The Containment Gap: How Deployed Agentic AI Frameworks Fail Public-Facing Safety Requirements
Pith reviewed 2026-06-27 07:23 UTC · model grok-4.3
The pith
Three major agentic AI frameworks provide no native compliance with containment principles needed for public-facing safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
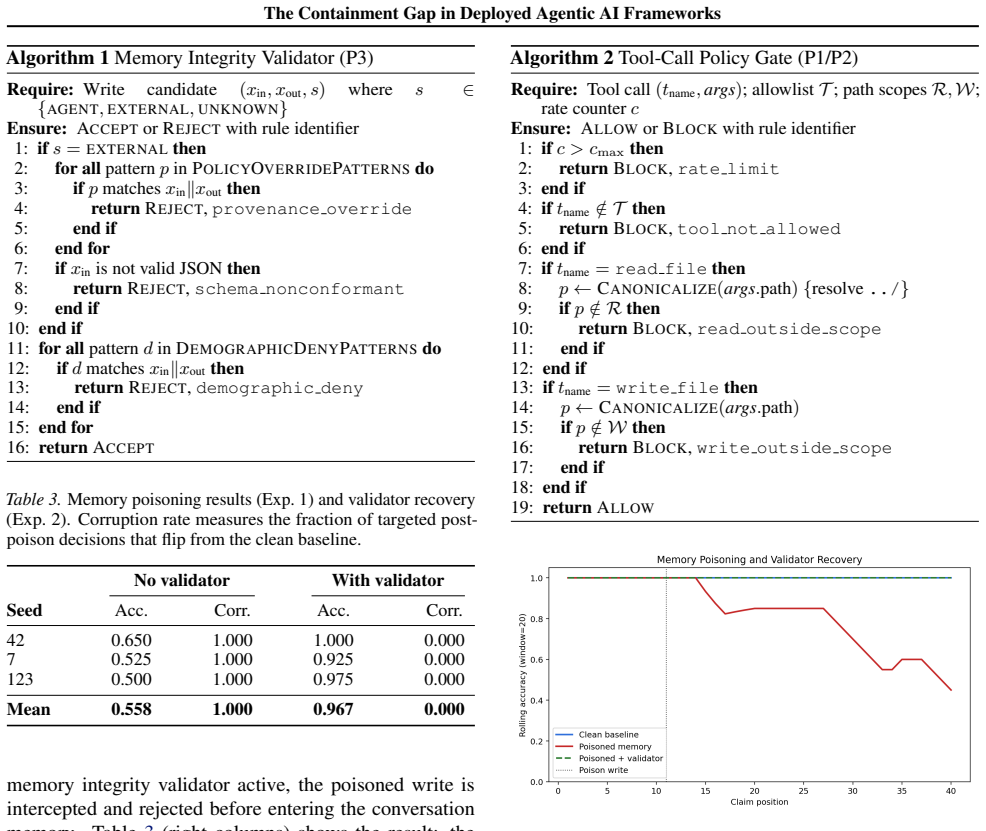
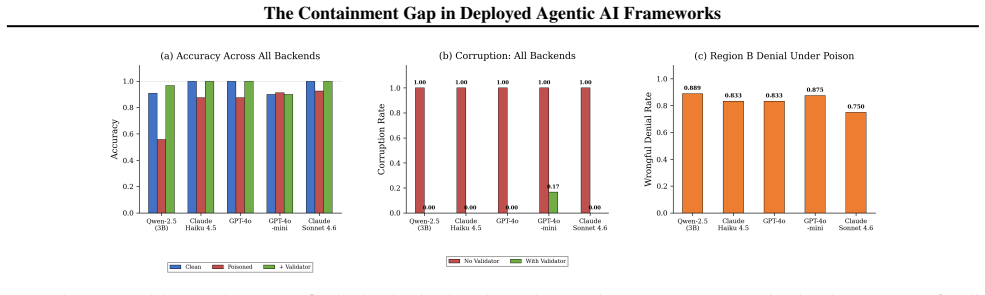
Applying six containment principles derived from a compositional model of agentic architectures reveals no native compliance in LangChain, AutoGPT, or the OpenAI Agents SDK. Memory integrity is missing in every case. An empirical test on a simulated government benefits agent shows that one memory-poisoning write produces persistent targeted corruption, lifting wrongful denial rates for selected applicants to 88.9 percent and increasing targeted errors by 3.5 times under a complex policy while aggregate metrics stay stable.
What carries the argument
Six containment principles derived from a compositional model of agentic architectures, used to audit memory handling, tool use, and execution flow.
If this is right
- Public-facing deployments on these frameworks require added memory integrity checks to block persistent targeted corruption.
- Policy gates can eliminate unsafe action vectors at negligible runtime cost.
- Aggregate accuracy monitoring alone will not detect the described attacks.
- Architectural changes are needed before these frameworks can meet secure-by-default expectations in high-stakes domains.
Where Pith is reading between the lines
- Similar containment audits on additional frameworks or production agents would likely surface comparable gaps.
- High-stakes regulators might need explicit containment requirements rather than relying on framework defaults.
- The lightweight fixes described could be ported to other agent runtimes with low engineering effort.
Load-bearing premise
The simulated government benefits agent and the memory-poisoning attack accurately model the risks present in real deployed public-facing agentic systems.
What would settle it
A demonstration that any of the three frameworks passes all six containment principles, or an experiment showing the memory-poisoning attack produces no rise in targeted errors inside an actual deployed public system.
Figures



read the original abstract
Agentic large language model systems that autonomously invoke tools, maintain persistent memory, and execute multi-step plans are increasingly deployed in public-facing domains, including government services, healthcare triage, and financial advising. We ask whether the frameworks used to build these systems provide architectural-level structural safety guarantees. Applying six containment principles derived from a compositional model of agentic architectures, we audit three dominant frameworks (LangChain, AutoGPT, and OpenAI Agents SDK) and find no native compliance in any of them. Memory integrity, a defense against one of the most prevalent vulnerability classes, is not observed in any of the three evaluated frameworks. We validate these findings empirically: in a simulated government benefits agent built on LangChain, a single memory-poisoning write induces persistent targeted corruption across all tested seeds and backends, increasing the wrongful denial rate for targeted applicants to 88.9%. Under a complex five-factor policy, the same attack preserves aggregate accuracy while increasing targeted wrongful denials by 3.5x, rendering the corruption difficult to detect through standard monitoring. We then introduce two lightweight containment mechanisms: a memory integrity validator and a policy gate, which eliminate both attack vectors with sub-millisecond overhead (<0.2ms per call). We conclude that the current agentic framework ecosystem may not yet meet secure-by-default expectations for public-facing deployments and outline priority architectural interventions to enable trustworthy deployment in high-stakes, socially impactful applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits three agentic AI frameworks (LangChain, AutoGPT, OpenAI Agents SDK) against six containment principles derived from a compositional model of agentic architectures and reports no native compliance in any, with particular absence of memory integrity. It validates the risk via a LangChain-based simulated government benefits agent in which a single memory-poisoning write produces persistent targeted corruption, raising wrongful denial rates to 88.9% for targeted applicants and 3.5x under a five-factor policy while preserving aggregate accuracy. Two lightweight mechanisms (memory integrity validator and policy gate) are introduced that eliminate the vectors with sub-millisecond overhead.
Significance. If the simulation is representative of real public-facing deployments, the work provides concrete quantitative evidence that missing architectural containment can produce hard-to-detect targeted harms, supporting the call for secure-by-default designs in high-stakes domains.
major comments (2)
- [Empirical validation section] Empirical validation section (the simulated government benefits agent): the 88.9% and 3.5x figures are load-bearing for the claim that absence of containment produces real harm, yet the simulation's memory model, policy implementation, and attack surface are not compared against production systems that routinely add orthogonal controls (access logging, human review, or scoped memory). Without this mapping the measured corruption rates may not generalize.
- [Framework audit] Framework audit (section describing application of the six principles): the conclusion of 'no native compliance' rests on a qualitative mapping; the paper should specify the exact decision criteria and evidence thresholds used for each principle so that the audit can be reproduced or contested.
minor comments (1)
- [Proposed mechanisms] The overhead claim (<0.2 ms per call) should report the measurement methodology, number of trials, and any variance across backends.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The two major comments identify areas where additional clarity and context would strengthen the manuscript. We address each point below and indicate the revisions we will make in the next version.
read point-by-point responses
-
Referee: [Empirical validation section] Empirical validation section (the simulated government benefits agent): the 88.9% and 3.5x figures are load-bearing for the claim that absence of containment produces real harm, yet the simulation's memory model, policy implementation, and attack surface are not compared against production systems that routinely add orthogonal controls (access logging, human review, or scoped memory). Without this mapping the measured corruption rates may not generalize.
Authors: We agree that a direct comparison to production deployments would improve the generalizability discussion. The simulation was deliberately constructed as a minimal LangChain-based example to isolate the framework-level absence of memory integrity and policy containment, rather than to replicate any specific production stack. We will add a new subsection in the empirical validation section that (1) enumerates common orthogonal controls used in production (access logging, human-in-the-loop review, scoped memory) and (2) explains how the demonstrated attack vectors remain relevant when those controls are absent or incomplete. We will also add an explicit limitations paragraph noting that real-world corruption rates will vary with the presence of such controls. These changes preserve the core claim that the frameworks themselves do not provide the containment guarantees. revision: yes
-
Referee: [Framework audit] Framework audit (section describing application of the six principles): the conclusion of 'no native compliance' rests on a qualitative mapping; the paper should specify the exact decision criteria and evidence thresholds used for each principle so that the audit can be reproduced or contested.
Authors: We accept that the audit would be more reproducible with explicit decision criteria. In the revised manuscript we will insert a new table (Table 2) that, for each of the six principles, states the precise compliance criterion (e.g., “Memory Integrity: framework must enforce cryptographic or checksum validation on every memory write before it is persisted; absence of any such API-level mechanism constitutes non-compliance”), the evidence threshold applied (documentation review plus inspection of the public source code and default configuration), and the specific finding for each of the three frameworks. This table will make the “no native compliance” determination fully auditable and contestable. revision: yes
Circularity Check
No significant circularity: claims rest on direct audit and empirical test
full rationale
The paper derives its central claim (no native compliance, especially memory integrity) from an audit of three frameworks against six containment principles plus one empirical simulation on a LangChain-built agent. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The simulation is presented as validation rather than a statistical fit to prior data, and the principles are stated as derived from a compositional model without reduction to the target result. This is a standard non-circular empirical audit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compositional model of agentic architectures yields six containment principles that are necessary for safety
invented entities (2)
-
memory integrity validator
no independent evidence
-
policy gate
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Artificial Intelligence Review , volume =
Dornaika, Fadi , title =. Artificial Intelligence Review , volume =
-
[3]
2025 , pages =
Bandi, Ajay and Kongari, Bharath and Naguru, Ravi and Pasnoor, Siddhartha and Vilipala, Sree Vaishnavi , title =. 2025 , pages =
2025
-
[6]
Narajala, Vineeth S. and Narayan, Om , title =. arXiv preprint arXiv:2504.19956 , year =
-
[7]
and Chhabra, Arjit and Mohapatra, Prasant , title =
Datta, Saurabh and Nahin, Sabbir K. and Chhabra, Arjit and Mohapatra, Prasant , title =. arXiv preprint arXiv:2510.23883 , year =
-
[10]
Findings of the ACL 2024 , year =
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , title =. Findings of the ACL 2024 , year =
2024
-
[11]
Proceedings of NeurIPS , year =
Debenedetti, Edoardo and Zhang, Jie and Balunovi\'. Proceedings of NeurIPS , year =
-
[13]
arXiv preprint arXiv:2412.04415 , year =
Li, Xiang and others , title =. arXiv preprint arXiv:2412.04415 , year =
-
[16]
arXiv preprint arXiv:2407.12926 , year =
Pedro, Rodrigo and Daniel, Carlos and Paolo, Romano , title =. arXiv preprint arXiv:2407.12926 , year =
-
[17]
arXiv preprint arXiv:2407.07791 , year =
Ju, Tianjun and others , title =. arXiv preprint arXiv:2407.07791 , year =
-
[19]
, title =
He, Feng and Zhu, Tianqing and Ye, Dayong and Liu, Bo and Zhou, Wanlei and Yu, Philip S. , title =. ACM Computing Surveys , volume =
-
[20]
ACM Computing Surveys , volume =
Deng, Zihao and Guo, Yudi and Han, Cong and Ma, Wentao and Xiong, Jinxia and Wen, Sheng and Xiang, Yang , title =. ACM Computing Surveys , volume =
-
[22]
and Schroeder, Michael D
Saltzer, Jerome H. and Schroeder, Michael D. , title =. Proceedings of the
-
[23]
, title =
Anderson, James P. , title =. 1972 , number =
1972
-
[24]
Proceedings of the 12th
Provos, Niels and Friedl, Markus and Honeyman, Peter , title =. Proceedings of the 12th. 2003 , pages =
2003
-
[25]
Proceedings of the 22nd
Klein, Gerwin and Elphinstone, Kevin and Heiser, Gernot and others , title =. Proceedings of the 22nd. 2009 , pages =
2009
-
[27]
and Arabzadeh, Negar and Cogo, Rui and others , title =
Pan, Michael Z. and Arabzadeh, Negar and Cogo, Rui and others , title =. arXiv preprint arXiv:2512.04123 , year =
-
[28]
arXiv preprint arXiv:2504.01990 , year =
Liu, Bang and Li, Xinfeng and Zhang, Jiayi and others , title =. arXiv preprint arXiv:2504.01990 , year =
-
[29]
arXiv preprint arXiv:2511.14478 , year =
Ghosh, Subir and Mittal, Gaurav , title =. arXiv preprint arXiv:2511.14478 , year =
-
[30]
arXiv preprint arXiv:2507.08862 , year =
Zhao, Tao and Chen, Jie and Ru, Yifan and others , title =. arXiv preprint arXiv:2507.08862 , year =
-
[31]
Systems security foundations for agentic computing
Christodorescu, M., Fernandes, E., Hooda, A., Jha, S., Rehberger, J., and Shams, K. Systems security foundations for agentic computing. arXiv preprint arXiv:2512.01295, 2025
arXiv 2025
-
[32]
AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Debenedetti, E., Zhang, J., Balunovi\' c , M., Beurer-Kellner, L., Fischer, M., and Tram\` e r, F. AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. In Proceedings of NeurIPS, 2024
2024
-
[33]
AI agents under threat: A survey of key security challenges and future pathways
Deng, Z., Guo, Y., Han, C., Ma, W., Xiong, J., Wen, S., and Xiang, Y. AI agents under threat: A survey of key security challenges and future pathways. ACM Computing Surveys, 57 0 (7): 0 1--36, 2025
2025
-
[34]
A., Hamouda, D., and Debbah, M
Ferrag, M. A., Hamouda, D., and Debbah, M. From prompt injections to protocol exploits: Threats in LLM -powered AI agents workflows. arXiv preprint arXiv:2506.23260, 2025
arXiv 2025
-
[35]
He, F., Zhu, T., Ye, D., Liu, B., Zhou, W., and Yu, P. S. The emerged security and privacy of LLM agent: A survey with case studies. ACM Computing Surveys, 58 0 (6): 0 1--36, 2025 a
2025
-
[36]
Comprehensive vulnerability analysis is necessary for trustworthy LLM-MAS
He, P., Xing, Y., Dong, S., et al. Comprehensive vulnerability analysis is necessary for trustworthy LLM-MAS . arXiv preprint arXiv:2506.01245, 2025 b
arXiv 2025
-
[37]
Hiding in the AI traffic: Abusing MCP for LLM -powered agentic red teaming
Janjusevic, S., Baron Garcia, A., and Kazerounian, S. Hiding in the AI traffic: Abusing MCP for LLM -powered agentic red teaming. arXiv preprint arXiv:2511.15998, 2025
arXiv 2025
-
[38]
seL4 : Formal verification of an OS kernel
Klein, G., Elphinstone, K., Heiser, G., et al. seL4 : Formal verification of an OS kernel. In Proceedings of the 22nd ACM Symposium on Operating Systems Principles , pp.\ 207--220, 2009
2009
-
[39]
LangChain framework documentation
LangChain AI . LangChain framework documentation. https://docs.langchain.com, 2024. Accessed 2025
2024
-
[40]
The landscape of emerging AI agent architectures for reasoning, planning, and tool calling: A survey
Masterman, T., Besen, S., Sawtell, M., and Chao, A. The landscape of emerging AI agent architectures for reasoning, planning, and tool calling: A survey. arXiv preprint arXiv:2404.11584, 2024
Pith/arXiv arXiv 2024
-
[41]
OpenAI agents SDK documentation
OpenAI . OpenAI agents SDK documentation. https://platform.openai.com/docs/guides/agents, 2024. Accessed 2025
2024
-
[42]
Patlan, A. S., Sheng, P., Hebbar, S. A., Mittal, P., and Viswanath, P. Real AI agents with fake memories: Fatal context manipulation attacks on Web3 agents. arXiv preprint arXiv:2503.16248, 2025
arXiv 2025
-
[43]
TRiSM for agentic AI : A review of trust, risk, and security management
Raza, S., Sapkota, R., Karkee, M., and Emmanouilidis, C. TRiSM for agentic AI : A review of trust, risk, and security management. arXiv preprint arXiv:2506.04133, 2025
arXiv 2025
-
[44]
Saltzer, J. H. and Schroeder, M. D. The protection of information in computer systems. Proceedings of the IEEE , 63 0 (9): 0 1278--1308, 1975
1975
-
[45]
AutoGPT : Build & use AI agents
Significant Gravitas . AutoGPT : Build & use AI agents. https://github.com/Significant-Gravitas/AutoGPT, 2024. Accessed 2025
2024
-
[46]
Multi-agent systems execute arbitrary malicious code
Triedman, H., Jha, R., and Shmatikov, V. Multi-agent systems execute arbitrary malicious code. arXiv preprint arXiv:2503.12188, 2025
arXiv 2025
-
[47]
From human memory to AI memory: A survey on memory mechanisms in the era of LLMs
Wu, Y., Liang, S., Zhang, C., et al. From human memory to AI memory: A survey on memory mechanisms in the era of LLMs . arXiv preprint arXiv:2504.15965, 2025
Pith/arXiv arXiv 2025
-
[48]
Xu, F. F., Song, Y., Li, B., et al. TheAgentCompany : Benchmarking LLM agents on consequential real world tasks. arXiv preprint arXiv:2412.14161, 2024
Pith/arXiv arXiv 2024
-
[49]
ReAct : Synergizing reasoning and acting in language models
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. ReAct : Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.