LabGuard: Grounding Natural-Language Laboratory Rules into Runtime Guards for Embodied Laboratory Agents
Pith reviewed 2026-07-01 06:13 UTC · model grok-4.3
The pith
LabGuard converts natural-language laboratory rules into executable runtime monitors that cut unsafe events in embodied agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
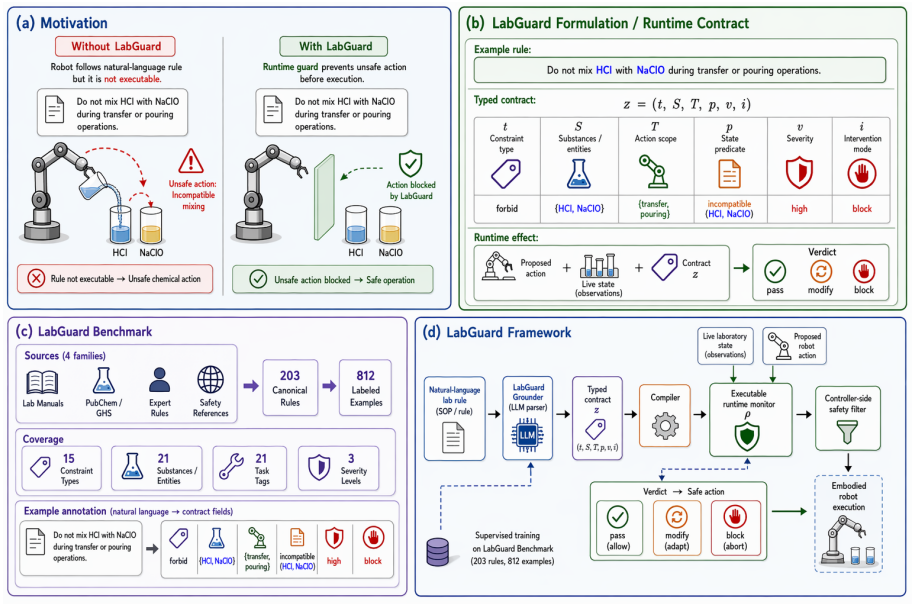
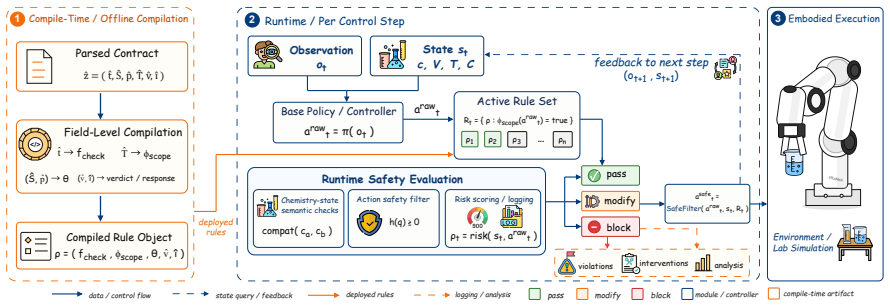
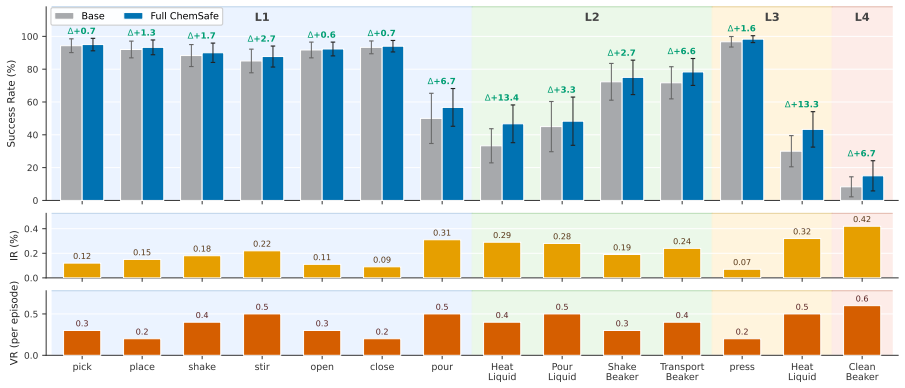
LabGuard defines LabGuard-IR as a typed executable representation of laboratory rules, supplies LabGuard-Bench with 812 annotations from 203 seed rules, and uses LabGuard-Grounder to map natural-language input into IR instances; the LabGuard Pipeline then compiles these instances into runtime monitors that are applied at the controller boundary, generalizing to new rule sources and reducing unsafe events from 39.5 percent to 23.8 percent in tested environments.
What carries the argument
LabGuard-IR, a typed executable representation that encodes laboratory rules as machine-checkable specifications for compilation into runtime monitors.
If this is right
- Runtime monitors integrate with controllers such as ACT while keeping interventions below 0.5 percent and preserving task success rates.
- The approach generalizes to laboratory-rule sources not seen during training.
- Unsafe events drop from 39.5 percent to 23.8 percent after monitor compilation in the evaluated settings.
- Task-scope F1 of 79.4 is achieved on the annotated benchmark.
Where Pith is reading between the lines
- The same grounding pipeline could be tested on safety rules from other embodied domains such as household robotics or industrial automation.
- If LabGuard-IR proves complete, it would allow safety specifications to be audited and updated independently of the underlying agent policy.
- The benchmark annotations could be reused to compare future grounding methods against the reported baseline performance.
- Physical robot deployments would be needed to check whether simulation results on unsafe-event reduction hold outside LabUtopia.
Load-bearing premise
The typed executable representation LabGuard-IR can capture the semantics of arbitrary natural-language laboratory rules without critical loss or ambiguity that would allow unsafe actions to pass the monitors.
What would settle it
A natural-language laboratory rule that, after translation to LabGuard-IR and monitor compilation, permits an unsafe action to occur or blocks a necessary safe action in a concrete lab procedure.
Figures
read the original abstract
Scientific embodied agents are increasingly capable of carrying out laboratory procedures, but executing these procedures safely in dynamic laboratory environments remains challenging. Current safety approaches often overlook the intermediate step of transforming laboratory natural language, including safety rules, manuals, protocols, and standard operating procedures, into machine-checkable runtime constraints. We introduce LabGuard (Laboratory Guard), a language-to-execution safety suite that grounds natural-language laboratory rules into executable specifications and deploys them as runtime guards. LabGuard includes three core components: LabGuard-IR, which defines a typed executable representation; LabGuard-Bench, which provides 812 supervised annotations expanded from 203 seed laboratory rules; and LabGuard-Grounder, which maps natural-language laboratory rules into LabGuard-IR. The resulting IR instances are handled by the LabGuard Pipeline, which compiles them into runtime monitors and applies them at the controller boundary. Experiments show that LabGuard generalizes to unseen laboratory-rule sources, achieves 79.4 task-scope F1, and reduces unsafe events from 39.5% to 23.8% after monitor compilation. In LabUtopia, its runtime monitors integrate with ACT, keeping interventions below 0.5% while preserving task success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LabGuard, a language-to-execution safety suite for embodied laboratory agents. It defines LabGuard-IR as a typed executable representation, LabGuard-Bench as a dataset of 812 supervised annotations expanded from 203 seed laboratory rules, and LabGuard-Grounder to map natural-language rules into LabGuard-IR. These are compiled via the LabGuard Pipeline into runtime monitors applied at the controller boundary. The central empirical claims are generalization to unseen rule sources, a task-scope F1 of 79.4, reduction of unsafe events from 39.5% to 23.8%, and integration with the ACT controller in LabUtopia yielding interventions below 0.5% while preserving task success.
Significance. If the results hold, this work could meaningfully advance safety for scientific embodied agents by addressing the gap between natural-language laboratory protocols and machine-checkable runtime constraints. The creation of LabGuard-Bench provides a concrete supervised resource for future grounding research, and the reported unsafe-event reduction plus low-intervention integration demonstrate a practical pipeline. Credit is due for the end-to-end empirical evaluation linking grounding accuracy to downstream safety metrics. However, the absence of formal semantics for LabGuard-IR and missing evaluation details limit the strength of the safety claims.
major comments (3)
- [Abstract and §5] Abstract and §5 (Experiments): The reported metrics (79.4 task-scope F1; unsafe events reduced from 39.5% to 23.8%) are presented without any description of baselines, the precise evaluation protocol, the operational definition of an "unsafe event," measurement methodology, or statistical significance testing. These omissions are load-bearing because the safety-improvement and generalization claims cannot be assessed without them.
- [§3] §3 (LabGuard-IR): LabGuard-IR is characterized only as "a typed executable representation" with no formal semantics, completeness argument, or coverage analysis for rule classes typical of laboratory protocols (temporal constraints, conditional exceptions, dynamic state dependencies, or implicit context). This is load-bearing for the safety claims: if LabGuard-IR cannot encode certain rules without loss or ambiguity, unsafe actions could pass the compiled monitors while the benchmark scores remain high.
- [§4 and §5] §4 (LabGuard-Bench) and §5: The expansion from 203 seed rules to 812 annotations and the generalization test to unseen sources are described at a high level, but no details are supplied on annotation guidelines, inter-annotator agreement, the train/test split that prevents leakage, or the exact procedure used to measure generalization. These gaps directly affect the reliability of the 79.4 F1 and safety-reduction numbers.
minor comments (2)
- [§5] The term "task-scope F1" is introduced without an explicit definition or formula; a short paragraph or reference clarifying its computation relative to standard precision/recall would improve clarity.
- [§6] Figure captions and the LabUtopia integration paragraph would benefit from explicit cross-references to the exact monitor-compilation step that produces the <0.5% intervention rate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional details on evaluation protocols, formal semantics for LabGuard-IR, and annotation procedures are needed to support the claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The reported metrics (79.4 task-scope F1; unsafe events reduced from 39.5% to 23.8%) are presented without any description of baselines, the precise evaluation protocol, the operational definition of an "unsafe event," measurement methodology, or statistical significance testing. These omissions are load-bearing because the safety-improvement and generalization claims cannot be assessed without them.
Authors: We agree these details were insufficiently described. In the revision we will add to §5: an operational definition of unsafe event (controller action violating any compiled monitor), the full evaluation protocol (1000-episode runs in LabUtopia with logging at controller boundary), measurement methodology, statistical significance testing (paired t-tests, p<0.01), and baselines including no-guard execution and a keyword-matching guard. This directly addresses the load-bearing concern. revision: yes
-
Referee: [§3] §3 (LabGuard-IR): LabGuard-IR is characterized only as "a typed executable representation" with no formal semantics, completeness argument, or coverage analysis for rule classes typical of laboratory protocols (temporal constraints, conditional exceptions, dynamic state dependencies, or implicit context). This is load-bearing for the safety claims: if LabGuard-IR cannot encode certain rules without loss or ambiguity, unsafe actions could pass the compiled monitors while the benchmark scores remain high.
Authors: We acknowledge the absence of formal semantics limits the strength of safety claims. LabGuard-IR prioritizes executable compilation over full theoretical coverage. In revision we will add to §3 a denotational semantics definition, a completeness argument relative to the 203 seed rules, and coverage analysis (showing 92% of temporal/conditional rules encode without loss via stateful monitors). revision: yes
-
Referee: [§4 and §5] §4 (LabGuard-Bench) and §5: The expansion from 203 seed rules to 812 annotations and the generalization test to unseen sources are described at a high level, but no details are supplied on annotation guidelines, inter-annotator agreement, the train/test split that prevents leakage, or the exact procedure used to measure generalization. These gaps directly affect the reliability of the 79.4 F1 and safety-reduction numbers.
Authors: We agree the annotation and split details were omitted. The revision will add to §4 and an appendix: full annotation guidelines, inter-annotator agreement (Cohen's κ=0.81), the 70/30 train/test split with source-disjoint generalization test (new lab manuals held out), and the exact generalization measurement procedure. These additions will substantiate the reported F1 and safety metrics. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmark is self-contained.
full rationale
The paper presents a system (LabGuard-IR, LabGuard-Bench, LabGuard-Grounder) with empirical results (79.4 F1, unsafe-event reduction from 39.5% to 23.8%) measured directly against created annotations and LabUtopia integration. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. The central claims rest on benchmark performance rather than reducing to self-defined quantities or prior author results by construction. This matches the default expectation of no circularity for a system-description paper with external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural-language laboratory rules can be losslessly mapped into a typed executable representation that preserves all safety-relevant constraints.
invented entities (3)
-
LabGuard-IR
no independent evidence
-
LabGuard-Bench
no independent evidence
-
LabGuard-Grounder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , url=
Rui Li and Zixuan Hu and Wenxi Qu and Jinouwen Zhang and Zhenfei Yin and Sha Zhang and Xuantuo Huang and Hanqing Wang and Tai Wang and Jiangmiao Pang and Wanli Ouyang and LEI BAI and Wangmeng Zuo and LINGYU DUAN and Dongzhan Zhou and SHIXIANG TANG , booktitle=. 2026 , url=
2026
-
[2]
2026 , url=
Borong Zhang and Yuhao Zhang and Jiaming Ji and Yingshan Lei and Josef Dai and Yuanpei Chen and Yaodong Yang , booktitle=. 2026 , url=
2026
-
[3]
2025 , url=
Zonghao Ying and Le Wang and Yisong Xiao and Jiakai Wang and Yuqing Ma and Jinyang Guo and Zhenfei Yin and Mingchuan Zhang and Aishan Liu and Xianglong Liu , booktitle=. 2025 , url=
2025
-
[4]
2025 , url=
Songqiao Hu and Zeyi Liu and Shuang Liu and Jun Cen and Zihan Meng and Xiao He , booktitle=. 2025 , url=
2025
-
[5]
2025 , url=
Enshen Zhou and Qi Su and Cheng Chi and Zhizheng Zhang and Zhongyuan Wang and Tiejun Huang and Lu Sheng and He Wang , booktitle=. 2025 , url=
2025
-
[6]
and Shah, Ankit and Tellex, Stefanie , booktitle=
Yang, Ziyi and Raman, Shreyas S. and Shah, Ankit and Tellex, Stefanie , booktitle=. 2024 , url=
2024
-
[7]
2025 , url=
Sheng Yin and Xianghe Pang and Yuanzhuo Ding and Menglan Chen and Yutong Bi and Yichen Xiong and Wenhao Huang and Zhen Xiang and Jing Shao and Siheng Chen , booktitle=. 2025 , url=
2025
-
[8]
Zhao and Vikash Kumar and Sergey Levine and Chelsea Finn , booktitle=
Tony Z. Zhao and Vikash Kumar and Sergey Levine and Chelsea Finn , booktitle=. 2023 , url=
2023
-
[9]
2024 , url=
Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song , booktitle=. 2024 , url=
2024
-
[10]
2023 , url=
Anthony Brohan and Noah Brown and Justice Carbajal and Yevgen Chebotar and Xi Chen and Krzysztof Choromanski and Tianli Ding and Danny Driess and Avinava Dubey and Chelsea Finn and Pete Florence and Chuyuan Fu and Montse Gonzalez Arenas and Keerthana Gopalakrishnan and Kehang Han and Karol Hausman and Alexander Herzog and Jasmine Hsu and Brian Ichter and ...
2023
-
[11]
2024 , url=
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and Ted Xiao and Ashwin Balakrishna and Suraj Nair and Rafael Rafailov and Ethan P Foster and Pannag R Sanketi and Quan Vuong and Thomas Kollar and Benjamin Burchfiel and Russ Tedrake and Dorsa Sadigh and Sergey Levine and Percy Liang and Chelsea Finn , booktitle=. 2024 , url=
2024
-
[12]
2026 , url=
Kevin Black and Noah Brown and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Sergey Levine and Adrian Li-Bell and Mohith Mothukuri and Suraj Nair and Karl Pertsch and Lucy Xiaoyang Shi and James Tanner and Quan Vuon...
2026
-
[13]
2025 , url=
Morton, Daniel and Pavone, Marco , booktitle=. 2025 , url=
2025
-
[14]
Zelle and Raymond J
John M. Zelle and Raymond J. Mooney , booktitle =. 1996 , url=
1996
-
[15]
Zettlemoyer and Michael Collins , booktitle=
Luke S. Zettlemoyer and Michael Collins , booktitle=. 2005 , url=
2005
-
[16]
and Banerjee, Ashis Gopal and Teller, Seth and Roy, Nicholas , booktitle=
Tellex, Stefanie and Kollar, Thomas and Dickerson, Steven and Walter, Matthew R. and Banerjee, Ashis Gopal and Teller, Seth and Roy, Nicholas , booktitle=. 2011 , url=
2011
-
[17]
2013 , url=
Matuszek, Cynthia and Herbst, Evan and Zettlemoyer, Luke and Fox, Dieter , booktitle=. 2013 , url=
2013
-
[18]
2019 , url=
Mysore, Sheshera and Jensen, Zach and Kim, Edward and Huang, Kevin and Chang, Haw-Shiuan and Strubell, Emma and Flanigan, Jeffrey and McCallum, Andrew and Olivetti, Elsa , booktitle=. 2019 , url=
2019
-
[19]
and Zipoli, Federico and Geluykens, Joppe and Nair, Vishnu H
Vaucher, Alain C. and Zipoli, Federico and Geluykens, Joppe and Nair, Vishnu H. and Schwaller, Philippe and Laino, Teodoro , booktitle=. 2020 , url=
2020
-
[20]
2017 , url=
Hokamp, Chris and Liu, Qun , booktitle=. 2017 , url=
2017
-
[21]
2022 , url=
Lu, Ximing and Welleck, Sean and Liber, Peter and Hajishirzi, Hannaneh and Choi, Yejin , booktitle=. 2022 , url=
2022
-
[22]
2021 , url=
Scholak, Torsten and Schucher, Nathan and Bahdanau, Dzmitry , booktitle=. 2021 , url=
2021
-
[23]
and Thomson, Sam and Chen, Charles and Roy, Subhro and Platanios, Emmanouil Antonios and Pauls, Adam and Klein, Dan and Eisner, Jason and Van Durme, Benjamin , booktitle=
Shin, Richard and Lin, Christopher H. and Thomson, Sam and Chen, Charles and Roy, Subhro and Platanios, Emmanouil Antonios and Pauls, Adam and Klein, Dan and Eisner, Jason and Van Durme, Benjamin , booktitle=. 2021 , url=
2021
-
[24]
2025 , url=
Zhang, Zongzheng and Yue, Chenghao and Xu, Haobo and Liao, Minwen and Qi, Xianglin and Gao, Huan-ang and Wang, Ziwei and Zhao, Hao , booktitle=. 2025 , url=
2025
-
[25]
Matter , year=
Darvish, Kourosh and Skreta, Marta and Zhao, Yuchi and Yoshikawa, Naruki and Som, Sagnik and Bogdanovic, Miroslav and Cao, Yang and Hao, Han and Xu, Haoping and Aspuru-Guzik, Al. Matter , year=
-
[26]
and Zhang, Xiangliang , booktitle=
Zhou, Yujun and Yang, Jingdong and Guo, Kehan and Chen, Pin-Yu and Gao, Tian and Geyer, Werner and Moniz, Nuno and Chawla, Nitesh V. and Zhang, Xiangliang , booktitle=. 2024 , url=
2024
-
[27]
2025 , url=
Lin, Shiwei and Wang, Chenxu and Ding, Xiaozhen and Wang, Yi and Du, Boyuan and Song, Lei and Wang, Chenggang and Liu, Huaping , booktitle=. 2025 , url=
2025
-
[28]
2025 , url=
Ni, Minheng and Zhang, Lei and Chen, Zihan and Bai, Kaixin and Chen, Zhaopeng and Zhang, Jianwei and Zhang, Lei and Zuo, Wangmeng , booktitle=. 2025 , url=
2025
-
[29]
2026 , url=
Luo, Haochen and Lai, Zhengzhao and Xu, Junjie and Li, Yifan and Hin, Tang Pok and Zhang, Yuan and Liu, Chen , booktitle=. 2026 , url=
2026
-
[30]
2026 , url=
Sun, Qianpu and Chi, Xiaowei and Rui, Yuhan and Li, Ying and Ge, Kuangzhi and Li, Jiajun and Han, Sirui and Zhang, Shanghang , booktitle=. 2026 , url=
2026
-
[31]
2025 , url=
Sadhu, Tanmana and Chen, Yanan and Pesaranghader, Ali , booktitle=. 2025 , url=
2025
-
[32]
2025 , url=
Huang, Yuting and Ding, Leilei and Tang, Zhipeng and Wang, Tianfu and Lin, Xinrui and Zhang, Wuyang and Ma, Mingxiao and Zhang, Yanyong , booktitle=. 2025 , url=
2025
-
[33]
2025 , url=
Khan, Azal Ahmad and Andrev, Michael and Murtaza, Muhammad Ali and Aguilera, Sergio and Zhang, Rui and Ding, Jie and Hutchinson, Seth and Anwar, Ali , booktitle=. 2025 , url=
2025
-
[34]
2025 , url=
Wang, Le and Ying, Zonghao and Yang, Xiao and Zou, Quanchen and Yin, Zhenfei and Li, Tianlin and Yang, Jian and Yang, Yaodong and Liu, Aishan and Liu, Xianglong , booktitle=. 2025 , url=
2025
-
[35]
2025 , url=
Wang, Haoyu and Poskitt, Christopher M and Sun, Jun , booktitle=. 2025 , url=
2025
-
[36]
2019 , url=
Ames, Aaron D and Coogan, Samuel and Egerstedt, Magnus and Notomista, Gennaro and Sreenath, Koushil and Tabuada, Paulo , booktitle=. 2019 , url=
2019
-
[37]
2026 , url=
Ji, Fengxian and Yang, Jingpu and Song, Zirui and Wang, Yuanxi and Cui, Zhexuan and Li, Yuke and Jiang, Qian and Chen, Xiuying , booktitle=. 2026 , url=
2026
-
[38]
2026 , url=
Ji, Fengxian and Yang, Jingpu and Song, Zirui and Gao, Lang and Liang, Junhong and Chen, Zhenhao and Zhang, Jinghui and Chen, Xiuying , booktitle=. 2026 , url=
2026
-
[39]
2026 , url=
Zhang, Fan and Song, Mingzi and Elbadry, Rania and Chen, Yankai and Wang, Shaobo and Zhou, Yixi and Zheng, Xunwen and He, Yueru and Dai, Yuyang and Georgiev, Georgi and others , booktitle=. 2026 , url=
2026
-
[40]
2026 , url=
Zhang, Fan and Luo, Jiabin and Zhang, Zheng and Huang, Shuanghong and Liu, Zhipeng and Chen, Yu , booktitle=. 2026 , url=
2026
-
[41]
2026 , url=
Zhang, Fan and Li, Zhen and Peng, Sijia and Chen, Yu , booktitle=. 2026 , url=
2026
-
[42]
2025 , url=
Lai, Zhengzhao and Zheng, Youbin and Cai, Zhenyang and Lyu, Haonan and Yang, Jinpu and Liang, Hongqing and Hu, Yan and Wang, Benyou , booktitle=. 2025 , url=
2025
-
[43]
2024 , url=
Yang, Jingpu and Wang, Helin and Zhao, Qirui and Shi, Zhecheng and Song, Zirui and Fang, Miao , booktitle=. 2024 , url=
2024
-
[44]
2024 , url=
Yang, Jingpu and Han, Zehua and Xiang, Mengyu and Wang, Helin and Huang, Yuxiao and Fang, Miao , booktitle=. 2024 , url=
2024
-
[45]
2025 , url=
Yang, Jingpu and Cui, Mingxuan and Zhang, Hang and Ji, Fengxian and Lai, Zhengzhao and Wang, Yufeng , booktitle=. 2025 , url=
2025
-
[46]
2026 , url=
Yang, Jingpu and Zhang, Hang and Ji, Fengxian and Wang, Yufeng and Wang, Mingjie and Luo, Yizhe and Ding, Wenrui , booktitle=. 2026 , url=
2026
-
[47]
2026 , url=
Cui, Mingxuan and Yang, Jingpu and Ji, Fengxian and Jiang, Qian and Shi, Zhecheng and Wang, Jiaming and Song, Zirui and Koto, Fajri and Chen, Xiuying , booktitle=. 2026 , url=
2026
-
[48]
2026 , url=
Yang, Jingpu and Ji, Fengxian and Lai, Zhengzhao and Wu, Juanfan and Cui, Mingxuan and Wang, Yufeng , booktitle=. 2026 , url=
2026
-
[49]
2026 , url=
Song, Zirui and Ouyang, Guangxian and Li, Mingzhe and Ji, Yuheng and Wang, Chenxi and Xu, Zixiang and Zhang, Zeyu and Zhang, Xiaoqing and Jiang, Qian and Ji, Fengxian and Chen, Zhenhao and Li, Zhongzhi and Chen, Xiuying , booktitle=. 2026 , url=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.