Anomaly-Informed Confidence Calibration for Vision-Based Safety Prediction
Pith reviewed 2026-05-21 04:21 UTC · model grok-4.3
The pith
Fusing perceptual reconstruction errors with dynamics uncertainty scores calibrates vision-based safety predictions under unseen distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
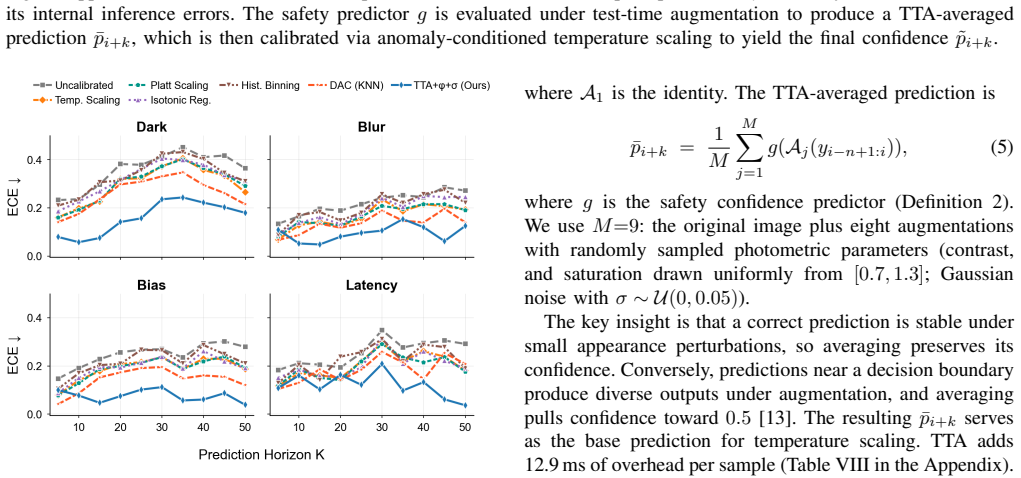
The Anomaly-Informed Online Calibration fuses a perceptual anomaly score from reconstruction error with a dynamics anomaly score from epistemic uncertainty and control-stream statistics inside a world model. Using these scores, a temperature-scaling calibrator performs test-time augmentation to reduce overconfidence selectively under shift while leaving nominal-condition performance unchanged. On a physical DonkeyCar tested with four real-world anomaly protocols (darkness, blur, actuation bias, processing latency) never seen in training, the method lowers average expected calibration error from 0.184 to 0.116.
What carries the argument
Anomaly-Informed Online Calibration, which fuses perceptual reconstruction error and dynamics epistemic uncertainty from a world model to adjust predictor temperature at test time.
If this is right
- Vision-based safety predictors can receive reliable confidence estimates without any component being retrained when new anomalies appear.
- The same fusion of perceptual and dynamics scores applies directly to other physical platforms that use camera images for control.
- Nominal performance stays intact because the calibrator acts only when the fused anomaly signal rises above baseline levels.
- Four specific anomaly types—darkness, blur, actuation bias, and processing latency—are each handled by the same online procedure.
Where Pith is reading between the lines
- The perception-dynamics gap identified here may appear in other control domains such as drone navigation or robotic manipulation whenever visual inputs remain plausible while physical behavior degrades.
- Replacing the world model with a learned dynamics predictor trained on more diverse shifts could extend the method to environments where the current model becomes unreliable.
- The selective nature of the calibration suggests it could be combined with uncertainty-aware planning to trigger safer fallback behaviors only when both perception and dynamics signals agree.
Load-bearing premise
The world model that supplies the dynamics anomaly score remains accurate and does not itself produce misleading signals when the input distribution shifts.
What would settle it
Run the same four anomaly protocols on the DonkeyCar while measuring whether the fused score still produces a lower expected calibration error than the best baseline; failure to show the 0.116 error or worse performance than the baseline would falsify the improvement claim.
Figures





read the original abstract
Reliable confidence estimates are important for safely deploying vision-based controllers in autonomous racing, where safety predictions must be derived from camera images, yet modern predictors become dangerously overconfident under test-time distribution shifts. We identify a critical perception-dynamics gap in existing anomaly signals: widely used scores, such as autoencoder reconstruction error, capture visual corruptions but miss dynamics anomalies (e.g., actuation bias, latency), where images remain plausible while the trajectory degrades. To address this, we propose an Anomaly-Informed Online Calibration approach that, without retraining any model component, fuses two complementary anomaly scores extracted from a world model: a perceptual score from reconstruction error and a dynamics score from epistemic uncertainty and control-stream statistics. Based on these fused scores, a lightweight temperature-scaling calibrator leverages test-time augmentation to selectively reduce overconfidence under shift while preserving nominal-condition performance. Experiments on a physical DonkeyCar under four real-world anomaly protocols unseen during training (darkness, blur, actuation bias, processing latency) reduce average expected calibration error from 0.184 to 0.116, a 37% improvement over the best baseline, without modifying the base safety predictor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Anomaly-Informed Online Calibration for vision-based safety prediction in autonomous racing. Without retraining, it fuses a perceptual anomaly score (reconstruction error) with a dynamics score (epistemic uncertainty plus control-stream statistics) extracted from a world model; the fused score then drives test-time temperature scaling to reduce overconfidence under distribution shift. On a physical DonkeyCar, the method lowers average expected calibration error from 0.184 to 0.116 (37 % improvement) across four real-world anomaly protocols unseen in training: darkness, blur, actuation bias, and processing latency.
Significance. If the result holds, the work supplies a practical, training-free mechanism for closing the perception-dynamics gap in anomaly detection for safety-critical vision controllers. The hardware validation with multiple distinct, physically realized shifts is a concrete strength that increases relevance for deployment.
major comments (2)
- [Abstract and §3 (Method)] The central claim that the fused anomaly score correctly triggers calibration under actuation bias and processing latency rests on the dynamics component (epistemic uncertainty and control-stream statistics) increasing meaningfully when images remain visually plausible. Because the world model is trained only on nominal trajectories, it is unclear whether epistemic uncertainty rises under these shifts; if it remains low or miscalibrated, the fusion under-detects the anomaly and the reported ECE reduction cannot be attributed to the proposed method. Please add an ablation or per-anomaly breakdown of the dynamics score values and their correlation with calibration improvement.
- [Experiments section] Table or figure reporting the 0.184-to-0.116 ECE reduction (and the 37 % figure) does not state the exact baseline implementations, the number of runs, or any statistical test for the improvement. Without these, it is impossible to judge whether the gain is robust or reproducible, which directly affects the strength of the empirical contribution.
minor comments (1)
- [§3] Define the precise fusion rule (e.g., weighted sum, product, or learned combination) for the perceptual and dynamics scores and state how the temperature is selected from the test-time augmentation ensemble.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments raise valid points about clarifying the contribution of the dynamics anomaly component and improving the reporting of experimental details for reproducibility. We address each major comment below and have incorporated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The central claim that the fused anomaly score correctly triggers calibration under actuation bias and processing latency rests on the dynamics component (epistemic uncertainty and control-stream statistics) increasing meaningfully when images remain visually plausible. Please add an ablation or per-anomaly breakdown of the dynamics score values and their correlation with calibration improvement.
Authors: We agree that explicit evidence for the dynamics score's behavior under non-visual shifts is important to substantiate the fusion mechanism. The world model, trained exclusively on nominal trajectories, produces elevated epistemic uncertainty when control inputs lead to trajectory deviations that are inconsistent with learned dynamics, even if the corresponding images appear plausible. In the revised manuscript we have added a per-anomaly breakdown (new Table 3 and accompanying text in §4.3) that reports mean dynamics scores for each of the four anomaly protocols together with their Pearson correlation to the observed per-anomaly ECE reductions. The added analysis shows that the dynamics score rises substantially for actuation bias and latency (while the perceptual score remains near nominal levels), and that this increase accounts for the majority of the calibration gain in those cases. We believe this directly addresses the concern and strengthens the attribution of the reported ECE improvement to the proposed method. revision: yes
-
Referee: [Experiments section] Table or figure reporting the 0.184-to-0.116 ECE reduction (and the 37 % figure) does not state the exact baseline implementations, the number of runs, or any statistical test for the improvement.
Authors: We acknowledge that the original presentation omitted several details required for full reproducibility assessment. In the revised version we have expanded the caption of the primary results table (Table 2) and the corresponding paragraph in §4.2 to (i) list the precise baseline implementations (standard temperature scaling, entropy-based scaling, and Monte-Carlo dropout calibration, each applied without anomaly information), (ii) state that all metrics are averaged over 5 independent physical runs with standard deviation reported, and (iii) include a paired t-test confirming that the ECE reduction is statistically significant (p < 0.05). These additions are now present in both the main text and the supplementary material. revision: yes
Circularity Check
No significant circularity; empirical validation on physical hardware
full rationale
The paper proposes an anomaly-informed online calibration method that fuses perceptual reconstruction error with dynamics epistemic uncertainty from a world model, then applies selective temperature scaling at test time. All performance claims (37% ECE reduction from 0.184 to 0.116) are obtained from direct measurement on a physical DonkeyCar under four unseen real-world anomaly protocols. No equations, fitted parameters, or self-citations are used to derive the reported improvement; the result is an external empirical outcome rather than a quantity defined by construction from the calibration procedure itself. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A world model trained on nominal data produces epistemic uncertainty that meaningfully signals dynamics anomalies such as actuation bias or latency.
Reference graph
Works this paper leans on
-
[1]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks,
K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” inNeurIPS, vol. 31, Curran Associates, Inc., 2018
work page 2018
-
[2]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inICML, 2017, pp. 1321–1330
work page 2017
-
[3]
Can you trust your model’s uncer- tainty? Evaluating predictive uncertainty under dataset shift,
Y . Ovadia et al., “Can you trust your model’s uncer- tainty? Evaluating predictive uncertainty under dataset shift,” inNeurIPS, vol. 32, 2019
work page 2019
-
[4]
Post-hoc uncertainty calibration for domain drift scenarios,
C. Tomani, S. Gruber, M. E. Erdem, D. Cremers, and F. Buettner, “Post-hoc uncertainty calibration for domain drift scenarios,” inCVPR, 2021, pp. 10 124– 10 132
work page 2021
-
[5]
Dropout as a Bayesian ap- proximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a Bayesian ap- proximation: Representing model uncertainty in deep learning,” inICML, 2016, pp. 1050–1059
work page 2016
-
[6]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” inNeurIPS, vol. 30, 2017
work page 2017
-
[7]
Ex- ploring covariate and concept shift for detection and calibration of out-of-distribution data,
J. Tian, Y .-C. Hsu, Y . Shen, H. Jin, and Z. Kira, “Ex- ploring covariate and concept shift for detection and calibration of out-of-distribution data,”arXiv preprint arXiv:2110.15231, 2021
-
[8]
Robust calibration with multi-domain temperature scaling,
Y . Yu, S. Bates, Y . Ma, and M. Jordan, “Robust calibration with multi-domain temperature scaling,” NeurIPS, vol. 35, pp. 27 510–27 523, 2022
work page 2022
-
[9]
Recurrent world models facilitate policy evolution,
D. Ha and J. Schmidhuber, “Recurrent world models facilitate policy evolution,” inNeurIPS, vol. 31, 2018
work page 2018
-
[10]
Benchmarking neu- ral network robustness to common corruptions and perturbations,
D. Hendrycks and T. Dietterich, “Benchmarking neu- ral network robustness to common corruptions and perturbations,” inICLR, 2019
work page 2019
-
[11]
Variational autoencoder based anomaly detection using reconstruction probability,
J. An and S. Cho, “Variational autoencoder based anomaly detection using reconstruction probability,” Special Lecture on IE, vol. 2, no. 1, pp. 1–18, 2015
work page 2015
-
[12]
An introduction to ROC analysis
T. Fawcett, “An introduction to roc analysis,”Pattern Recognition Letters, vol. 27, no. 8, pp. 861–874, 2006, ROC Analysis in Pattern Recognition,ISSN: 0167- 8655.DOI:10.1016/j.patrec.2005.10.010
-
[13]
A. Hekler, T. J. Brinker, and F. Buettner, “Test time augmentation meets post-hoc calibration: Uncertainty quantification under real-world conditions,” inPro- ceedings of the AAAI Conference on Artificial Intel- ligence, vol. 37, Jun. 2023, pp. 14 856–14 864.DOI: 10.1609/aaai.v37i12.26735
-
[14]
Deep anomaly detection with outlier exposure,
D. Hendrycks, M. Mazeika, and T. G. Dietterich, “Deep anomaly detection with outlier exposure,” in ICLR, 2019
work page 2019
-
[15]
Learning to drive (L2D) as a low-cost benchmark for real-world reinforcement learning,
A. Viitala, R. Boney, Y . Zhao, A. Ilin, and J. Kannala, “Learning to drive (L2D) as a low-cost benchmark for real-world reinforcement learning,” inICAR, IEEE, 2021, pp. 275–281
work page 2021
-
[16]
A baseline for detect- ing misclassified and out-of-distribution examples in neural networks,
D. Hendrycks and K. Gimpel, “A baseline for detect- ing misclassified and out-of-distribution examples in neural networks,” inICLR, 2017
work page 2017
-
[17]
Block selection method for using feature norm in out-of- distribution detection,
Y . Yu, S. Shin, S. Lee, C. Jun, and K. Lee, “Block selection method for using feature norm in out-of- distribution detection,” inCVPR, 2023, pp. 15 701– 15 711
work page 2023
-
[18]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,
J. C. Platt, “Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,” inAdvances in Large Margin Classifiers, MIT Press, 1999, pp. 61–74
work page 1999
-
[19]
Transforming classifier scores into accurate multiclass probability estimates,
B. Zadrozny and C. Elkan, “Transforming classifier scores into accurate multiclass probability estimates,” inKDD, 2002, pp. 694–699
work page 2002
-
[20]
Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers,
B. Zadrozny and C. Elkan, “Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers,” inICML, 2001, pp. 609–616
work page 2001
-
[21]
Beyond in-domain scenarios: Robust density-aware calibration,
C. Tomani, F. K. Waseda, Y . Shen, and D. Cremers, “Beyond in-domain scenarios: Robust density-aware calibration,” inICML, 2023, pp. 34 344–34 368
work page 2023
-
[22]
Measuring calibration in deep learning,
J. Nixon, M. W. Dusenberry, L. Zhang, G. Jerfel, and D. Tran, “Measuring calibration in deep learning,” in CVPRW, 2019
work page 2019
-
[23]
VOS: Learning what you don’t know by virtual outlier synthesis,
X. Du, Z. Wang, M. Cai, and Y . Li, “VOS: Learning what you don’t know by virtual outlier synthesis,” in ICLR, 2022
work page 2022
-
[24]
React: Out-of-distribution detection with rectified activations,
Y . Sun, C. Guo, and Y . Li, “React: Out-of-distribution detection with rectified activations,” inNeurIPS, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34, Curran Associates, Inc., 2021, pp. 144–157
work page 2021
-
[25]
Z. Mao, C. Sobolewski, and I. Ruchkin, “How safe am i given what i see? calibrated prediction of safety chances for image-controlled autonomy,” inProc. of the 6th Annual Learning for Dynamics and Control Conference, vol. 242, PMLR, 2024, pp. 1370–1387
work page 2024
-
[26]
Misbehaviour prediction for autonomous driving sys- tems,
A. Stocco, M. Weiss, M. Calzana, and P. Tonella, “Misbehaviour prediction for autonomous driving sys- tems,” inICSE, 2020, pp. 359–371.DOI:10.1145/ 3377811.3380353
-
[27]
Mas- tering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mas- tering diverse control tasks through world models,” Nature, vol. 640, pp. 647–653, 2025
work page 2025
-
[28]
End to End Learning for Self-Driving Cars
M. Bojarski et al., “End to end learning for self-driving cars,”arXiv preprint arXiv:1604.07316, 2016. APPENDIX A Training and Implementation Details Table V lists the training hyperparameters for all pipeline components. The world model consists of a convolutional V AE operating on64×64images and a ConvLSTM predictor that autoregressively rolls out laten...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.