICASSP55912.2026.11460869
-
[15]
Lu,Z.,Xu,S.,Yan,K.,Cai,X.,Zhang,C.,Li,Y.,Stefanidis,A.,Nguyen,A.,Su,J.: Skinclip-vl: Consistency-aware vision-language learning for multimodal skin cancer diagnosis (2026), https://arxiv.org/abs/2603.21010
arXiv 2026
-
[16]
New England Journal of Medicine (2019)
Mack, M.J., Leon, M.B., Thourani, V.H., Makkar, R.R., Kodali, S.K., Russo, M., et al.: Transcatheter aortic-valve replacement with a balloon-expandable valve in low-risk patients. New England Journal of Medicine (2019). https://doi.org/10. 1056/NEJMoa1814052
2019
-
[17]
In: 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI)
Sun, Y., Lee, Y.Z., Woodard, G.A., Zhu, H., Lian, C., Liu, M.: R2gen-mamba: A selective state space model for radiology report generation. In: 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI). pp. 1–4 (2025). https: //doi.org/10.1109/ISBI60581.2025.10980814
-
[18]
Journal of the American College of Cardiology (2021)
VARC-3 Writing Committee, Généreux, P., Piazza, N., Alu, M.C., Nazif, T., Hahn, R.T., et al.: Valve academic research consortium 3: Updated endpoint definitions for aortic valve clinical research. Journal of the American College of Cardiology (2021). https://doi.org/10.1016/j.jacc.2021.02.038
-
[19]
Vedantam, R., Zitnick, C.L., Parikh, D.: Cider: Consensus-based image description evaluation.In:2015IEEEConferenceonComputerVisionandPatternRecognition (CVPR). pp. 4566–4575 (2015). https://doi.org/10.1109/CVPR.2015.7299087
-
[20]
Wang, W., et al.: Internvl3.5: Advancing open-source multimodal models in versa- tility, reasoning, and efficiency (2025), https://arxiv.org/abs/2508.18265
Pith/arXiv arXiv 2025
-
[21]
SeqTrack: Sequence to se- quence learning for visual object tracking
Wang, Z., Liu, L., Wang, L., Zhou, L.: Metransformer: Radiology report generation by transformer with multiple learnable expert tokens. In: 2023 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 11558–11567. IEEE Computer Society (2023). https://doi.org/10.1109/CVPR52729.2023.01112
-
[22]
Xue, C., Liu, Y., Zhou, M., Su, J., Lu, Z.: Semantic-topological graph reasoning for language-guided pulmonary screening (2026), https://arxiv.org/abs/2604.05620
Pith/arXiv arXiv 2026
-
[23]
Yang, A., et al.: Qwen3 technical report (2025), https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.