MGUP: A Momentum-Gradient Alignment Update Policy for Stochastic Optimization
Pith reviewed 2026-06-27 01:28 UTC · model grok-4.3
The pith
MGUP augments momentum-based optimizers by applying larger step sizes to a fixed proportion of parameters each iteration while using smaller non-zero steps elsewhere.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
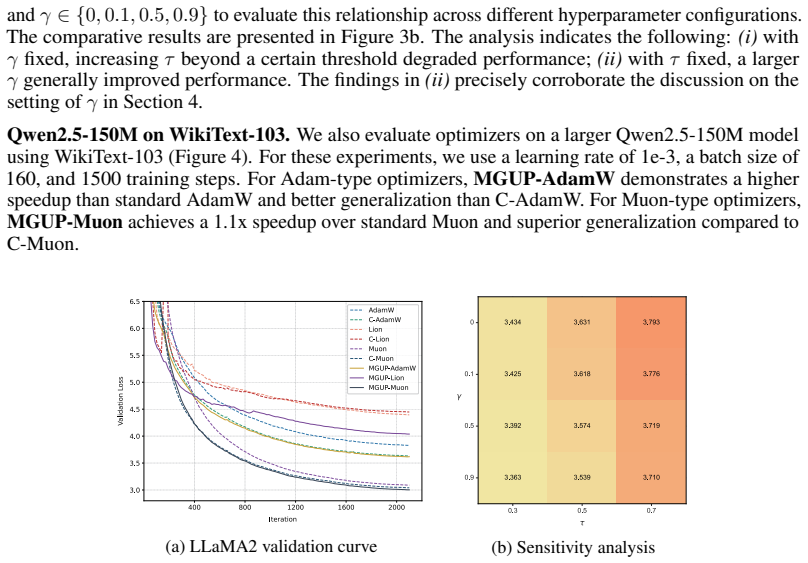
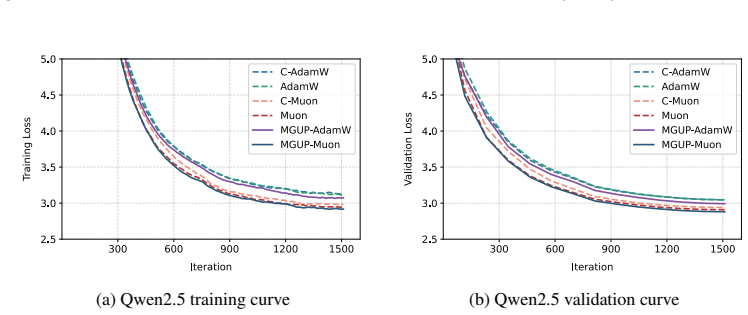
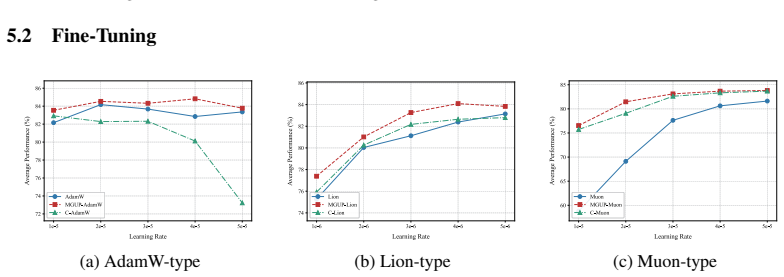
MGUP augments standard momentum-based optimizers by applying larger step-sizes to a selected fixed proportion of parameters in each iteration, while applying smaller, non-zero step-sizes to the rest. As a nearly plug-and-play module, MGUP seamlessly integrates with optimizers such as AdamW, Lion, and Muon. This yields powerful variants such as MGUP-AdamW, MGUP-Lion, and MGUP-Muon. Under standard assumptions, we provide theoretical convergence guarantees for MGUP-AdamW (without weight decay) in stochastic optimization. Extensive experiments across diverse tasks, including MAE pretraining, LLM pretraining, and downstream fine-tuning, demonstrate that our MGUP-enhanced optimizers achieve superi
What carries the argument
MGUP, the Momentum-Gradient Alignment Update Policy, which selects a fixed proportion of parameters for larger step sizes based on momentum-gradient alignment and applies smaller non-zero steps to the remainder.
Load-bearing premise
The selective application of larger step-sizes to a fixed proportion of parameters each iteration preserves convergence under the standard assumptions invoked for stochastic optimization theory.
What would settle it
A controlled training run on a standard benchmark in which MGUP-AdamW either diverges or yields clearly worse final performance than plain AdamW when the described selection and step-size rules are followed exactly.
Figures

read the original abstract
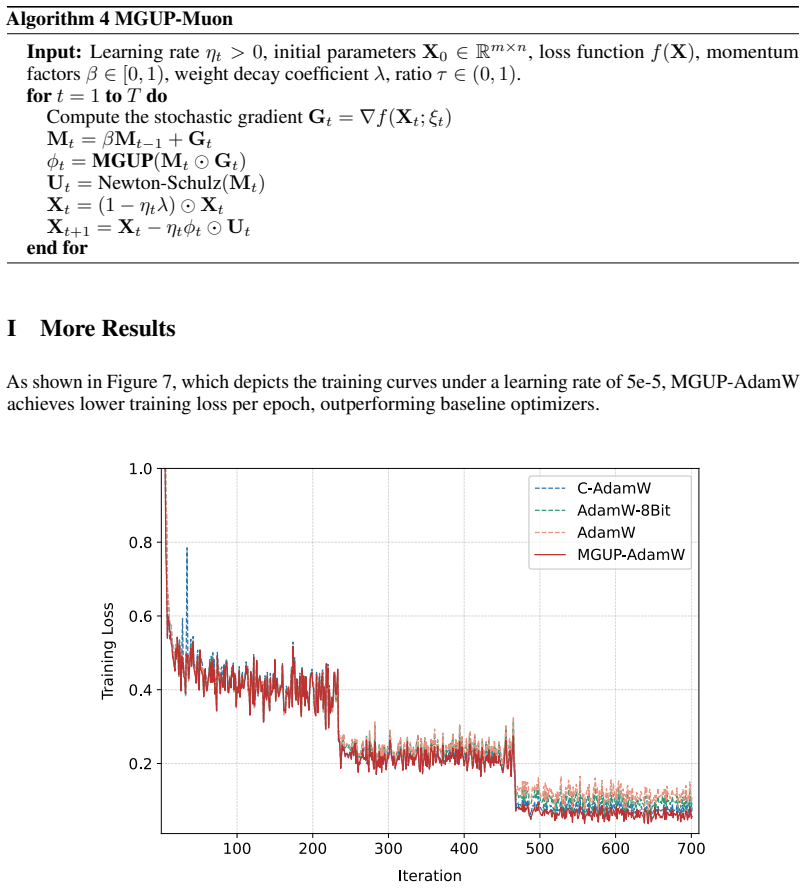
Efficient optimization is essential for training large language models. Although intra-layer selective updates have been explored, a general mechanism that enables fine-grained control while ensuring convergence guarantees is still lacking. To bridge this gap, we propose \textbf{MGUP}, a novel mechanism for selective updates. \textbf{MGUP} augments standard momentum-based optimizers by applying larger step-sizes to a selected fixed proportion of parameters in each iteration, while applying smaller, non-zero step-sizes to the rest. As a nearly {plug-and-play} module, \textbf{MGUP} seamlessly integrates with optimizers such as AdamW, Lion, and Muon. This yields powerful variants such as \textbf{MGUP-AdamW}, \textbf{MGUP-Lion}, and \textbf{MGUP-Muon}. Under standard assumptions, we provide theoretical convergence guarantees for \textbf{MGUP-AdamW} (without weight decay) in stochastic optimization. Extensive experiments across diverse tasks, including MAE pretraining, LLM pretraining, and downstream fine-tuning, demonstrate that our \textbf{MGUP}-enhanced optimizers achieve superior or more stable performance compared to their original base optimizers. We offer a principled, versatile, and theoretically grounded strategy for efficient intra-layer selective updates, accelerating and stabilizing the training of large-scale models. The code is publicly available at https://github.com/MaeChd/MGUP.
Editorial analysis
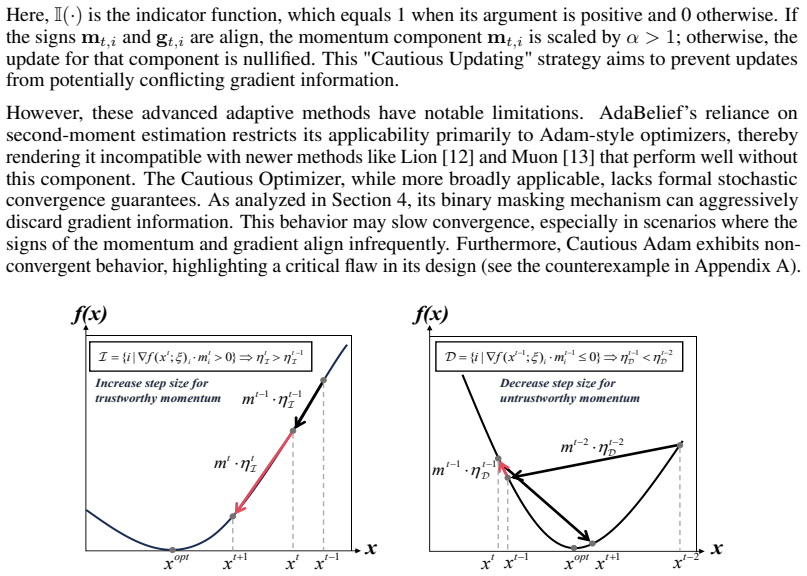
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MGUP, a mechanism that augments momentum-based optimizers (AdamW, Lion, Muon) by applying larger step-sizes to a fixed proportion of parameters each iteration and smaller non-zero step-sizes to the remainder. It claims convergence guarantees for MGUP-AdamW (no weight decay) under standard stochastic optimization assumptions and reports superior or more stable empirical performance on MAE pretraining, LLM pretraining, and downstream fine-tuning.
Significance. If the convergence analysis holds and the empirical gains are robust and reproducible, the method would supply a simple, nearly plug-and-play route to intra-layer selective updates with theoretical support, potentially aiding efficient training of large models.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical section: the convergence guarantee for MGUP-AdamW is asserted under 'standard assumptions,' yet the manuscript provides no derivation details, equation references, or explicit statement of how the fixed-proportion selection (a free parameter) interacts with those assumptions; without this, the central theoretical claim cannot be evaluated.
- [Theoretical Analysis] The weakest assumption—that selective larger step-sizes on a fixed proportion of parameters each iteration preserves the standard convergence conditions—is load-bearing but not shown to hold; the selection criterion (momentum-gradient alignment) must be shown not to introduce bias that violates the invoked assumptions.
minor comments (1)
- The public code release is a positive for reproducibility and should be highlighted.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the theoretical section accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical section: the convergence guarantee for MGUP-AdamW is asserted under 'standard assumptions,' yet the manuscript provides no derivation details, equation references, or explicit statement of how the fixed-proportion selection (a free parameter) interacts with those assumptions; without this, the central theoretical claim cannot be evaluated.
Authors: We agree that the current presentation of the convergence result would benefit from additional detail. The manuscript states the guarantee under standard assumptions but does not include the derivation steps or explicit interaction with the fixed-proportion parameter. In the revision we will expand the theoretical section (and add an appendix if needed) with the key proof outline, equation references to the standard assumptions (L-smoothness, bounded variance), and a clear statement of how the fixed-proportion selection enters the analysis. revision: yes
-
Referee: [Theoretical Analysis] The weakest assumption—that selective larger step-sizes on a fixed proportion of parameters each iteration preserves the standard convergence conditions—is load-bearing but not shown to hold; the selection criterion (momentum-gradient alignment) must be shown not to introduce bias that violates the invoked assumptions.
Authors: We acknowledge that an explicit argument is required to confirm the selection does not introduce bias. The alignment-based selection operates on the current momentum and gradient pair with a fixed proportion, and because the proportion is deterministic and the expectation is taken over the stochastic gradient noise, the selected subset preserves the unbiasedness property of the original optimizer. In the revision we will add a short lemma or remark formalizing this preservation under the invoked assumptions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe MGUP as an augmentation to existing momentum-based optimizers (AdamW, Lion, Muon) via selective step-size application to a fixed proportion of parameters, with convergence guarantees claimed for MGUP-AdamW (no weight decay) under unspecified standard assumptions. No equations, derivations, self-citations, or fitted parameters are visible that reduce any prediction or uniqueness claim to the inputs by construction. The selective-update mechanism is presented as a general plug-and-play addition whose convergence is asserted to hold under the same assumptions used for the base optimizers, without evidence of self-definitional loops, ansatz smuggling, or renaming of known results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed proportion of parameters receiving larger steps
axioms (1)
- domain assumption standard assumptions for convergence in stochastic optimization
Reference graph
Works this paper leans on
-
[1]
Gradient descent happens in a tiny subspace
Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018
Pith/arXiv arXiv 2018
-
[2]
Larsen, Stanislav Fort, Nic Becker, and Surya Ganguli
Brett W. Larsen, Stanislav Fort, Nic Becker, and Surya Ganguli. How many degrees of freedom do we need to train deep networks: a loss landscape perspective. In International Conference on Learning Representations (ICLR), 2022
2022
-
[3]
Galore: Memory-efficient LLM training by gradient low-rank projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory-efficient LLM training by gradient low-rank projection. In International Conference on Machine Learning (ICML), 2024
2024
-
[4]
Ldadam: Adaptive optimization from low-dimensional gradient statistics
Thomas Robert, Mher Safaryan, Ionut-Vlad Modoranu, and Dan Alistarh. Ldadam: Adaptive optimization from low-dimensional gradient statistics. In International Conference on Learning Representations (ICLR), 2025
2025
-
[5]
Sparse is enough in fine-tuning pre-trained large language models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, and Bo Du. Sparse is enough in fine-tuning pre-trained large language models. In International Conference on Machine Learning (ICML), 2024
2024
-
[6]
Autofreeze: Automatically freezing model blocks to accelerate fine-tuning
Yuhan Liu, Saurabh Agarwal, and Shivaram Venkataraman. Autofreeze: Automatically freezing model blocks to accelerate fine-tuning. ArXiv, abs/2102.01386, 2021
arXiv 2021
-
[7]
Full parameter fine-tuning for large language models with limited resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, and Xipeng Qiu. Full parameter fine-tuning for large language models with limited resources. In Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[8]
LISA: layerwise importance sampling for memory-efficient large language model fine-tuning
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. LISA: layerwise importance sampling for memory-efficient large language model fine-tuning. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[9]
Badam: A memory efficient full parameter optimization method for large language models
Qijun Luo, Hengxu Yu, and Xiao Li. Badam: A memory efficient full parameter optimization method for large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
Cautious optimizers: Improving training with one line of code
Kaizhao Liang, Lizhang Chen, Bo Liu, and Qiang Liu. Cautious optimizers: Improving training with one line of code. ArXiv, abs/2411.16085, 2024
arXiv 2024
-
[11]
Adabelief optimizer: Adapting stepsizes by the belief in observed gradients
Juntang Zhuang, Tommy Tang, Yifan Ding, Sekhar C Tatikonda, Nicha Dvornek, Xenophon Papademetris, and James Duncan. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Advances in Neural Information Processing Systems (NeurIPS), 33:18795– 18806, 2020
2020
-
[12]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V . Le. Symbolic discovery of optimization algorithms. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024
2024
-
[14]
On the importance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. InInternational Conference on Machine Learning (ICML), ICML’13. JMLR.org, 2013
2013
-
[15]
Wolfe, Zhaoqi Li, and Anastasios Kyrillidis
John Chen, Cameron R. Wolfe, Zhaoqi Li, and Anastasios Kyrillidis. Demon: Improved neural network training with momentum decay. ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3958–3962, 2019. 10
2022
-
[16]
Towards understanding how momentum improves generalization in deep learning
Samy Jelassi and Yuanzhi Li. Towards understanding how momentum improves generalization in deep learning. In International Conference on Machine Learning (ICML), 2022
2022
-
[17]
When and why momentum accelerates sgd: An empirical study
Jingwen Fu, Bohan Wang, Huishuai Zhang, Zhizheng Zhang, Wei Chen, and Na Zheng. When and why momentum accelerates sgd: An empirical study. ArXiv, abs/2306.09000, 2023
arXiv 2023
-
[18]
SPIDER: near-optimal non- convex optimization via stochastic path-integrated differential estimator
Cong Fang, Chris Junchi Li, Zhouchen Lin, and Tong Zhang. SPIDER: near-optimal non- convex optimization via stochastic path-integrated differential estimator. In Advances in Neural Information Processing Systems (NeurIPS), pages 687–697, 2018
2018
-
[19]
Momentum-based variance reduction in non-convex SGD
Ashok Cutkosky and Francesco Orabona. Momentum-based variance reduction in non-convex SGD. In Advances in Neural Information Processing Systems (NeurIPS), pages 15210–15219, 2019
2019
-
[20]
SUPER-ADAM: faster and universal framework of adaptive gradients
Feihu Huang, Junyi Li, and Heng Huang. SUPER-ADAM: faster and universal framework of adaptive gradients. In Advances in Neural Information Processing Systems (NeurIPS), pages 9074–9085, 2021
2021
-
[21]
Mars: Unleashing the power of variance reduction for training large models
Huizhuo Yuan, Yifeng Liu, Shuang Wu, Xun Zhou, and Quanquan Gu. Mars: Unleashing the power of variance reduction for training large models. ArXiv, abs/2411.10438, 2024
arXiv 2024
-
[22]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research, 12(7), 2011
2011
-
[23]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Interna- tional Conference on Learning Representations (ICLR), San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
2015
-
[24]
Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, and Sham M. Kakade. De- constructing what makes a good optimizer for autoregressive language models. In International Conference on Learning Representations (ICLR), 2025
2025
-
[25]
Adashift: Decorrelation and convergence of adaptive learning rate methods
Zhiming Zhou, Qingru Zhang, Guansong Lu, Hongwei Wang, Weinan Zhang, and Yong Yu. Adashift: Decorrelation and convergence of adaptive learning rate methods. In International Conference on Learning Representations (ICLR), 2019
2019
-
[26]
Adasgd: Bridging the gap between sgd and adam
Jiaxuan Wang and Jenna Wiens. Adasgd: Bridging the gap between sgd and adam. ArXiv, abs/2006.16541, 2020
arXiv 2006
-
[27]
Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P. Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun. Adam-mini: Use fewer learning rates to gain more. In International Conference on Learning Representations (ICLR), 2025
2025
-
[28]
On the convergence of adaptive gradient methods for nonconvex optimization
Dongruo Zhou, Yiqi Tang, Ziyan Yang, Yuan Cao, and Quanquan Gu. On the convergence of adaptive gradient methods for nonconvex optimization. ArXiv, abs/1808.05671, 2018
arXiv 2018
-
[29]
On the convergence of A class of adam-type algorithms for non-convex optimization
Xiangyi Chen, Sijia Liu, Ruoyu Sun, and Mingyi Hong. On the convergence of A class of adam-type algorithms for non-convex optimization. In International Conference on Learning Representations (ICLR), 2019
2019
-
[30]
A novel convergence analysis for algorithms of the adam family
Zhishuai Guo, Yi Xu, Wotao Yin, Rong Jin, and Tianbao Yang. A novel convergence analysis for algorithms of the adam family. ArXiv, abs/2112.03459, 2021
arXiv 2021
-
[31]
Convergence of adam under relaxed assumptions
Haochuan Li, Alexander Rakhlin, and Ali Jadbabaie. Convergence of adam under relaxed assumptions. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[32]
Closing the gap between the upper bound and lower bound of adam’s iteration complexity
Bohan Wang, Jingwen Fu, Huishuai Zhang, Nanning Zheng, and Wei Chen. Closing the gap between the upper bound and lower bound of adam’s iteration complexity. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[33]
Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models
Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Yan. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9508–9520, 2024. 11
2024
-
[34]
Convergence guarantees for rmsprop and adam in generalized-smooth non-convex optimization with affine noise variance
Qi Zhang, Yi Zhou, and Shaofeng Zou. Convergence guarantees for rmsprop and adam in generalized-smooth non-convex optimization with affine noise variance. Trans. Mach. Learn. Res., 2025, 2025
2025
-
[35]
On convergence of adam for stochastic optimization under relaxed assumptions
Yusu Hong and Junhong Lin. On convergence of adam for stochastic optimization under relaxed assumptions. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[36]
A high probability analysis of adaptive sgd with momentum
Xiaoyu Li and Francesco Orabona. A high probability analysis of adaptive sgd with momentum. arXiv preprint arXiv:2007.14294, 2020
arXiv 2007
-
[37]
Bach, and Nicolas Usunier
Alexandre Défossez, Léon Bottou, Francis R. Bach, and Nicolas Usunier. A simple convergence proof of adam and adagrad. Transactions on Machine Learning Research, 2022
2022
-
[38]
High probability convergence of adam under unbounded gradients and affine variance noise
Yusu Hong and Junhong Lin. High probability convergence of adam under unbounded gradients and affine variance noise. ArXiv, abs/2311.02000, 2023
arXiv 2023
-
[39]
Global convergence of the heavy-ball method for convex optimization
Euhanna Ghadimi, Hamid Reza Feyzmahdavian, and Mikael Johansson. Global convergence of the heavy-ball method for convex optimization. 2015 European Control Conference (ECC), pages 310–315, 2014
2015
-
[40]
A unified analysis of stochastic momentum methods for deep learning
Yan Yan, Tianbao Yang, Zhe Li, Qihang Lin, and Yi Yang. A unified analysis of stochastic momentum methods for deep learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, pages 2955–2961. ijcai.org, 2018
2018
-
[41]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations (ICLR), 2019
2019
-
[42]
Muon is scalable for llm training
Jingyuan Liu, Jianling Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Meng Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is scala...
Pith/arXiv arXiv 2025
-
[43]
8-bit optimizers via block-wise quantization
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 8-bit optimizers via block-wise quantization. In International Conference on Learning Representations (ICLR), 2022
2022
-
[44]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021
2021
-
[45]
Girshick
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll’ar, and Ross B. Girshick. Masked autoencoders are scalable vision learners. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15979–15988, 2021
2022
-
[46]
Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anth...
Pith/arXiv arXiv 2023
-
[47]
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, 12 Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji L...
Pith/arXiv arXiv 2024
-
[48]
Roberta: A robustly optimized bert pretraining approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692, 2019
Pith/arXiv arXiv 1907
-
[49]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[50]
Adam can con- verge without any modification on update rules
Yushun Zhang, Congliang Chen, Naichen Shi, Ruoyu Sun, and Zhi-Quan Luo. Adam can con- verge without any modification on update rules. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[51]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning (ICML), pages 4596–4604. PMLR, 2018
2018
-
[52]
Q-galore: Quantized galore with INT4 projection and layer-adaptive low- rank gradients
Zhenyu Zhang, Ajay Kumar Jaiswal, Lu Yin, Shiwei Liu, Jiawei Zhao, Yuandong Tian, and Zhangyang Wang. Q-galore: Quantized galore with INT4 projection and layer-adaptive low- rank gradients. In Conference on Parsimony and Learning, Stanford University, USA, 24-27 March 2025, volume 280 of Proceedings of Machine Learning Research, pages 1035–1050. PMLR, 2025
2025
-
[53]
Greedy layer-wise training of deep networks
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems (NeurIPS), pages 153–160. MIT Press, 2006
2006
-
[54]
Hinton, Simon Osindero, and Yee-Whye Teh
Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18(7):1527–1554, 2006
2006
-
[55]
Adalomo: Low-memory optimiza- tion with adaptive learning rate
Kai Lv, Hang Yan, Qipeng Guo, Haijun Lv, and Xipeng Qiu. Adalomo: Low-memory optimiza- tion with adaptive learning rate. In Findings of the Association for Computational Linguistics (ACL), pages 12486–12502, 2024
2024
-
[56]
A method for solving the convex programming problem with convergence rate o(1/k2)
Yurii Nesterov. A method for solving the convex programming problem with convergence rate o(1/k2). Proceedings of the USSR Academy of Sciences, 269:543–547, 1983
1983
-
[57]
Lecture 6a overview of mini– batch gradient descent
Geoffrey Hinton, Nitish Srivastava, and Kevin Swersky. Lecture 6a overview of mini– batch gradient descent. Coursera Lecture slides https://class. coursera. org/neuralnets-2012- 001/lecture,[Online, 2012
2012
-
[58]
Reddi, Satyen Kale, and Sanjiv Kumar
Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. In International Conference on Learning Representations (ICLR), 2018
2018
-
[59]
Incorporating nesterov momentum into adam
Timothy Dozat. Incorporating nesterov momentum into adam. 2016
2016
-
[60]
Adaptive gradient methods with dynamic bound of learning rate
Liangchen Luo, Yuanhao Xiong, Yan Liu, and Xu Sun. Adaptive gradient methods with dynamic bound of learning rate. In International Conference on Learning Representations (ICLR), 2019
2019
-
[61]
On the variance of the adaptive learning rate and beyond
Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han. On the variance of the adaptive learning rate and beyond. In International Conference on Learning Representations (ICLR), 2020
2020
-
[62]
Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum
Zeke Xie, Xinrui Wang, Huishuai Zhang, Issei Sato, and Masashi Sugiyama. Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum. In International Conference on Machine Learning (ICML), 2020
2020
-
[63]
Sophia: A scalable stochastic second-order optimizer for language model pre-training
Hong Liu, Zhiyuan Li, David Leo Wright Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. In International Conference on Learning Representations (ICLR), 2024. 13
2024
-
[64]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. In International Conference on Machine Learning (ICML), 2018
2018
-
[65]
On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
Da Chang, Yongxiang Liu, and Ganzhao Yuan. On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
Pith/arXiv arXiv 2025
-
[66]
Muoneq: Balancing before orthogonalization with lightweight equilibration
Da Chang, Qiankun Shi, Lvgang Zhang, Yu Li, Ruijie Zhang, Yao Lu, Yongxiang Liu, and Ganzhao Yuan. Muoneq: Balancing before orthogonalization with lightweight equilibration. arXiv preprint arXiv:2603.28254, 2026
Pith/arXiv arXiv 2026
-
[67]
A sufficient condition for convergences of adam and rmsprop
Fangyu Zou, Li Shen, Zequn Jie, Weizhong Zhang, and Wei Liu. A sufficient condition for convergences of adam and rmsprop. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11127–11135, 2019
2019
-
[68]
pulse-decay
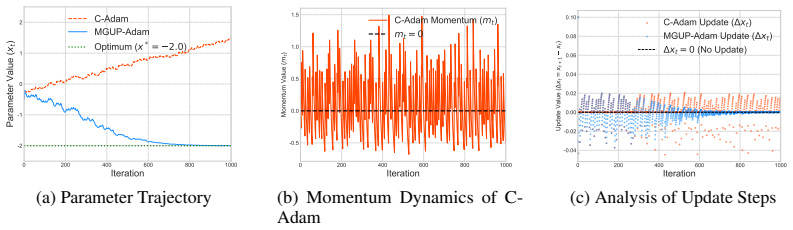
Yuqing Liang, Meixuan He, Jinlan Liu, and Dongpo Xu. Convergence of adam for non-convex objectives: relaxed hyperparameters and non-ergodic case. Mach. Learn., 114(3):75, 2025. 14 Appendix The appendices are structured as follows: • Appendix A gives a counterexample showing that Cautious Adam may diverge. • Appendix B summarizes additional related work. •...
2025
-
[69]
exp ˆX 2 s,i w2 s,i ! | F s−1,i # ≤ E
≥ ϵ2(1 − β2). Next, the following inequalities and equality hold: b2 s,i ≥ v2 s,i + ϵ2 ≥ (1 − β2) sX j=1 βs−j 2 g2 j,i + ϵ2 , ms,i = (1 − β1) sX j=1 βs−j 1 gj,i. For the first expression, it follows that: tX s=1 g2 s,i b2 s,i ≤ 1 1 − β2 tX s=1 g2 s,i ϵ2 +Ps j=1 βs−j 2 g2 j,i . (◦) ≤ 1 1 − β2 " log 1 + 1 ϵ2 tX s=1 βt−s 2 g2 s,i ! − t log β2 # ≤ 1 1...
2034
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.