Impact Analysis of Speech Representation Learning Models for Acoustic Side-Channel Attack
Pith reviewed 2026-06-29 04:41 UTC · model grok-4.3
The pith
Kolmogorov-Arnold Networks for fine-tuning speech models set new state-of-the-art on keyboard acoustic side-channel attacks even under VoIP codecs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the KEYAC dataset, replacing the final classifier with Kolmogorov-Arnold Networks during partial fine-tuning of speech representation models yields higher keystroke inference accuracy than fully connected or convolutional heads in both standard and VoIP-codec conditions, establishing a new state-of-the-art.
What carries the argument
Kolmogorov-Arnold Networks (KAN) used as the fine-tuning head to capture nonlinear feature interactions that standard networks miss when adapting speech representations to acoustic side-channel key inference.
If this is right
- Partial fine-tuning of speech models improves keystroke inference accuracy over zero-shot transfer on KEYAC.
- Performance remains limited across VoIP codecs when only conventional fine-tuning layers are used.
- KAN-based fine-tuning produces the highest reported accuracy on KEYAC for both clean and codec-degraded audio.
- The method shows that nonlinear modeling directly improves robustness of side-channel attacks to audio compression.
Where Pith is reading between the lines
- The same KAN replacement could be tested on other audio side-channel tasks that involve nonlinear distortions such as room reverberation or microphone frequency response.
- KEYAC may become a standard benchmark for measuring how well audio foundation models resist codec or channel effects in security settings.
- If KAN heads generalize, they might also raise performance when speech models are adapted to detect other subtle acoustic leaks such as printer or hard-drive sounds.
Load-bearing premise
The accuracy drop under VoIP codecs arises because conventional fine-tuning layers cannot adequately model nonlinear interactions among the extracted speech features.
What would settle it
Measure whether KAN fine-tuning still outperforms standard heads on a fresh keyboard acoustic dataset recorded through a different VoIP codec or with added background noise; if the gap closes or reverses, the central claim is falsified.
Figures
read the original abstract
Acoustic side-channel attacks (ASCA) on keyboards have gained increasing attention, yet impact of speech representation learning models in ASCA remains unexplored. Addressing this, we introduce KEYAC, a dataset designed to analyze representation generalization for ASCA under both standard and VoIP codec settings. On KEYAC, we evaluate six representation learning models under zero-shot and partial fine-tuning settings using fully connected and convolutional networks. Results show that while partial fine-tuning improves performance, models struggle to generalize across VoIP codecs. We hypothesize this limitation stems from inadequate modeling of nonlinear feature interactions in conventional fine-tuning architectures. To address this, we employ Kolmogorov-Arnold Networks (KAN) for fine-tuning. Empirical results show that KAN-based fine-tuning consistently outperforms the baselines and establishes a new state-of-the-art on KEYAC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the KEYAC dataset to study the impact of speech representation learning models on acoustic side-channel attacks (ASCA) under standard and VoIP codec conditions. It evaluates six models in zero-shot and partial fine-tuning settings using FC and CNN heads, observes that partial fine-tuning improves performance but generalization to VoIP codecs remains challenging, hypothesizes that this is due to insufficient modeling of nonlinear feature interactions in standard architectures, and proposes Kolmogorov-Arnold Networks (KAN) for fine-tuning, reporting that KAN consistently outperforms the baselines and achieves new state-of-the-art results on KEYAC.
Significance. If the empirical results hold under proper controls, the paper contributes a new benchmark dataset for ASCA research and provides evidence that KAN-based fine-tuning can improve performance in this domain. The work highlights challenges in generalizing across VoIP codecs, which is relevant for real-world attack scenarios. The introduction of KEYAC is a clear strength as a reproducible resource for the community.
major comments (1)
- [Abstract] The central claim that KAN-based fine-tuning outperforms baselines specifically because it better models nonlinear feature interactions (addressing the VoIP gap) is not isolated by the experiments. No parameter-matched capacity controls, no comparisons to other nonlinear heads (e.g., deeper MLPs or attention), and no post-hoc analysis of learned activations or interaction terms are described. This leaves the explanatory link between hypothesis and result insecure.
minor comments (1)
- [Abstract] The abstract states results and a hypothesis but supplies no experimental details, error bars, dataset statistics, or ablation studies, which weakens verifiability of the reported outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] The central claim that KAN-based fine-tuning outperforms baselines specifically because it better models nonlinear feature interactions (addressing the VoIP gap) is not isolated by the experiments. No parameter-matched capacity controls, no comparisons to other nonlinear heads (e.g., deeper MLPs or attention), and no post-hoc analysis of learned activations or interaction terms are described. This leaves the explanatory link between hypothesis and result insecure.
Authors: We agree that the experiments do not isolate the explanatory mechanism. The manuscript reports consistent gains from KAN fine-tuning over the FC and CNN heads across the six representation models and both codec conditions, but does not include parameter-matched capacity controls, comparisons against other nonlinear heads such as deeper MLPs or attention layers, or post-hoc inspection of learned activations or interaction terms. The hypothesis is presented as motivation for trying KAN rather than as a claim proven by controlled ablation. We will revise the abstract and discussion sections to qualify the language, presenting KAN results as an empirical improvement that addresses the observed generalization difficulty without asserting that the improvement is specifically due to superior nonlinear interaction modeling. We will also add an explicit limitations paragraph noting the absence of the suggested controls and listing them as future work. This is a partial revision. revision: partial
Circularity Check
No circularity: empirical claims rest on dataset experiments, not self-referential derivations
full rationale
The paper introduces KEYAC dataset and reports empirical comparisons of representation models under zero-shot and partial fine-tuning, plus KAN-based fine-tuning. No equations, fitted parameters renamed as predictions, or derivation chains appear. The hypothesis about nonlinear interactions motivates the KAN choice but is not used to derive results by construction; outcomes are measured directly on held-out data. No self-citations are load-bearing for any central claim. The work is self-contained against external benchmarks (KEYAC performance numbers).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Impact Analysis of Speech Representation Learning Models for Acoustic Side-Channel Attack
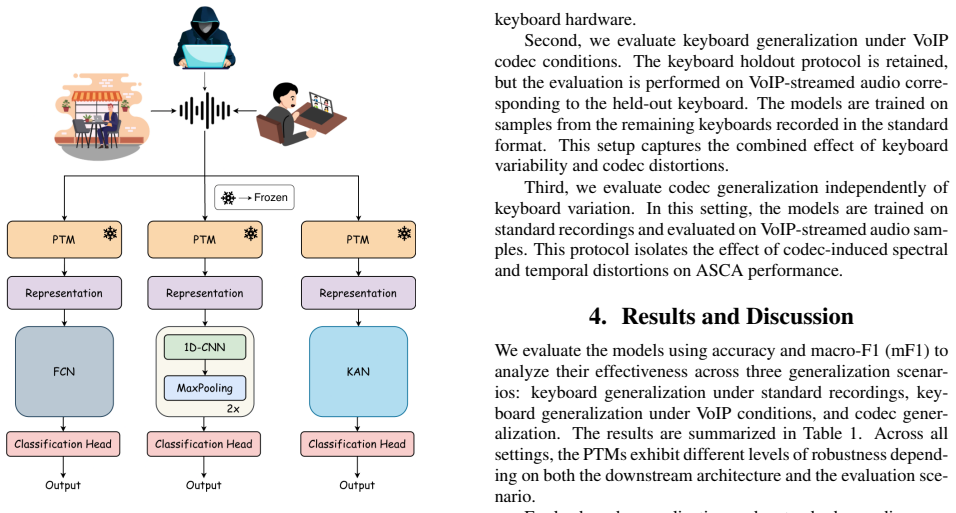
Introduction Keystroke sounds produced on a physical keyboard carry dis- tinctive acoustic signatures [1, 2, 3]. These signatures can be exploited to identify individual keystrokes, potentially compro- mising user security and privacy in real-world environments. Such attacks are commonly referred to as acoustic side-channel attacks (ASCA). In practice, us...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Pretrained Models We consider four self-supervised (SSL) speech PTM back- bones for evaluation, namely, Wav2Vec2, WavLM, HuBERT, and XLS-R
Background 2.1. Pretrained Models We consider four self-supervised (SSL) speech PTM back- bones for evaluation, namely, Wav2Vec2, WavLM, HuBERT, and XLS-R. Wav2Vec2 learns contextualized speech represen- tations through a masked latent prediction framework opti- mized with a contrastive objective [7]. WavLM extends this framework by jointly learning acous...
-
[3]
Methodology 3.1. Dataset Existing Acoustic Side-Channel Attack (ASCA) datasets are of- ten limited by outdated hardware, small-scale collections, or evaluations restricted to basic keyboard generalization tasks. Moreover, prior datasets lack the diversity needed to study rep- resentation stability across modern telecommunication chan- nels. To address the...
-
[4]
The results are summarized in Table 1
Results and Discussion We evaluate the models using accuracy and macro-F1 (mF1) to analyze their effectiveness across three generalization scenar- ios: keyboard generalization under standard recordings, key- board generalization under V oIP conditions, and codec gener- alization. The results are summarized in Table 1. Across all settings, the PTMs exhibit...
-
[5]
Conclusion In this work, we introducedKEYAC, a dataset designed to study acoustic side-channel attacks under realistic conditions, includ- ing cross-device variability and V oIP codec distortions. Using this dataset, we systematically evaluated multiple speech pre- trained models to examine their generalization capability for keystroke identification acro...
-
[6]
There is no AI contribution in ideation, methodological contribution, results, or content development
Generative AI Use Disclosure Generative AI has been used only for linguistic editing and im- proving readability. There is no AI contribution in ideation, methodological contribution, results, or content development
-
[7]
Keyboard acoustic emanations,
D. Asonov and R. Agrawal, “Keyboard acoustic emanations,” in Proceedings of the IEEE Symposium on Security and Privacy. IEEE, 2004, pp. 3–11
2004
-
[8]
Keyboard acoustic emana- tions revisited,
L. Zhuang, F. Zhou, and D. Tygar, “Keyboard acoustic emana- tions revisited,” inProceedings of the 2009 ACM Conference on Computer and Communications Security. ACM, 2009, pp. 373– 382
2009
-
[9]
Decker: Domain-invariant embedding for cross-keyboard extrac- tion and recognition,
B. B. P. Maurya, N. Choudhury, D. Agarwal, and A. B. Buduru, “Decker: Domain-invariant embedding for cross-keyboard extrac- tion and recognition,” inProceedings of the ACM Asia Conference on Computer and Communications Security, 2026, pp. 1707– 1720
2026
-
[10]
A Practical Deep Learning-Based Acoustic Side Channel Attack on Keyboards,
J. Harrison, E. Toreini, and M. Mehrnezhad, “A Practical Deep Learning-Based Acoustic Side Channel Attack on Keyboards,” in2023 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Jul. 2023, pp. 270–280. [Online]. Available: http://arxiv.org/abs/2308.01074
-
[11]
Reflexnoop: Near-line-of-sight acoustic keystroke inference via laptop screen reflections,
T. Maiet al., “Reflexnoop: Near-line-of-sight acoustic keystroke inference via laptop screen reflections,” ACM CCS / preprint, 2024, project / preprint (cite exact source when available)
2024
-
[12]
Making acoustic side-channel attacks on noisy keyboards viable with llm-assisted spectrograms’
S. A. Ayati, J. H. Park, Y . Cai, and M. Botacin, “Making acoustic side-channel attacks on noisy keyboards viable with llm-assisted spectrograms’” typo” correction,”arXiv preprint arXiv:2504.11622, 2025
-
[13]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[14]
Hubert: Self-supervised speech representa- tion learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representa- tion learning by masked prediction of hidden units,” inICASSP / arXiv, 2021
2021
-
[15]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE/ACM Transactions on Au- dio, Speech and Language Processing, 2022
2022
-
[16]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[17]
X-vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust dnn embeddings for speaker recognition,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333
2018
-
[18]
Xls-r: Self- supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. V on Platen, Y . Saraf, J. Pinoet al., “Xls-r: Self- supervised cross-lingual speech representation learning at scale,” arXiv preprint arXiv:2111.09296, 2021
-
[19]
Transforming the embeddings: A lightweight technique for speech emotion recog- nition tasks,
O. C. Phukan, A. B. Buduru, and R. Sharma, “Transforming the embeddings: A lightweight technique for speech emotion recog- nition tasks,”arXiv preprint arXiv:2305.18640, 2023
-
[20]
KAN: Kolmogorov-Arnold Networks
Z. Liu, Y . Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljaˇci´c, T. Y . Hou, and M. Tegmark, “Kan: Kolmogorov-arnold net- works,”arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Superb: Speech processing universal performance benchmark,
S.-w. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakho- tia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Linet al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021
-
[22]
Slue: New benchmark tasks for spoken language un- derstanding evaluation on natural speech,
S. Shon, A. Pasad, F. Wu, P. Brusco, Y . Artzi, K. Livescu, and K. J. Han, “Slue: New benchmark tasks for spoken language un- derstanding evaluation on natural speech,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7927–7931
2022
-
[23]
Slue phase-2: A benchmark suite of diverse spoken language understanding tasks,
S. Shon, S. Arora, C.-J. Lin, A. Pasad, F. Wu, R. Sharma, W.- L. Wu, H.-y. Lee, K. Livescu, and S. Watanabe, “Slue phase-2: A benchmark suite of diverse spoken language understanding tasks,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 8906–8937
2023
-
[24]
Classification of vocal inten- sity category from speech using the wav2vec2 and whisper em- beddings,
M. Kodali, S. Kadiri, and P. Alku, “Classification of vocal inten- sity category from speech using the wav2vec2 and whisper em- beddings,” inInterspeech. International Speech Communication Association (ISCA), 2023, pp. 4134–4138
2023
-
[25]
A large-scale evaluation of speech foundation models,
S.-w. Yang, H.-J. Chang, Z. Huang, A. T. Liu, C.-I. Lai, H. Wu, J. Shi, X. Chang, H.-S. Tsai, W.-C. Huanget al., “A large-scale evaluation of speech foundation models,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 32, pp. 2884–2899, 2024
2024
-
[26]
From raw speech to fixed representations: A comprehensive evaluation of speech em- bedding techniques,
D. Porjazovski, T. Gr ´osz, and M. Kurimo, “From raw speech to fixed representations: A comprehensive evaluation of speech em- bedding techniques,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3546–3560, 2024
2024
-
[27]
On the use of x-vectors for robust speaker recognition
O. Novotn `y, O. Plchot, P. Matejka, L. Mosner, and O. Glem- bek, “On the use of x-vectors for robust speaker recognition.” in Odyssey, 2018, pp. 168–175
2018
-
[28]
Loki: Low-dimensional kan for ef- ficient fine-tuning image models,
X. Cai, R. Pan, and H. Yang, “Loki: Low-dimensional kan for ef- ficient fine-tuning image models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 14 869– 14 880
2025
-
[29]
From kan to gr-kan: Advancing speech enhancement with kan- based methodology,
H. Li, Y . Hu, C. Chen, S. M. Siniscalchi, S. Liu, and E. S. Chng, “From kan to gr-kan: Advancing speech enhancement with kan- based methodology,”arXiv preprint arXiv:2412.17778, 2024
-
[30]
Rethinking cross-corpus speech emo- tion recognition benchmarking: Are paralinguistic pre-trained representations sufficient?
O. C. Phukan, M. M. Akhtar, S. R. Behera, P. Bhagath, P. B. Reddy, A. B. Buduruet al., “Rethinking cross-corpus speech emo- tion recognition benchmarking: Are paralinguistic pre-trained representations sufficient?” in2025 Asia Pacific Signal and In- formation Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2025, pp. 1022–1027
2025
-
[31]
Foca: Multimodal malware classification via hyperbolic cross- attention,
N. Choudhury, B. B. P. Maurya, O. C. Phukan, and A. B. Buduru, “Foca: Multimodal malware classification via hyperbolic cross- attention,”arXiv preprint arXiv:2601.17638, 2026
-
[32]
N. Choudhury, B. B. P. Maurya, B. V . Kuwar, and A. B. Buduru, “Gocoma: Hyperbolic multimodal representation fu- sion for large language model-generated code attribution,”arXiv preprint arXiv:2604.16377, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.