LLMs Struggle to Measure What Distinguishes Students of Different Proficiency Levels: A Study of Item Discrimination in Reading Comprehension Assessment
Pith reviewed 2026-06-26 20:54 UTC · model grok-4.3
The pith
Large language models show only weak alignment with human item discrimination scores in reading comprehension tests, reaching at most 0.24 Spearman correlation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
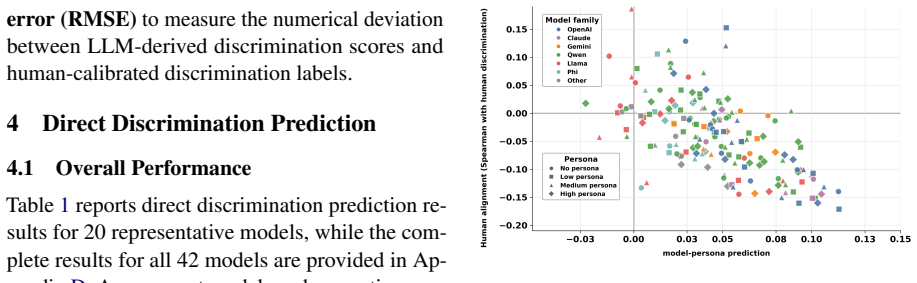
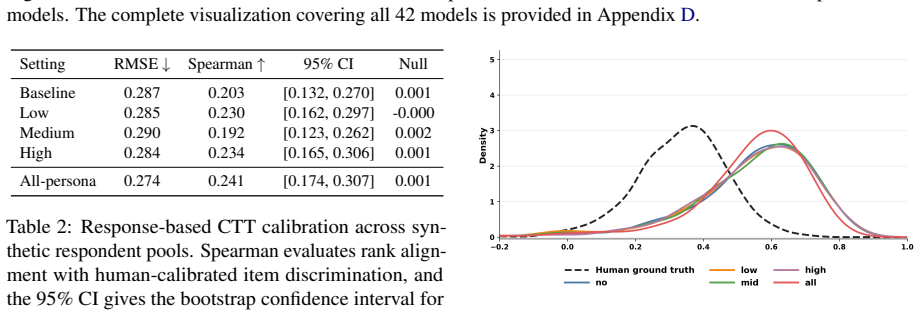
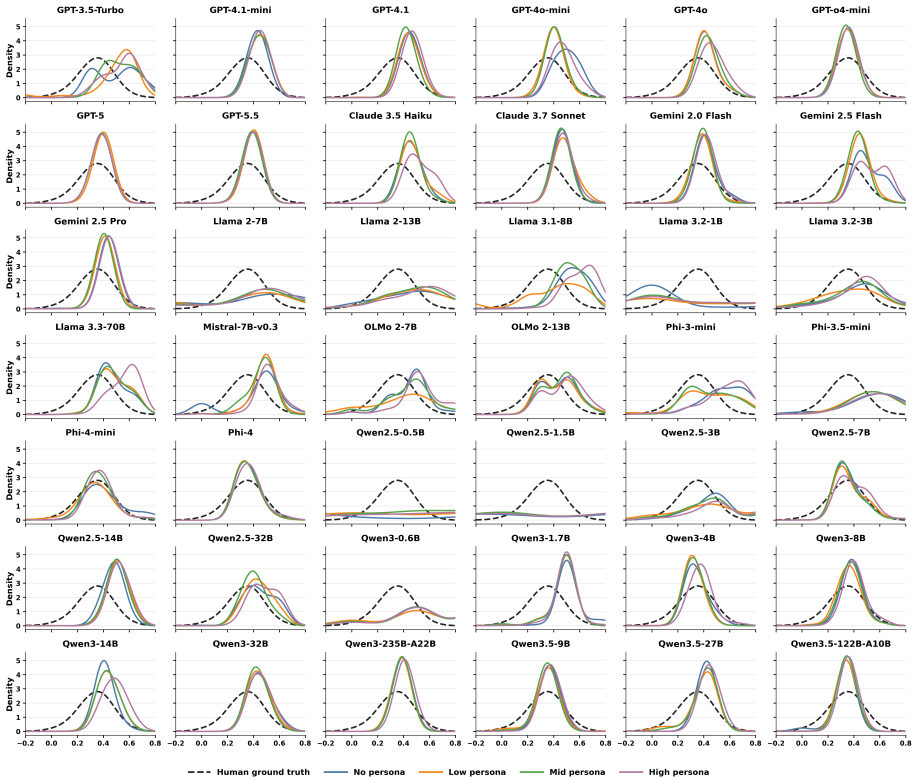
Direct prediction of discrimination values from item content yields at most 0.152 Spearman correlation with human data, while response-based CTT calibration using an all-persona synthetic pool reaches 0.241; these results indicate that current LLMs hold non-random discrimination-relevant signal yet fall short of reliably reproducing how items distinguish human students of differing proficiency.
What carries the argument
Item discrimination computed via Classical Test Theory from either direct LLM estimates or synthetic student response patterns.
If this is right
- LLMs contain measurable but limited discrimination-relevant information in zero-shot settings.
- Response-based calibration using multiple synthetic personas outperforms direct numerical prediction.
- Item discrimination remains harder for LLMs to capture than item difficulty has been in prior work.
- Current models do not yet support fully synthetic psychometric calibration of reading comprehension items.
Where Pith is reading between the lines
- If synthetic discrimination scores improve, test developers could iterate item pools with far fewer live human pilots.
- Persona diversity in prompting may be a practical lever for raising correlation without new model training.
- The gap between 0.241 and usable levels suggests future work on fine-tuning or few-shot calibration rather than zero-shot alone.
Load-bearing premise
LLM-generated answers can stand in for real human student responses when calculating item discrimination scores.
What would settle it
An experiment that collects new human responses on the same reading items and checks whether the resulting human discrimination rankings match those derived from the best LLM synthetic pool at correlation above 0.5.
Figures
read the original abstract
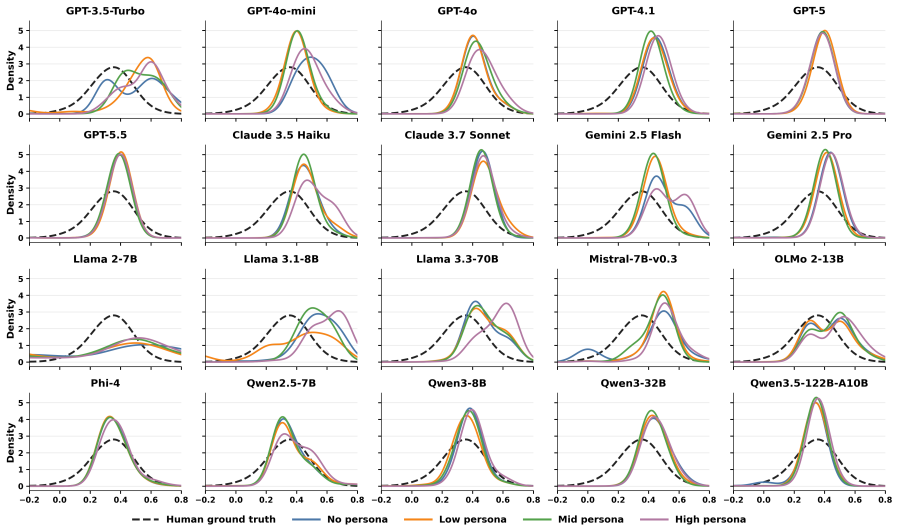
Item discrimination is a fundamental psychometric property of educational assessment, which measures whether an item meaningfully distinguishes students with higher proficiency from students with lower proficiency. While various existing works have explored whether large language models (LLMs) can estimate item difficulty, it remains unclear whether they can capture item discrimination. In this work, we evaluate 42 proprietary and open-weight LLMs in zero-shot settings using two complementary approaches: direct discrimination prediction, where models explicitly estimate an item's discrimination value from its content, and response-based Classical Test Theory (CTT) calibration, where LLM answers are treated as synthetic student responses to compute discrimination scores. Our results show that direct prediction yields weak alignment with human-calibrated discrimination: the best-performing model reaches only a Spearman correlation of 0.152. Response-based CTT calibration provides a stronger but still limited signal, with the all-persona synthetic respondent pool reaching a Spearman correlation of 0.241. These findings highlight item discrimination as an open challenge for LLM-based psychometric evaluation: current LLMs contain non-random discrimination-relevant signal, but they do not yet reliably capture how assessment items distinguish human students.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether 42 LLMs can capture item discrimination in reading comprehension assessments. It reports two zero-shot approaches: direct prediction of discrimination values (max Spearman correlation 0.152 with human benchmarks) and response-based Classical Test Theory calibration treating LLM persona answers as synthetic student responses (max Spearman 0.241 for an all-persona pool). The central claim is that LLMs contain non-random discrimination-relevant signal but do not yet reliably capture how items distinguish human students of different proficiency levels.
Significance. If the empirical results hold after addressing methodological details, the work provides a concrete benchmark across 42 models and two complementary methods, highlighting item discrimination as a distinct open challenge beyond item difficulty estimation. The use of external human benchmarks and standard correlation metrics is a strength that allows direct comparison to psychometric standards.
major comments (2)
- [Methods (response-based CTT calibration)] The response-based CTT approach (abstract and corresponding methods section) interprets the Spearman correlation of 0.241 as evidence of non-random signal from synthetic responses. However, this requires that the persona-induced accuracy patterns vary across items in ways that parallel real human proficiency differences; no validation is reported showing that the synthetic pool produces differentiated error profiles rather than uniform capabilities or training artifacts, which directly affects whether the correlation supports the claim about capturing human discrimination.
- [Abstract and Experiments section] No details are provided on dataset size (number of items or test-takers), item selection criteria, or statistical testing (e.g., p-values or confidence intervals) for the reported Spearman correlations of 0.152 and 0.241. These omissions make it difficult to assess the reliability and generalizability of the central empirical findings.
minor comments (1)
- [Abstract] The abstract would benefit from briefly stating the number of items and the source of the human discrimination benchmarks to allow readers to immediately gauge the scale of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key methodological aspects of our work. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (response-based CTT calibration)] The response-based CTT approach (abstract and corresponding methods section) interprets the Spearman correlation of 0.241 as evidence of non-random signal from synthetic responses. However, this requires that the persona-induced accuracy patterns vary across items in ways that parallel real human proficiency differences; no validation is reported showing that the synthetic pool produces differentiated error profiles rather than uniform capabilities or training artifacts, which directly affects whether the correlation supports the claim about capturing human discrimination.
Authors: We agree that explicit validation of differentiated error profiles in the synthetic responses would strengthen the interpretation. The positive correlation with human benchmarks provides indirect support for non-uniform patterns (uniform capabilities across items would be unlikely to produce a positive alignment with human discrimination values), but we acknowledge the absence of direct validation such as item-wise accuracy variance or profile comparisons. In the revised manuscript, we will add analyses of accuracy variance across items for the all-persona pool and, where feasible, compare synthetic response patterns to human data to address this concern. revision: partial
-
Referee: [Abstract and Experiments section] No details are provided on dataset size (number of items or test-takers), item selection criteria, or statistical testing (e.g., p-values or confidence intervals) for the reported Spearman correlations of 0.152 and 0.241. These omissions make it difficult to assess the reliability and generalizability of the central empirical findings.
Authors: We agree these details are necessary for assessing reliability. The full manuscript describes the dataset and experiments, but we will expand the abstract and experiments section in the revision to explicitly report the number of items and test-takers, item selection criteria, and statistical testing including p-values and confidence intervals for the reported Spearman correlations. revision: yes
Circularity Check
No circularity: direct empirical evaluation against external human benchmarks
full rationale
The paper performs straightforward empirical comparisons of LLM outputs (direct predictions and response-based CTT scores) against independently collected human item discrimination values, using standard Spearman correlations as the metric. No equations, fitted parameters, or results are defined in terms of themselves; the central claims rest on external human data as the ground truth benchmark rather than any internal derivation or self-citation chain. The evaluation is fully falsifiable outside the paper's own fitted values and contains no self-definitional, ansatz-smuggling, or renaming steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Spearman rank correlation appropriately quantifies alignment between model outputs and human-calibrated discrimination values
Forward citations
Cited by 1 Pith paper
-
Cognitive Episodes in LLM Reasoning Traces Enable Interpretable Human Item Difficulty Prediction
Epi2Diff extracts cognitive episode sequences from LRM reasoning traces and combines them with semantic features to predict human item difficulty, outperforming baselines on four educational datasets.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2512.18880 , year=
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction , author=. arXiv preprint arXiv:2512.18880 , year=
-
[2]
2023 , publisher=
The cambridge multiple-choice questions reading dataset , author=. 2023 , publisher=
2023
-
[3]
Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
Findings from the first shared task on automated prediction of difficulty and response time for multiple-choice questions , author=. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
2024
-
[4]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[5]
Introducing APIs for GPT-3.5 Turbo and Whisper , author =
-
[6]
GPT-4o mini: advancing cost-efficient intelligence , author =
-
[7]
Introducing GPT-4.1 in the API , author =
-
[8]
Introducing OpenAI o3 and o4-mini , year =
-
[9]
GPT-5 System Card , author =
-
[10]
2025 , howpublished =
Claude 3.7 Sonnet System Card , author =. 2025 , howpublished =
2025
-
[11]
2024 , howpublished =
Introducing Gemini 2.0: Our New AI Model for the Agentic Era , author =. 2024 , howpublished =
2024
-
[12]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[13]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[14]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[15]
Qwen2.5: A Party of Foundation Models , url =
-
[16]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[17]
2026 , howpublished =
Qwen3.5: Towards Native Multimodal Agents , author =. 2026 , howpublished =
2026
-
[18]
arXiv preprint arXiv:2412.08905 , year=
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
-
[19]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[20]
International conference on artificial intelligence in education , pages=
A quantitative study of NLP approaches to question difficulty estimation , author=. International conference on artificial intelligence in education , pages=. 2023 , organization=
2023
-
[21]
Information Processing & Management , volume=
Automated estimation of item difficulty for multiple-choice tests: An application of word embedding techniques , author=. Information Processing & Management , volume=. 2018 , publisher=
2018
-
[22]
2010 , publisher=
Item response theory , author=. 2010 , publisher=
2010
-
[23]
1991 , publisher=
Fundamentals of item response theory , author=. 1991 , publisher=
1991
-
[24]
Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers , pages=
Textual complexity as a predictor of difficulty of listening items in language proficiency tests , author=. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers , pages=
2016
-
[25]
annual meeting of the National Council on Measurement in Education, Chicago, IL , year=
Automated capturing of psycho-linguistic features in reading assessment text , author=. annual meeting of the National Council on Measurement in Education, Chicago, IL , year=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Question Difficulty Prediction for READING Problems in Standard Tests , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Language testing , volume=
Predicting item difficulty in a reading comprehension test with an artificial neural network , author=. Language testing , volume=. 1995 , publisher=
1995
-
[28]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[29]
2021 ieee 33rd international conference on tools with artificial intelligence (ictai) , pages=
Automatically predict question difficulty for reading comprehension exercises , author=. 2021 ieee 33rd international conference on tools with artificial intelligence (ictai) , pages=. 2021 , organization=
2021
-
[30]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Jump-starting item parameters for adaptive language tests , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[31]
Educational and Psychological Measurement , volume=
Item difficulty modeling using fine-tuned small and large language models , author=. Educational and Psychological Measurement , volume=. 2025 , publisher=
2025
-
[32]
Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
Unibucllm: Harnessing LLMs for automated prediction of item difficulty and response time for multiple-choice questions , author=. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
2024
-
[33]
International Conference on Artificial Intelligence in Education , pages=
Reasoning and sampling-augmented mcq difficulty prediction via llms , author=. International Conference on Artificial Intelligence in Education , pages=. 2025 , organization=
2025
-
[34]
arXiv preprint arXiv:2412.11831 , year=
Are you doubtful? Oh, it might be difficult then! Exploring the use of model uncertainty for question difficulty estimation , author=. arXiv preprint arXiv:2412.11831 , year=
-
[35]
Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
Upn-icc at bea 2024 shared task: Leveraging llms for multiple-choice questions difficulty prediction , author=. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
2024
-
[36]
Expert Systems with Applications , volume=
Student modeling approaches: A literature review for the last decade , author=. Expert Systems with Applications , volume=. 2013 , publisher=
2013
-
[37]
Journal of artificial intelligence in education , volume=
Applications of simulated students: An exploration , author=. Journal of artificial intelligence in education , volume=. 1994 , publisher=
1994
-
[38]
IEEE Transactions on Education , volume=
AutoTutor: An intelligent tutoring system with mixed-initiative dialogue , author=. IEEE Transactions on Education , volume=. 2005 , publisher=
2005
-
[39]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
More diverse dialogue datasets via diversity-informed data collection , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[40]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[41]
International Journal of Artificial Intelligence in Education , volume=
Simulated learners in educational technology: A systematic literature review and a turing-like test , author=. International Journal of Artificial Intelligence in Education , volume=. 2024 , publisher=
2024
-
[42]
User modeling and user-adapted interaction , volume=
Knowledge tracing: Modeling the acquisition of procedural knowledge , author=. User modeling and user-adapted interaction , volume=. 1994 , publisher=
1994
-
[43]
, author=
Probabilistic models for some intelligence and attainment tests. , author=. 1993 , publisher=
1993
-
[44]
2012 , publisher=
Applications of item response theory to practical testing problems , author=. 2012 , publisher=
2012
-
[45]
2025 , publisher=
Item response theory: Foundations for psychologists and social scientists , author=. 2025 , publisher=
2025
-
[46]
Proceedings of the tenth acm conference on learning@ scale , pages=
Gpteach: Interactive ta training with gpt-based students , author=. Proceedings of the tenth acm conference on learning@ scale , pages=
-
[47]
NeurIPS’23 Workshop on Generative AI for Education (GAIED) , year=
Generative agent for teacher training: Designing educational problem-solving simulations with large language model-based agents for pre-service teachers , author=. NeurIPS’23 Workshop on Generative AI for Education (GAIED) , year=
-
[48]
arXiv preprint arXiv:2507.12674 , year=
ParaStudent: Generating and Evaluating Realistic Student Code by Teaching LLMs to Struggle , author=. arXiv preprint arXiv:2507.12674 , year=
-
[49]
arXiv preprint arXiv:2510.05056 , year=
Modeling student learning with 3.8 million program traces , author=. arXiv preprint arXiv:2510.05056 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks? , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2205.14334 , year=
Teaching models to express their uncertainty in words , author=. arXiv preprint arXiv:2205.14334 , year=
-
[52]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[53]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[54]
arXiv preprint arXiv:2504.06514 , year=
Missing premise exacerbates overthinking: Are reasoning models losing critical thinking skill? , author=. arXiv preprint arXiv:2504.06514 , year=
-
[55]
British Journal of Educational Technology , volume=
Leveraging LLM respondents for item evaluation: A psychometric analysis , author=. British Journal of Educational Technology , volume=. 2025 , publisher=
2025
-
[56]
Fourth Workshop on Knowledge-infused Learning , year=
Can LLMs solve reading comprehension tests as second language learners? , author=. Fourth Workshop on Knowledge-infused Learning , year=
-
[57]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Large language models are students at various levels: Zero-shot question difficulty estimation , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[58]
Can LLM s Reliably Simulate Real Students' Abilities in Mathematics and Reading Comprehension?
Srivatsa, KV Aditya and Maurya, Kaushal and Kochmar, Ekaterina. Can LLM s Reliably Simulate Real Students' Abilities in Mathematics and Reading Comprehension?. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.75
-
[59]
Do LLM s Give Psychometrically Plausible Responses in Educational Assessments?
S. Do LLM s Give Psychometrically Plausible Responses in Educational Assessments?. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.21
-
[60]
Leveraging Fine-tuned Large Language Models in Item Parameter Prediction
Han, Suhwa and Rijmen, Frank and Boykin, Allison Ames and Lottridge, Susan. Leveraging Fine-tuned Large Language Models in Item Parameter Prediction. Proceedings of the Artificial Intelligence in Measurement and Education Conference (AIME-Con): Full Papers. 2025
2025
-
[61]
QG - SMS : Enhancing Test Item Analysis via Student Modeling and Simulation
Nguyen, Bang and Du, Tingting and Yu, Mengxia and Angrave, Lawrence and Jiang, Meng. QG - SMS : Enhancing Test Item Analysis via Student Modeling and Simulation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1268
-
[62]
Advancing human assessment: The methodological, psychological and policy contributions of ETS , pages=
A review of developments and applications in item analysis , author=. Advancing human assessment: The methodological, psychological and policy contributions of ETS , pages=. 2017 , publisher=
2017
-
[63]
, author=
Introduction to classical and modern test theory. , author=. 1986 , publisher=
1986
-
[64]
2013 , publisher=
Developing and validating test items , author=. 2013 , publisher=
2013
-
[65]
, author=
The standards for educational and psychological testing. , author=. 2013 , publisher=
2013
-
[66]
2008 , publisher=
Statistical theories of mental test scores , author=. 2008 , publisher=
2008
-
[67]
, author=
Essentials of educational measurement. , author=. 1972 , publisher=
1972
-
[68]
, author=
Item Analysis for Criterion-Referenced Tests. , author=. Online Submission , year=
-
[69]
International Journal of Artificial Intelligence in Education , volume=
Text-based question difficulty prediction: A systematic review of automatic approaches , author=. International Journal of Artificial Intelligence in Education , volume=. 2024 , publisher=
2024
-
[70]
Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
Large language model-based pipeline for item difficulty and response time estimation for educational assessments , author=. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , pages=
2024
-
[71]
arXiv preprint arXiv:2306.13047 , year=
Analysis of the cambridge multiple-choice questions reading dataset with a focus on candidate response distribution , author=. arXiv preprint arXiv:2306.13047 , year=
-
[72]
arXiv preprint arXiv:2506.09796 , year=
Do LLMs Give Psychometrically Plausible Responses in Educational Assessments? , author=. arXiv preprint arXiv:2506.09796 , year=
-
[73]
Educational and Psychological Measurement , volume=
Field-testing multiple-choice questions with AI examinees: English grammar items , author=. Educational and Psychological Measurement , volume=. 2025 , publisher=
2025
-
[74]
arXiv preprint arXiv:2410.12294 , year=
Llm-based cognitive models of students with misconceptions , author=. arXiv preprint arXiv:2410.12294 , year=
-
[75]
arXiv preprint arXiv:2510.11502 , year=
Learning to make mistakes: Modeling incorrect student thinking and key errors , author=. arXiv preprint arXiv:2510.11502 , year=
-
[76]
Model Card Addendum: Claude 3.5 Haiku and Upgraded Claude 3.5 Sonnet , year =
-
[77]
Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models , year =
-
[78]
Meta Llama 3.3 70B Instruct Model Card , year =
-
[79]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[80]
arXiv preprint arXiv:2501.00656 , year=
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.